Python网络爬虫实战:卫健委官网数据的爬取
好久不见!
这次我们来爬一下 国家卫健委官网 的文章。
零 爬虫和反爬机制间的博弈
关于我跟网站反爬机制之间的各种博弈过程,我其实在另一篇博客中详细写了,可惜不知道哪儿触碰到了 CSDN 的审核机制,审查没有通过。其实也是一些失败的爬虫尝试,没什么意思。真的有人感兴趣的话可以私下加我交流。
讲道理,卫健委的网站比我想象中要难爬的多,反爬机制是真的强。
经过无数次的 412 错误,我发现这个网站的反爬机制有以下几个特点(个人经验,总结不准确或者有遗漏的点欢迎大家补充)。
- 服务器在处理网络请求时是要验证 Cookie 的。
- Cookie 的值是动态变化的,一个 Cookie 的有效时长大概只有几十秒。
- 访问不同的网页时会更换 Cookie ,所以通过打时间差,用一个 Cookie 爬多个网页的想法不成立。
- 网站会检测识别并限制 Selenium 的访问,用 Selenium 访问得到的只是一个空界面。
这样的特点就意味着,我没有办法通过常规的方法来爬取该网站。
很显然,该站的 Cookie 是经过 js 加密的,其中至少包含了 3 个加密后的参数。
想要真正意义上破解其加密算法,实现数据爬取,理论上是可行的,因为加密过程是在浏览器中完成的,所有加密的代码都可以在开发者工具中看到,所以理论上,你只需要懂 js,花点功夫是可以完成破解的。(But,不建议这样去做,如果是磨练技术,可以私下研究研究,但如果是为了写爬虫而写这个,投入和产出其实是有点不成正比的,不划算。而且破解对方网站加密算法,你可是在法律的边缘试探啊!)
在我一筹莫展之际,一位大佬的推荐给我一款 “神器”,成功完成了爬取,那就是 pyppeteer。
关于这个框架,多的我也不说了(主要是我也是刚接触,了解不深,详细的介绍大家可以去网上查找了解)
简单说,就是进阶版的 selenium,功能更完善,效率更高,更容易绕过反爬检测。
抱着试试看的心态,我安装了这个库,试着跑了一下。
import asyncio
from pyppeteer import launch
url = 'http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml'
async def fetchUrl(url):
browser = await launch({'headless': False,'dumpio':True, 'autoClose':True})
page = await browser.newPage()
await page.goto(url)
await asyncio.wait([page.waitForNavigation()])
str = await page.content()
await browser.close()
print(str)
asyncio.get_event_loop().run_until_complete(fetchUrl(url))居然真的成功了!
至此,借由 Pyppeteer 这个神器,卫健委官网的反爬机制终于算是可以绕过去了。
下面我会详细介绍爬取的过程。
贰 卫健委官网文章的爬取
1. 安装必要的库
我们的爬虫用到的库是 pyppeteer 和 BeautifulSoup 库,下面是安装指令(具体安装方法网上教程很多)
pip install pyppeteer
pip install bs4如果运行以下代码没有报错,说明安装成功。
import asyncio
from pyppeteer import launch
from bs4 import BeautifulSoup
2. 分析目标网站
由于经过前面的尝试,我们已经可以成功绕过网站的反爬机制,所以这里可以直接放心的分析网页结构了。
第一页 : http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml
第二页 : http://www.nhc.gov.cn/xcs/yqtb/list_gzbd_2.shtml
第三页 : http://www.nhc.gov.cn/xcs/yqtb/list_gzbd_3.shtml
首先观察分析网站的 URL 规则,我们可以发现,除第一页之外,其他页码的 URL 都有显著的规律——URL 中的数字对应了当前的页码,也就是说,是通过 URL 来实现翻页的。
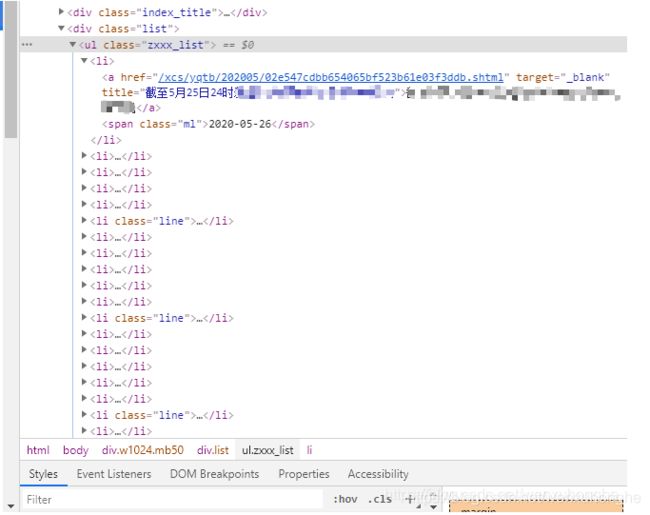
如上图所示,我们通过 F12 召唤出来的开发者工具可以看到,所有的文章,都存放在一个 class 为 zxxx_list 的 ul 标签下,其中每一个 li 标签对应着一篇文章(除了中间有部分 class="line" 的 li 标签是作为分割线)。
- 文章的标题存放在 li 标签下, a 标签的 title 属性里,
- 文章的链接存放在 a 标签的 href 属性里。
- 发表时间存放在 li 标签下,span 标签的 text 里。
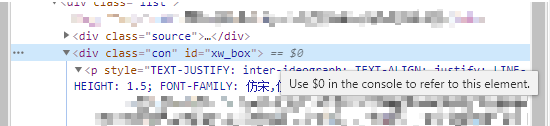
然后分析文章详情界面,正文部分存放在一个 id 为 xw_box 的 div 标签下(div 下的 众多 p 标签中,不过不用去管那些 p 标签,直接取 div 的 text 即可)。
至此,网站界面分析完成。
3. 开始编码爬取
首先导入需要的库。
import os
import asyncio
from pyppeteer import launch
from bs4 import BeautifulSoup将 pyppeteer 的操作封装成 fetchUrl 函数,用于发起网络请求,获取网页源码。
async def pyppteer_fetchUrl(url):
browser = await launch({'headless': False,'dumpio':True, 'autoClose':True})
page = await browser.newPage()
await page.goto(url)
await asyncio.wait([page.waitForNavigation()])
str = await page.content()
await browser.close()
return str
def fetchUrl(url):
return asyncio.get_event_loop().run_until_complete(pyppteer_fetchUrl(url))然后我们根据 URL 构成规则,通过 getPageUrl 函数构造每一页的 URL 链接(博主爬取的时候,网站的文章只有 7 页,所以这儿设置页数为 range(1, 7),大家可以根据自己爬取时候的实际情况进行调整)。
def getPageUrl():
for page in range(1,7):
if page == 1:
yield 'http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml'
else:
url = 'http://www.nhc.gov.cn/xcs/yqtb/list_gzbd_'+ str(page) +'.shtml'
yield url通过 getTitleUrl 函数,获取某一页的文章列表中的每一篇文章的标题,链接,和发布日期。
def getTitleUrl(html):
bsobj = BeautifulSoup(html,'html.parser')
titleList = bsobj.find('div', attrs={"class":"list"}).ul.find_all("li")
for item in titleList:
link = "http://www.nhc.gov.cn" + item.a["href"];
title = item.a["title"]
date = item.span.text
yield title, link, date通过 getContent 函数,获取某一篇文章的正文内容。(如果没有获取到正文部分,则返回 “爬取失败”)
def getContent(html):
bsobj = BeautifulSoup(html,'html.parser')
cnt = bsobj.find('div', attrs={"id":"xw_box"}).find_all("p")
s = ""
if cnt:
for item in cnt:
s += item.text
return s
return "爬取失败!"通过 saveFile 函数,可以将爬取到的数据保存在本地的 txt 文档里。
def saveFile(path, filename, content):
if not os.path.exists(path):
os.makedirs(path)
# 保存文件
with open(path + filename + ".txt", 'w', encoding='utf-8') as f:
f.write(content)最后是主函数。
if "__main__" == __name__:
for url in getPageUrl():
s =fetchUrl(url)
for title,link,date in getTitleUrl(s):
print(title,link)
#如果日期在1月21日之前,则直接退出
mon = int(date.split("-")[1])
day = int(date.split("-")[2])
if mon <= 1 and day < 21:
break;
html =fetchUrl(link)
content = getContent(html)
print(content)
saveFile("D:/Python/NHC_Data/", title, content)
print("-----"*20)这里我简单介绍一下主函数中做了什么。
- 首先通过 getPageUrl 函数,生成某一页的链接 url
- 然后通过 fetchUrl 函数访问该链接,获取网页的源码内容 s。
- 然后 通过 getTitleUrl 函数去 解析 s,得到该页文章列表中的文章 标题 title,链接 link,发布日期 date。
- 然后这里我做了一个判断,由于网站的通报文章是从 1月21日正式开始的,所以我将文章发布日期限定在 1月21日 以后。
- 然后通过 fetchUrl 和 getContent 函数去访问并解析 link ,获得该文章的正文内容 content。
- 最后通过 saveFile 函数将 content 保存在本地文件中。
4. 数据展示
最后做一下数据展示。
至此,卫健委官网文章数据爬取完毕。
叁 写在后面的话
距离上次写博客真的是过了好久了。
而且工作以后时间真的不比之前在学校那样宽裕,只能趁着下班之后抽点时间出来写。这篇博客愣是断断续续写了一周多。
不过我还是会继续学习,不断磨练自己的技术的。
回到这篇爬虫。
虽然从结果而言,我是成功将网站中的目标数据爬取下来了,算是成功的。但是讲道理,从爬虫代码本身而言,写的并不是那么漂亮,包括这些库的使用也没那么熟练,还有很大的进步空间。
这篇博文最大的意义在于抛砖引玉,希望各位大佬能够不吝分享自己爬虫的一些技巧。
同时也希望这篇博文,能够在大家遇到这类网站,手足无措的时候,提供一丝灵感,一个方向。
2020.5.29 补充
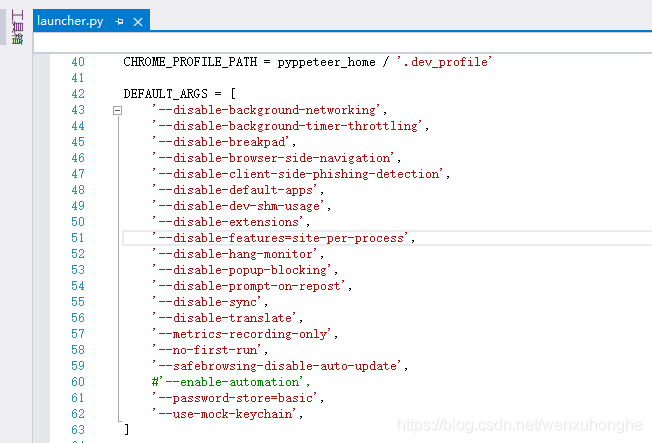
1. 很重要的一点文中忘记说了,为了防止服务器监测 webdriver,需要在导入 launch 之前,将 --enable-automation 禁用,如下所示。
from pyppeteer import launcher
# 在导入 launch 之前 把 --enable-automation 禁用 防止监测webdriver
launcher.AUTOMATION_ARGS.remove("--enable-automation")
from pyppeteer import launch我为了图省事儿,直接在源码中把这个注释掉了(反正我估摸着也不会有想让对方检测的需求吧)
文件路径:python安装路径下的 Python37_64\Lib\site-packages\pyppeteer\launcher.py 。
2. 文中源码爬取到的数据,文件名是文章标题,数据展示部分的截图,为了过审我批量重命名为发布日期,望理解。
如果文章中有哪里没有讲明白,或者讲解有误的地方,欢迎在评论区批评指正,或者扫描下面的二维码,加我微信,大家一起学习交流,共同进步。
