wordcount
文章目录
-
-
- Hadoop-Map/Reduce(WordCount)
-
- JAVA_API
- WordCount编写
- 项目打包
- 与HDFS做连接并上传到上面
-
Hadoop-Map/Reduce(WordCount)
JAVA_API
package com.bdqn.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.fs.permission.FsPermission;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URI;
/**
* User:26918
* Time:11:27
*
* @author ZhaoBinrui on 2020/9/9
*/
public class HDFSJavaAPI {
private static final String HDFS_URI="hdfs://hadoop001:9000";
private static Configuration cfg = null;
private static FileSystem fileSystem = null;
/**
* 创建目录:hadoop fs -mkdir /data
* @param dirName
* @throws Exception
*/
public static void createDirectory(String dirName) throws Exception{
fileSystem.mkdirs(new Path(dirName));
System.out.println("目录:"+dirName+"======>创建成功!");
}
/**
* 上传本地文件到hdfs:hadoop fs -put /home/hadoop183/data
* @param localPath
* @throws Exception
*/
public static void putFile(String localPath,String destPath) throws Exception{
Path lPath = new Path(localPath);
Path dPath = new Path(destPath);
fileSystem.copyFromLocalFile(lPath,dPath);
System.out.println("文件"+localPath+"======>上传成功!");
}
/**
* 从hdfs下载文件
* @param localPath
* @param destPath
* @throws Exception
*/
public static void downloadFile(String destPath,String localPath) throws Exception{
Path dPath = new Path(destPath);
Path lPath = new Path(localPath);
fileSystem.copyToLocalFile(false,dPath,lPath,true);
System.out.println("文件"+localPath+"======>下载成功!");
}
/**
* 上传大文件(以文件流的形式)
* @param src
* @param dst
* @throws IOException
*/
public static void uploadBigFile(String src,String dst)throws IOException{
//
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(new File(src)));
//
FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path(dst), new Progressable() {
@Override
public void progress() {
System.out.print(".");
}
});
//
IOUtils.copyBytes(bufferedInputStream,fsDataOutputStream,4096);
}
/**
* 删除HDFS上的文件/目录
* @param filePath
* @throws IOException
*/
public static void delete(String filePath)throws IOException{
if (fileSystem.exists(new Path(filePath))){
fileSystem.delete(new Path(filePath));
System.out.println(filePath+"已删除!");
}else{
System.out.println("不存在");
}
}
/**
* 查看文件:cat
* @param fileName
* @throws IOException
*/
public static void text(String fileName) throws IOException{
FSDataInputStream inputStream = fileSystem.open(new Path(fileName));
IOUtils.copyBytes(inputStream,System.out,4096);
}
/**
* 查看hdfs上的文件或目录:list
* @param filePath
* @throws IOException
*/
public static void list(String filePath) throws IOException{
FileStatus[] fileStatuses = fileSystem.listStatus(new Path(filePath));
for (FileStatus fileStatus : fileStatuses) {
//判断是普通文件还是目录
String isDir = fileStatus.isDirectory()?"d":"-";
//权限
FsPermission permission = fileStatus.getPermission();
//owner
String owner = fileStatus.getOwner();
//group
String group = fileStatus.getGroup();
//size
long len = fileStatus.getLen();
//last modified
long modificationTime = fileStatus.getModificationTime();
//replication
short replication = fileStatus.getReplication();
//block size
long blockSize = fileStatus.getBlockSize();
//name
Path path = fileStatus.getPath();
System.out.println(
isDir + permission + "\t" + owner
+ "\t" + group + "\t" + len/1024
+ "K\t" + modificationTime
+ "\t" + replication + "\t"
+ blockSize/1024/1024 + "M\t" + path
);
}
}
/**
* 文件重命名
* @param oldName
* @param newName
* @throws IOException
*/
public static void rename(String oldName,String newName)throws IOException{
Path oldpath = new Path(oldName);
Path newPath = new Path(newName);
if (fileSystem.exists(oldpath)){
fileSystem.rename(oldpath,newPath);
System.out.println("重命名成功!");
}else{
System.out.println("重命名失败");
}
}
/**
* 创建并且写入文件内容
* @param newFile
* @throws IOException
*/
public static void createFile(String newFile)throws IOException{
FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path(newFile));
fsDataOutputStream.write("hello".getBytes());
fsDataOutputStream.flush();
fsDataOutputStream.close();
System.out.println(newFile+"创建并写入成功");
}
public static void main(String[] args) throws Exception {
cfg = new Configuration();
fileSystem = FileSystem.get(new URI(HDFS_URI),cfg,"hadoop183");
System.out.println("HDFS文件系统成功启动...");
//createDirectory("/data");
//putFile("E:\\备份.txt","/data");
//downloadFile("/data/城市地摊财富秘籍.pdf","D:\\城市地摊财富秘籍.pdf");
//list("/data");
//uploadBigFile("E:\\软件安装包\\CentOS-7-x86_64-DVD-1810.iso","data/CentOS-7.iso");
delete("/user/hadoop183/data");
//rename("/user/hadoop183/1.iso","CentOS-7.iso");
//text("data/input_hello.txt");
//createFile("data/input_hello.txt");
}
}
使用上方的Java API接口创建data目录
- HDFS文件系统下创建data/lib目录,并将准备好的wordcount.txt文件上传到HDFS文件系统下的data目录

WordCount编写
package com.bdqn.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.reduce.IntSumReducer;
import java.io.IOException;
/**
* User:26918
* Time:10:57
* @author ZhaoBinrui on 2020/9/10
*/
public class WordCount {
// 自定义Mapper类
public static class MyMapper extends Mapper<Object, Text,Text, IntWritable>{
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
IntWritable one = new IntWritable(1);
// value 是hadoop从wordcount.txt中读取到的每一行内容
String line = value.toString();
// 每行数据按照空格分割,达到每个单词
String[] words = line.split(" ");
// 对每个单词记性计数===>(hello,1)(hadoop,1)....
for (String word : words) {
context.write(new Text(word),one);
}
System.out.println(context);
}
}
// 自定义Reducer类
public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
// 定义每个单词出现次数的初始值
int sum = 0;
// key 表示从map获取到的输入内容===>map的输出作为reduce的输入
// 合并每个单词出现的次数
for (IntWritable value : values) {
sum+=Integer.valueOf(String.valueOf(value));
}
// 输出
context.write(key,new IntWritable(sum));
}
}
// 运行WordCount
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 读取hadoop配置文件
Configuration conf = new Configuration();
//作业
Job job = Job.getInstance(conf,"word count");
// 设置作业的jar所在的类
job.setJarByClass(WordCount.class);
// 设置映射数据的mapper类
job.setMapperClass(MyMapper.class);
job.setCombinerClass(IntSumReducer.class);
// 设置规约(汇总/合并)数据的reduce
job.setReducerClass(IntSumReducer.class);
// 设置reduce输出的key和value的参数
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置wordcount运行所需要的参数
Path inputPath = new Path(args[0]);
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(conf);
if (!fileSystem.exists(inputPath)){
System.out.println("输入的参数有误!");
System.exit(1);
}
if (fileSystem.exists(outputPath)){
System.out.println("输入目录已存在,即将删除...");
fileSystem.delete(outputPath,true);
System.out.println("目录已删除,程序继续运行...");
}
FileInputFormat.addInputPath(job,inputPath);
FileOutputFormat.setOutputPath(job,outputPath);
// 运行作业
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
项目打包
-
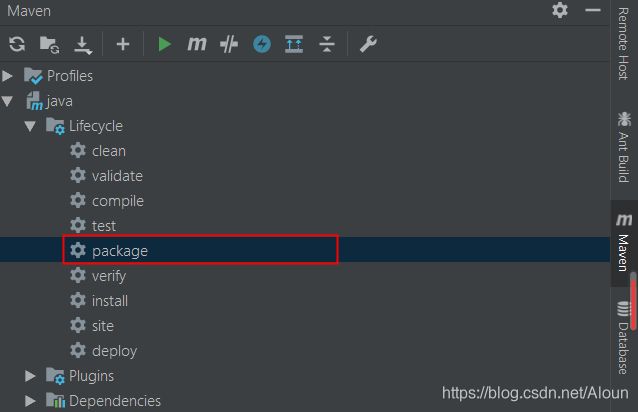
点击右侧Maven导航栏,java–>Lifecycle–>package来进行打包
-
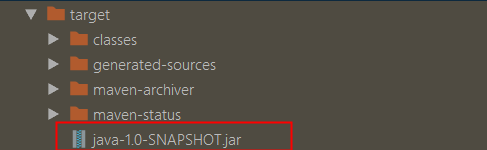
打包好的项目jar包
与HDFS做连接并上传到上面
-
点击Tools–>Deployment–>Configuration弹出页面,进行连接

-
选择类型为SFTP,输入ip地址,用户名和密码来进行连接

-
第一次上传时,要点击Tools–>Development–>Browse Remote Host来弹出弹框,之后的话直接点击右侧Remote Host导航栏来弹出

-
直接将打包好的项目jar包,拖进data/lib目录下

-
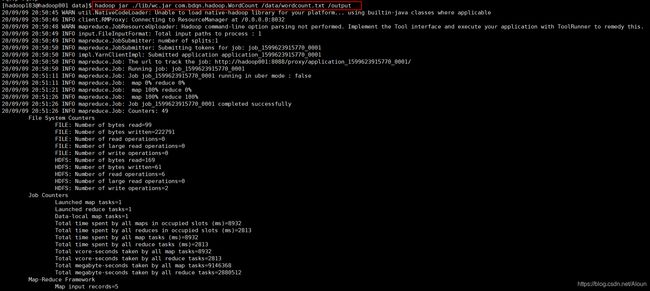
之后在xshell中输入
hadoop jar ./lib/wc.jar com.bdqn.hadoop.WordCount /data/wordcount.txt /output
-
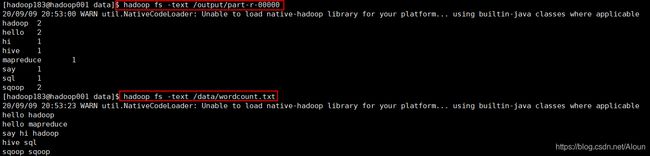
运行完成后,可以使用
hadoop fs -text /output/part-r-00000和hadoop fs -text /data/wordcount.txt来查看是否相同