JS 正则笔记
JS 正则笔记
- 元字表 `[]`
- 捕获组 `()`
- 断言
- `(?=exp)` 表示: 右侧等于
- `(?!exp) ` 表示: 右侧不等于
- `(?<=exp) ` 表示: 左侧等于
- `(?
- 例子:
- 正则方法
- exec
- 正则表达式标志
- 字符属性 `\p{exp}`
- *最后可能有的童鞋还是习惯正规点的 [官方文档](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_Expressions)*
- ?
- (x)
- (?:x)
- x(?=y)
- x(?!y)
- 参考:
JS正则笔记,因为正则在各种环境下的差异,所以会分开写。
替换 http:// www.baidu.com 为 http:// 666.baidu.com
//不带协议,替换完成后再拼接。结果 https://jerryjin.baidu.com/
location.protocol + '//' +location.href.replace(/^.+?(?=\.)/, 'jerryjin');
//带协议部分,直接匹配出要替换的内容。结果 https://jerryjin.baidu.com/
location.href.match(/^.+\//)[0].replace(/(?<=\/\/).+?(?=\.)/, 'jerryjin');
元字表 []
方括号中的任意字符匹配:
- 多个字符是
或的关系, - 横杠
-可以表示范围如:[0-9],[a-z],[0-9a-zA-Z] - 口号里最前面加
^括号内容取反。原来的包含变成不包含比如:[^0-9]除了数字
捕获组 ()
圆括号里的内容视为就表整体。
表达式中引用捕获组:
\0匹配内容\1第一个捕获组\n第N个捕获组
断言
仅作为条件,不捕获。以下仅为个人理解
(?=exp) 表示: 右侧等于
?表示问, =表示等于,加在一起就是问右边是不是等于exp (默认顺序是从左向右)
// 匹配右侧符合 '.baidu' 的部分:匹配到 "www"
'www.baidu.com,pan.csdn.net'.match(/.*(?=\.baidu)/)[0];
(?!exp) 表示: 右侧不等于
?表示问, !表示不等于,加在一起就是问右边是不是不等于exp(默认顺序是从左向右)
// 匹配右侧不等于 'b' 的三个数字, 匹配到 '222' (开g全局匹配到:["222", "333", "444"])
'aaa111bbb222ccc333ddd444'.match(/\d{3}(?!b)/);
(?<=exp) 表示: 左侧等于
?表示问, <表示左边, =表示等于,加在一起就是问左边是不是等于exp
// 左侧等于 'baidu.' 右侧等于 ',' 匹配到 'com'
'www.baidu.com,pan.csdn.net'.match(/(?<=baidu\.).*(?=,)/)[0];
// 左侧等于 'c' 的数字,匹配到 '333'
'aaa111bbb222ccc333ddd444'.match(/(?<=c)\d+/)[0];
(? 表示: 左侧不等于
?表示问, <表示左边, !表示不等于,加在一起就是问左边是不是不等于exp
// 左侧不等于 'c' 的数字,匹配到 '111'
'aaa111bbb222ccc333ddd444'.match(/(?)[0];
# 知识点1 非贪婪模式(惰性模式): (exp?)
.+? 开始匹配第一个满足的部分,因为我们要替换的只是 www 如果不用惰性模式,则会一直匹配到最后 www.baidu
结果就变成了:https://jerryjin.com/
# 知识点2 正向预查(断言/环视) : (?=exp)
其实就是检测右则是否满足此条件,仅此而已。(只匹配不提取)
上面的例子中加上"(?=\.)"匹配出的结果就是 www 不加配出的结果就是 www. (仅此而已,自己玩玩就明白了)
# 知识点3 反向预查(断言/环视) : (?<=exp)
不多解释,上面是检测右边。这个就是检测左边了。说多了反而让人糊涂。
例子:
url各部分单独 提取:
var str = "https://www.baidu.com:8080/index/go/to/1.html?a=1&b=2#top1";
str.match(/^(http|https|ftp)/).pop(); // https
str.match(/(?<=:)\d+/); // 8080
str.match(/(?<=https:\/\/)([^/:]+)/).pop(); // www.baidu.com
str.match(/(?<=\/\/[^/]+\/).+(?=\?)/).pop(); // index/go/to/1.html
str.match(/^(?:.+\/)(.+)(?=\?)/)[1]; // 1.html
str.match(/(?<=\?).+/).pop(); // a=1&b=2
str.match(/(?<=#).*/).pop(); // top1
url提取:
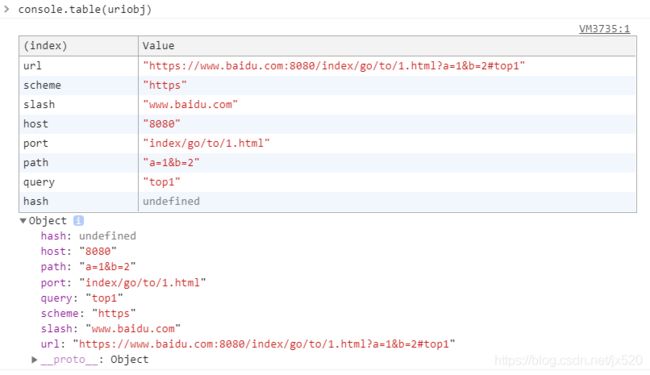
var str = "www.baidu.com:8080/index/go/to/1.html?a=1&b=2#top1";
var ruiPartsKey = ["url", "scheme", "slash", "host", "port", "path", "query", "hash"];
var ruiPartsVal = str.match(/^(?:([A-Za-z]+):)?(\/{0,3})([0-9.\-A-Za-z]+)(?::(\d+))?(?:\/([^?#]*))?(?:\?([^#]*))?(?:#(.*))?$/);
var uriobj = {};
ruiPartsKey.forEach((v, i) => uriobj[v] = ruiPartsVal[i]);
console.table(uriobj);
正则方法
| 方法 | 描述 | 对象方法 |
|---|---|---|
| exec | 在字符串中测试是否匹配,返回一个数组(未匹配到则返回null)。 | RegExp方法 |
| test | 在字符串中测试是否匹配,返回true或false。 | RegExp方法 |
| match | 在字符串中执行查找,返回一个数组或者在未匹配到时返回null。 | String方法 |
| search | 在字符串中测试,返回匹配到的位置索引,或者在失败时返回-1。 | String方法 |
| replace | 在字符串中执行查找,并且使用替换字符串替换掉匹配到的子字符串。 $&:匹配的内容,$n捕获的原子组,从左向右数括号即可 |
String方法 |
| split | 一个使用正则表达式或者一个固定字符串分隔一个字符串,分隔子字符串到数组。 | String方法 |
exec
var reg = /\d+/g;
var str = 'a1b2c3d4f5e6';
var result;
var arr = [];
while (result = reg.exec(str)) {
arr.push(result);
}
console.table(arr);
正则表达式标志
| 标志 | 描述 |
|---|---|
| g | 全局搜索。 |
| i | 不区分大小写搜索。 |
| m | 多行搜索。(每一行单独处理) |
| y | 执行“粘性”搜索,匹配从目标字符串的当前位置开始,可以使用y标志。 |
| s | 允许 . 匹配换行符。 |
| u | 使用unicode码的模式进行匹配。(匹配宽字节) |
字符属性 \p{exp}
// 所有汉字
"asdf123.你发,好虚!".match(/\p{sc=Han}/gu)
(4) ["你", "发", "好", "虚"]
// 所有数字
"asdf123.你发,好虚!".match(/\p{N}/gu)
(4) ["你", "发", "好", "虚"]
// 所有标点
"asdf123.你发,好虚!".match(/\p{P}/gu)
(3) [".", ",", "!"]
// 所有字母 (含汉字)
"asdf123.你发,好虚!".match(/\p{L}/gu)
(8) ["a", "s", "d", "f", "你", "发", "好", "虚"]
// 所有字母 (含汉字)和数字
"asdf123.你发,好虚!".match(/[\p{N}\p{L}]/gu)
(8) ["a", "s", "d", "f", "你", "发", "好", "虚"]
// \P{L} 或 [^\p{L}] // 所有非字母
// \P{N} 或 [^\p{N}] // 所有非数字
最后可能有的童鞋还是习惯正规点的 官方文档
?
匹配前面一个表达式0次或者1次。等价于 {0,1}。
例如,/e?le?/ 匹配 “angel” 中的 ‘el’,和 “angle” 中的 ‘le’ 以及"oslo’ 中的’l’。
如果紧跟在任何量词 *、 +、? 或 {} 的后面,将会使量词变为非贪婪的(匹配尽量少的字符),和缺省使用的贪婪模式(匹配尽可能多的字符)正好相反。
例如,对 “123abc” 应用 /\d+/ 将会返回 “123”,如果使用 /\d+?/,那么就只会匹配到 “1”。
还可以运用于先行断言,如本表的 x(?=y) 和 x(?!y) 条目中所述。
(x)
匹配 ‘x’ 并且记住匹配项,就像下面的例子展示的那样。括号被称为 捕获括号。
模式/(foo) (bar) \1 \2/中的 ‘(foo)’ 和 ‘(bar)’ 匹配并记住字符串 “foo bar foo bar” 中前两个单词。模式中的 \1 和 \2 匹配字符串的后两个单词。注意 \1、\2、\n 是用在正则表达式的匹配环节。在正则表达式的替换环节,则要使用像 $1、 2 、 2、 2、n 这样的语法,例如,‘bar foo’.replace( /(…) (…)/, ‘$2 $1’ )。
(?:x)
匹配 ‘x’ 但是不记住匹配项。这种叫作非捕获括号,使得你能够定义为与正则表达式运算符一起使用的子表达式。来看示例表达式 /(?:foo){1,2}/。如果表达式是 /foo{1,2}/,{1,2}将只对 ‘foo’ 的最后一个字符 ’o‘ 生效。如果使用非捕获括号,则{1,2}会匹配整个 ‘foo’ 单词。
x(?=y)
匹配’x’仅仅当’x’后面跟着’y’.这种叫做正向肯定查找。
例如,/Jack(?=Sprat)/会匹配到’Jack’仅仅当它后面跟着’Sprat’。/Jack(?=Sprat|Frost)/匹配‘Jack’仅仅当它后面跟着’Sprat’或者是‘Frost’。但是‘Sprat’和‘Frost’都不是匹配结果的一部分。
x(?!y)
匹配’x’仅仅当’x’后面不跟着’y’,这个叫做正向否定查找。
例如,/\d+(?!.)/匹配一个数字仅仅当这个数字后面没有跟小数点的时候。正则表达式/\d+(?!.)/.exec(“3.141”)匹配‘141’但是不是‘3.141’
参考:
JS正则表达式解析URL(协议/域名/端口/路径/参数/锚点)