基于web的HA集群管理套件RHCS
基于web的HA集群管理套件RHCS
关于RHCS:
Red Hat Cluster Suite即红帽集群套件,它是一套综合的软件组件,可以通过在部署时采用不同的配置,以满足对高可用性,负载均衡,可扩展性,文件共享和节约成本的需要。REDHAT公司在2007年发布RHEL5时,就将原本作为独立软件发售的用于构建企业级集群的集群套件RHCS集成到了操作系统中一同发布。
RHCS提供如下两种不同类型的集群:
应用/服务故障切换——通过创建N个节点的服务器集群来实现关键应用和服务的故障切换
IP负载均衡——对一群服务器上收到的IP网络请求进行负载均衡
RHCS in RHEL6:
在RHEL6上RHCS定义高可用资源架构的更加明晰,完全借助于类似corosync的机制,cman不再借助于openAIS,而是借助于corosync;资源管理完全借助于rgmanager,在rgmanager内部就可以完成资源配置同步传递,取消了ccsd,将资源管理的配置与基础信息架构层的配置分开,将lock_dlmd整合进dlm_controld中统一实现;对GFS文件系统管理使用gfs_controld这个独立组件完成,gfs_controld是RHCS专门为管理GFS文件系统提供的一个优化控制进程,而对OCFS的管理使用dlm_controld,如果用不到集群文件系统,可以不启动这个两个组件,只需要cman和rgmanage即可。
RHCS组件说明:
CMAN: Cluster manager是一个分布式集群管理工具,运行在集群的各个节点上,为RHCS提供集群管理任务。它用于管理集群成员、消息和通知。它通过监控每个节点的运行状态来了解节点成员之间的有关系。当集群中某个节点出现故障时,节点成员关系将发生改变,CMAN及时将这种改变通知底层,进而做出相应的调整。CMAN根据每个节点的运行状态,统计出一个法定节点数,作为集群是否存活的依据。当整个集群中有多于一半的节点处于激活状态时,表示达到了法定节点数,此集群可以正常运行,当集群中有一半或少于一半的节点处于激活状态时,表示没有达到法定的节点数,此时整个集群系统将变得不可用。CMAN依赖于CCS,并且CMAN通过CCS读取cluster.conf文件。
rgmanager: Resource Group Manager主要用来监督、启动、停止集群的应用、服务和资源,与cman一样,rgmanager也是RHCS中的一个核心服务,可通过系统中的serivce命令进行启/停操作;当一个节点的服务失败时,rgmanager提供自动透明的Failover错误切换功能:可以将服务从失败节点转移至其它健康节点。RHCS通过rgmanager来管理集群服务,rgmanager运行在每个集群节点上,在服务器上对应的进程为clurgmgrd。
搭建环境
1、集群:server7 172.25.68.7
server8 172.25.68.8
用server7搭建web界面
2、时间同步(集群节点心跳一致,corosync机制)
3、安装集群管理套件
配置本地yum源
vim /etc/yum.repos.d/rhel-source.repo
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.68.250/rhel6.5/HighAvailability/
enabled=1
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.68.250/rhel6.5/ResilientStorage
enabled=1
gpgcheck=0
[LoadBalancer]
name=LoadBalancer
baseurl=http://172.25.68.250/rhel6.5/LoadBalancer
enabled=1
gpgcheck=0
[ScalableFileSystem]
name=ScalableFileSystem
baseurl=http://172.25.68.250/rhel6.5/ScalableFileSystem
enabled=1
gpgcheck=0
配置第一个集群节点(server7)
luci是基于web的图形化的集群管理界面
yum install ricci luci -y
passwd ricci
/etc/init.d/ricci start
/etc/init.d/luci start
要设置开机自启,否则后面当节点重启会出问题
chkconfig ricci on
chkconfig luci on
netstat -antlp
tcp 0 0 :::11111 :::* LISTEN 1205/ricci
另一个集群节点(server8)安装ricci
yum install ricci -y
passwd ricci
/etc/init.d/ricci start
chkconfig ricci on #设置开机自启
netstat -antlp
tcp 0 0 :::11111 :::* LISTEN 1210/ricci
浏览器访问 https://172.25.68.7:8084
root身份登陆进入HA集群管理界面

一、创建集群,添加servr1,server4到集群中
注意:
由于创建集群的时候会有reboot的动作,所以要设置ricci,luci为开机自启
/etc/hosts 添加域名解析
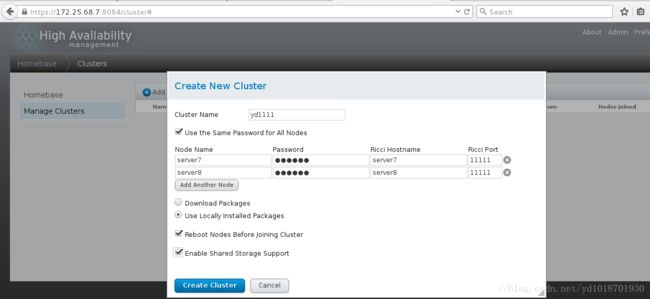
Download Packages :启动时根据yum源自动更新rhcl
Use Locally Installed Packages :在本地安装需要的软件,不进行更新
ps ax 创建集群的时候自动在本地安装软件
1270 ? D 0:06 /usr/bin/python /usr/bin/yum -y install cman rgmanager l
用clustat命令查看集群的状态

二、添加Fence Device
问题: 在高可用集群节点之间会有网络设备,当网络设备,或者节点网卡出问题时,节点之间发送的心跳报文无法到达,则备机就会认为主节点挂掉,则自身提升为主机,将资源抢夺过来,这样当主节点恢复时,会发生”脑裂”
解决方案: 添加FenceDevice,解决脑裂问题,当某个节点出现问题时,强制重启该设备,避免该结点恢复发生资源抢夺问题
关于Fence:
Fence主要就是通过服务器或存储本身的硬件管理接口,又或者是外部电源管理设备,来对服务器或存储发起直接的硬件管理指令,控制服务器或存储链路的开关。因此,Fence机制也被称为”I/O屏障”技术。当CMAN确定一个节点离线后,它在集群结构中通告这个问题节点,fenced进程将问题节点隔离,彻底断开问题节点的所有I/O连接,防止问题节点破坏共享数据,严格保证集群环境中企业核心数据的完整性。它可以避免因出现不可预知的情况而造成的“脑裂”现象。Split-Brain(脑裂)是指当两个节点之间的心跳线中断时,两台主机都无法获取对方的信息,此时两台主机都认为自己是主节点,于是对集群资源(共享存储,公共IP地址)进行争用抢夺。
Fence工作原理: 当意外原因导致主机异常或宕机时,备用机会首先调用fence设备,然后通过fence设备将异常的主机重启或从网络上隔离,释放异常主机占据的资源,当隔离操作成功后,返回信息给备用机,备用机在接到信息后,开始接管主机的服务和资源。
1、安装fence插件
[root@foundation68 ~]# rpm -qa | grep fence
libxshmfence-1.2-1.el7.x86_64
fence-virtd-0.3.2-2.el7.x86_64
fence-virtd-multicast-0.3.2-2.el7.x86_64
fence-virtd-libvirt-0.3.2-2.el7.x86_64
[root@foundation68 ~]# yum install -y fence-virtd-0.3.2-2.el7.x86_64 fence-virtd-multicast-0.3.2-2.el7.x86_64 fence-virtd-libvirt-0.3.2-2.el7.x86_64
2、配置(初始化)fence
[root@foundation68 ~]# fence_virtd -c
这里修改接口和key file的路径,其他的选择默认
Interface [br0]:
Key File [/etc/cluster/fence_xvm.key]:
3、完成初始化配置之后需要创建一个key
[root@foundation68 cluster]# dd if=/dev/urandom of=fence_xvm.key bs=128 count=1
1+0 records in
1+0 records out
128 bytes (128 B) copied, 0.000388778 s, 329 kB/s
[root@foundation68 cluster]# ls
fence_xvm.key
4、把创建好的key发送给server7和server8两个节点
[root@foundation68 cluster]# scp fence_xvm.key root@server7:/etc/cluster/
[root@foundation68 cluster]# scp fence_xvm.key root@server8:/etc/cluster/
5、进入集群管理的web界面
(1)点击你所创建的集群名字,进去之后点击Node,选择任意节点,进去点击add fence method,给fence起个名
(2)添加自定义fence设备类型
点击你所创建的集群名字,进去设置fence Device如下图

(3)成功之后回到第一步,点击add fence instance
这里的domain写的是uuid,如果节点名和域名一样的话,这里也可以写域名,比如我这里可以server7

注:以上动作各个节点都要做
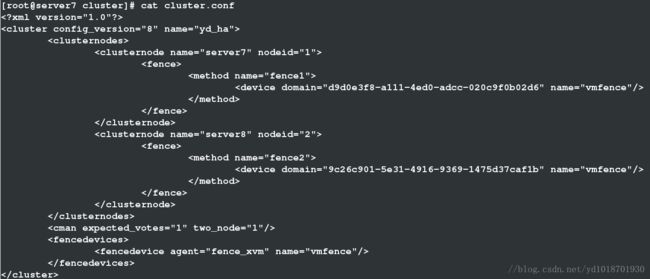
(4)查看配置文件
(5)测试:
[root@server7 cluster]# fence_node server8
fence server8 success
[root@server8 cluster]# vim /etc/sysconfig/network
[root@server8 cluster]# Write failed: Broken pipe
重启后集群恢复
[root@server8 ~]# clustat
Cluster Status for yd_ha @ Fri May 4 17:15:49 2018
Member Status: Quorate
Member Name ID Status
—— —- —- ——
server7 1 Online
server8 2 Online, Local
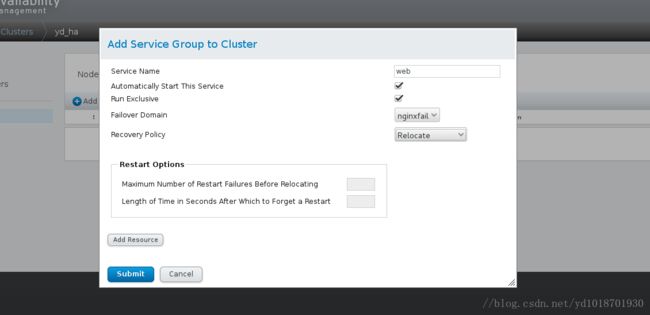
三、添加failover domain,起名(任意)为nginxfail
Failover Domain: 与服务相关,Failover Domain指定了集群中某个节点故障以后,该节点上的Service和Resource所能够转移的目标节点,进而限定了一个Resource能够转移的节点范围,可以理解为服务的故障转移域;每个Node都允许与多个Failover Domain进行绑定,也就是说每个Node都可以为多个Service服务,因此可以实现双主方式的集群配置。RHCS中一个服务必须要定义Failover Domain,在定义故障转移域前要定义好故障发生时的优先动作,是先重启服务还是进行转移,在定义故障转移域时可以按照节点在故障转移域中的次序设定转移的优先级,如果没有设置优先,集群高可用服务可在转移域内的任意节点间转移。

四、添加资源
1、添加虚拟ip

2、添加nginx,我们用脚本方式配置nginx

3、整合服务组

我们发现此时nginx服务运行在server7 (running on server7)
查看:
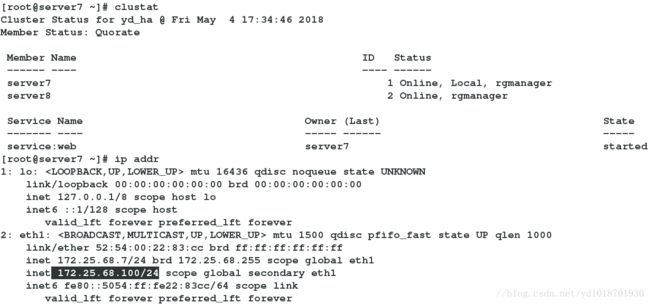
之前添加的虚拟ip也在server7上
测试:
关闭server7上正在运行的nginx,然后等待15s左右在server8上查看集群状态

web服务running on server8 & ip飘移过来说明成功