Python爬虫初学四(Ajax&selenium爬虫)
目录
一、什么是Ajax
二、Ajax的来由
三、Ajax如何分析页面
四、案例(基于Ajax和requests的的微博采集器)
五、selenium的使用
1.什么是selenium?
2.Selenium的使用
一、什么是Ajax
Ajax(Asynchronous JavaScript and XML)异步的JS和XML。原理是: 利用JS在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
AJAX = 异步 JavaScript 和 XML。
AJAX 是一种用于创建快速动态网页的技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
传统的网页(不使用 AJAX)如果需要更新内容,必需重载整个网页面。
有很多使用 AJAX 的应用程序案例:新浪微博、Google 地图、开心网等等。
二、Ajax的来由
1.浏览器中可看到正常显示的数据,但使用requests得到的结果并没有。 这是什么原因呢?
requests获取的是原始的HTML文档,而浏览器中的页面是经过JS处理数据后生成的结果。
2.这些数据的来源有哪些情况呢?
Ajax加载、包含在HTML文档中、经过JavaScript和特定算法计算后生成。
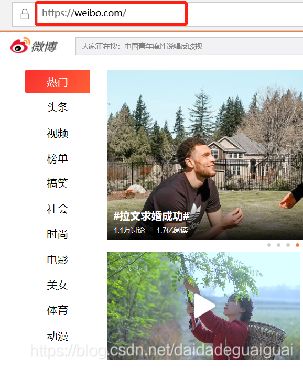

三、Ajax如何分析页面
拖动刷新的内容由Ajax加载且页面的URL无变化,那么可以去哪里查看这些Ajax请求?
- 开发者工具(F12)->Network选项卡, 获取页面加载过程中Browser与Server之间请求和响应。
- 筛选出所有的Ajax请求。在请求的上方有一层筛选栏,直接点击XHR(Ajax特殊的响应类型)
- 模拟Ajax请求,提取我们所需要的信息。
- 打开Ajax的XHR过滤器,然后一直滑动页面以加载新的微博内容。可以看到,会不断有Ajax请求发出。请求的参数有4个:type、value、containerid和page。
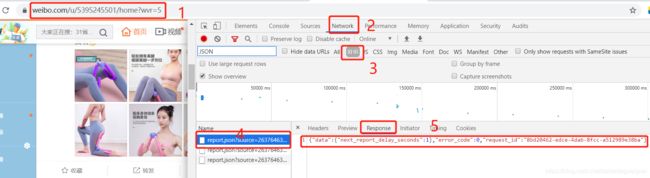

四、案例(基于Ajax和requests的的微博采集器)
项目描述
本项目爬取的目标是新浪微博指定用户的公开基本信息,如用户昵称、头像、用户的关注、粉丝列表以及发布的微博等,这些信息抓取之后保存至 MySQL。
项目技能点
Requests + Ajax(XHR) + Json解析 Scrapy + Ajax(XHR) + Json解析 + SpiderKeeper可视化工具
import os
import requests
from colorama import Fore
from fake_useragent import UserAgent
from requests import HTTPError
def download_page(url, parmas=None):
"""
根据url地址下载html页面
:param url:
:param parmas:
:return: str
"""
try:
ua = UserAgent()
headers = {
'User-Agent': ua.random,
}
# 请求https协议的时候, 回遇到报错: SSLError
# verify=Flase不验证证书
response = requests.get(url, params=parmas, headers=headers)
except HTTPError as e:
print(Fore.RED + '[-] 爬取网站%s失败: %s' % (url, str(e)))
return None
else:
# content返回的是bytes类型, text返回字符串类型
# response.json()方法会自动将字符串反序列为python数据类型
"""
html = response.text # 字符串
json.loads(html) # 将字符串反序列化为python数据类型
"""
# return response.json()
return response
def parse_html(html):
"""
参考源代码解析
:param html:
:return:
"""
cards = html.get('data').get('cards')
count = 0
for card in cards:
try:
count += 1
text = card['mblog'].get('text')
pics = card['mblog'].get('pics')
# todo: 1. 对于博客正文的内容进行处理: 删除标签(正则+re.sub)
print("第%s篇微博正文内容: %s" % (count, text))
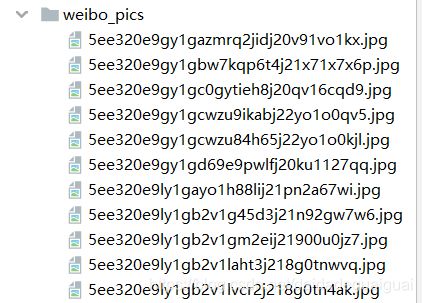
if pics:
for index, pic in enumerate(pics):
pic_url = pic.get('url')
pic_content = download_page(pic_url).content
# 图片网址-> 图片名称 https://wx1.sinaimg.cn/orj360/005N3SJDly1fyhlxakcj3j30dc0dcaa4.jpg
img_fname = os.path.join('weibo_pics', pic_url.split('/')[-1])
with open(img_fname, 'wb') as f:
f.write(pic_content)
print("下载第[%s]张图片成功" % (index + 1))
except Exception as e:
print("下载博客失败: %s" % (str(e)))
if __name__ == '__main__':
uid = input("请输入你要爬取微博博主的uid:")
for page in range(10):
url = 'https://m.weibo.cn/api/container/getIndex?uid=%s&type=uid&containerid=107603%s&page=%s' % (
uid, uid, page)
html = download_page(url).json()
parse_html(html)
测试结果:

五、selenium的使用
1.什么是selenium?
- Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
- 框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。
- 使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。使用简单,可使用Java,Python等多种语言编写用例脚本。
- 利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些JavaScript动态渲染的页面来说,此种抓取方式非常有效。
2.Selenium的使用
1. 动态渲染页面爬取
JS动态渲染的页面不止Ajax一种,有些网站,不能直接分析Ajax来抓取(会有一些加密解密算法),难以直接找出其规律
例如:中国青年网:页面由JS生成但不包含Ajax请求
ECharts:图形都是经过JS计算之后生成
淘宝网:其Ajax接口含有很多加密参数
那么如何解决这些问题?
直接使用模拟浏览器运行的方式实现,可见即可爬,Python提供了模拟浏览器运行的库:Selenium、Splash、PyV8、Ghost等
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作。同时,还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些JavaScript动态渲染的页面来说,此种抓取方式非常有效。但是它的速度很慢,不推荐使用
在使用时要先声明浏览器对象
Selenium支持很多的浏览器,Chrome、Firefox、Edge等,还有Android、BlackBerry等手机端浏览器。另外,也支持无界面浏览器PhantomJS.
通过对象,向浏览器发起请求
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()关键:运行后,弹出Chrome浏览器
注意,需要安装浏览器驱动,火狐、谷歌都行
https://github.com/mozilla/geckodriver/releases
https://npm.taobao.org/mirrors/chromedriver/2.41/
将下载好的chromedriver.exe放入Python安装路径下的Script文件夹内
例如:通过selenium爬虫直接跳转至“python”关键词搜索的地方
import time
from selenium import webdriver
# 1). 通过浏览器驱动打开浏览器
# 注意点: 下载驱动器文件到本地, 并移动到 (当前Python环境目录\Scripts\驱动文件), 当前的Python环境目录如何获取? where python
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()
# 2). 通过浏览器访问网址
browser.get('https://www.baidu.com')
# 2-1). 节点查找: 根据id=wd查找我们输入的表框对象
input = browser.find_element_by_id('kw')
input.send_keys('python')
input.send_keys(Keys.ENTER)
time.sleep(15)
# 3) 关闭浏览器
browser.close()
测试结果:

这里 是直接跳转的,,,
