企业网络订单的异常检测项目
项目:企业网络订单的异常检测
一、项目背景与挖掘目标
企业或平台在销售商品的过程中,常常会遇到一些异常订单,例如黄牛订单、恶意订单、商家刷单等。
此项目的目的是找到非普通用户的订单记录,即识别订单的异常状态。
二、项目数据介绍
1.案例数据是某企业的部分订单,以下是数据概况:
(1)特征变量数:13
(2)数据记录数:134190
(3)是否有NA值:有
(4)是否有异常值:有
2. 以下是数据集的13个特征变量的详细说明:
(1)order_id:订单ID,有数字组合而成,例如4283851335
(2)order_date:订单日期,格式为YYYY-MM-DD,例如2013-10-17
(3)order_time:订单日期,格式为HH:MM:SS,例如12:54:44
(4)cat:商品一级类别,字符串类型,包含中英文
(5)attribution:商品所属的渠道来源,字符串型,包含中英文
(6)pro_id:商品ID,数字组合而成
(7)pro_brand:商品品牌,字符串型,包含中英文
(8)total_money:商品销售金额,浮点型
(9)total_quantity:商品销售数量,整数型
(10)ordera_source:订单来源,从哪个渠道形成的销售,字符串型,包含中英文
(11)pay_type:支付类型,字符串型,包含中英文
(12)use_id:用户ID,由数字和字母等组成的字符串
(13)city:用户下订单时的城市,字符串型,中文
(14)目标变量:abnormal_label,代表该订单记录是否是异常订单
三.代码展示
#一、导包
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder #将分类变量转为数值变量
from imblearn.over_sampling import SMOTE #过抽样处理,均衡样本
from sklearn.model_selection import train_test_split
from sklearn.ensemble import VotingClassifier, GradientBoostingClassifier, RandomForestClassifier # 集成分类库和投票方法库
from sklearn.naive_bayes import GaussianNB
from sklearn import neighbors #k近邻
from sklearn.model_selection import StratifiedKFold, cross_val_score # 导入交叉检验算法
from sklearn.model_selection import GridSearchCV #网格搜索(调参利器)
import matplotlib as plt
%matplotlib inline
from pylab import *
mpl.rcParams['font.sans-serif']= ['SimHei'] #画图时中文无法正常显示的解决
import warnings
warnings.filterwarnings('ignore') # 不发出警告
#二、读取文件
abnormal_orders=pd.read_table(r'E:\abnormal_orders.txt',sep=',')
print(abnormal_orders.head(5))
#order_id作为订单ID号,无重复数值,类似于常数列,故删除该列
abnormal_orders.drop('order_id',axis=1,inplace=True)
| order_id | order_date | order_time | cat | attribution | pro_id | pro_brand | total_money | total_quantity | order_source | pay_type | user_id | city | abnormal_label |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4277880103 | 2013-10-17 | 13:09:16 | NaN | GO | 8000001215 | NaN | 1000.0 | 1000 | 游戏站点 | 当当支付 | murongchun | 北京市 | 0 |
| 4283851335 | 2013-09-23 | 14:09:49 | 手机摄影数码 | POP | 8002042497 | 三星 | 766000.0 | 200 | 主站 | 合并支付 | dakehu_zy | 上海市 | 1 |
| 4277700101 | 2013-08-27 | 14:26:38 | NaN | GO | 7000000960 | 国之美艺术品 | 8000.0 | 160 | do.site_id | 在线支付 | 1391175862 | NaN | 1 |
| 4276537082 | 2013-09-11 | 14:16:47 | 电视冰箱洗衣机空调 | POP | 8001992420 | 樱花 | 19900.0 | 100 | 主站 | 合并支付 | qq-3be293b | 泉州市 | 1 |
| 4281111595 | 2013-04-10 | 10:44:46 | 家具建材 | POP | 8002199518 | 纬度空间 | 100.0 | 100 | 主站 | 合并支付 | nonscorpio | 广州市 | 1 |
通过观察,数据中有三列数据商品id、用户id、订单id较为特殊,均属于唯一标识可用于辨别用户和商品,而订单id与剩下两者有交叉较为重复,故选择删除订单id这一列特征。
# 三、空值预处理
# 1.检测哪一列特征数据中有空值
abnormal_orders_null=abnormal_orders.isnull().any()
#2.获取空值所在列
abnormal_orders_null_col=abnormal_orders_null[abnormal_orders_null==True]
print(abnormal_orders_null_col)
# 3.统计每一列的空值数量
abnormal_orders_null_count=abnormal_orders.isnull().sum()
print(abnormal_orders_null_count)
#4.统计总的缺失记录条数
abnormal_orders_null_sum=abnormal_orders.isnull().any(axis=1).sum()
print(abnormal_orders_null_sum)
# 5.删除空值所在的行
abnormal_orders.dropna(inplace=True) #由于空值非数值型变量,故整体删除
# 6.恢复默认索引
abnormal_orders.reset_index(drop=True,inplace=True)
获取空值所在列
| columns | isnull |
|---|---|
| cat | True |
| pro_brand | True |
| total_money | True |
| city | True |
统计每一列的空值数量
| columns | nums |
|---|---|
| order_date | 0 |
| order_time | 0 |
| cat | 1390 |
| attribution | 0 |
| pro_id | 0 |
| pro_brand | 772 |
| total_money | 1 |
| total_quantity | 0 |
| order_source | 0 |
| pay_type | 0 |
| user_id | 0 |
| city | 2 |
| abnormal_label | 0 |
总的缺失记录条数:1429
对于缺失值的处理策略分三种,填充,不做处理,或者丢弃,没有固定的标准,一般而言如果后续模型支持空值(如XGBoost模型),一般选择不处理.如果空值样本比例小,可以丢弃或者填充都可以.如果空值比例较大,一般需要做填充处理.
通过对每一列进行空值检测,发现商品一级类别里有1390个空值,商品品牌里有772个空值,消费金额里有1个空值,城市特征里有2个空值。
空值数量1429,相对于总样本数量134190条,缺失值数量仅占1%,故选择dropna直接删除空值所在的行。
# 四.将分类变量转换为数值型变量
# 1.选取分类变量所在的列,并将其转为数值型变量
columns=['cat','attribution','pro_brand','order_source','pay_type','user_id','city']
abnormal_orders_labels=abnormal_orders[columns].apply(LabelEncoder().fit_transform)
# 2.替换原来的分类数据列,将其变为数值型数据
abnormal_orders[columns]=abnormal_orders_labels
或者以上代码可以用下面代码代替:
# 1.选取分类变量所在的列,并将其转为数值型变量
columns=['cat','attribution','pro_brand','order_source','pay_type','user_id','city']
#2.建立模型
ode=OrdinalEncoder()
#3.替换原来的分类数据列,将其变为数值型数据
abnormal_orders[columns]=ode.fit_transform(abnormal_orders[columns])
由于特征中含有中文或英文,为方便计算机分析特征,故将其转换为数字编码。
这里有两种可以将字符串数据转换为数值型数据的方法:
preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值;
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值.
# 五.拆分时间序列
# 1.将周、月、日数据分割出来并添加至数据框中
time_data1=[pd.datetime.strptime(dates,'%Y-%m-%d') for dates in abnormal_orders['order_date']]
abnormal_orders['time_week']=[data.weekday() for data in time_data1]
abnormal_orders['time_month']=[data.month for data in time_data1]
abnormal_orders['time_day']=[data.day for data in time_data1]
# 2.将时、分、秒数据分割出来并添加至数据框中
time_data2=[pd.datetime.strptime(dates,'%H:%M:%S') for dates in abnormal_orders['order_time']]
abnormal_orders['time_hour']=[data.hour for data in time_data2]
abnormal_orders['time_minute']=[data.minute for data in time_data2]
abnormal_orders['time_second']=[data.second for data in time_data2]
# 3.删除时间列
abnormal_orders.drop(columns=['order_date','order_time'],axis=1,inplace=True)
# 4.将abnormal_label列移至最后一列
a_label=abnormal_orders['abnormal_label']
abnormal_orders.drop('abnormal_label',axis=1,inplace=True)
abnormal_orders['abnormal_label']=a_label.values
根据特征工程中特征的处理原则,需要将数据集中的日期和时间加以处理,一般用的较多的处理方法就是根据时间所在的年,月,日,周,小时数,分数,秒数.将一个时间特征转为多个离散特征.
针对日期的处理:
time_data1对象是通过列表推导式,从abnormal_orders[‘order_date’]获取每个数据值,然后使用pd.datetime.strptime(dates,’%Y-%m-%d’)将其转化为pandas的日期格式,在通过weekday(),day,month,等函数将日期数据转换为周几,当月几号,和月份.
针对时间数据的处理与以上类似.
日期和时间数据处理完成后,将原始数据中的order_date和order_time两列删除.
# 六.各特征间的相关性分析
x=abnormal_orders.iloc[:,:-1]
correlation_matrix = np.corrcoef(x,rowvar=0)
#print(correlation_matrix.round(2))
# 相关性可视化
fig,axe=plt.subplots(1,1,figsize=(6,6),dpi=100)
hot_img = axe.matshow(np.abs(correlation_matrix),vmin=0,vmax=1)#绘制热力图,值域从0到1
fig.colorbar(hot_img)#生成颜色渐变条
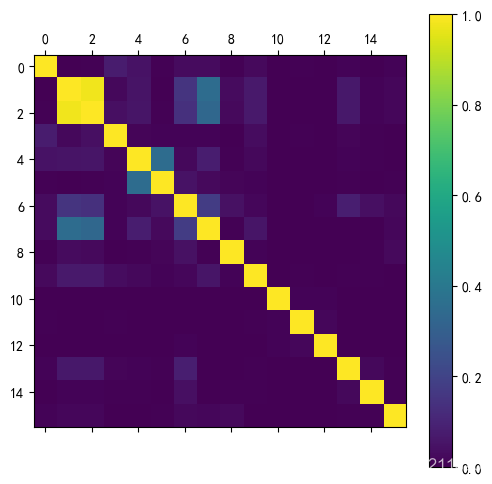
可以看出各列特征之间相关性很弱,且特征数量较少共13个,故不采取降维处理
#七.数据过抽样处理
#1,划分数据集与目标集
X,y=abnormal_orders.iloc[:,:-1],abnormal_orders.iloc[:,-1]
#2.目标集两类别对应的数量
print(y.value_counts())
model_smote=SMOTE()#建立过抽样模型
x_smote,y_smote=model_smote.fit_sample(X,y)
#3.使用SMOTE算法过抽样处理后的两类别数量
print(y_smote.value_counts())
过抽样处理前:
| classes | nums |
|---|---|
| 0 | 104477 |
| 1 | 28284 |
过抽样处理后:
| classes | nums |
|---|---|
| 1 | 104477 |
| 0 | 104477 |
# 八.切割训练集和测试集
X_train,X_test,y_train,y_test=train_test_split(x_smote,y_smote,test_size=0.3,random_state=101)
切分训练集和测试集,测试集占比30%.
# 九.模型训练(默认参数)
rf = RandomForestClassifier(random_state=0)
gbdt = GradientBoostingClassifier(random_state=0)
knn = neighbors.KNeighborsClassifier(n_neighbors = 6 , weights='distance',leaf_size=10)
bayes = GaussianNB()
estimators=[('randomforest',rf),('gradientboosting',gbdt),('kneighborsclassifier',knn),('bayes',bayes)]
vot = VotingClassifier(estimators=estimators,voting='soft',n_jobs=-1)
vot.fit(X_train1, y_train1) # 训练集训练模型
print(vot.score(X_train1, y_train1))#模型拟合训练集评分
vot.score(X_test1, y_test1)#模型拟合测试集评分
模型评判分数:
1.0
0.851037695215914
这里随机森林和GBDT模型仅仅使用默认参数建立的模型,使用GridSearchCV调参耗时太长.
朴素贝叶斯的高斯模型参数基本不用调节,直接建模使用即可.
knn模型使用以下代码进行调参,返回最佳参数如下
#3. knn模型调参
param_test3 = {'n_neighbors' : range(1,20,5) ,'leaf_size':range(10,50,10)}
gsearch3 = GridSearchCV(estimator = neighbors.KNeighborsClassifier(weights='distance'),
param_grid = param_test3, scoring='roc_auc',cv=5)
gsearch3.fit(x_smote, y_smote)
print(gsearch3.best_params_,gsearch3.best_score_)
最佳参数和最佳评分
{‘leaf_size’: 10, ‘n_neighbors’: 6} 0.8251097204656013
这里使用投票法建立模型,集成各个模型的预测结果,对数据集进行预测.这里属于集成学习方法,具体参考集成学习方法-VotingClassifier
鉴于运行效率,并没有运行完此部分代码,只是为了展示调参的思想
# 1.随机森林调参
param_test1 = {'n_estimators':range(50,200,10),'max_depth':range(1,10,2)}
gsearch1 = GridSearchCV(estimator = RandomForestClassifier(min_samples_split=100,min_samples_leaf=20,max_features=None ,random_state=10),
param_grid = param_test1, scoring='roc_auc',cv=5)
gsearch1.fit(x_smote, y_smote)
print(gsearch1.best_params_,gsearch1.best_score_)
# 2.GBDT调参
param_test2 = {'n_estimators':range(20,81,10),'max_depth':range(1,10,2),'min_samples_split':range(400,1900,200), 'min_samples_leaf':range(60,101,10)}
gsearch2 = GridSearchCV(estimator = GradientBoostingClassifier(random_state=10),
param_grid = param_test2, scoring='roc_auc',cv=5)
gsearch2.fit(x_smote, y_smote)
print(gsearch2.best_params_,gsearch2.best_score_)
# 十.交叉验证测试集成方法voting得分
cv = StratifiedKFold(5, random_state=2) # 设置交叉检验方法
cv_score1 = cross_val_score(vot, X_train1, y_train1, cv=cv) # 交叉检验
print('{:*^60}'.format('Cross val scores:'),'\n',cv_score1) # 打印每次交叉检验得分
print('Mean scores is: %.2f' % cv_score1.mean()) # 打印平均交叉检验得分
*********************Cross val scores:
[0.84815752 0.84354276 0.84210166 0.84634055 0.84565686]
Mean scores is: 0.85
StratifiedKFold分层采样,用于交叉验证:与KFold最大的差异在于,StratifiedKFold方法是根据标签中不同类别占比来进行拆分数据的。具体参考交叉验证两种采样方法的区别
使用sklearn中的cross_val_score方法对模型进行交叉验证,具体作用是用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合。具体参考cross_val_score用法
# 十一、预测新数据集
# 1.读取新数据集
data_x_new = pd.read_csv(r'E:\new_abnormal_orders.csv')
# 2.删除订单id列
data_x_new = data_x_new.drop(['order_id'],axis=1)
# 3.标签化
# 3.1.选取分类变量所在的列,并将其转为数值型变量
data_x_new_labels=data_x_new[['cat','attribution','pro_brand','order_source','pay_type','user_id','city']].apply(LabelEncoder().fit_transform)
# 3.2.替换原来的分类数据列,将其变为数值型数据
data_x_new[['cat','attribution','pro_brand','order_source','pay_type','user_id','city']]=data_x_new_labels
data_x_new
# 4.时间序列处理
# 4.1.将周、月、日数据分割出来并添加至数据框中
time_data3=[pd.datetime.strptime(dates,'%Y/%m/%d') for dates in data_x_new['order_date']]
data_x_new['time_week']=[data.weekday() for data in time_data3]
data_x_new['time_month']=[data.month for data in time_data3]
data_x_new['time_day']=[data.day for data in time_data3]
# 4.2.将时、分、秒数据分割出来并添加至数据框中
time_data4=[pd.datetime.strptime(dates,'%H:%M:%S') for dates in data_x_new['order_time']]
data_x_new['time_hour']=[data.hour for data in time_data4]
data_x_new['time_minute']=[data.minute for data in time_data4]
data_x_new['time_second']=[data.second for data in time_data4]
# 4.3.删除时间列
data_x_new.drop(columns=['order_date','order_time'],axis=1,inplace=True)
# 5.预测
predict_y=vot.predict(data_x_new)#预测数据的类别
predict_proba=vot.predict_proba(data_x_new)#预测数据归为0类或1类的概率
predict=np.hstack((predict_y.reshape(-1,1),predict_proba))
predict_final=pd.DataFrame(predict,columns=['predict','proba_0','proba_0_1'])
predict_final
| num | predict | proba_0 | proba_0_1 |
|---|---|---|---|
| 0 | 1.0 | 0.488756 | 0.511244 |
| 1 | 0.0 | 0.629079 | 0.370921 |
| 2 | 0.0 | 0.623792 | 0.376208 |
| 3 | 0.0 | 0.646604 | 0.353396 |
| 4 | 0.0 | 0.661104 | 0.338896 |
| 5 | 0.0 | 0.591594 | 0.408406 |
| 6 | 0.0 | 0.561970 | 0.438030 |
这里是预测新数据所属类别及预测类别的机率,即各订单是否属于异常订单.
项目总结:
1.项目可优化的部分:
(1)由于模型训练的时间较长,故大部分直接使用了默认参数,后期如果时间充足可继续优化模型参数。
(2)本模型中直接将四种模型使用voting集成为一个新的模型,但实际上,如果时间充足,可使用gridsearchcv将每一个分类模型参数调到最优,再使用交叉验证计算组合不同模型时的得分,如果其中有些模型得分明显较低则可舍弃,最后选择最优的模型组合。
2.项目注意点:
(1)耗时长,本项目中由于采用了voting集成的思想,故运行时间较长,调参过程也耗时较长。实际工作中,可结合实际情况,采取对应的措施,如时间紧迫,则可采用单个模型进行训练,如时间充足或对模型精度要求较高,则可采用集成思想同时使用多个模型进行训练,也或者可以折中,取两个模型集成。
(2)样本均衡处理:本项目中目标变量的两个类别对应的样本数量有着明显的差别,故要进行样本均衡处理。
2.项目过程中遇到的问题:
(1)本项目过程中遇到的最大的问题是,模型结果的可解释性差,有点类似于黑箱。举个例子,假如业务部门提供给我们这些数据,经过模型训练后,虽然对订单的正常/异常状态做出了预测,但是并不能提供给业务部门清晰的逻辑,比如具备什么样的特征大概率会是异常订单。言而总之,最大的问题是算法的应用和实际情况无法有效衔接起来。
类似于(1)中提到的问题,模型可解释性差,主要原因是算法预测过程的可视化缺失,随机森林虽然可以将每一颗树都可视化出来,但如果树的数量较多的话,那么可解释性也会降低很多。而其他模型的可视化并不了解。
(2)训练集和测试集得分相差较大,暂无解决此问题的思路。
3.项目过程中学到的东西:
(1)在本次项目中最大的收获是,学习到了拿到一个项目后的处理流程。
(2)使用smote进行样本均衡处理,当项目中存在样本类别不均衡的问题时,经过样本均衡处理,可提高模型精度。
(3)使用voting投票模型训练模型,以前大多都是单个模型进行训练,但是在实际工作中(例分类问题),分类模型有很多,经常面临选择哪一个模型的问题,而使用集成的思想,可以集合不同的模型的优点,起到三个“臭皮匠”顶一个诸葛亮的效果,并进一步提升模型的稳定性。