This page provides an overview of Pod, the smallest deployable object in the Kubernetes object model.
- Understanding Pods
- How Pods manage multiple Containers
- Networking
- Storage
- How Pods manage multiple Containers
- Working with Pods
- Pods and Controllers
- Pod Templates
Understanding Pods
This page provides an overview of Pod, the smallest deployable object in the Kubernetes object model.
- Understanding Pods
- How Pods manage multiple Containers
- Networking
- Storage
- How Pods manage multiple Containers
- Working with Pods
- Pods and Controllers
- Pod Templates
Understanding Pods
A Pod is the basic building block of Kubernetes–the smallest and simplest unit in the Kubernetes object model that you create or deploy.
A Pod represents a running process on your cluster.
A Pod encapsulates an application container (or, in some cases, multiple containers), storage resources, a unique network IP, and options that govern how the container(s) should run.
A Pod represents a unit of deployment: a single instance of an application in Kubernetes, which might consist of either a single container or a small number of containers that are tightly coupled and that share resources.
Docker is the most common container runtime used in a Kubernetes Pod, but Pods support other container runtimes as well.
Pods in a Kubernetes cluster can be used in two main ways:
- Pods that run a single container. The “one-container-per-Pod” model is the most common Kubernetes use case; in this case, you can think of a Pod as a wrapper around a single container, and Kubernetes manages the Pods rather than the containers directly.
- Pods that run multiple containers that need to work together. A Pod might encapsulate an application composed of multiple co-located containers that are tightly coupled and need to share resources. These co-located containers might form a single cohesive unit of service–one container serving files from a shared volume to the public, while a separate “sidecar” container refreshes or updates those files. The Pod wraps these containers and storage resources together as a single manageable entity.
The Kubernetes Blog has some additional information on Pod use cases. For more information, see:
- The Distributed System Toolkit: Patterns for Composite Containers
- Container Design Patterns
Each Pod is meant to run a single instance of a given application.
If you want to scale your application horizontally (e.g., run multiple instances), you should use multiple Pods, one for each instance.
In Kubernetes, this is generally referred to as replication. Replicated Pods are usually created and managed as a group by an abstraction called a Controller.
See Pods and Controllers for more information.
How Pods manage multiple Containers
Pods are designed to support multiple cooperating processes (as containers) that form a cohesive unit of service.
The containers in a Pod are automatically co-located and co-scheduled on the same physical or virtual machine in the cluster.
The containers can share resources and dependencies, communicate with one another, and coordinate when and how they are terminated.
Note that grouping multiple co-located and co-managed containers in a single Pod is a relatively advanced use case. You should use this pattern only in specific instances in which your containers are tightly coupled.
For example, you might have a container that acts as a web server for files in a shared volume, and a separate “sidecar” container that updates those files from a remote source, as in the following diagram:
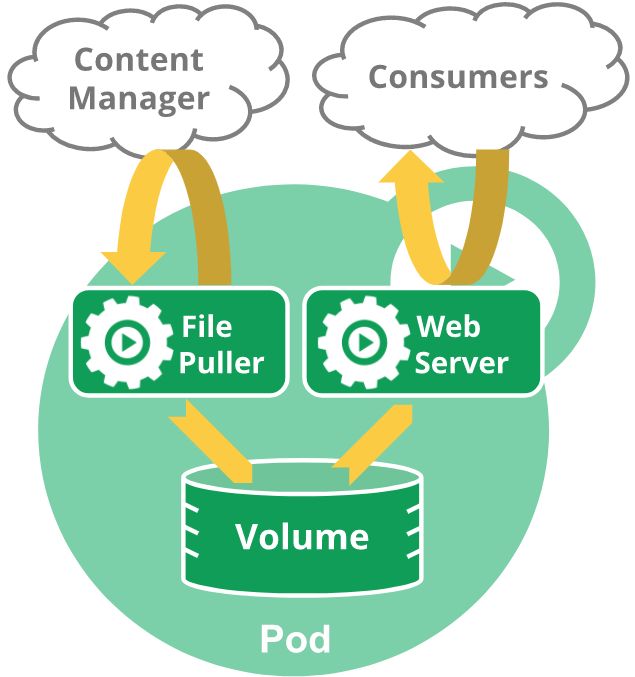
Pods provide two kinds of shared resources for their constituent containers: networking and storage.
Networking
Each Pod is assigned a unique IP address.
Every container in a Pod shares the network namespace, including the IP address and network ports.
Containers inside a Pod can communicate with one another using localhost.
When containers in a Pod communicate with entities outside the Pod, they must coordinate how they use the shared network resources (such as ports).
Storage
A Pod can specify a set of shared storage volumes.
All containers in the Pod can access the shared volumes, allowing those containers to share data.
Volumes also allow persistent data in a Pod to survive in case one of the containers within needs to be restarted.
See Volumes for more information on how Kubernetes implements shared storage in a Pod.
Working with Pods
You’ll rarely create individual Pods directly in Kubernetes–even singleton Pods.
This is because Pods are designed as relatively ephemeral, disposable entities.
When a Pod gets created (directly by you, or indirectly by a Controller), it is scheduled to run on a Node in your cluster. The Pod remains on that Node until the process is terminated, the pod object is deleted, the pod is evicted for lack of resources, or the Node fails.
Note: Restarting a container in a Pod should not be confused with restarting the Pod. The Pod itself does not run, but is an environment the containers run in and persists until it is deleted.
Pods do not, by themselves, self-heal.
If a Pod is scheduled to a Node that fails, or if the scheduling operation itself fails, the Pod is deleted; likewise, a Pod won’t survive an eviction due to a lack of resources or Node maintenance.
Kubernetes uses a higher-level abstraction, called a Controller, that handles the work of managing the relatively disposable Pod instances. Thus, while it is possible to use Pod directly, it’s far more common in Kubernetes to manage your pods using a Controller.
See Pods and Controllers for more information on how Kubernetes uses Controllers to implement Pod scaling and healing.
Pods and Controllers
A Controller can create and manage multiple Pods for you, handling replication and rollout and providing self-healing capabilities at cluster scope.
For example, if a Node fails, the Controller might automatically replace the Pod by scheduling an identical replacement on a different Node.
Some examples of Controllers that contain one or more pods include:
- Deployment
- StatefulSet
- DaemonSet
In general, Controllers use a Pod Template that you provide to create the Pods for which it is responsible.
Pod Templates
Pod templates are pod specifications which are included in other objects, such as Replication Controllers, Jobs, and DaemonSets.
Controllers use Pod Templates to make actual pods.
The sample below is a simple manifest for a Pod which contains a container that prints a message.
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo Hello Kubernetes! && sleep 3600']
Rather than specifying the current desired state of all replicas, pod templates are like cookie cutters.
Once a cookie has been cut, the cookie has no relationship to the cutter. There is no quantum entanglement. Subsequent changes to the template or even switching to a new template has no direct effect on the pods already created.
Similarly, pods created by a replication controller may subsequently be updated directly. This is in deliberate contrast to pods, which do specify the current desired state of all containers belonging to the pod.
This approach radically simplifies system semantics and increases the flexibility of the primitive.
Pods
- What is a Pod?
- Motivation for pods
- Management
- Resource sharing and communication
- Uses of pods
- Alternatives considered
- Durability of pods (or lack thereof)
- Termination of Pods
- Force deletion of pods
- Privileged mode for pod containers
- API Object
pods are the smallest deployable units of computing that can be created and managed in Kubernetes.
What is a Pod?
A pod (as in a pod of whales or pea pod) is a group of one or more containers (such as Docker containers), with shared storage/network, and a specification for how to run the containers.
A pod’s contents are always co-located and co-scheduled, and run in a shared context.
A pod models an application-specific “logical host” - it contains one or more application containers which are relatively tightly coupled — in a pre-container world, they would have executed on the same physical or virtual machine.
While Kubernetes supports more container runtimes than just Docker, Docker is the most commonly known runtime, and it helps to describe pods in Docker terms.
The shared context of a pod is a set of Linux namespaces, cgroups, and potentially other facets of isolation - the same things that isolate a Docker container.
Within a pod’s context, the individual applications may have further sub-isolations applied.
Containers within a pod share an IP address and port space, and can find each other via localhost.
They can also communicate with each other using standard inter-process communications like SystemV semaphores or POSIX shared memory.
Containers in different pods have distinct IP addresses and can not communicate by IPC.
Applications within a pod also have access to shared volumes, which are defined as part of a pod and are made available to be mounted into each application’s filesystem.
In terms of Docker constructs, a pod is modelled as a group of Docker containers with shared namespaces and shared volumes.
Like individual application containers, pods are considered to be relatively ephemeral (rather than durable) entities.
As discussed in life of a pod, pods are created, assigned a unique ID (UID), and scheduled to nodes where they remain until termination (according to restart policy) or deletion.
If a node dies, the pods scheduled to that node are scheduled for deletion, after a timeout period.
A given pod (as defined by a UID) is not “rescheduled” to a new node; instead, it can be replaced by an identical pod, with even the same name if desired, but with a new UID (see replication controller for more details). (In the future, a higher-level API may support pod migration.)
When something is said to have the same lifetime as a pod, such as a volume, that means that it exists as long as that pod (with that UID) exists.
If that pod is deleted for any reason, even if an identical replacement is created, the related thing (e.g. volume) is also destroyed and created anew.

A multi-container pod that contains a file puller and a web server that uses a persistent volume for shared storage between the containers.
Motivation for pods
Management
Pods are a model of the pattern of multiple cooperating processes which form a cohesive unit of service.
They simplify application deployment and management by providing a higher-level abstraction than the set of their constituent applications.
Pods serve as unit of deployment, horizontal scaling, and replication.
Colocation (co-scheduling), shared fate (e.g. termination), coordinated replication, resource sharing, and dependency management are handled automatically for containers in a pod.
Resource sharing and communication
Pods enable data sharing and communication among their constituents.
The applications in a pod all use the same network namespace (same IP and port space), and can thus “find” each other and communicate using localhost. Because of this, applications in a pod must coordinate their usage of ports.
Each pod has an IP address in a flat shared networking space that has full communication with other physical computers and pods across the network.
The hostname is set to the pod’s Name for the application containers within the pod. More details on networking.
In addition to defining the application containers that run in the pod, the pod specifies a set of shared storage volumes.
Volumes enable data to survive container restarts and to be shared among the applications within the pod.
Uses of pods
Pods can be used to host vertically integrated application stacks (e.g. LAMP), but their primary motivation is to support co-located, co-managed helper programs, such as:
- content management systems, file and data loaders, local cache managers, etc.
- log and checkpoint backup, compression, rotation, snapshotting, etc.
- data change watchers, log tailers, logging and monitoring adapters, event publishers, etc.
- proxies, bridges, and adapters
- controllers, managers, configurators, and updaters
Individual pods are not intended to run multiple instances of the same application, in general.
For a longer explanation, see The Distributed System ToolKit: Patterns for Composite Containers.
Alternatives considered
Why not just run multiple programs in a single (Docker) container?
- Transparency. Making the containers within the pod visible to the infrastructure enables the infrastructure to provide services to those containers, such as process management and resource monitoring. This facilitates a number of conveniences for users.
- Decoupling software dependencies. The individual containers may be versioned, rebuilt and redeployed independently. Kubernetes may even support live updates of individual containers someday.
- Ease of use. Users don’t need to run their own process managers, worry about signal and exit-code propagation, etc.
- Efficiency. Because the infrastructure takes on more responsibility, containers can be lighter weight.
Why not support affinity-based co-scheduling of containers?
That approach would provide co-location, but would not provide most of the benefits of pods, such as resource sharing, IPC, guaranteed fate sharing, and simplified management.
Durability of pods (or lack thereof)
Pods aren’t intended to be treated as durable entities.
They won’t survive scheduling failures, node failures, or other evictions, such as due to lack of resources, or in the case of node maintenance.
In general, users shouldn’t need to create pods directly. They should almost always use controllers (e.g., Deployments), even for singletons.
Controllers provide self-healing with a cluster scope, as well as replication and rollout management.
The use of collective APIs as the primary user-facing primitive is relatively common among cluster scheduling systems, including Borg, Marathon, Aurora, and Tupperware.
Pod is exposed as a primitive in order to facilitate:
- scheduler and controller pluggability
- support for pod-level operations without the need to “proxy” them via controller APIs
- decoupling of pod lifetime from controller lifetime, such as for bootstrapping
- decoupling of controllers and services — the endpoint controller just watches pods
- clean composition of Kubelet-level functionality with cluster-level functionality — Kubelet is effectively the “pod controller”
- high-availability applications, which will expect pods to be replaced in advance of their termination and certainly in advance of deletion, such as in the case of planned evictions, image prefetching, or live pod migration #3949
There is new first-class support for stateful pods with the StatefulSet controller (currently in beta). The feature was alpha in 1.4 and was called PetSet.
For prior versions of Kubernetes, best practice for having stateful pods is to create a replication controller with replicas equal to 1 and a corresponding service, see this MySQL deployment example.
Termination of Pods
Because pods represent running processes on nodes in the cluster, it is important to allow those processes to gracefully terminate when they are no longer needed (vs being violently killed with a KILL signal and having no chance to clean up).
Users should be able to request deletion and know when processes terminate, but also be able to ensure that deletes eventually complete.
When a user requests deletion of a pod the system records the intended grace period before the pod is allowed to be forcefully killed, and a TERM signal is sent to the main process in each container. Once the grace period has expired the KILL signal is sent to those processes and the pod is then deleted from the API server.
If the Kubelet or the container manager is restarted while waiting for processes to terminate, the termination will be retried with the full grace period.
An example flow:
- User sends command to delete Pod, with default grace period (30s)
- The Pod in the API server is updated with the time beyond which the Pod is considered “dead” along with the grace period.
- Pod shows up as “Terminating” when listed in client commands
- (simultaneous with 3) When the Kubelet sees that a Pod has been marked as terminating because the time in 2 has been set, it begins the pod shutdown process.
- If the pod has defined a preStop hook, it is invoked inside of the pod. If the
preStophook is still running after the grace period expires, step 2 is then invoked with a small (2 second) extended grace period. - The processes in the Pod are sent the TERM signal.
- (simultaneous with 3), Pod is removed from endpoints list for service, and are no longer considered part of the set of running pods for replication controllers. Pods that shutdown slowly can continue to serve traffic as load balancers (like the service proxy) remove them from their rotations.
- When the grace period expires, any processes still running in the Pod are killed with SIGKILL.
- The Kubelet will finish deleting the Pod on the API server by setting grace period 0 (immediate deletion). The Pod disappears from the API and is no longer visible from the client.
By default, all deletes are graceful within 30 seconds.
The kubectl delete command supports the --grace-period=option which allows a user to override the default and specify their own value. The value 0 force deletes the pod.
In kubectl version >= 1.5, you must specify an additional flag --force along with --grace-period=0 in order to perform force deletions.
Force deletion of pods
Force deletion of a pod is defined as deletion of a pod from the cluster state and etcd immediately.
When a force deletion is performed, the apiserver does not wait for confirmation from the kubelet that the pod has been terminated on the node it was running on. It removes the pod in the API immediately so a new pod can be created with the same name.
On the node, pods that are set to terminate immediately will still be given a small grace period before being force killed.
Force deletions can be potentially dangerous for some pods and should be performed with caution.
In case of StatefulSet pods, please refer to the task documentation for deleting Pods from a StatefulSet.
Privileged mode for pod containers
From Kubernetes v1.1, any container in a pod can enable privileged mode, using the privileged flag on the SecurityContext of the container spec.
This is useful for containers that want to use linux capabilities like manipulating the network stack and accessing devices.
Processes within the container get almost the same privileges that are available to processes outside a container.
With privileged mode, it should be easier to write network and volume plugins as separate pods that don’t need to be compiled into the kubelet.
If the master is running Kubernetes v1.1 or higher, and the nodes are running a version lower than v1.1, then new privileged pods will be accepted by api-server, but will not be launched. They will be pending state.
If user calls kubectl describe pod FooPodName, user can see the reason why the pod is in pending state.
The events table in the describe command output will say:
Error validating pod "FooPodName"."FooPodNamespace" from api, ignoring:
spec.containers[0].securityContext.privileged: forbidden '<*>(0xc2089d3248)true'
If the master is running a version lower than v1.1, then privileged pods cannot be created.
If user attempts to create a pod, that has a privileged container, the user will get the following error:
The Pod "FooPodName" is invalid. spec.containers[0].securityContext.privileged: forbidden '<*>(0xc20b222db0)true'
API Object
Pod is a top-level resource in the Kubernetes REST API. More details about the API object can be found at: Pod API object.
Pod Lifecycle
This page describes the lifecycle of a Pod.
- Pod phase
- Pod conditions
- Container probes
- When should you use liveness or readiness probes?
- Pod and Container status
- Restart policy
- Pod lifetime
- Examples
- Advanced liveness probe example
- Example states
Pod phase
A Pod’s status field is a PodStatus object, which has a phase field.
The phase of a Pod is a simple, high-level summary of where the Pod is in its lifecycle.
The phase is not intended to be a comprehensive rollup of observations of Container or Pod state, nor is it intended to be a comprehensive state machine.
The number and meanings of Pod phase values are tightly guarded. Other than what is documented here, nothing should be assumed about Pods that have a given phase value.
Here are the possible values for phase:
-
Pending: The Pod has been accepted by the Kubernetes system, but one or more of the Container images has not been created. This includes time before being scheduled as well as time spent downloading images over the network, which could take a while.
-
Running: The Pod has been bound to a node, and all of the Containers have been created. At least one Container is still running, or is in the process of starting or restarting.
-
Succeeded: All Containers in the Pod have terminated in success, and will not be restarted.
-
Failed: All Containers in the Pod have terminated, and at least one Container has terminated in failure. That is, the Container either exited with non-zero status or was terminated by the system.
-
Unknown: For some reason the state of the Pod could not be obtained, typically due to an error in communicating with the host of the Pod.
Pod conditions
A Pod has a PodStatus, which has an array of PodConditions.
Each element of the PodCondition array has a type field and a status field.
The type field is a string, with possible values PodScheduled, Ready, Initialized, and Unschedulable.
The status field is a string, with possible values True, False, and Unknown.
Container probes
Container probes
A Probe is a diagnostic performed periodically by the kubelet on a Container.
To perform a diagnostic, the kubelet calls a Handlerimplemented by the Container. There are three types of handlers:
-
ExecAction: Executes a specified command inside the Container. The diagnostic is considered successful if the command exits with a status code of 0.
-
TCPSocketAction: Performs a TCP check against the Container’s IP address on a specified port. The diagnostic is considered successful if the port is open.
-
HTTPGetAction: Performs an HTTP Get request against the Container’s IP address on a specified port and path. The diagnostic is considered successful if the response has a status code greater than or equal to 200 and less than 400.
Each probe has one of three results:
- Success: The Container passed the diagnostic.
- Failure: The Container failed the diagnostic.
- Unknown: The diagnostic failed, so no action should be taken.
The kubelet can optionally perform and react to two kinds of probes on running Containers:
-
livenessProbe: Indicates whether the Container is running. If the liveness probe fails, the kubelet kills the Container, and the Container is subjected to its restart policy. If a Container does not provide a liveness probe, the default state isSuccess. -
readinessProbe: Indicates whether the Container is ready to service requests. If the readiness probe fails, the endpoints controller removes the Pod’s IP address from the endpoints of all Services that match the Pod. The default state of readiness before the initial delay isFailure. If a Container does not provide a readiness probe, the default state isSuccess.
When should you use liveness or readiness probes?
Edit This Page
Pod Lifecycle
This page describes the lifecycle of a Pod.
- Pod phase
- Pod conditions
- Container probes
- When should you use liveness or readiness probes?
- Pod and Container status
- Restart policy
- Pod lifetime
- Examples
- Advanced liveness probe example
- Example states
- What’s next
Pod phase
A Pod’s status field is a PodStatus object, which has a phase field.
The phase of a Pod is a simple, high-level summary of where the Pod is in its lifecycle. The phase is not intended to be a comprehensive rollup of observations of Container or Pod state, nor is it intended to be a comprehensive state machine.
The number and meanings of Pod phase values are tightly guarded. Other than what is documented here, nothing should be assumed about Pods that have a given phase value.
Here are the possible values for phase:
-
Pending: The Pod has been accepted by the Kubernetes system, but one or more of the Container images has not been created. This includes time before being scheduled as well as time spent downloading images over the network, which could take a while.
-
Running: The Pod has been bound to a node, and all of the Containers have been created. At least one Container is still running, or is in the process of starting or restarting.
-
Succeeded: All Containers in the Pod have terminated in success, and will not be restarted.
-
Failed: All Containers in the Pod have terminated, and at least one Container has terminated in failure. That is, the Container either exited with non-zero status or was terminated by the system.
-
Unknown: For some reason the state of the Pod could not be obtained, typically due to an error in communicating with the host of the Pod.
Pod conditions
A Pod has a PodStatus, which has an array of PodConditions. Each element of the PodCondition array has a type field and a status field. The type field is a string, with possible values PodScheduled, Ready, Initialized, and Unschedulable. The status field is a string, with possible values True, False, and Unknown.
Container probes
A Probe is a diagnostic performed periodically by the kubelet on a Container. To perform a diagnostic, the kubelet calls a Handlerimplemented by the Container. There are three types of handlers:
-
ExecAction: Executes a specified command inside the Container. The diagnostic is considered successful if the command exits with a status code of 0.
-
TCPSocketAction: Performs a TCP check against the Container’s IP address on a specified port. The diagnostic is considered successful if the port is open.
-
HTTPGetAction: Performs an HTTP Get request against the Container’s IP address on a specified port and path. The diagnostic is considered successful if the response has a status code greater than or equal to 200 and less than 400.
Each probe has one of three results:
- Success: The Container passed the diagnostic.
- Failure: The Container failed the diagnostic.
- Unknown: The diagnostic failed, so no action should be taken.
The kubelet can optionally perform and react to two kinds of probes on running Containers:
-
livenessProbe: Indicates whether the Container is running. If the liveness probe fails, the kubelet kills the Container, and the Container is subjected to its restart policy. If a Container does not provide a liveness probe, the default state isSuccess. -
readinessProbe: Indicates whether the Container is ready to service requests. If the readiness probe fails, the endpoints controller removes the Pod’s IP address from the endpoints of all Services that match the Pod. The default state of readiness before the initial delay isFailure. If a Container does not provide a readiness probe, the default state isSuccess.
When should you use liveness or readiness probes?
If the process in your Container is able to crash on its own whenever it encounters an issue or becomes unhealthy, you do not necessarily need a liveness probe; the kubelet will automatically perform the correct action in accordance with the Pod’s restartPolicy.
If you’d like your Container to be killed and restarted if a probe fails, then specify a liveness probe, and specify a restartPolicy of Always or OnFailure.
If you’d like to start sending traffic to a Pod only when a probe succeeds, specify a readiness probe.
In this case, the readiness probe might be the same as the liveness probe, but the existence of the readiness probe in the spec means that the Pod will start without receiving any traffic and only start receiving traffic after the probe starts succeeding.
If you want your Container to be able to take itself down for maintenance, you can specify a readiness probe that checks an endpoint specific to readiness that is different from the liveness probe.
Note that if you just want to be able to drain requests when the Pod is deleted, you do not necessarily need a readiness probe; on deletion, the Pod automatically puts itself into an unready state regardless of whether the readiness probe exists.
The Pod remains in the unready state while it waits for the Containers in the Pod to stop.
Pod and Container status
A PodSpec has a restartPolicy field with possible values Always, OnFailure, and Never. The default value is Always. restartPolicy applies to all Containers in the Pod.
restartPolicy only refers to restarts of the Containers by the kubelet on the same node.
Failed Containers that are restarted by the kubelet are restarted with an exponential back-off delay (10s, 20s, 40s …) capped at five minutes, and is reset after ten minutes of successful execution.
As discussed in the Pods document, once bound to a node, a Pod will never be rebound to another node.
Pod lifetime
In general, Pods do not disappear until someone destroys them. This might be a human or a controller.
The only exception to this rule is that Pods with a phase of Succeeded or Failed for more than some duration (determined by the master) will expire and be automatically destroyed.
Three types of controllers are available:
-
Use a Job for Pods that are expected to terminate, for example, batch computations. Jobs are appropriate only for Pods with
restartPolicyequal to OnFailure or Never. -
Use a ReplicationController, ReplicaSet, or Deployment for Pods that are not expected to terminate, for example, web servers. ReplicationControllers are appropriate only for Pods with a
restartPolicyof Always. -
Use a DaemonSet for Pods that need to run one per machine, because they provide a machine-specific system service.
All three types of controllers contain a PodTemplate.
It is recommended to create the appropriate controller and let it create Pods, rather than directly create Pods yourself.
That is because Pods alone are not resilient to machine failures, but controllers are.
If a node dies or is disconnected from the rest of the cluster, Kubernetes applies a policy for setting the phase of all Pods on the lost node to Failed.
Examples
Advanced liveness probe example
Liveness probes are executed by the kubelet, so all requests are made in the kubelet network namespace.
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- args:
- /server
image: k8s.gcr.io/liveness
livenessProbe:
httpGet:
# when "host" is not defined, "PodIP" will be used
# host: my-host
# when "scheme" is not defined, "HTTP" scheme will be used. Only "HTTP" and "HTTPS" are allowed
# scheme: HTTPS
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 15
timeoutSeconds: 1
name: liveness
Example states
- Pod is running and has one Container. Container exits with success.
- Log completion event.
- If
restartPolicyis:- Always: Restart Container; Pod
phasestays Running. - OnFailure: Pod
phasebecomes Succeeded. - Never: Pod
phasebecomes Succeeded.
- Always: Restart Container; Pod
- Pod is running and has one Container. Container exits with failure.
- Log failure event.
- If
restartPolicyis:- Always: Restart Container; Pod
phasestays Running. - OnFailure: Restart Container; Pod
phasestays Running. - Never: Pod
phasebecomes Failed.
- Always: Restart Container; Pod
- Pod is running and has two Containers. Container 1 exits with failure.
- Log failure event.
- If
restartPolicyis:- Always: Restart Container; Pod
phasestays Running. - OnFailure: Restart Container; Pod
phasestays Running. - Never: Do not restart Container; Pod
phasestays Running.
- Always: Restart Container; Pod
- If Container 1 is not running, and Container 2 exits:
- Log failure event.
- If
restartPolicyis:- Always: Restart Container; Pod
phasestays Running. - OnFailure: Restart Container; Pod
phasestays Running. - Never: Pod
phasebecomes Failed.
- Always: Restart Container; Pod
- Pod is running and has one Container. Container runs out of memory.
- Container terminates in failure.
- Log OOM event.
- If
restartPolicyis:- Always: Restart Container; Pod
phasestays Running. - OnFailure: Restart Container; Pod
phasestays Running. - Never: Log failure event; Pod
phasebecomes Failed.
- Always: Restart Container; Pod
- Pod is running, and a disk dies.
- Kill all Containers.
- Log appropriate event.
- Pod
phasebecomes Failed. - If running under a controller, Pod is recreated elsewhere.
- Pod is running, and its node is segmented out.
- Node controller waits for timeout.
- Node controller sets Pod
phaseto Failed. - If running under a controller, Pod is recreated elsewhere.