R语言小代码(弥补测试)
任务一:R语言获取中国石油股票数据
#quantmod 包默认是访问 yahoo finance 的数据,
#其中包括上证和深证的股票数据,还有港股数据。
library(quantmod)
#中国石油--沪A601857 港股00857
#上证代码是 ss,深证代码是 sz,港股代码是 hk
#setSymbolLookup(sy=list(name='00857.hk',src='yahoo'))
#getSymbols("sy")----下载不下来
#chartSeries(sy)
setSymbolLookup(sy2=list(name='601857.ss',src='yahoo'))
getSymbols("sy2")
chartSeries(SY2)
#万科 000002.sz
setSymbolLookup(wk=list(name='000002.sz',src='yahoo'))
getSymbols("wk")
chartSeries(WK)
中国石油:
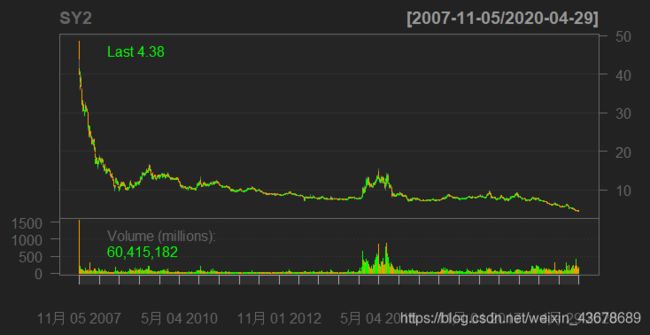

万科:


任务二:向量操作
> x <- paste("金融",rep(c(2001:2004),each=2),c("甲班","乙班"))
> x
[1] "金融 2001 甲班" "金融 2001 乙班" "金融 2002 甲班" "金融 2002 乙班"
[5] "金融 2003 甲班" "金融 2003 乙班" "金融 2004 甲班" "金融 2004 乙班"
任务三:数据框操作
任务内容:
Insurance数据集为某保险公司的车险数据,
按列依次表示:家庭住址区域,投保汽车排量,投保人年龄,投保人数量,要求索赔的数量
1.读入保险数据
2.检测NA值,并输出其位置
3.删除含有缺失值的行
4.保存为另一个数据框,要求将数据按照投保人数量的升序排序,若值相等,按要求索赔的数量排序。
5.定义新的数据框为数据框中家庭住址区域为3的内容。
#1.读入保险数据
#安装包与载入数据集:
install.packages('MASS') # 安装包
library(MASS) #载入包
data(Insurance) # 载入数据集
ins <- Insurance #拷贝一份数据
View(ins)

#2.检测NA值,并输出其位置
which(is.na(ins))
integer(0)
#3.删除含有缺失值的行
ins1=na.omit(ins)
ins1
> ins1
District Group Age Holders Claims
1 1 <1l <25 197 38
2 1 <1l 25-29 264 35
3 1 <1l 30-35 246 20
4 1 <1l >35 1680 156
5 1 1-1.5l <25 284 63
6 1 1-1.5l 25-29 536 84
7 1 1-1.5l 30-35 696 89
8 1 1-1.5l >35 3582 400
9 1 1.5-2l <25 133 19
10 1 1.5-2l 25-29 286 52
11 1 1.5-2l 30-35 355 74
12 1 1.5-2l >35 1640 233
13 1 >2l <25 24 4
14 1 >2l 25-29 71 18
15 1 >2l 30-35 99 19
16 1 >2l >35 452 77
17 2 <1l <25 85 22
18 2 <1l 25-29 139 19
19 2 <1l 30-35 151 22
20 2 <1l >35 931 87
21 2 1-1.5l <25 149 25
22 2 1-1.5l 25-29 313 51
23 2 1-1.5l 30-35 419 49
24 2 1-1.5l >35 2443 290
25 2 1.5-2l <25 66 14
26 2 1.5-2l 25-29 175 46
27 2 1.5-2l 30-35 221 39
28 2 1.5-2l >35 1110 143
29 2 >2l <25 9 4
30 2 >2l 25-29 48 15
31 2 >2l 30-35 72 12
32 2 >2l >35 322 53
33 3 <1l <25 35 5
34 3 <1l 25-29 73 11
35 3 <1l 30-35 89 10
36 3 <1l >35 648 67
37 3 1-1.5l <25 53 10
38 3 1-1.5l 25-29 155 24
39 3 1-1.5l 30-35 240 37
40 3 1-1.5l >35 1635 187
41 3 1.5-2l <25 24 8
42 3 1.5-2l 25-29 78 19
43 3 1.5-2l 30-35 121 24
44 3 1.5-2l >35 692 101
45 3 >2l <25 7 3
46 3 >2l 25-29 29 2
47 3 >2l 30-35 43 8
48 3 >2l >35 245 37
49 4 <1l <25 20 2
50 4 <1l 25-29 33 5
51 4 <1l 30-35 40 4
52 4 <1l >35 316 36
53 4 1-1.5l <25 31 7
54 4 1-1.5l 25-29 81 10
55 4 1-1.5l 30-35 122 22
56 4 1-1.5l >35 724 102
57 4 1.5-2l <25 18 5
58 4 1.5-2l 25-29 39 7
59 4 1.5-2l 30-35 68 16
60 4 1.5-2l >35 344 63
61 4 >2l <25 3 0
62 4 >2l 25-29 16 6
63 4 >2l 30-35 25 8
64 4 >2l >35 114 33
>
#4.保存为另一个数据框,要求将数据按照投保人数量的升序排序,若值相等,按要求索赔的数量排序。
ins2=ins[order(ins$Holders,ins$Claims),]#默认升序
ins2
> ins2
District Group Age Holders Claims
61 4 >2l <25 3 0
45 3 >2l <25 7 3
29 2 >2l <25 9 4
62 4 >2l 25-29 16 6
57 4 1.5-2l <25 18 5
49 4 <1l <25 20 2
13 1 >2l <25 24 4
41 3 1.5-2l <25 24 8
63 4 >2l 30-35 25 8
46 3 >2l 25-29 29 2
53 4 1-1.5l <25 31 7
50 4 <1l 25-29 33 5
33 3 <1l <25 35 5
58 4 1.5-2l 25-29 39 7
51 4 <1l 30-35 40 4
47 3 >2l 30-35 43 8
30 2 >2l 25-29 48 15
37 3 1-1.5l <25 53 10
25 2 1.5-2l <25 66 14
59 4 1.5-2l 30-35 68 16
14 1 >2l 25-29 71 18
31 2 >2l 30-35 72 12
34 3 <1l 25-29 73 11
42 3 1.5-2l 25-29 78 19
54 4 1-1.5l 25-29 81 10
17 2 <1l <25 85 22
35 3 <1l 30-35 89 10
15 1 >2l 30-35 99 19
64 4 >2l >35 114 33
43 3 1.5-2l 30-35 121 24
55 4 1-1.5l 30-35 122 22
9 1 1.5-2l <25 133 19
18 2 <1l 25-29 139 19
21 2 1-1.5l <25 149 25
19 2 <1l 30-35 151 22
38 3 1-1.5l 25-29 155 24
26 2 1.5-2l 25-29 175 46
1 1 <1l <25 197 38
27 2 1.5-2l 30-35 221 39
39 3 1-1.5l 30-35 240 37
48 3 >2l >35 245 37
3 1 <1l 30-35 246 20
2 1 <1l 25-29 264 35
5 1 1-1.5l <25 284 63
10 1 1.5-2l 25-29 286 52
22 2 1-1.5l 25-29 313 51
52 4 <1l >35 316 36
32 2 >2l >35 322 53
60 4 1.5-2l >35 344 63
11 1 1.5-2l 30-35 355 74
23 2 1-1.5l 30-35 419 49
16 1 >2l >35 452 77
6 1 1-1.5l 25-29 536 84
36 3 <1l >35 648 67
44 3 1.5-2l >35 692 101
7 1 1-1.5l 30-35 696 89
56 4 1-1.5l >35 724 102
20 2 <1l >35 931 87
28 2 1.5-2l >35 1110 143
40 3 1-1.5l >35 1635 187
12 1 1.5-2l >35 1640 233
4 1 <1l >35 1680 156
24 2 1-1.5l >35 2443 290
8 1 1-1.5l >35 3582 400
>
#5.定义新的数据框为数据框中家庭住址区域为3的内容。
ins3 <- subset(ins,ins$District == "3")
ins3
> ins3
District Group Age Holders Claims
33 3 <1l <25 35 5
34 3 <1l 25-29 73 11
35 3 <1l 30-35 89 10
36 3 <1l >35 648 67
37 3 1-1.5l <25 53 10
38 3 1-1.5l 25-29 155 24
39 3 1-1.5l 30-35 240 37
40 3 1-1.5l >35 1635 187
41 3 1.5-2l <25 24 8
42 3 1.5-2l 25-29 78 19
43 3 1.5-2l 30-35 121 24
44 3 1.5-2l >35 692 101
45 3 >2l <25 7 3
46 3 >2l 25-29 29 2
47 3 >2l 30-35 43 8
48 3 >2l >35 245 37
>
任务四:画图操作
任务内容:
1.录入数据。
2.求工资的均值。
3.绘制工资数据的散点图,并为图形添加参数。
4.绘制工资数据的箱线图,并为图形添加参数。
5.将3,4绘制的图形放到一张图中。
# 1.录入数据。
x<-c(1:19)
y<-c(2000,2100,2200,2300,2350,2450,2500,2700,
2900,2850,3500,3800,2600,3000,3300,3200,4000,3100,4200)
# 2.求工资的均值。
sum=0
for (i in y){
sum=sum+i
}
avg=sum/length(y)
avg
> avg
[1] 2897.368
#3.绘制工资数据的散点图,并为图形添加参数。
plot(x,y,main="工资数据",xlab="月",ylab="元",
lty=2,col='blue', xaxt='n',yaxt = "n")
axis(1,at=x,labels=x,las = 1)
axis(2,at=y,labels=y,las = 1)

#4.绘制工资数据的箱线图,并为图形添加参数。
boxplot(y,width=2, col='red', border="purple",main="工资数据",ylab="元",yaxt = "n")
axis(2,at=y,labels=y,las = 1)
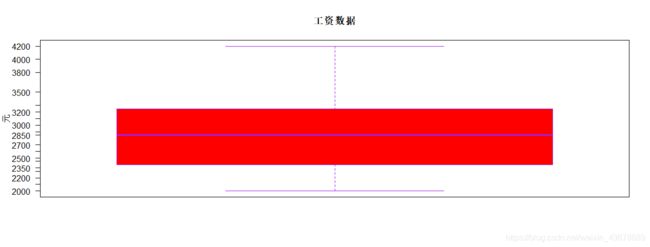
#5.将3,4绘制的图形放到一张图中。
a=par(mfrow=c(1,2))
#3.绘制工资数据的散点图,并为图形添加参数。
plot(x,y,main="工资数据",xlab="月",ylab="元",
lty=2,col='blue', xaxt='n',yaxt = "n")
axis(1,at=x,labels=x,las = 1)
axis(2,at=y,labels=y,las = 1)
#4.绘制工资数据的箱线图,并为图形添加参数。
boxplot(y,width=2, col='red', border="purple",main="工资数据",ylab="元",yaxt = "n")
axis(2,at=y,labels=y,las = 1)
par(a)
