hadoop,pySpark环境安装与运行实战《一》
一、环境准备
环境最好再mac或者liunx环境搭建最为友好,不建议在windows上折腾。
1)安装java jdk
下载java jdk 并在~/.bash_profile配置,jdk mac路径查找方式
#export JAVA_HOME=/Users/wangyun/Documents/BigData/App/jdk1.8.0_60
#export PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME=$(/usr/libexec/java_home)
export PATH=$JAVA_HOME/bin:$PATH
export CLASS_PATH=$JAVA_HOME/lib输入:java -version验证环境

2)安装scala
下载scala 并在~/.bash_profile配置环境变量,并source ~/.bash_profile
export SCALA_HOME=/Users/wangyun/Documents/BigData/App/scala-2.13.2
export PATH=$SCALA_HOME/bin:$PATH输入:scala -version验证

3)安装 hadoop
下载hadoop 并在~/.bash_profile配置环境变量,并source ~/.bash_profile
export HADOOP_HOME =/Users/wangyun/Documents/BigData/App/hadoop-2.10
export PATH=$HADOOP_HOME/bin:$PATH4)安装spark
下载spark 并在~/.bash_profile配置环境变量,并source ~/.bash_profile
export SPARK_HOME=/Users/wangyun/Documents/BigData/App/spark-3.0.0-preview2-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_PYTHON=python3二、hadoop配置
进入
hadoop/etc/hadoop/目录 文件配置
hadoop-env.sh 增加:export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk-10.0.1.jdk/Contents/Home
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk-10.0.1.jdk/Contents/Home
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
# Extra Java CLASSPATH elements. Automatically insert capacity-scheduler.
core-site.xml 增加
fs.default.name
hdfs://127.0.0.1:8020
hdfs-site.xml 增加三组 property
dfs.namenode.name.dir
/Users/wangyun/Documents/BigData/App/tmp/dfs/name
dfs.datanode.data.dir
/Users/wangyun/Documents/BigData/App/tmp/dfs/data
dfs.replication
1
mapred-site.xml 增加一组 property
mapreduce.framework.name
yarn
yarn-site.xml 增加 property
yarn.nodemanager.aux-services
mapr educe_shuffle
到此hadoop配置完成
初始化: 进入hadoop bin目录
mac 出现Starting namenodes on [localhost]
localhost: ssh: connect to host localhost port 22: Connection refused
localhost: ssh: connect to host localhost port 22: Connection refused
Starting secondary namenodes [0.0.0.0]
0.0.0.0: ssh: connect to host 0.0.0.0 port 22: Connection refused报错参见 https://blog.csdn.net/wywinstonwy/article/details/105996077
./hadoop nodename -format启动dfs sbin目录 启动报错的情况之一
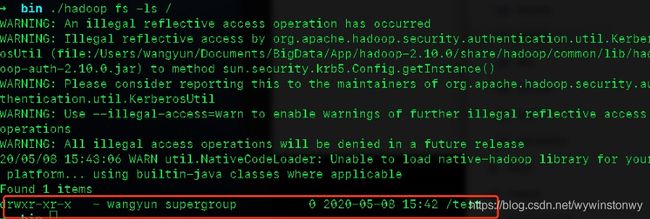
./start-dfs.sh查看文件夹
./hadoop fs -ls /
创建文件夹
./hadoop fs -mkdir /test
上传文件:
./hadoop fs -put /Users/wangyun/Desktop/lala.txt /test/
查看文件
./hadoop fs -ls /test
读取文件
./hadoop fs -text /test/lala.txt
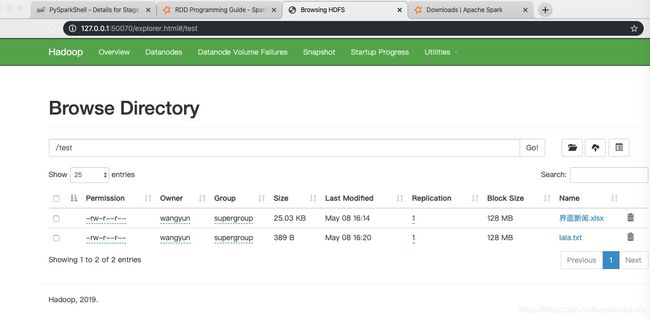
访问: http://127.0.0.1:50070/explorer.html#/test
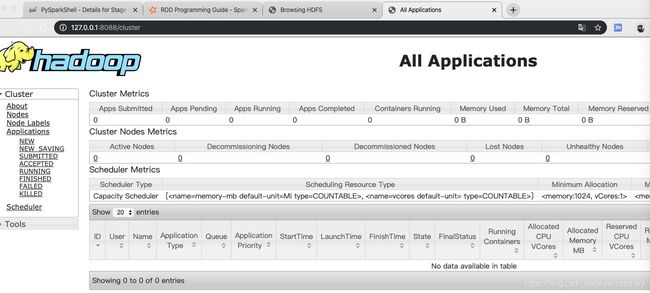
驱动yarn,sbin目录下
执行:./start-yarn.sh
访问:http://127.0.0.1:8088/cluster
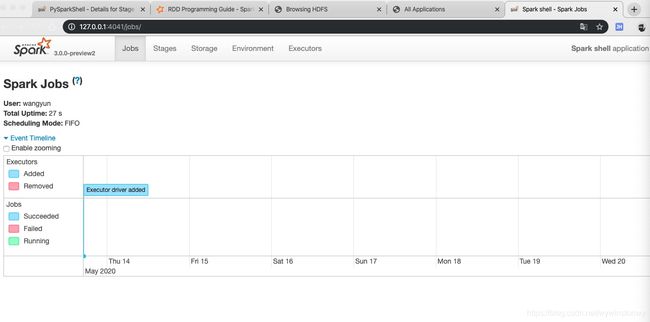
进入spark bin目录启动spark
./spark-shell
Spark context Web UI available at http://bogon:4040
Spark context available as 'sc' (master = local[*], app id = local-1588985838107).
Spark session available as 'spark'.
注意:端口占用会自动+1
启动pySpark bin目录
./pyspark 默认启动的是python 2
需要就该配置文件
修改spark-env.sh文件,在末尾添加
PYSPARK_PYTHON=/usr/bin/python3 实际的路径地址
到此spark相关配置和启动完成,可进入编程模式,参见官网写个简单demo
data =[1,2,3,4,5]
distData = sc.parallelize(data)
print(distData.collect())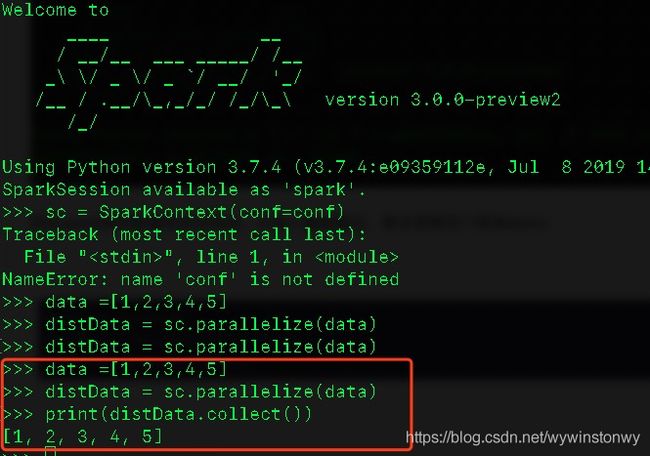
创建spark001.py 测试demo
from pyspark import SparkContext,SparkConf
if __name__ =="__main__":
conf = SparkConf().setMaster("local[2]").setAppName('spark002')
sc = SparkContext(conf=conf)
#map 算子
def mymap():
data = [1,2,3,4,5]
rdd1 = sc.parallelize(data)
rdd2 = rdd1.map(lambda x:x*2)
print(rdd2.collect())
def mymap2():
a = ['dog','pig','tiger','lion','cat','bird','dog']
rdd1 = sc.parallelize(a)
rdd2 = rdd1.map(lambda x:(x,1))
print(rdd2.collect())
def myfilter():
data = [1,2,3,4,5]
rdd1 = sc.parallelize(data)
mapRdd = rdd1.map(lambda x:x*2)
filterRdd = mapRdd.filter(lambda x:x>5)
print(filterRdd.collect())
#简化写法
# rdd = rdd1.map(lambda x:x*2).filter(lambda x:x>5)
# print(rdd.collect())
def myflatMap():
data =['hello spark','hello world','hello world']
rdd1 = sc.parallelize(data)
rdd2 = rdd1.flatMap(lambda line:line.split(" "))
print(rdd2.collect())
def mygroupByKey():
data = ['hello spark', 'hello world',
'hello world']
rdd1 = sc.parallelize(data)
rdd2 = rdd1.flatMap(
lambda line: line.split(" ")).map(lambda x:(x,1))
groupRdd = rdd2.groupByKey()
print(groupRdd.collect())
print(groupRdd.map(lambda x:{x[0]:list(x[1])}).collect())
def myReduceByKey():
data = ['hello spark', 'hello world',
'hello world']
rdd1 = sc.parallelize(data)
rdd2 = rdd1.flatMap(
lambda line: line.split(" ")).map(
lambda x: (x, 1))
reduceByKeyRdd = rdd2.reduceByKey(lambda x,y:x+y)
print(reduceByKeyRdd.collect())
myReduceByKey()
sc.stop()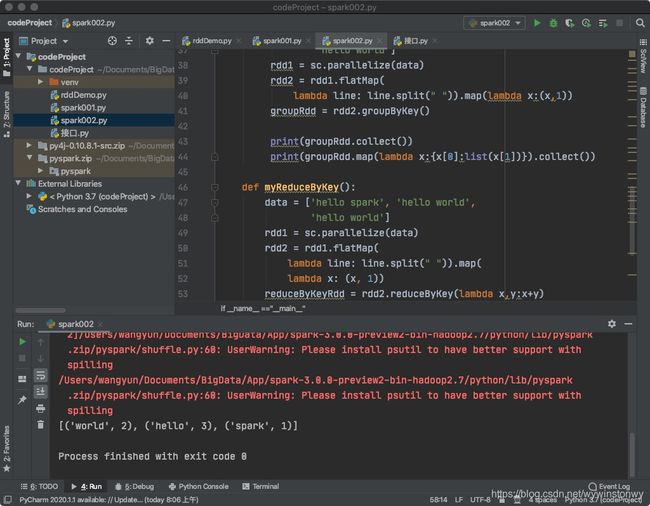
相关推荐:
hadoop,pySpark环境安装与运行实战《一》
Spark RDD操作,常用算子《二》
PySpark之算子综合实战案例《三》
Spark运行模式以及部署《四》
Spark Core解析《五》
PySpark之Spark Core调优《六》
PySpark之Spark SQL的使用《七》
持续更新中...