Spark运行模式以及部署《四》
Spark运行模式有5种:
1)local
本地模式或者开发测试模式,
./bin/pyspark \
--master local[4] \
--name spark001通过$SPARK_HOME/bin/pyspark --help 可查看帮助
2)standalone
standalone为spark自带集群管理,分为master和worker节点。
首先配置conf/slaves.temlate,增加集群节点。

# A Spark Worker will be started on each of the machines listed below.
localhost中loacal改成需要的域名或者ip地址。假设你有五台机器,就应该配置
hadoop0001
hadoop0002
hadoop0003
hadoop0004
hadoop0005
如果多台机器,部署相同的路径下,
配置完成后可启动 $SPARK_HOME/sbin/ start-master.sh和start-slave.sh 或者启动 start-all.sh
$SPARK_HOME/sbin/starrt-all.sh启动后可通过jps查看

如果出现报错 在$SPARK_HOME/conf配置 spark-env.sh
从启动日志中可看到默认webUI端口是8080为master,8081为worker端口
7077端口为spark提交作业的端口,可参加官方文档如下,通过日志也可以找到启动端口。

master WEBUI:8080

worker WebUI:80801

提交作业测试,先回去$SPARK_HOME/bin
1.终端启动spark: ./pyspark --master spark://hadoop001:7077 并提交作业

collect后spark job可看到任务
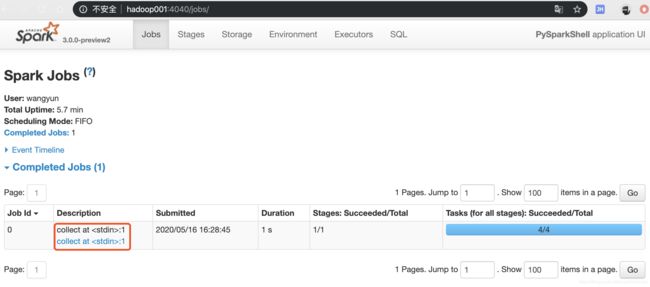
2../spark-submit --master spark://hadoop001:7077 --name sparkalone py.files
如果standalone模式并且节点大于1的时候,使用本地文件要确保每天机器都有,或者使用hdfs,确保每天机器路径相同都能访问。
启动hdfs,./start-dfs.sh,通过hadoop fs -ls/查看是否有文件。http://127.0.0.1:50070 dfs端口为50070第一章有提到:hadoop,pySpark环境安装与运行实战《一》
采用hdfs数据进行提交,指定master,name,提交的脚本文件,数据路径。
./spark-submit --master spark://hadoop001:7077 --name spark-standalone /Users/wangyun/Documents/BigData/script/spark003.py hdfs://hadoop001:8020/test/data.txt
输出结果:

3)yarn
spark 通过客户端,负责提交作业到yarn,yarn只需要一个节点,然后提交作业即可。这个不需要spark集群(master和worker),如果是standalone模式,每个机器上都需要部署spark,然后需要启动spark集群(master和worker)
提交作业到yarn,命令如下,log控制台会提示报错
./spark-submit --master yarn --name spark-yarn /Users/wangyun/Documents/BigData/script/spark003.py hdfs://hadoop001:8020/test/data.txtException in thread "main" org.apache.spark.SparkException: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment. 官方文档参考:http://spark.apache.org/docs/latest/running-on-yarn.html
cd hadoop-2.10/etc/hadoop 
$SPARK_HOME/conf/spark-env.sh 中增加如下code:
HADOOP_CONF_DIR=/Users/wangyun/Documents/BigData/App/hadoop-2.10/etc/hadoop
然后继续执行以下提交命令,运行正常。记得启动 ¥HADOOP/sbin/start-yarn.sh
./spark-submit --master yarn --name spark-yarn /Users/wangyun/Documents/BigData/script/spark003.py hdfs://hadoop001:8020/test/data.txt通过WEBUI可查看:http://hadoop001:8088/cluster
yarn支持client和cluster模式:client提交作业的进程是不能停止的,否则作业就挂了。
cluster提交作业后就断开了,因为driver运行在am中.
4)mesos
参见官方:http://spark.apache.org/docs/latest/running-on-mesos.html
5)kuberneters
The Kubernetes scheduler is currently experimental. In future versions, there may be behavioral changes around configuration, container images and entrypoints.
Kubernetes调度器目前处于试验阶段。在未来的版本中,可能会对配置、容器映像和入口点进行行为更改。具体参见:http://spark.apache.org/docs/latest/running-on-kubernetes.html
相关推荐:
hadoop,pySpark环境安装与运行实战《一》
Spark RDD操作,常用算子《二》
PySpark之算子综合实战案例《三》
Spark运行模式以及部署《四》
Spark Core解析《五》
PySpark之Spark Core调优《六》
PySpark之Spark SQL的使用《七》
持续更新中...