Linux的poll机制
目录
- 前言
- 1 应用层使用poll
-
- 1.1 poll的原型
- 1.2 使用示例
- 2 驱动怎么支持poll
-
- 2.1 字符设备驱动
- 3 一些更深入的分析
-
- 3.1 从系统调用poll到驱动的xxx_poll
-
- 3.1.1 sys_poll
- 3.1.2 do_sys_poll
- 3.1.3 do_poll
- 3.1.4 do_pollfd
- 3.1.5 vfs_poll
- 3.1.6 总结
- 3.2 poll_wait做了什么
-
- 3.2.1 poll_wait的定义
- 3.2.2 __pollwait
- 3.2.3 一些补充说明
- PS:对私有数据的使用的一些体会
- 4 select和poll
- 5 epoll又是怎么回事
- 6 参考文献
前言
最近学习linux的poll机制时,总感觉学习的不够深入,仅仅停留在按照套路写驱动的层面。觉得还是要再深入分析,因此用一篇博客来记录这个知识点,内容主要来源于一些书籍、网络资源、韦东山老师的视频教程,以及自己的分析和理解。内容会随着本人学习的深入不断完善,如有错漏也希望同道中人指正。
1 应用层使用poll
1.1 poll的原型
poll的函数原型如下:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
参数与返回值的含义如下:
| 参数/返回值 | 含义 |
|---|---|
| fds | 指向struct pollfd类型的数组,其中记录了要监听的文件的描述符、要监听的事件、返回的事件 |
| nfds | struct pollfd类型的数组的成员个数 |
| timeout | 如果没有监听的事件返回,则等待timeout时间后返回,其值为0表示不等待,值为正数表示等待的毫秒数,值为负数表示永久等待 |
| 返回值 | 负数——失败、0——等待超时且被监听的文件中没有就绪的、正数——被监听的文件中有事件返回的文件个数 |
1.2 使用示例
int ret;
char name[20] = {
0};
// 要监听两个文件
struct pollfd fds[2];
...
for (int i = 0; i < 2; ++i)
{
sprintf(name, "/dev/mydev%d", i);
// 填充要监听的文件描述符
fds[i].fd = open(name, O_RDWR);
if (fds[i].fd == -1)
{
perror("err is");
exit(EXIT_FAILURE);
}
// 指定要监听的事件
fds[i].events = POLLIN | POLLRDNORM;
// 初始化返回事件
fds[i].revents = 0;
}
while (1)
{
// 监听2个文件(若无监听事件返回则永久等待)
ret = poll(fds, 2, -1);
if (ret == -1)
{
perror("err is");
exit(EXIT_FAILURE);
}
// 第一个文件有监听的事件返回
if ((fds[0].revents & POLLIN) || (fds[0].revents & POLLRDNORM))
{
// 做相应处理
}
// 第二个文件有监听的事件返回
if ((fds[1].revents & POLLIN) || (fds[1].revents & POLLRDNORM))
{
// 做相应处理
}
}
...
2 驱动怎么支持poll
2.1 字符设备驱动
字符设备驱动通过struct file_operations结构提供一系列的操作,其中就包含poll,应用层对poll的调用最终会执行到该结构的poll成员,因此我们要支持poll操作的话就需要填充该成员,即完成驱动层的poll函数。这个函数一般可以这么写:
static unsigned int xxx_poll(struct file *file, poll_table *wait)
{
unsigned int mask = 0;
struct xxx_dev *device = file->private_data;
...
// 将当前进程加入读等待队列
poll_wait(file, &device->wait_queue_for_read, wait);
// 将当前进程加入写等待队列
poll_wait(file, &device->wait_queue_for_write, wait);
if (xxx) // 设备文件有数据可读
mask |= POLLIN | POLLRDNORM;
if (xxx) // 设备文件有数据可写
mask |= POLLOUT | POLLWRNORM;
...
return mask;
}
此外,如果暂时没有监听事件返回,poll可能会睡眠,因此我们需要在write、read等操作中在适当的时机唤醒等待队列中的进程。比如,写入数据之后通常设备文件可读,此时可以唤醒等待在读等待队列中的进程;而读出数据后通常设备文件可写,此时可以唤醒等待在写等待队列中的进程。
3 一些更深入的分析
以下涉及到一些源码分析,源码的版本是linux-kernel-5.3.1
3.1 从系统调用poll到驱动的xxx_poll
我们在应用层调用poll函数之后发生了什么?它是怎样一步步的调用到驱动层的poll函数的,此外,它还做了哪些事情?这些内容我们可以通过跟踪poll函数得到。
3.1.1 sys_poll
应用层的poll函数会触发80中断(在ARM平台下是软中断svc),进而根据系统调用号找到与之对应的内核函数sys_poll(一般系统调用xxx在内核中对应的函数是sys_xxx):
SYSCALL_DEFINE3(poll, struct pollfd __user *, ufds, unsigned int, nfds,
int, timeout_msecs)
{
struct timespec64 end_time, *to = NULL;
int ret;
// 对时间参数做一些处理
if (timeout_msecs >= 0) {
to = &end_time;
poll_select_set_timeout(to, timeout_msecs / MSEC_PER_SEC,
NSEC_PER_MSEC * (timeout_msecs % MSEC_PER_SEC));
}
// 调用do_sys_poll
ret = do_sys_poll(ufds, nfds, to);
if (ret == -ERESTARTNOHAND) {
// 如果出错则做一些错误处理
...
}
return ret;
}
3.1.2 do_sys_poll
static int do_sys_poll(struct pollfd __user *ufds, unsigned int nfds,
struct timespec64 *end_time)
{
// 在栈上申请了一个struct poll_wqueues类型的数据(这个数据比较重要,后面还会见到)
struct poll_wqueues table;
int err = -EFAULT, fdcount, len;
// 我们知道应用层向内核传入了一个struct pollfd类型的数组,我们要将这些数据传入内核,因此要在内核里申请空间接收这些数据;
// 而在堆上申请数据代价比较大,在栈上申请较为简单快捷,但栈上空间有限,因此这里申请了一定数量的空间,如果还是放不下后面才会在堆上再申请空间。
long stack_pps[POLL_STACK_ALLOC/sizeof(long)];
// struct poll_list是变长数组,即最后的成员是一个零长的数组,这个变长数组会占据栈上申请的空间,用于存放应用层传入的struct pollfd类型的数组
struct poll_list *const head = (struct poll_list *)stack_pps;
struct poll_list *walk = head;
unsigned long todo = nfds;
// 对进程监听的文件数量做一个限制
if (nfds > rlimit(RLIMIT_NOFILE))
return -EINVAL;
// 应用层传入的struct pollfd类型的数组大小为nfds
// 当前在栈上申请的空间可以放入N_STACK_PPS这么多的struct pollfd类型的元素
// 取两者当中小的那个
len = min_t(unsigned int, nfds, N_STACK_PPS);
// 在这个循环里把应用层传入的struct pollfd类型的数组拷贝到内核中
for (;;) {
walk->next = NULL;
walk->len = len;
if (!len)
break;
// 进行拷贝操作
if (copy_from_user(walk->entries, ufds + nfds-todo,
sizeof(struct pollfd) * walk->len))
goto out_fds;
// 将已经完成拷贝的数量减去
todo -= walk->len;
// 全部拷贝完则跳出循环
if (!todo)
break;
// 栈上的空间不够,需要在堆上申请内存
// 申请时是一页一页申请的,POLLFD_PER_PAGE表示一页内存能够存放多少struct pollfd
// 一页一页的申请有什么好处呢,申请和释放的效率更高么?这个暂不清楚
len = min(todo, POLLFD_PER_PAGE);
walk = walk->next = kmalloc(struct_size(walk, entries, len),
GFP_KERNEL);
if (!walk) {
err = -ENOMEM;
goto out_fds;
}
}
// 初始化struct poll_wqueues类型的变量table
poll_initwait(&table);
// 调用do_poll,do_poll会返回发生监听事件的文件数量
fdcount = do_poll(head, &table, end_time);
// do_poll函数中可能会申请一些资源,且这些资源被记录到变量table中,因此这里要释放
poll_freewait(&table);
// 将返回事件记录到用户空间的struct pollfd元素的revents成员中(告诉应用程序返回的是哪个监听事件)
for (walk = head; walk; walk = walk->next) {
struct pollfd *fds = walk->entries;
int j;
for (j = 0; j < walk->len; j++, ufds++)
if (__put_user(fds[j].revents, &ufds->revents))
goto out_fds;
}
err = fdcount;
out_fds:
walk = head->next;
// 如果在堆上申请了空间去存放应用层传入的数据那么在函数返回之前要释放掉
while (walk) {
struct poll_list *pos = walk;
walk = walk->next;
kfree(pos);
}
// 返回的就是do_poll的返回值,如果未出错的话会返回发生监听事件的文件数量
return err;
}
上文中,我用注释的方式大概分析了do_sys_poll所做的事情,总的来说做了这么几件事:
- 将应用层传入的struct pollfd类型的数组拷贝到内核
- 初始化了struct poll_wqueues类型的变量table
- 调用do_poll函数
- 将返回事件记录到用户空间的struct pollfd元素的revents成员
- 最终返回发生监听事件的文件数量
只有上述的注释,可能还有一些比较重要的细节没有介绍清楚,因此这里再做一些补充:
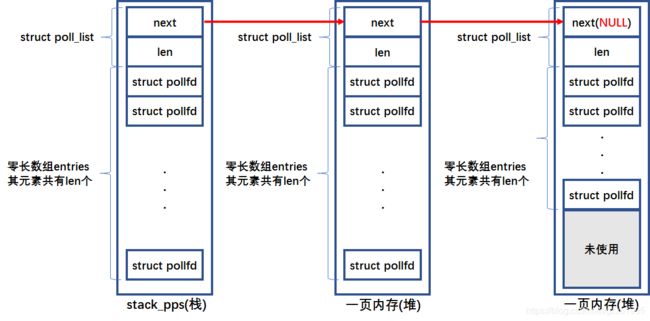
用栈和堆来存放应用层的struct pollfd数组:
内核首先在栈上申请空间,这段空间是一个long型数组,数组名为stack_pps。然后会将该数组通过强制类型转换,解释为struct poll_list类型,这个类型比较有意思,它使用了变长数组这一语言特性:
struct poll_list {
struct poll_list *next;
int len;
struct pollfd entries[0];
};
如果栈上空间不够,就会在堆上申请内存,申请时是一页一页的申请的,而这些后来申请的内存与之前堆上的内存怎么联系在一起呢?答案是struct poll_list的next成员。这种做法在内核的其他地方也有用到,这里我们使用一张图来说明:
poll_initwait(&table):
这个函数用来初始化struct poll_wqueues类型的变量table,这个结构的成员如下:
struct poll_wqueues {
poll_table pt;
struct poll_table_page *table;
struct task_struct *polling_task;
int triggered;
int error;
int inline_index;
struct poll_table_entry inline_entries[N_INLINE_POLL_ENTRIES];
};
初始化函数会为每一个成员填充初始值:
void poll_initwait(struct poll_wqueues *pwq)
{
init_poll_funcptr(&pwq->pt, __pollwait);
pwq->polling_task = current;
pwq->triggered = 0;
pwq->error = 0;
pwq->table = NULL;
pwq->inline_index = 0;
}
其中特别需要注意的是:pt成员的_qproc成员被赋值为了__pollwait;polling_task成员被赋值为了current(前进程在调用poll)。
3.1.3 do_poll
static int do_poll(struct poll_list *list, struct poll_wqueues *wait,
struct timespec64 *end_time)
{
poll_table* pt = &wait->pt;
ktime_t expire, *to = NULL;
int timed_out = 0, count = 0;
u64 slack = 0;
__poll_t busy_flag = net_busy_loop_on() ? POLL_BUSY_LOOP : 0;
unsigned long busy_start = 0;
// 如果不需要等待(应用层调用poll函数时传入timeout参数为0)
if (end_time && !end_time->tv_sec && !end_time->tv_nsec) {
pt->_qproc = NULL; // 不需要等待的话,这个函数指针(__pollwait)就不需要了
timed_out = 1; // 不需要等待则直接将超时标记置为1
}
// 需要等待的话这里会处理一下时间参数,看名字应该跟时间精度有关系
if (end_time && !timed_out)
slack = select_estimate_accuracy(end_time);
for (;;) {
struct poll_list *walk;
bool can_busy_loop = false;
// 这个循环处理应用层传入的struct pollfd类型的数组,数组中每个元素都代表一个要监听的文件
// 联系上一小节的内容,struct poll_list结构会以一个链表的形式接收应用层传入的struct pollfd,这个循环就是遍历上述链表
for (walk = list; walk != NULL; walk = walk->next) {
struct pollfd * pfd, * pfd_end;
pfd = walk->entries;
pfd_end = pfd + walk->len;
// 每个struct poll_list中都有一个变长数组,这个循环就是遍历变长数组的,这样一来用户层传入的所有struct pollfd都被遍历到了
for (; pfd != pfd_end; pfd++) {
// 对每一个要监听的文件调用do_pollfd
if (do_pollfd(pfd, pt, &can_busy_loop,
busy_flag)) {
count++; // 如果被监听的文件发生了监听的事件那么计数加1
pt->_qproc = NULL; // 既然监听事件有了,那就无需睡眠了,这个函数指针也就不需要了
...
}
}
}
// 到这里所有要监听的文件都遍历完了
pt->_qproc = NULL; // 这个函数指针起的作用是将当前进程挂到等待队列上,在驱动的poll函数中的poll_wait里面调用。这个动作在当前循环中只需要进行一次。
if (!count) {
// 没有监听事件发生
count = wait->error;
if (signal_pending(current)) // 判断进程是否收到信号
count = -ERESTARTNOHAND;
}
// 如果超时、发生错误、进程收到信号,或者有监听事件发生则跳出循环(返回count)
if (count || timed_out)
break;
// 这里应该是和套接字有关的处理,暂不深究
if (can_busy_loop && !need_resched()) {
...
}
busy_flag = 0;
// 如果应用层调用poll时选择永久延时,即timeout < 0,那么这里的end_time为NULL
// 因此这里的条件判断是针对timeout >= 0的情况,且to需要是NULL,即这个循环第一次执行到这里才会执行这个分支
if (end_time && !to) {
// 如果需要延时,那么我们需要把延时时间转换成ktime_t类型,后面的睡眠函数只认ktime_t类型的时间参数
expire = timespec64_to_ktime(*end_time);
to = &expire;
}
// 运行到这里说明没有监听事件发生,且应用层的timeout != 0,需要睡眠
// 调用poll_schedule_timeout函数进行睡眠,直到超时,或被唤醒(要么被信号唤醒,要么被读写等驱动程序从相应的等待队列中唤醒)
if (!poll_schedule_timeout(wait, TASK_INTERRUPTIBLE, to, slack))
timed_out = 1;
}
return count;
}
上述内容比较多,因此还是做一个总结,总的来说do_poll函数做了这么几件事情:
- 根据是否需要延时做一些处理(不需要延时的话会把超时参数置1)
- 在一个大循环中:遍历每一个被监听的文件,并调用do_pollfd处理这些被监听的文件;对于有监听事件的文件进行计数;如果有监听事件/信号/超时/出错,则跳出循环,否则进行睡眠
do_poll调用了一个非常关键的函数do_pollfd,接下来就分析这个函数。
3.1.4 do_pollfd
static inline __poll_t do_pollfd(struct pollfd *pollfd, poll_table *pwait,
bool *can_busy_poll,
__poll_t busy_flag)
{
int fd = pollfd->fd;
__poll_t mask = 0, filter;
struct fd f;
// 校验文件描述符的合法性
if (fd < 0)
goto out;
mask = EPOLLNVAL;
// 根据文件描述符从当前进程获取文件对象(struct file)
f = fdget(fd);
if (!f.file)
goto out;
filter = demangle_poll(pollfd->events) | EPOLLERR | EPOLLHUP;
pwait->_key = filter | busy_flag;
// 调用vfs_poll处理要监听的文件,返回该文件的所有事件(如POLLIN、POLLOUT等)
mask = vfs_poll(f.file, pwait);
if (mask & busy_flag)
*can_busy_poll = true;
// 过滤掉我们不关心的事件(我们只关心需要监听的事件,即应用层event指定的事件)
mask &= filter;
fdput(f);
out:
/* ... and so does ->revents */
pollfd->revents = mangle_poll(mask);
return mask;
}
可见,正真干活的函数是vfs_poll,其实也就是这个函数,调用了驱动层的poll函数,我们终于接近真相了!
3.1.5 vfs_poll
static inline __poll_t vfs_poll(struct file *file, struct poll_table_struct *pt)
{
// 如果我们没有在驱动层注册相应的poll函数,则返回DEFAULT_POLLMASK(内核认为这个可能性不大,毕竟既然应用层有poll的需求,驱动层就应该提供相应的poll函数)
if (unlikely(!file->f_op->poll))
return DEFAULT_POLLMASK;
// 调用驱动层的poll函数(一般被命名为xxx_poll),返回值就是xxx_poll的返回值
return file->f_op->poll(file, pt);
}
终于,我们跟踪完了从应用层的poll到驱动层的xxx_poll的整个调用栈。在xxx_poll中,一般会根据设备的情况,将相应的标志置位并返回。比如,如设备此时有数据可读,我们会置位POLLIN;设备有数据可写,我们会置位POLLOUT。
3.1.6 总结
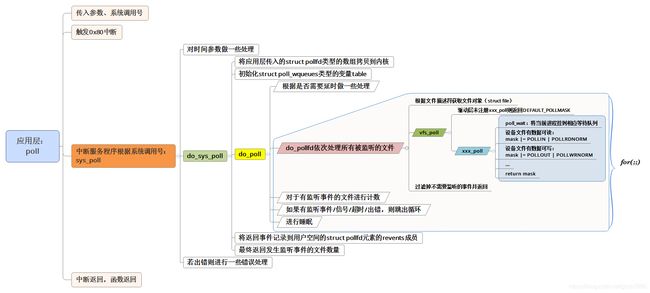
以上的跟踪过程内容比较多,有必要在对其进行一个梳理。考虑到图比文字更有表现力,因此这里我使用一幅图来对上述内容做一个总结:
3.2 poll_wait做了什么
上文已经介绍过,驱动程序中xxx_poll会调用poll_wait函数将当前进程挂到等待列表上,poll_wait的原型如下:
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
其中参数wait_address是一个等待队列,粗看这个原型,应该是把当前进程挂到wait_address上(事实也是如此)。不过看到有些文献上有这样的表述“poll_wait所做的工作是把当前进程添加到wait参数指定的等待列表(poll_table)中”,个人感觉这样的表述不妥,让人迷惑,poll_table中只有一个函数指针,一个key字段,哪来的“等待列表”?于是决定分析一下这个函数,也为后来者提供一点资料。
3.2.1 poll_wait的定义
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address)
p->_qproc(filp, wait_address, p);
}
3.2.2 __pollwait
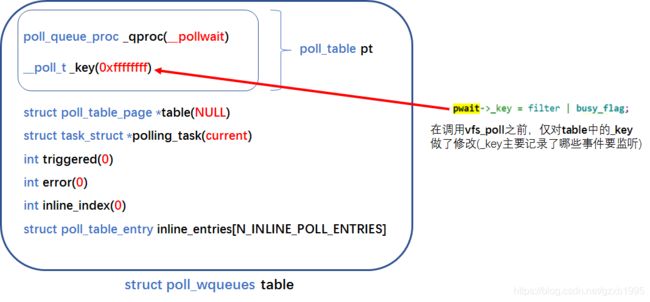
我们传给poll_wait的参数p,实际上指向的是do_sys_poll中定义的struct poll_wqueues类型的变量table的pt成员。回忆一下上文,table的pt成员的_qproc成员被赋值为了__pollwait;polling_task成员被赋值为了current,其他成员也都在poll_initwait中做了初始化(下图红色加粗的是各成员初始化的值):
因此我们调用poll_wait实际上是调用__pollwait。在给出__pollwait函数的定义并对其进行分析之前,我们还要看一个结构struct poll_table_entry。这个结构对于我们理解__pollwait函数有帮助:
struct poll_table_entry {
struct file *filp; // 文件对象
__poll_t key;
wait_queue_entry_t wait; // 等待队列元素
wait_queue_head_t *wait_address; // 等待队列头部
};
这个结构和poll的睡眠有很大的关系,从它的成员类型大概可以猜出进程会被挂到wait_address指向的等待队列,而使用的等待队列元素就是wait。
好了,现在我们开始分析__pollwait函数:
static void __pollwait(struct file *filp, wait_queue_head_t *wait_address, poll_table *p)
{
// pwq指向的是前文所说的变量table
struct poll_wqueues *pwq = container_of(p, struct poll_wqueues, pt);
// 申请一个poll_table_entry类型的变量,并将其地址返回给entry
struct poll_table_entry *entry = poll_get_entry(pwq);
if (!entry)
return;
// 将filp赋值给entry的filp成员,get_file起到的作用是将filp指向的文件对象的引用计数加1
entry->filp = get_file(filp);
// 将调用poll_wait时传入的等待队列赋值给entry的wait_address成员
entry->wait_address = wait_address;
// 将table变量的pt成员的_key成员赋值给entry的key成员
entry->key = p->_key;
// entry的wait成员是一个等待队列元素
// 这里会将这个等待队列元素的各个成员做一个初始化
// flags = 0;
// private = NULL;
// func = pollwake;
init_waitqueue_func_entry(&entry->wait, pollwake);
// private = &table
entry->wait.private = pwq;
// 将entry的wait成员添加到调用poll_wait时传入的等待队列
add_wait_queue(wait_address, &entry->wait);
}
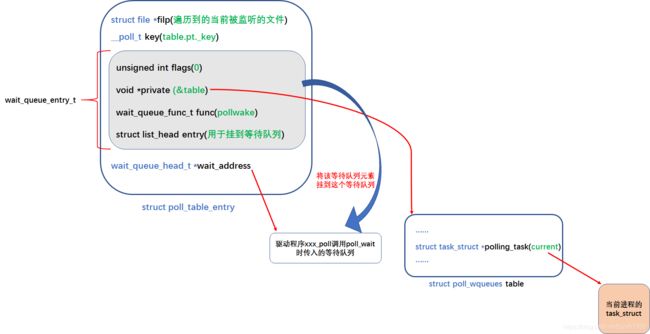
可以看到,在__pollwait函数中,kernel会申请一个struct poll_table_entry类型的变量,使用这个变量的wait成员(一个等待队列元素)记录当前进程,并挂接到该变量的wait_address成员指向的等待队列(挂接到等待队列的是等待队列元素,这个元素会通过指针或直接或间接的指向当前进程):
3.2.3 一些补充说明
到这里我们已经说清楚了poll_wait函数做了哪些事情,在结束这一小节之前,我再做一些补充说明,主要关于:
① 使用poll_get_entry函数申请struct poll_table_entry的一些细节;
② poll_freewait函数。
下面开始说明:
① poll_get_entry:
使用该函数申请struct poll_table_entry时,会先在table变量的inline_entries成员(struct poll_table_entry类型的数组)中寻找可用空间,如果找不到,就会在堆上申请内存,一次申请一页,table变量的table成员(struct poll_table_page *类型)就会指向申请到的页。用完一页就会再申请一页,以头插的方式插入table变量的table成员指向的页链。这个用栈空间来优化性能、用链表来串联多个内存页的做法之前已经遇到,不再多说,给一幅图就都清楚了:
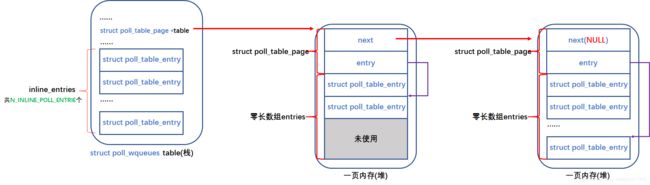
② poll_freewait:
使用poll去监听多个文件时,最终会调用到每个文件在驱动层的xxx_poll函数,这个函数又会调用poll_wait,进而调用__pollwait,在这个函数里面会调用poll_get_entry函数申请struct poll_table_entry,并将任务挂到调用poll_wait时指定的等待队列。假如要监听的文件有监听事件,poll就会返回,那么我们之前向等待队列挂接的等待队列元素就需要移除,申请的struct poll_table_entry就需要被释放。这些操作都发生在poll_freewait:
void poll_freewait(struct poll_wqueues *pwq)
{
struct poll_table_page * p = pwq->table;
int i;
for (i = 0; i < pwq->inline_index; i++)
free_poll_entry(pwq->inline_entries + i); // 从等待队列移除等待队列元素
while (p) {
// 在堆内存申请了空间
struct poll_table_entry * entry;
struct poll_table_page *old;
entry = p->entry;
do {
entry--;
free_poll_entry(entry); // 移除等待队列元素
} while (entry > p->entries);
old = p;
p = p->next;
free_page((unsigned long) old); // 释放页
}
}
PS:对私有数据的使用的一些体会
至此,一定程度上,应该已经把Linux的poll机制的一些基本内容说清楚了。在阅读源码的过程中,我学到了一些优化性能的技巧,以及关于私有数据(private)使用的一些技巧,这里记录一些我对私有数据的使用的一些体会:
通常使用void *类型的指针来指向私有数据,私有数据的内含只有私有数据的提供者才知道,kernel是不知道的,因此怎么去解读并处理私有数据,也应该由私有数据的提供者给出。换句话说,我们给指向私有数据的指针赋值为私有数据的地址,也要提供处理私有数据的函数,因为只有我们自己知道私有数据的内容。内核会在适当的时候调用我们提供的函数处理我们提供的私有数据。
这样做的好处是可以让kernel中的在适当的时候调用我们提供的函数处理我们提供的私有数据这一机制保持稳定,同时私有数据可以根据实际需要灵活多变,只要提供不同的处理私有数据的函数即可。
举例:
① 在Linux的poll机制中,我们将等待队列元素的private成员指向了变量table,同时将func成员指向了pollwake,pollwake知道等待队列元素的private指向的是table。pollwake在等待队列被唤醒时会被调用,它能够正确的处理private。
② 我们使用DECLARE_WAITQUEUE来定义等待队列元素时,private成员指向了current,func成员指向了default_wake_function,default_wake_function会把private解读成struct task_struct *类型的指针。
4 select和poll
loading…
5 epoll又是怎么回事
loading…
6 参考文献
[1] 韦东山老师一期视频教程
[2] linux-kernel-5.3.1