python3读写csv
以前的要用rb来读,python3直接读就行
pandas也可以
import csv
with open('test.csv','r')as f:
f_csv = csv.reader(f)
for row in f_csv:
print(row)import csv
headers = ['class','name','sex','height','year']
rows = [
[1,'xiaoming','male',168,23],
[1,'xiaohong','female',162,22],
[2,'xiaozhang','female',163,21],
[2,'xiaoli','male',158,21]
]
with open('test.csv','w')as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)
f_csv.writerows(rows)
2、写入字典序列的数据
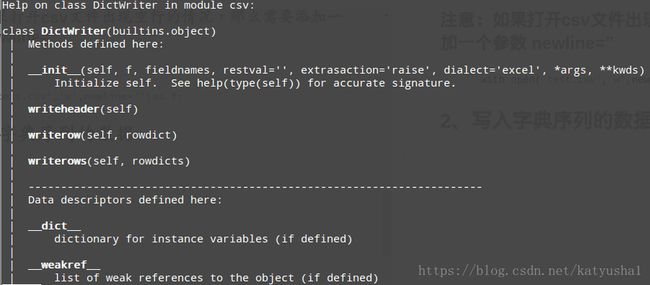
参考help(csv.DictWriter)可知,在写入字典序列类型数据的时候,需要传入两个参数,一个是文件对象——f,一个是字段名称——fieldnames,到时候要写入表头的时候,只需要调用writerheader方法,写入一行字典系列数据调用writerrow方法,并传入相应字典参数,写入多行调用writerows
具体代码如下:
import csv
headers = ['class','name','sex','height','year']
rows = [
{'class':1,'name':'xiaoming','sex':'male','height':168,'year':23},
{'class':1,'name':'xiaohong','sex':'female','height':162,'year':22},
{'class':2,'name':'xiaozhang','sex':'female','height':163,'year':21},
{'class':2,'name':'xiaoli','sex':'male','height':158,'year':21},
]
with open('test2.csv','w',newline='')as f:
f_csv = csv.DictWriter(f,headers)
f_csv.writeheader()
f_csv.writerows(rows)