spark 决策树浅谈
一、决策树是一种分类算法,类似于我们写程序过程中的if-else判断,但是在判断的过程中又加入了一些信息论的熵的概念以及基尼系数的概念。
spark中有决策树的分类算法,又有决策树的回归算法。我用到了分类算法,就暂且分享一下我对决策树分类算法的理解。
二、决策树的基本模型
1、先看一个广为流传的例子----某网站的相亲数据
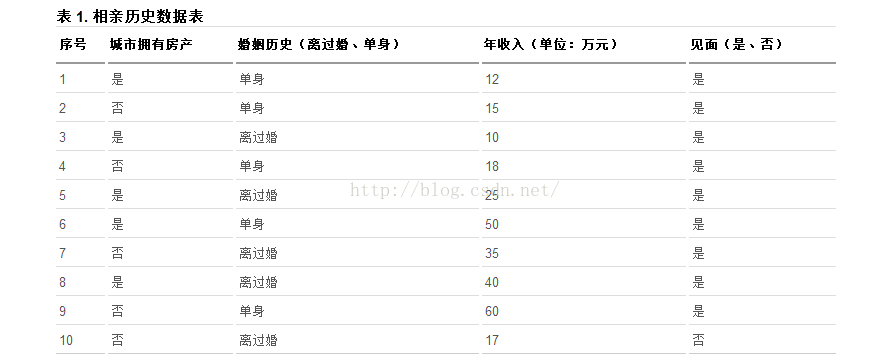
图一——相亲数据
这个表记录了相亲网站男士的数据,女士可与根据这个记录来决定要不要见这个相亲对象。
怎样根据这些数据来做最后的决定呢?也就是一个决策树。
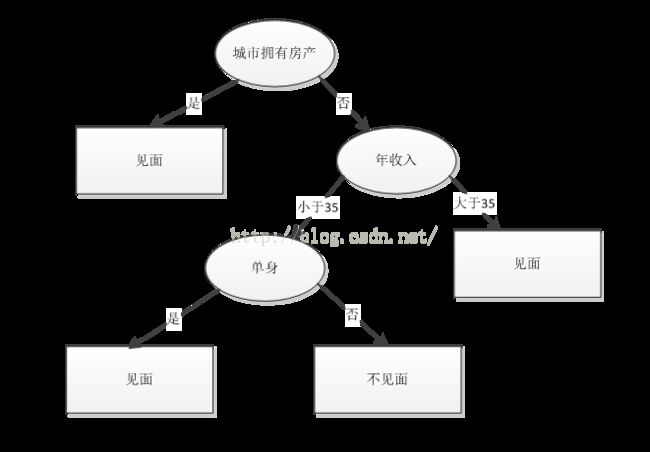
图2 ——决策树示意图
决策树的形状就是这样的,类似于我们做一件事情之前,先考虑各种情况,考虑完一个再考量另一个,直到把所有数据都考虑完以后再做最后的决定。
决策数的构建过程:
1、每一行作为一个记录;
2、每一列作为一个属性;
3、最后一列是最后的决定,也就是见或不见两种结果;
4、计算每一个属性的信息增益;(下面会讲到什么是信息增益)。选择信息增益最大的最为一个节点,向左向右各形成一个分支,也就是上面3中提到的见或不见的结果。
5、然后对下面的分支节点再重复上面的步骤4,直到用完所有属性或者该分支已经无法再分(比如城市有房产的一定见面,它不用再考量其它情况);
a、决策树的构建过程重点在节点的选取上,不是盲目的选择任意一个节点作为根节点的。需要用到熵的概念:
以上面的表格为例,最后的结果是分类两个也就是1、见,2、不见。 每一个类别所占的比例为 ![]() (k=1,2,3...K)次数K为我们所分的类别个数,本例中K为2,也就是i取1,2.
(k=1,2,3...K)次数K为我们所分的类别个数,本例中K为2,也就是i取1,2.
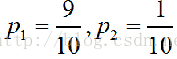 ,p1代表见面的,p2代表不见面的。信息熵的表达式为:
,p1代表见面的,p2代表不见面的。信息熵的表达式为:。熵代表这个概率空间的纯度,说白了也就是这个概率空间取值的绝对性(比如在有房和无房之间,我们几乎可以说有房一定见面)。另外学过信息论的都知道,熵是关于概率分布的上凸函数,此处不再作图,简单描述一下。当概率空间是平均分布的时候,我们的熵可以去到最大值,当概率全取为0或者1时,熵值为0,两端为0 ,中间为1,也就是上凸函数。熵越大,不确定性越大,熵越小,不确定性越小,越纯。
b、信息增益。
信息增益是指某一个属性的信息增益,以属性1城市是否拥有房产为例。 
房产这个属性分为两种情况,有和无![]() ,
,![]() 是所有记录的一个子集,v分为两种情况(有 无),每一种情况中各有5条记录,同时每条记录的结果又分为见面和不见面,首先要计算Ent(Dv),然后在计算信息增益
是所有记录的一个子集,v分为两种情况(有 无),每一种情况中各有5条记录,同时每条记录的结果又分为见面和不见面,首先要计算Ent(Dv),然后在计算信息增益
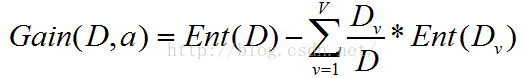
Ent(D1) = 0,Ent(D2) =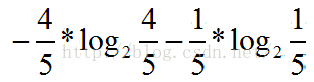
D1/D = 0.5,D2/D = 0.5。这样就可以计算出增益了,同理计算其他的所有属性的信息增益,选择增益最大的一个属性作为分支点,以此类推,就可以生成一个决策树。
二、spark中的决策树算法。
重点讲一下针对连续特征是如何处理的,何为连续特征?先看一下什么是离散特征,比如是否拥有房产,就两种情况是 否,这种就为离散特征或者是名称特征。那比如说年龄12 ,13 ,16 ,19 ,30,32,45,21,78,90,50,。你第一眼看去,这不是连续的啊,取值连续不就是离散的吗?对,你说的没错,从信号的角度老看这就是离散数据,但是这样的话就是一个年龄一个类别,我们仅仅以年龄就可以确定最后的结果,这样好吗?显然是片面的,那就要想办法把他变为离散的数据,从理论上来讲,我们可以以每一个数据作为一个分割点,小于这个数据作为一类,大于这个数据作为另一类。对于少量的数据这没问题,但是对于百万条,亿级别的数据显然是不可取的。在spark中采用了一种采样的策略。
对于离散无序数据比如:老,中,少。有几种分割方法,老,中|少,老|中,少,老|少,中。仅此三种,也就是2^(M-1)-1种。
对于离散有序数据比如:老,中,少。有老|中,少,老,中|少,仅两种情况,也就是M-1种情况。
对于连续数据,本质上是有无数种分割情况,但是spark采用了一种采样策略。先对一个特征下的所有数据进行排序,然后人为的设定一个划分区间,划分区间确定了,也就是确定了划分点,二者是减一关系,当然这个划分区间也是你后期调参数的一个重要特征。一下面几个数据为例:
12, 14 ,16 ,11, 43, 32, 45, 56, 54, 89, 76
首先进行排序:11,12,12,16,32,43,45,54,56,76,89。
其次设定划分区间,比如为3,就是说3个数据作为一组,相应的划分点也就是出来了。12,43,56,89分别作为划分点,然后计算他们每个作为划分点的信息增益,选择增益最大的一个点作为最终的划分点。就这么简单。但是实现起来就没有这么简单了,先看一个决策树的demo,再看源码。
这是随机森林的一个例子,随机森林将树的个数设为1,就是一颗决策树,spark在调用决策数的的类时,其实是调用了随机森林的构造函数:
public static void medicalRandomForest(JavaRDD train,JavaRDD test) throws IOException{
System.out.println("*****随机森林开始计算*****");
int numClasses = 2;
//categoricalFeaturesInfo为空,意味着所有的特征为连续性变量
HashMap categoricalFeaturesInfo = new HashMap<>();
int numTrees = 7;
String featureSubStrategy = "auto";//每个节点考虑的特征数量(auto时根据numTree来决定)
String impurity = "gini";//信息增益的计算标准
int maxDepth = 6;
int maxBins = 25;//特征最大装箱数,划分区间的长度
int seed = 12345;//选择特征子集的随机种子
// File dtResult = new File("rfMaxBins.txt");
// FileWriter dtOut = new FileWriter(dtResult);
// for(maxBins=3; maxBins<=100; maxBins++){
final RandomForestModel rfModel = RandomForest.trainClassifier(train, numClasses,
categoricalFeaturesInfo, numTrees, featureSubStrategy, impurity, maxDepth, maxBins,
seed);
JavaRDD>scoresAndLabelTrain = train.map(line -> {
double score = rfModel.predict(line.features());
return new Tuple2 (score, line.label());
});
JavaRDD> scoresAndLabelTest = test.map(line -> {
double score = rfModel.predict(line.features());
return new Tuple2 (score, line.label());
});
double trainPre = 1.0 - (1.0 * scoresAndLabelTrain.filter(p1 -> {
return !p1._1().equals(p1._2());
}).count()/train.count());
double testPre = 1.0 - (1.0 * scoresAndLabelTest.filter(p1 -> {
return !p1._1().equals(p1._2());
}).count()/test.count());
// dtOut.write(maxBins+" "+trainPre+" "+testPre);
// dtOut.write("\r\n");
System.out.println("trainPre = "+ trainPre);
System.out.println("testPre = " + testPre);
System.out.println("测试集的结果显示:");
BinaryClassificationMetrics metricTrain = new BinaryClassificationMetrics(scoresAndLabelTrain.rdd());
System.out.println("训练集 Area under ROC = "+ metricTrain.areaUnderROC());
BinaryClassificationMetrics metricTest = new BinaryClassificationMetrics(scoresAndLabelTest.rdd());
System.out.println("测试集 Area under ROC = "+ metricTest.areaUnderROC());
System.out.println("Learned classification forest model:\n" + rfModel.toDebugString());
System.out.println("maxBins = " +maxBins + "*****随机森林计算结束*****");
// }
// dtOut.close();
} 随机森林中关键的类是 org.apache.spark.mllib.tree.RandomForest、org.apache.spark.mllib.tree.model.RandomForestModel 这两个类,它们提供了随机森林具体的 trainClassifier 和 predict 函数。
从上面的 demo 中可以看到,训练随机森林算法采用的是 RandomForest 的伴生对象中的 trainClassifier 方法,其源码如下:
三、随机森林的源码分析:源码1:
def trainClassifier(
input: RDD[LabeledPoint],
numClasses: Int,
categoricalFeaturesInfo: Map[Int, Int],
numTrees: Int,
featureSubsetStrategy: String,
impurity: String,
maxDepth: Int,
maxBins: Int,
seed: Int = Utils.random.nextInt()): RandomForestModel = {
val impurityType = Impurities.fromString(impurity)
val strategy = new Strategy(Classification, impurityType, maxDepth,
numClasses, maxBins, Sort, categoricalFeaturesInfo)
//调用的是重载的另外一个 trainClassifier
trainClassifier(input, strategy, numTrees, featureSubsetStrategy, seed)
}重载后 trainClassifier 方法代码如下:
源码2:
def trainClassifier(
input: RDD[LabeledPoint],
strategy: Strategy,
numTrees: Int,
featureSubsetStrategy: String,
seed: Int): RandomForestModel = {
require(strategy.algo == Classification,
s"RandomForest.trainClassifier given Strategy with invalid algo: ${strategy.algo}")
//在该方法中创建 RandomForest 对象
val rf = new RandomForest(strategy, numTrees, featureSubsetStrategy, seed)
//再调用其 run 方法,传入的参数是类型 RDD[LabeledPoint],方法返回的是 RandomForestModel 实例
rf.run(input)
}源码3:
def run(input: RDD[LabeledPoint]): RandomForestModel = {
val timer = new TimeTracker()
timer.start("total")
timer.start("init")
val retaggedInput = input.retag(classOf[LabeledPoint])
//建立决策树的元数据信息(分裂点位置、箱子数及各箱子包含特征属性的值等等)
val metadata =
DecisionTreeMetadata.buildMetadata(retaggedInput, strategy, numTrees, featureSubsetStrategy)
logDebug("algo = " + strategy.algo)
logDebug("numTrees = " + numTrees)
logDebug("seed = " + seed)
logDebug("maxBins = " + metadata.maxBins)
logDebug("featureSubsetStrategy = " + featureSubsetStrategy)
logDebug("numFeaturesPerNode = " + metadata.numFeaturesPerNode)
logDebug("subsamplingRate = " + strategy.subsamplingRate)
// Find the splits and the corresponding bins (interval between the splits) using a sample
// of the input data.
timer.start("findSplitsBins")
//找到切分点(splits)及箱子信息(Bins)
//对于连续型特征,利用切分点抽样统计简化计算
//对于名称型特征,如果是无序的,则最多有个 splits=2^(numBins-1)-1 划分
//如果是有序的,则最多有 splits=numBins-1 个划分
val (splits, bins) = DecisionTree.findSplitsBins(retaggedInput, metadata)
timer.stop("findSplitsBins")
logDebug("numBins: feature: number of bins")
logDebug(Range(0, metadata.numFeatures).map { featureIndex =>
s"\t$featureIndex\t${metadata.numBins(featureIndex)}"
}.mkString("\n"))
// Bin feature values (TreePoint representation).
// Cache input RDD for speedup during multiple passes.
//转换成树形的 RDD 类型,转换后,所有样本点已经按分裂点条件分到了各自的箱子中
val treeInput = TreePoint.convertToTreeRDD(retaggedInput, bins, metadata)
val withReplacement = if (numTrees > 1) true else false
// convertToBaggedRDD 方法使得每棵树就是样本的一个子集
val baggedInput
= BaggedPoint.convertToBaggedRDD(treeInput,
strategy.subsamplingRate, numTrees,
withReplacement, seed).persist(StorageLevel.MEMORY_AND_DISK)
// depth of the decision tree
val maxDepth = strategy.maxDepth
require(maxDepth <= 30,
s"DecisionTree currently only supports maxDepth <= 30, but was given maxDepth = $maxDepth.")
// Max memory usage for aggregates
// TODO: Calculate memory usage more precisely.
val maxMemoryUsage: Long = strategy.maxMemoryInMB * 1024L * 1024L
logDebug("max memory usage for aggregates = " + maxMemoryUsage + " bytes.")
val maxMemoryPerNode = {
val featureSubset: Option[Array[Int]] = if (metadata.subsamplingFeatures) {
// Find numFeaturesPerNode largest bins to get an upper bound on memory usage.
Some(metadata.numBins.zipWithIndex.sortBy(- _._1)
.take(metadata.numFeaturesPerNode).map(_._2))
} else {
None
}
//计算聚合操作时节点的内存
RandomForest.aggregateSizeForNode(metadata, featureSubset) * 8L
}
require(maxMemoryPerNode <= maxMemoryUsage,
s"RandomForest/DecisionTree given maxMemoryInMB = ${strategy.maxMemoryInMB}," +
" which is too small for the given features." +
s" Minimum value = ${maxMemoryPerNode / (1024L * 1024L)}")
timer.stop("init")
/*
* The main idea here is to perform group-wise training of the decision tree nodes thus
* reducing the passes over the data from (# nodes) to (# nodes / maxNumberOfNodesPerGroup).
* Each data sample is handled by a particular node (or it reaches a leaf and is not used
* in lower levels).
*/
// Create an RDD of node Id cache.
// At first, all the rows belong to the root nodes (node Id == 1).
//节点是否使用缓存,节点 ID 从 1 开始,1 即为这颗树的根节点,左节点为 2,右节点为 3,依次递增下去
val nodeIdCache = if (strategy.useNodeIdCache) {
Some(NodeIdCache.init(
data = baggedInput,
numTrees = numTrees,
checkpointInterval = strategy.checkpointInterval,
initVal = 1))
} else {
None
}
// FIFO queue of nodes to train: (treeIndex, node)
val nodeQueue = new mutable.Queue[(Int, Node)]()
val rng = new scala.util.Random()
rng.setSeed(seed)
// Allocate and queue root nodes.
//创建树的根节点
val topNodes: Array[Node] = Array.fill[Node](numTrees)(Node.emptyNode(nodeIndex = 1))
//将(树的索引,数的根节点)入队,树索引从 0 开始,根节点从 1 开始
Range(0, numTrees).foreach(treeIndex => nodeQueue.enqueue((treeIndex, topNodes(treeIndex))))
while (nodeQueue.nonEmpty) {
// Collect some nodes to split, and choose features for each node (if subsampling).
// Each group of nodes may come from one or multiple trees, and at multiple levels.
// 取得每个树所有需要切分的节点
val (nodesForGroup, treeToNodeToIndexInfo) =
RandomForest.selectNodesToSplit(nodeQueue, maxMemoryUsage, metadata, rng)
// Sanity check (should never occur):
assert(nodesForGroup.size > 0,
s"RandomForest selected empty nodesForGroup. Error for unknown reason.")
// Choose node splits, and enqueue new nodes as needed.
timer.start("findBestSplits")
//找出最优切点
DecisionTree.findBestSplits(baggedInput, metadata, topNodes, nodesForGroup,
treeToNodeToIndexInfo, splits, bins, nodeQueue, timer, nodeIdCache = nodeIdCache)
timer.stop("findBestSplits")
}
baggedInput.unpersist()
timer.stop("total")
logInfo("Internal timing for DecisionTree:")
logInfo(s"$timer")
// Delete any remaining checkpoints used for node Id cache.
if (nodeIdCache.nonEmpty) {
try {
nodeIdCache.get.deleteAllCheckpoints()
} catch {
case e: IOException =>
logWarning(s"delete all checkpoints failed. Error reason: ${e.getMessage}")
}
}
val trees = topNodes.map(topNode => new DecisionTreeModel(topNode, strategy.algo))
new RandomForestModel(strategy.algo, trees)
}
}源码4:
/**
* Returns splits and bins for decision tree calculation.
* Continuous and categorical features are handled differently.
*
* Continuous features:
* For each feature, there are numBins - 1 possible splits representing the possible binary
* decisions at each node in the tree.
* This finds locations (feature values) for splits using a subsample of the data.
*
* Categorical features:
* For each feature, there is 1 bin per split.
* Splits and bins are handled in 2 ways:
* (a) "unordered features"
* For multiclass classification with a low-arity feature
* (i.e., if isMulticlass && isSpaceSufficientForAllCategoricalSplits),
* the feature is split based on subsets of categories.
* (b) "ordered features"
* For regression and binary classification,
* and for multiclass classification with a high-arity feature,
* there is one bin per category.
*
* @param input Training data: RDD of [[org.apache.spark.mllib.regression.LabeledPoint]]
* @param metadata Learning and dataset metadata
* @return A tuple of (splits, bins).
* Splits is an Array of [[org.apache.spark.mllib.tree.model.Split]]
* of size (numFeatures, numSplits).
* Bins is an Array of [[org.apache.spark.mllib.tree.model.Bin]]
* of size (numFeatures, numBins).
*/
protected[tree] def findSplitsBins(
input: RDD[LabeledPoint],
metadata: DecisionTreeMetadata): (Array[Array[Split]], Array[Array[Bin]]) = {
logDebug("isMulticlass = " + metadata.isMulticlass)
val numFeatures = metadata.numFeatures
// Sample the input only if there are continuous features.
// 判断特征中是否存在连续特征
val hasContinuousFeatures = Range(0, numFeatures).exists(metadata.isContinuous)
val sampledInput = if (hasContinuousFeatures) {
// Calculate the number of samples for approximate quantile calculation.
//采样样本数量,最少应该为 10000 个
val requiredSamples = math.max(metadata.maxBins * metadata.maxBins, 10000)
//计算采样比例
val fraction = if (requiredSamples < metadata.numExamples) {
requiredSamples.toDouble / metadata.numExamples
} else {
1.0
}
logDebug("fraction of data used for calculating quantiles = " + fraction)
input.sample(withReplacement = false, fraction, new XORShiftRandom().nextInt()).collect()
} else {
//如果为离散特征,则构建一个空数组(即无需采样)
new Array[LabeledPoint](0)
}
// //分裂点策略,目前 Spark 中只实现了一种策略:排序 Sort
metadata.quantileStrategy match {
case Sort =>
//每个特征分别对应一组切分点位置
val splits = new Array[Array[Split]](numFeatures)
//存放切分点位置对应的箱子信息
val bins = new Array[Array[Bin]](numFeatures)
// Find all splits.
// Iterate over all features.
var featureIndex = 0
//遍历所有的特征
while (featureIndex < numFeatures) {
//特征为连续的情况
if (metadata.isContinuous(featureIndex)) {
val featureSamples = sampledInput.map(lp => lp.features(featureIndex))
// findSplitsForContinuousFeature 返回连续特征的所有切分位置
val featureSplits = findSplitsForContinuousFeature(featureSamples,
metadata, featureIndex)
val numSplits = featureSplits.length
//连续特征的箱子数为切分点个数+1
val numBins = numSplits + 1
logDebug(s"featureIndex = $featureIndex, numSplits = $numSplits")
//切分点数组及特征箱子数组
splits(featureIndex) = new Array[Split](numSplits)
bins(featureIndex) = new Array[Bin](numBins)
var splitIndex = 0
//遍历切分点
while (splitIndex < numSplits) {
//获取切分点对应的值,由于是排过序的,因此它具有阈值属性
val threshold = featureSplits(splitIndex)
//保存对应特征所有的切分点位置信息
splits(featureIndex)(splitIndex) =
new Split(featureIndex, threshold, Continuous, List())
splitIndex += 1
}
//采用最小阈值 Double.MinValue 作为最左边的分裂位置并进行装箱
bins(featureIndex)(0) = new Bin(new DummyLowSplit(featureIndex, Continuous),
splits(featureIndex)(0), Continuous, Double.MinValue)
splitIndex = 1
//除最后一个箱子外剩余箱子的计算,各箱子里将存放的是两个切分点位置阈值区间的属性值
while (splitIndex < numSplits) {
bins(featureIndex)(splitIndex) =
new Bin(splits(featureIndex)(splitIndex - 1), splits(featureIndex)(splitIndex),
Continuous, Double.MinValue)
splitIndex += 1
}
//最后一个箱子的计算采用最大阈值 Double.MaxValue 作为最右边的切分位置
bins(featureIndex)(numSplits) = new Bin(splits(featureIndex)(numSplits - 1),
new DummyHighSplit(featureIndex, Continuous), Continuous, Double.MinValue)
} else { //特征为离散情况时的计算
val numSplits = metadata.numSplits(featureIndex)
val numBins = metadata.numBins(featureIndex)
// Categorical feature
//离线属性的个数
val featureArity = metadata.featureArity(featureIndex)
//特征无序时的处理方式
if (metadata.isUnordered(featureIndex)) {
// Unordered features
// 2^(maxFeatureValue - 1) - 1 combinations
splits(featureIndex) = new Array[Split](numSplits)
var splitIndex = 0
while (splitIndex < numSplits) {
//提取特征的属性值,返回集合包含其中一个或多个的离散属性值
val categories: List[Double] =
extractMultiClassCategories(splitIndex + 1, featureArity)
splits(featureIndex)(splitIndex) =
new Split(featureIndex, Double.MinValue, Categorical, categories)
splitIndex += 1
}
} else {
//有序特征无需处理,箱子与特征值对应
// Ordered features
// Bins correspond to feature values, so we do not need to compute splits or bins
// beforehand. Splits are constructed as needed during training.
splits(featureIndex) = new Array[Split](0)
}
// For ordered features, bins correspond to feature values.
// For unordered categorical features, there is no need to construct the bins.
// since there is a one-to-one correspondence between the splits and the bins.
bins(featureIndex) = new Array[Bin](0)
}
featureIndex += 1
}
(splits, bins)
case MinMax =>
throw new UnsupportedOperationException("minmax not supported yet.")
case ApproxHist =>
throw new UnsupportedOperationException("approximate histogram not supported yet.")
}
}源码5:
/**
* Find the best split for a node.
* @param binAggregates Bin statistics.
* @return tuple for best split: (Split, information gain, prediction at node)
*/
private def binsToBestSplit(
binAggregates: DTStatsAggregator, // DTStatsAggregator,其中引用了 ImpurityAggregator,给出计算不纯度 impurity 的逻辑
splits: Array[Array[Split]],
featuresForNode: Option[Array[Int]],
node: Node): (Split, InformationGainStats, Predict) = {
// calculate predict and impurity if current node is top node
val level = Node.indexToLevel(node.id)
var predictWithImpurity: Option[(Predict, Double)] = if (level == 0) {
None
} else {
Some((node.predict, node.impurity))
}
// For each (feature, split), calculate the gain, and select the best (feature, split).
//对各特征及切分点,计算其信息增益并从中选择最优 (feature, split)
val (bestSplit, bestSplitStats) =
Range(0, binAggregates.metadata.numFeaturesPerNode).map { featureIndexIdx =>
val featureIndex = if (featuresForNode.nonEmpty) {
featuresForNode.get.apply(featureIndexIdx)
} else {
featureIndexIdx
}
val numSplits = binAggregates.metadata.numSplits(featureIndex)
//特征为连续值的情况
if (binAggregates.metadata.isContinuous(featureIndex)) {
// Cumulative sum (scanLeft) of bin statistics.
// Afterwards, binAggregates for a bin is the sum of aggregates for
// that bin + all preceding bins.
val nodeFeatureOffset = binAggregates.getFeatureOffset(featureIndexIdx)
var splitIndex = 0
while (splitIndex < numSplits) {
binAggregates.mergeForFeature(nodeFeatureOffset, splitIndex + 1, splitIndex)
splitIndex += 1
}
// Find best split.
val (bestFeatureSplitIndex, bestFeatureGainStats) =
Range(0, numSplits).map { case splitIdx =>
//计算 leftChild 及 rightChild 子节点的 impurity
val leftChildStats = binAggregates.getImpurityCalculator(nodeFeatureOffset, splitIdx)
val rightChildStats = binAggregates.getImpurityCalculator(nodeFeatureOffset, numSplits)
rightChildStats.subtract(leftChildStats)
//求 impurity 的预测值,采用的是平均值计算
predictWithImpurity = Some(predictWithImpurity.getOrElse(
calculatePredictImpurity(leftChildStats, rightChildStats)))
//求信息增益 information gain 值,用于评估切分点是否最优
val gainStats = calculateGainForSplit(leftChildStats,
rightChildStats, binAggregates.metadata, predictWithImpurity.get._2)
(splitIdx, gainStats)
}.maxBy(_._2.gain)
(splits(featureIndex)(bestFeatureSplitIndex), bestFeatureGainStats)
} else if (binAggregates.metadata.isUnordered(featureIndex)) { //无序离散特征时的情况
// Unordered categorical feature
val (leftChildOffset, rightChildOffset) =
binAggregates.getLeftRightFeatureOffsets(featureIndexIdx)
val (bestFeatureSplitIndex, bestFeatureGainStats) =
Range(0, numSplits).map { splitIndex =>
val leftChildStats = binAggregates.getImpurityCalculator(leftChildOffset, splitIndex)
val rightChildStats = binAggregates.getImpurityCalculator(rightChildOffset, splitIndex)
predictWithImpurity = Some(predictWithImpurity.getOrElse(
calculatePredictImpurity(leftChildStats, rightChildStats)))
val gainStats = calculateGainForSplit(leftChildStats,
rightChildStats, binAggregates.metadata, predictWithImpurity.get._2)
(splitIndex, gainStats)
}.maxBy(_._2.gain)
(splits(featureIndex)(bestFeatureSplitIndex), bestFeatureGainStats)
} else { //有序离散特征时的情况
// Ordered categorical feature
val nodeFeatureOffset = binAggregates.getFeatureOffset(featureIndexIdx)
val numBins = binAggregates.metadata.numBins(featureIndex)
/* Each bin is one category (feature value).
* The bins are ordered based on centroidForCategories, and this ordering determines which
* splits are considered. (With K categories, we consider K - 1 possible splits.)
*
* centroidForCategories is a list: (category, centroid)
*/
//多元分类时的情况
val centroidForCategories = if (binAggregates.metadata.isMulticlass) {
// For categorical variables in multiclass classification,
// the bins are ordered by the impurity of their corresponding labels.
Range(0, numBins).map { case featureValue =>
val categoryStats = binAggregates.getImpurityCalculator(nodeFeatureOffset, featureValue)
val centroid = if (categoryStats.count != 0) {
// impurity 求的就是均方差
categoryStats.calculate()
} else {
Double.MaxValue
}
(featureValue, centroid)
}
} else { // 回归或二元分类时的情况 regression or binary classification
// For categorical variables in regression and binary classification,
// the bins are ordered by the centroid of their corresponding labels.
Range(0, numBins).map { case featureValue =>
val categoryStats = binAggregates.getImpurityCalculator(nodeFeatureOffset, featureValue)
val centroid = if (categoryStats.count != 0) {
//求的就是平均值作为 impurity
categoryStats.predict
} else {
Double.MaxValue
}
(featureValue, centroid)
}
}
logDebug("Centroids for categorical variable: " + centroidForCategories.mkString(","))
// bins sorted by centroids
val categoriesSortedByCentroid = centroidForCategories.toList.sortBy(_._2)
logDebug("Sorted centroids for categorical variable = " +
categoriesSortedByCentroid.mkString(","))
// Cumulative sum (scanLeft) of bin statistics.
// Afterwards, binAggregates for a bin is the sum of aggregates for
// that bin + all preceding bins.
var splitIndex = 0
while (splitIndex < numSplits) {
val currentCategory = categoriesSortedByCentroid(splitIndex)._1
val nextCategory = categoriesSortedByCentroid(splitIndex + 1)._1
//将两个箱子的状态信息进行合并
binAggregates.mergeForFeature(nodeFeatureOffset, nextCategory, currentCategory)
splitIndex += 1
}
// lastCategory = index of bin with total aggregates for this (node, feature)
val lastCategory = categoriesSortedByCentroid.last._1
// Find best split.
//通过信息增益值选择最优切分点
val (bestFeatureSplitIndex, bestFeatureGainStats) =
Range(0, numSplits).map { splitIndex =>
val featureValue = categoriesSortedByCentroid(splitIndex)._1
val leftChildStats =
binAggregates.getImpurityCalculator(nodeFeatureOffset, featureValue)
val rightChildStats =
binAggregates.getImpurityCalculator(nodeFeatureOffset, lastCategory)
rightChildStats.subtract(leftChildStats)
predictWithImpurity = Some(predictWithImpurity.getOrElse(
calculatePredictImpurity(leftChildStats, rightChildStats)))
val gainStats = calculateGainForSplit(leftChildStats,
rightChildStats, binAggregates.metadata, predictWithImpurity.get._2)
(splitIndex, gainStats)
}.maxBy(_._2.gain)
val categoriesForSplit =
categoriesSortedByCentroid.map(_._1.toDouble).slice(0, bestFeatureSplitIndex + 1)
val bestFeatureSplit =
new Split(featureIndex, Double.MinValue, Categorical, categoriesForSplit)
(bestFeatureSplit, bestFeatureGainStats)
}
}.maxBy(_._2.gain)
(bestSplit, bestSplitStats, predictWithImpurity.get._1)
}参考文献:
[1] 周志华 机器学习
[2] http://www.cnblogs.com/fxjwind/p/4151044.html
[3] http://www.cnblogs.com/fxjwind/p/4151044.html
[4] http://spark.apache.org/docs/latest/mllib-ensembles.html