PYNQ初体验--基于PYNQ简单的数字识别
目录标题
- 准备工作
- 移植到PYNQ上
准备工作
因为我们要做的就是将训练好的网络移植到PYNQ上,所以我们需要先在PC上把数字网络识别的网络训练好。因为我也是初次接触这个东西,这里的网络很简单,就用了一层的全连接层,计算量很小,先试试水(不排除有空的话会去用FPGA端加速做复杂的网络,这里我只用到了PS端的资源,并未涉及到PL端的资源)。
废话不多说,先用如下的代码训练一个简单的数字识别网络。
环境配置如下:
Windows 10 64bit
Python 3.6
import tensorflow as tf
import urllib
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image, ImageFilter
mnist = input_data.read_data_sets("MNIST_data/", one_hot = True)
#建立BP神经网络模型
num_classes = 10#数据类型0-9
input_size = 784#28*28
hidden_units_size = 30#层节点数
batch_size = 100#
training_iterations = 50000#迭代次数
# 设置变量
X = tf.placeholder (tf.float32, shape = [None, input_size])
Y = tf.placeholder (tf.float32, shape = [None, num_classes])
W1 = tf.Variable (tf.random_normal ([input_size, num_classes],
stddev = 0.1),name='weight')#hidden_units_size = 30#正态分布随机数
B1 = tf.Variable (tf.constant (0.1),
[num_classes],name='biases')#常数为1,形状为(1,1)
W2 = tf.Variable (tf.random_normal ([hidden_units_size,
num_classes], stddev = 0.1))#正态分布随机数
B2 = tf.Variable (tf.constant (0.1), [num_classes])
# 搭建计算网络 使用 relu 函数作为激励函数 这个函数就是 y = max (0,x) 的一个类似线性函数 拟合程度还是不错的
# 使用交叉熵损失函数 这是分类问题例如 : 神经网络 对率回归经常使用的一个损失函数
#第1层神经网络
hidden_opt = tf.matmul (X, W1) + B1#矩阵运算
final_opt = tf.nn.relu (hidden_opt)#激活函数
#第2层神经网络
#final_opt = tf.matmul (hidden_opt, W2) + B2#矩阵运算
#final_opt = tf.nn.relu (final_opt)#激活函数,最终的输出结果
loss = tf.reduce_mean (
tf.nn.softmax_cross_entropy_with_logits (labels = Y, logits = final_opt))#损失函数,交叉熵方法
opt = tf.train.GradientDescentOptimizer (0.1).minimize (loss)
init = tf.global_variables_initializer ()#全局变量初始化
correct_prediction = tf.equal (tf.argmax (Y, 1), tf.argmax (final_opt, 1))
accuracy = tf.reduce_mean (tf.cast (correct_prediction, 'float'))#将张量转化成float
# 进行计算 打印正确率
sess = tf.Session ()#生成能进行TensorFlow计算的类
saver=tf.train.Saver()
sess.run (init)
for i in range (training_iterations) :
batch_x,batch_y = mnist.train.next_batch (batch_size)#每次迭代选用的样本数100
#print(batch_input.shape)
#print(batch_labels)
training_loss = sess.run ([opt, loss], feed_dict = {
X: batch_x, Y: batch_y})
if (i+1) % 10000 == 0 :
train_accuracy = accuracy.eval (session = sess, feed_dict = {
X: batch_x,Y: batch_y})
test_acc = accuracy.eval (session = sess, feed_dict = {
X: mnist.test.images[:1000],Y: mnist.test.labels[:1000]})
print ("step : %d, training accuracy = %g " % (i+1, train_accuracy))
print("step : %d, test accuracy = %g " % (i+1, test_acc))
saver.save( sess,"path/weights.ckpt")
###测试集输出结果可视化
先用上述网络将网络训练好,最后的权重信息全部保存在了weights.ckpt中了,到时候将权重读取出来,保存为mat 格式就好了,下面就是将训练好的权重读取出来并存为mat格式。
# coding=utf-8
# Author:Tommy_Zane
# Time:2020/5/20
'''
从训练好的文件中提取出重建网络的权重
并存储为.mat格式
'''
import tensorflow as tf
import scipy.io as io
import numpy as np
#权重文件路径
model_path1 = r".\path\weights.ckpt"
#获取权重,Key_name为你所需要保存的权重在Checkpoint中的名字
reader1 = tf.train.NewCheckpointReader(model_path1)
value_W1 = reader1.get_tensor(r'biases')
#保存的.mat文件名
mat_path_1 = r'.\path\biases.mat'
#Matlab_name为在MATLAB中打开后的矩阵名称
io.savemat(mat_path_1, {
'Matlab_name': value_W1})
然后我们需要将mat文件转为array格式。
import tensorflow as tf
import scipy.io as io
import numpy as np
import h5py
data = h5py.File('E:\python_code\path\weight1.mat')
#权重
data = data['weight']
data = np.transpose(data)
np.save("E:\python_code\path\weight", data) #改为保存为整数,以逗号分隔
#偏置
data = data['biases']
data = np.transpose(data)
np.save("E:\python_code\path\biases", data) #改为保存为整数,以逗号分隔
基本上到了这里,准备工作已经准备完了,其实很简单,就是把训练好的网络的权值导出来,我这里可能做的有点繁杂了,毕竟第一次弄这个,大神轻喷好吧。
移植到PYNQ上
首先启动PYNQ进入Linux系统,然后进入jupyter notebook界面。
先将前面制作好的权值和偏置upload到PYNQ上,然后开始读取权值和偏置。

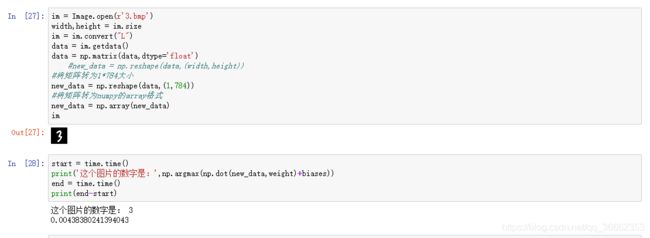
权值和偏置读取完了,现在就可以读取图片了,并将图片转为1*784的矩阵。

可以看到我们刚刚读取的图片是这个,数值为1:

直接利用读入的权值和偏置算出概率大小,最后识别出是哪个数字。

我们再看看用时情况,这里只用了0.0024s左右。

这里还测试了别的数字,如下所示:
虽然只有一层的连接层,识别的正确率可以达到98左右吧,后续还可以改进进一步提升正确率,后续有机会的话我会考虑去用FPGA加速做复杂的网络。