Flink批处理Demo(含源码)
- Flink的批处理Source
- 基于本地集合
- 基于文件
- 基于CSV
- 基于压缩文件
- Flink的Transformation
- map
- flatmap
- filter
- reduce
- rebalance
- Flink的Sink
- 写入集合
- 写入文件
- Flink程序本地执行和集群执行
- Flink的广播变量
- Flink的累加器
- Flink的分布式缓存
Flink 应用程序结构主要包含三部分,Source/Transformation/Sink,如下图所示:
-
Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:
- 基于本地集合的 source
- 基于文件的 source
- 基于网络套接字的 source
- 自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
-
Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。
-
Sink:接收器,Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来,Flink 常见的 Sink 大概有如下几类:
- 写入文件、
- 打印输出、
- 写入 socket 、
- 自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 Sink。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DpA4v3DM-1594733860413)(assets/YbZnoM.jpg)]
环境搭建
pom.xml
<properties>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.11scala.version>
<flink.version>1.6.1flink.version>
<hadoop.version>2.7.5hadoop.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table_${scala.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-scala_${scala.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_${scala.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_${scala.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.44version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-runtime-web_2.11artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<testSourceDirectory>src/test/scalatestSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>2.5.1version>
<configuration>
<source>${maven.compiler.source}source>
<target>${maven.compiler.target}target>
configuration>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.0version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.xu.batch.BatchFromCollectionmainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-jar-pluginartifactId>
<version>2.6version>
<configuration>
<archive>
<manifest>
<addClasspath>trueaddClasspath>
<classpathPrefix>lib/classpathPrefix>
<mainClass>com.xu.env.BatchRemoteEvenmainClass>
manifest>
archive>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-dependency-pluginartifactId>
<version>2.10version>
<executions>
<execution>
<id>copy-dependenciesid>
<phase>packagephase>
<goals>
<goal>copy-dependenciesgoal>
goals>
<configuration>
<outputDirectory>${project.build.directory}/liboutputDirectory>
configuration>
execution>
executions>
plugin>
plugins>
build>
一 Flink批处理DataSource
DataSource 是什么呢?就字面意思其实就可以知道:数据来源。
Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来,Flink 就能够一直计算下去,这个 Data Sources 就是数据的来源地。
Flink在批处理中常见的source主要有两大类。
-
基于本地集合的source(Collection-based-source)
-
基于文件的source(File-based-source)
1.1. 基于本地集合的Source
在Flink中最常见的创建本地集合的DataSet方式有三种。
-
使用env.fromElements(),这种方式也支持Tuple,自定义对象等复合形式。
-
使用env.fromCollection(),这种方式支持多种Collection的具体类型。
-
使用env.generateSequence(),这种方法创建基于Sequence的DataSet。
使用方式如下:
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable
import scala.collection.mutable.{ArrayBuffer, ListBuffer}
/**
* 读取集合中的批次数据
*/
object BatchFromCollection {
def main(args: Array[String]): Unit = {
//获取flink执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//导入隐式转换
import org.apache.flink.api.scala._
//0.用element创建DataSet(fromElements)
val ds0: DataSet[String] = env.fromElements("spark", "flink")
ds0.print()
//1.用Tuple创建DataSet(fromElements)
val ds1: DataSet[(Int, String)] = env.fromElements((1, "spark"), (2, "flink"))
ds1.print()
//2.用Array创建DataSet
val ds2: DataSet[String] = env.fromCollection(Array("spark", "flink"))
ds2.print()
//3.用ArrayBuffer创建DataSet
val ds3: DataSet[String] = env.fromCollection(ArrayBuffer("spark", "flink"))
ds3.print()
//4.用List创建DataSet
val ds4: DataSet[String] = env.fromCollection(List("spark", "flink"))
ds4.print()
//5.用List创建DataSet
val ds5: DataSet[String] = env.fromCollection(ListBuffer("spark", "flink"))
ds5.print()
//6.用Vector创建DataSet
val ds6: DataSet[String] = env.fromCollection(Vector("spark", "flink"))
ds6.print()
//7.用Queue创建DataSet
val ds7: DataSet[String] = env.fromCollection(mutable.Queue("spark", "flink"))
ds7.print()
//8.用Stack创建DataSet
val ds8: DataSet[String] = env.fromCollection(mutable.Stack("spark", "flink"))
ds8.print()
//9.用Stream创建DataSet(Stream相当于lazy List,避免在中间过程中生成不必要的集合)
val ds9: DataSet[String] = env.fromCollection(Stream("spark", "flink"))
ds9.print()
//10.用Seq创建DataSet
val ds10: DataSet[String] = env.fromCollection(Seq("spark", "flink"))
ds10.print()
//11.用Set创建DataSet
val ds11: DataSet[String] = env.fromCollection(Set("spark", "flink"))
ds11.print()
//12.用Iterable创建DataSet
val ds12: DataSet[String] = env.fromCollection(Iterable("spark", "flink"))
ds12.print()
//13.用ArraySeq创建DataSet
val ds13: DataSet[String] = env.fromCollection(mutable.ArraySeq("spark", "flink"))
ds13.print()
//14.用ArrayStack创建DataSet
val ds14: DataSet[String] = env.fromCollection(mutable.ArrayStack("spark", "flink"))
ds14.print()
//15.用Map创建DataSet
val ds15: DataSet[(Int, String)] = env.fromCollection(Map(1 -> "spark", 2 -> "flink"))
ds15.print()
//16.用Range创建DataSet
val ds16: DataSet[Int] = env.fromCollection(Range(1, 9))
ds16.print()
//17.用fromElements创建DataSet
val ds17: DataSet[Long] = env.generateSequence(1, 9)
ds17.print()
}
}
1.2. 基于文件的Source
Flink支持直接从外部文件存储系统中读取文件的方式来创建Source数据源,Flink支持的方式有以下几种:
- 读取本地文件数据
- 读取HDFS文件数据
- 读取CSV文件数据
- 读取压缩文件
- 遍历目录
下面分别演示每个数据源的加载方式:
1.2.1. 读取本地文件
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, GroupedDataSet}
/**
* 读取文件中的批次数据
*/
object BatchFromFile {
def main(args: Array[String]): Unit = {
//使用readTextFile读取本地文件
//初始化环境
val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//加载数据
val datas: DataSet[String] = environment.readTextFile("data.txt")
//触发程序执行
datas.print()
}
}
1.2.2. 读取HDFS文件数据
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, GroupedDataSet}
/**
* 读取文件中的批次数据
*/
object BatchFromFile {
def main(args: Array[String]): Unit = {
//使用readTextFile读取本地文件
//初始化环境
val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//加载数据
val datas: DataSet[String] = environment.readTextFile("hdfs://node01:8020/README.txt")
//触发程序执行
datas.print()
}
}
1.2.3. 读取CSV文件数据
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, GroupedDataSet}
/**
* 读取CSV文件中的批次数据
*/
object BatchFromCsvFile {
def main(args: Array[String]): Unit = {
//初始化环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
// 用于映射CSV文件的样例类
case class Student(id:Int, name:String)
val csvDataSet = env.readCsvFile[Student]("./data/input/subject.csv")
csvDataSet.print()
//触发程序执行
datas.print()
}
}
1.2.4. 读取压缩文件
对于以下压缩类型,不需要指定任何额外的inputformat方法,flink可以自动识别并且解压。但是,压缩文件可能不会并行读取,可能是顺序读取的,这样可能会影响作业的可伸缩性。
| 压缩格式 | 扩展名 | 并行化 |
|---|---|---|
| DEFLATE | .deflate | no |
| GZIP | .gz .gzip | no |
| Bzip2 | .bz2 | no |
| XZ | .xz | no |
import org.apache.flink.api.scala.ExecutionEnvironment
/**
* 读取压缩文件的数据
*/
object BatchFromCompressFile {
def main(args: Array[String]): Unit = {
//初始化环境
val env = ExecutionEnvironment.getExecutionEnvironment
//加载数据
val result = env.readTextFile("D:\\BaiduNetdiskDownload\\hbase-1.3.1-bin.tar.gz")
//触发程序执行
result.print()
}
}
1.2.5. 遍历目录
flink支持对一个文件目录内的所有文件,包括所有子目录中的所有文件的遍历访问方式。
对于从文件中读取数据,当读取的数个文件夹的时候,嵌套的文件默认是不会被读取的,只会读取第一个文件,其他的都会被忽略。所以我们需要使用recursive.file.enumeration进行递归读取
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
import org.apache.flink.configuration.Configuration
/**
* 遍历目录的批次数据
*/
object BatchFromFolder {
def main(args: Array[String]): Unit = {
//初始化环境
val env = ExecutionEnvironment.getExecutionEnvironment
val parameters = new Configuration
// recursive.file.enumeration 开启递归
parameters.setBoolean("recursive.file.enumeration", true)
val result = env.readTextFile("D:\\data\\dataN").withParameters(parameters)
//触发程序执行
result.print()
}
}
2. Flink批处理Transformation
| Transformation | 说明 |
|---|---|
| map | 将DataSet中的每一个元素转换为另外一个元素 |
| flatMap | 将DataSet中的每一个元素转换为0…n个元素 |
| mapPartition | 将一个分区中的元素转换为另一个元素 |
| filter | 过滤出来一些符合条件的元素 |
| reduce | 可以对一个dataset或者一个group来进行聚合计算,最终聚合成一个元素 |
| reduceGroup | 将一个dataset或者一个group聚合成一个或多个元素 |
| aggregate | 按照内置的方式来进行聚合。例如:SUM/MIN/MAX… |
| distinct | 去重 |
| join | 将两个DataSet按照一定条件连接到一起,形成新的DataSet |
| union | 将两个DataSet取并集,并不会去重 |
| rebalance | 让每个分区的数据均匀分布,避免数据倾斜 |
| partitionByHash | 按照指定的key进行hash分区 |
| sortPartition | 指定字段对分区中的数据进行排序 |
4.1. map
将DataSet中的每一个元素转换为另外一个元素
示例
使用map操作,将以下数据
"1,张三", "2,李四", "3,王五", "4,赵六"
转换为一个scala的样例类。
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 创建一个
User样例类 - 使用
map操作执行转换 - 打印测试
参考代码
case class User(id:String, name:String)
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.fromCollection(
List("1,张三", "2,李四", "3,王五", "4,赵六")
)
val userDataSet: DataSet[User] = textDataSet.map {
text =>
val fieldArr = text.split(",")
User(fieldArr(0), fieldArr(1))
}
userDataSet.print()
2.2. flatMap
将DataSet中的每一个元素转换为0…n个元素
示例
分别将以下数据,转换成国家、省份、城市三个维度的数据。
将以下数据
张三,中国,江西省,南昌市
李四,中国,河北省,石家庄市
Tom,America,NewYork,Manhattan
转换为
(张三,中国)
(张三,中国,江西省)
(张三,中国,江西省,江西省)
(李四,中国)
(李四,中国,河北省)
(李四,中国,河北省,河北省)
(Tom,America)
(Tom,America,NewYork)
(Tom,America,NewYork,NewYork)
思路
-
以上数据为一条转换为三条,显然,应当使用
flatMap来实现 -
分别在
flatMap函数中构建三个数据,并放入到一个列表中姓名, 国家
姓名, 国家省份
姓名, 国家省份城市
步骤
-
构建批处理运行环境
-
构建本地集合数据源
-
使用
flatMap将一条数据转换为三条数据- 使用逗号分隔字段
- 分别构建国家、国家省份、国家省份城市三个元组
-
打印输出
参考代码
// 1. 构建批处理运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 构建本地集合数据源
val userDataSet = env.fromCollection(List(
"张三,中国,江西省,南昌市",
"李四,中国,河北省,石家庄市",
"Tom,America,NewYork,Manhattan"
))
// 3. 使用`flatMap`将一条数据转换为三条数据
val resultDataSet = userDataSet.flatMap{
text =>
// - 使用逗号分隔字段
val fieldArr = text.split(",")
// - 分别构建国家、国家省份、国家省份城市三个元组
List(
(fieldArr(0), fieldArr(1)), // 构建国家维度数据
(fieldArr(0), fieldArr(1) + fieldArr(2)), // 构建省份维度数据
(fieldArr(0), fieldArr(1) + fieldArr(2) + fieldArr(3)) // 构建城市维度数据
)
}
// 4. 打印输出
resultDataSet.print()
2.3. mapPartition
将一个分区中的元素转换为另一个元素
示例
使用mapPartition操作,将以下数据
"1,张三", "2,李四", "3,王五", "4,赵六"
转换为一个scala的样例类。
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 创建一个
User样例类 - 使用
mapPartition操作执行转换 - 打印测试
参考代码
// 3. 创建一个`User`样例类
case class User(id:String, name:String)
def main(args: Array[String]): Unit = {
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 使用`fromCollection`构建数据源
val userDataSet = env.fromCollection(List("1,张三", "2,李四", "3,王五", "4,赵六"))
// 4. 使用`mapPartition`操作执行转换
val resultDataSet = userDataSet.mapPartition{
iter =>
// TODO:打开连接
// 对迭代器执行转换操作
iter.map{
ele =>
val fieldArr = ele.split(",")
User(fieldArr(0), fieldArr(1))
}
// TODO:关闭连接
}
// 5. 打印测试
resultDataSet.print()
}
map和mapPartition的效果是一样的,但如果在map的函数中,需要访问一些外部存储。例如:
访问mysql数据库,需要打开连接, 此时效率较低。而使用mapPartition可以有效减少连接数,提高效率
2.4. filter
过滤出来一些符合条件的元素
示例:
过滤出来以下以h开头的单词。
"hadoop", "hive", "spark", "flink"
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 使用
filter操作执行过滤 - 打印测试
参考代码
def main(args: Array[String]): Unit = {
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 使用`fromCollection`构建数据源
val wordDataSet = env.fromCollection(List("hadoop", "hive", "spark", "flink"))
// 3. 使用`filter`操作执行过滤
val resultDataSet = wordDataSet.filter(_.startsWith("h"))
// 4. 打印测试
resultDataSet.print()
}
2.5. reduce
可以对一个dataset或者一个group来进行聚合计算,最终聚合成一个元素
示例1
请将以下元组数据,使用reduce操作聚合成一个最终结果
("java" , 1) , ("java", 1) ,("java" , 1)
将上传元素数据转换为("java",3)
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 使用
redice执行聚合操作 - 打印测试
参考代码
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 使用`fromCollection`构建数据源
val wordCountDataSet = env.fromCollection(List(("java" , 1) , ("java", 1) ,("java" , 1) ))
// 3. 使用`redice`执行聚合操作
val resultDataSet = wordCountDataSet.reduce{
(wc1, wc2) =>
(wc2._1, wc1._2 + wc2._2)
}
// 4. 打印测试
resultDataSet.print()
示例2
请将以下元组数据,下按照单词使用groupBy进行分组,再使用reduce操作聚合成一个最终结果
("java" , 1) , ("java", 1) ,("scala" , 1)
转换为
("java", 2), ("scala", 1)
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 使用
groupBy按照单词进行分组 - 使用
reduce对每个分组进行统计 - 打印测试
参考代码
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 使用`fromCollection`构建数据源
val wordcountDataSet = env.fromCollection(List(("java" , 1) , ("java", 1) ,("scala" , 1) ))
// 3. 使用`groupBy`按照单词进行分组
val groupedDataSet = wordcountDataSet.groupBy(_._1)
// 4. 使用`reduce`对每个分组进行统计
val resultDataSet = groupedDataSet.reduce{
(wc1, wc2) =>
(wc1._1, wc1._2 + wc2._2)
}
// 5. 打印测试
resultDataSet.print()
2.6. reduceGroup
可以对一个dataset或者一个group来进行聚合计算,最终聚合成一个元素
reduce和reduceGroup的区别
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jT3B9eFG-1594733860416)(assets/1554278411562.png)]
- reduce是将数据一个个拉取到另外一个节点,然后再执行计算
- reduceGroup是先在每个group所在的节点上执行计算,然后再拉取
示例
请将以下元组数据,下按照单词使用groupBy进行分组,再使用reduceGroup操作进行单词计数
("java" , 1) , ("java", 1) ,("scala" , 1)
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 使用
groupBy按照单词进行分组 - 使用
reduceGroup对每个分组进行统计 - 打印测试
参考代码
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 2. 使用`fromCollection`构建数据源
val wordcountDataSet = env.fromCollection(
List(("java" , 1) , ("java", 1) ,("scala" , 1) )
)
// 3. 使用`groupBy`按照单词进行分组
val groupedDataSet = wordcountDataSet.groupBy(_._1)
// 4. 使用`reduceGroup`对每个分组进行统计
val resultDataSet = groupedDataSet.reduceGroup{
iter =>
iter.reduce{(wc1, wc2) => (wc1._1,wc1._2 + wc2._2)}
}
// 5. 打印测试
resultDataSet.print()
2.7. aggregate
按照内置的方式来进行聚合, Aggregate只能作用于元组上。例如:SUM/MIN/MAX…
示例
请将以下元组数据,使用aggregate操作进行单词统计
("java" , 1) , ("java", 1) ,("scala" , 1)
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 使用
groupBy按照单词进行分组 - 使用
aggregate对每个分组进行SUM统计 - 打印测试
参考代码
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 使用`fromCollection`构建数据源
val wordcountDataSet = env.fromCollection(
List(("java" , 1) , ("java", 1) ,("scala" , 1) )
)
// 3. 使用`groupBy`按照单词进行分组
val groupedDataSet = wordcountDataSet.groupBy(0)
// 4. 使用`aggregate`对每个分组进行`SUM`统计
val resultDataSet = groupedDataSet.aggregate(Aggregations.SUM, 1)
// 5. 打印测试
resultDataSet.print()
注意
要使用aggregate,只能使用字段索引名或索引名称来进行分组
groupBy(0),否则会报一下错误:Exception in thread "main" java.lang.UnsupportedOperationException: Aggregate does not support grouping with KeySelector functions, yet.
4.8. distinct
去除重复的数据
示例
请将以下元组数据,使用distinct操作去除重复的单词
("java" , 1) , ("java", 2) ,("scala" , 1)
去重得到
("java", 1), ("scala", 1)
步骤
- 获取
ExecutionEnvironment运行环境 - 使用
fromCollection构建数据源 - 使用
distinct指定按照哪个字段来进行去重 - 打印测试
参考代码
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 使用`fromCollection`构建数据源
val wordcountDataSet = env.fromCollection(
List(("java" , 1) , ("java", 1) ,("scala" , 1) )
)
// 3. 使用`distinct`指定按照哪个字段来进行去重
val resultDataSet = wordcountDataSet.distinct(0)
// 4. 打印测试
resultDataSet.print()
2.8. join
使用join可以将两个DataSet连接起来
示例:
在资料\测试数据源中,有两个csv文件,有一个为score.csv,一个为subject.csv,分别保存了成绩数据以及学科数据。

需要将这两个数据连接到一起,然后打印出来。

步骤
-
分别将资料中的两个文件复制到项目中的
data/join/input中 -
构建批处理环境
-
创建两个样例类
* 学科Subject(学科ID、学科名字) * 成绩Score(唯一ID、学生姓名、学科ID、分数——Double类型) -
分别使用
readCsvFile加载csv数据源,并制定泛型 -
使用join连接两个DataSet,并使用
where、equalTo方法设置关联条件 -
打印关联后的数据源
参考代码
// 学科Subject(学科ID、学科名字)
case class Subject(id:Int, name:String)
// 成绩Score(唯一ID、学生姓名、学科ID、分数)
case class Score(id:Int, name:String, subjectId:Int, score:Double)
def main(args: Array[String]): Unit = {
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 3. 分别使用`readCsvFile`加载csv数据源
val scoreDataSet = env.readCsvFile[Score]("./data/join/input/score.csv")
val subjectDataSet = env.readCsvFile[Subject]("./data/join/input/subject.csv")
// 4. 使用join连接两个DataSet,并使用`where`、`equalTo`方法设置关联条件
val joinedDataSet = scoreDataSet.join(subjectDataSet).where(2).equalTo(0)
// 5. 打印关联后的数据源
joinedDataSet.print()
}
2.9. union
将两个DataSet取并集,不会去重。
示例
将以下数据进行取并集操作
数据集1
"hadoop", "hive", "flume"
数据集2
"hadoop", "hive", "spark"
步骤
- 构建批处理运行环境
- 使用
fromCollection创建两个数据源 - 使用
union将两个数据源关联在一起 - 打印测试
参考代码
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 使用`fromCollection`创建两个数据源
val wordDataSet1 = env.fromCollection(List("hadoop", "hive", "flume"))
val wordDataSet2 = env.fromCollection(List("hadoop", "hive", "spark"))
// 3. 使用`union`将两个数据源关联在一起
val resultDataSet = wordDataSet1.union(wordDataSet2)
// 4. 打印测试
resultDataSet.print()
2.10. rebalance
Flink也会产生数据倾斜的时候,例如:当前的数据量有10亿条,在处理过程就有可能发生如下状况:
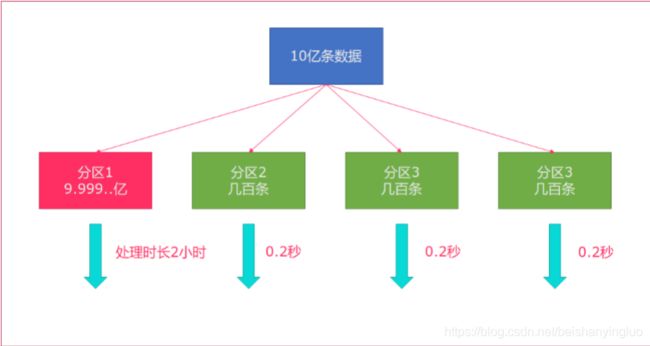
rebalance会使用轮询的方式将数据均匀打散,这是处理数据倾斜最好的选择。
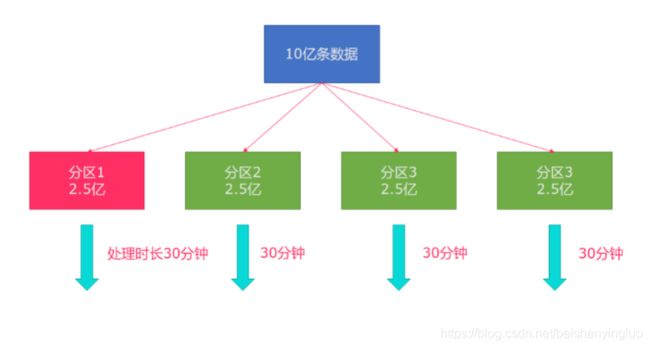
步骤
-
构建批处理运行环境
-
使用
env.generateSequence创建0-100的并行数据 -
使用
fiter过滤出来大于8的数字 -
使用map操作传入
RichMapFunction,将当前子任务的ID和数字构建成一个元组在RichMapFunction中可以使用`getRuntimeContext.getIndexOfThisSubtask`获取子任务序号 -
打印测试
参考代码
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 使用`env.generateSequence`创建0-100的并行数据
val numDataSet = env.generateSequence(0, 100)
// 3. 使用`fiter`过滤出来`大于8`的数字
val filterDataSet = numDataSet.filter(_ > 8)
// 4. 使用map操作传入`RichMapFunction`,将当前子任务的ID和数字构建成一个元组
val resultDataSet = filterDataSet.map(new RichMapFunction[Long, (Long, Long)] {
override def map(in: Long): (Long, Long) = {
(getRuntimeContext.getIndexOfThisSubtask, in)
}
})
// 5. 打印测试
resultDataSet.print()
上述代码没有加rebalance,通过观察,有可能会出现数据倾斜。
在filter计算完后,调用rebalance,这样,就会均匀地将数据分布到每一个分区中。
2.11. hashPartition
按照指定的key进行hash分区
示例
基于以下列表数据来创建数据源,并按照hashPartition进行分区,然后输出到文件。
List(1,1,1,1,1,1,1,2,2,2,2,2)
步骤
- 构建批处理运行环境
- 设置并行度为
2 - 使用
fromCollection构建测试数据集 - 使用
partitionByHash按照字符串的hash进行分区 - 调用
writeAsText写入文件到data/parition_output目录中 - 打印测试
参考代码
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 1. 设置并行度为`2`
env.setParallelism(2)
// 2. 使用`fromCollection`构建测试数据集
val numDataSet = env.fromCollection(List(1,1,1,1,1,1,1,2,2,2,2,2))
// 3. 使用`partitionByHash`按照字符串的hash进行分区
val partitionDataSet: DataSet[Int] = numDataSet.partitionByHash(_.toString)
// 4. 调用`writeAsText`写入文件到`data/parition_output`目录中
partitionDataSet.writeAsText("./data/parition_output")
// 5. 打印测试
partitionDataSet.print()
2.12. sortPartition
指定字段对分区中的数据进行排序
示例
按照以下列表来创建数据集
List("hadoop", "hadoop", "hadoop", "hive", "hive", "spark", "spark", "flink")
对分区进行排序后,输出到文件。
步骤
- 构建批处理运行环境
- 使用
fromCollection构建测试数据集 - 设置数据集的并行度为
2 - 使用
sortPartition按照字符串进行降序排序 - 调用
writeAsText写入文件到data/sort_output目录中 - 启动执行
参考代码
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 使用`fromCollection`构建测试数据集
val wordDataSet = env.fromCollection(List("hadoop", "hadoop", "hadoop", "hive", "hive", "spark", "spark", "flink"))
// 3. 设置数据集的并行度为`2`
wordDataSet.setParallelism(2)
// 4. 使用`sortPartition`按照字符串进行降序排序
val sortedDataSet = wordDataSet.sortPartition(_.toString, Order.DESCENDING)
// 5. 调用`writeAsText`写入文件到`data/sort_output`目录中
sortedDataSet.writeAsText("./data/sort_output/")
// 6. 启动执行
env.execute("App")
3. Flink批处理Sink
flink在批处理中常见的sink
-
基于本地集合的sink(Collection-based-sink)
-
基于文件的sink(File-based-sink)
3.1. 基于本地集合的sink
目标:
基于下列数据,分别 进行打印输出,error输出,collect()
(19, "zhangsan", 178.8),
(17, "lisi", 168.8),
(18, "wangwu", 184.8),
(21, "zhaoliu", 164.8)
代码:
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
import org.apache.flink.core.fs.FileSystem.WriteMode
import org.apache.flink.api.scala._
object BatchSinkCollection {
def main(args: Array[String]): Unit = {
//1.定义环境
val env = ExecutionEnvironment.getExecutionEnvironment
//2.定义数据 stu(age,name,height)
val stu: DataSet[(Int, String, Double)] = env.fromElements(
(19, "zhangsan", 178.8),
(17, "lisi", 168.8),
(18, "wangwu", 184.8),
(21, "zhaoliu", 164.8)
)
//3.TODO sink到标准输出
stu.print
//3.TODO sink到标准error输出
stu.printToErr()
//4.TODO sink到本地Collection
print(stu.collect())
env.execute()
}
}
3.2. 基于文件的sink
-
flink支持多种存储设备上的文件,包括本地文件,hdfs文件等。
-
flink支持多种文件的存储格式,包括text文件,CSV文件等。
-
writeAsText():TextOuputFormat - 将元素作为字符串写入行。字符串是通过调用每个元素的toString()方法获得的。
3.2.1. 将数据写入本地文件
目标:
基于下列数据,写入到文件中
Map(1 -> "spark", 2 -> "flink")
代码:
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
import org.apache.flink.core.fs.FileSystem.WriteMode
import org.apache.flink.api.scala._
/**
* 将数据写入本地文件
*/
object BatchSinkFile {
def main(args: Array[String]): Unit = {
//1.定义环境
val env = ExecutionEnvironment.getExecutionEnvironment
//2.定义数据
val ds1: DataSet[Map[Int, String]] = env.fromElements(Map(1 -> "spark", 2 -> "flink"))
//3 .TODO 写入到本地,文本文档,NO_OVERWRITE模式下如果文件已经存在,则报错,OVERWRITE模式下如果文件已经存在,则覆盖
ds1.setParallelism(1).writeAsText("test/data1/aa", WriteMode.OVERWRITE)
env.execute()
}
}
3.2.2. 将数据写入HDFS
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
import org.apache.flink.core.fs.FileSystem.WriteMode
import org.apache.flink.api.scala._
/**
* 将数据写入本地文件
*/
object BatchSinkFile {
def main(args: Array[String]): Unit = {
//1.定义环境
val env = ExecutionEnvironment.getExecutionEnvironment
//2.定义数据 stu(age,name,height)
val stu: DataSet[(Int, String, Double)] = env.fromElements(
(19, "zhangsan", 178.8),
(17, "lisi", 168.8),
(18, "wangwu", 184.8),
(21, "zhaoliu", 164.8)
)
val ds1: DataSet[Map[Int, String]] = env.fromElements(Map(1 -> "spark", 2 -> "flink"))
//1.TODO 写入到本地,文本文档,NO_OVERWRITE模式下如果文件已经存在,则报错,OVERWRITE模式下如果文件已经存在,则覆盖
ds1.setParallelism(1).writeAsText("hdfs://bigdata111:9000/a", WriteMode.OVERWRITE)
env.execute()
}
}
4. Flink程序本地执行和集群执行
4.1. 本地执行
Flink支持两种不同的本地执行。
LocalExecutionEnvironment 是启动完整的Flink运行时(Flink Runtime),包括 JobManager 和 TaskManager 。 这种方式包括内存管理和在集群模式下执行的所有内部算法。
CollectionEnvironment 是在 Java 集合(Java Collections)上执行 Flink 程序。 此模式不会启动完整的Flink运行时(Flink Runtime),因此执行的开销非常低并且轻量化。 例如一个DataSet.map()变换,会对Java list中所有元素应用 map() 函数。
4.1.1. local环境
LocalEnvironment是Flink程序本地执行的句柄。可使用它,独立或嵌入其他程序在本地 JVM 中运行Flink程序。
本地环境通过该方法实例化ExecutionEnvironment.createLocalEnvironment()。
默认情况下,启动的本地线程数与计算机的CPU个数相同。也可以指定所需的并行性。本地环境可以配置为使用enableLogging()/ 登录到控制台disableLogging()。
在大多数情况下,ExecutionEnvironment.getExecutionEnvironment()是更好的方式。LocalEnvironment当程序在本地启动时(命令行界面外),该方法会返回一个程序,并且当程序由命令行界面调用时,它会返回一个预配置的群集执行环境。
注意:本地执行环境不启动任何Web前端来监视执行。
/**
* local环境
*/
object BatchCollectionsEven {
def main(args: Array[String]): Unit = {
// 开始时间
var start_time =new Date().getTime
//TODO 初始化本地执行环境
val env = ExecutionEnvironment.createLocalEnvironment
val list: DataSet[String] = env.fromCollection(List("1","2"))
list.print()
// 结束时间
var end_time =new Date().getTime
println(end_time-start_time) //单位毫秒
}
}
4.1.2. 集合环境
使用集合的执行CollectionEnvironment是执行Flink程序的低开销方法。这种模式的典型用例是自动化测试,调试和代码重用。
用户也可以使用为批处理实施的算法,以便更具交互性的案例
请注意,基于集合的Flink程序的执行仅适用于适合JVM堆的小数据。集合上的执行不是多线程的,只使用一个线程
/**
* local环境
*/
object BatchCollectionsEven {
def main(args: Array[String]): Unit = {
// 开始时间
var start_time =new Date().getTime
//TODO 初始化本地执行环境
val env = ExecutionEnvironment.createCollectionsEnvironment
val list: DataSet[String] = env.fromCollection(List("1","2"))
list.print()
// 结束时间
var end_time =new Date().getTime
println(end_time-start_time) //单位毫秒
}
}
4.2. 集群执行
Flink程序可以在许多机器的集群上分布运行。有两种方法可将程序发送到群集以供执行:
- 使用命令行界面提交
- 使用代码中的远程环境提交
4.2.1. 使用命令行提交
./bin/flink run ./examples/batch/WordCount.jar --input file:///home/user/hamlet.txt --output file:///home/user/wordcount_out
4.2.2. 使用代码中远程环境提交
通过IDE,直接在远程环境上执行Flink Java程序。
操作步骤
-
添加Maven插件
org.apache.maven.plugins maven-jar-plugin 2.6 true lib/ com.flink.DataStream.RemoteEven org.apache.maven.plugins maven-dependency-plugin 2.10 copy-dependencies package copy-dependencies ${project.build.directory}/lib /** 创建远程执行环境。远程环境将程序(部分)发送到集群以执行。请注意,程序中使用的所有文件路径都必须可以从集群中访问。除非通过[[ExecutionEnvironment.setParallelism()]显式设置并行度,否则执行将使用集群的默认并行度。 * @param host JobManager的ip或域名 * @param port JobManager的端口 * @param jarFiles 包含需要发送到集群的代码的JAR文件。如果程序使用用户定义的函数、用户定义的输入格式或任何库,则必须在JAR文件中提供这些函数。 */ def createRemoteEnvironment(host: String, port: Int, jarFiles: String*): ExecutionEnvironment = { new ExecutionEnvironment(JavaEnv.createRemoteEnvironment(host, port, jarFiles: _*)) }
示例
读取HDFS上的score.csv文件, 获取到每个学生最好的成绩信息.
开发步骤
- 创建远程执行环境
- 读取远程CSV文件,转换成元组类型
- 根据姓名分组,按成绩倒序排列,取第一个值
- 打印结果
代码
object BatchRemoteEven {
def main(args: Array[String]): Unit = {
// 1. 创建远程执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.createRemoteEnvironment("node01", 8081, "E:\\bigdata_ws\\flink-base\\target\\flink-base-1.0-SNAPSHOT.jar")
// 2. 读取远程CSV文件,转换为元组类型
val scoreDatSet: DataSet[(Long, String, Long, Double)] = env.readCsvFile[(Long, String, Long, Double)]("hdfs://node01:8020/flink-datas/score.csv")
// 3. 根据姓名分组,按成绩倒序排列,取第一个值
val list: DataSet[(Long, String, Long, Double)] = scoreDatSet.groupBy(1).sortGroup(3,Order.DESCENDING).first(1)
// 4. 打印结果
list.print()
}
}
5. Flink的广播变量
Flink支持广播。可以将数据广播到TaskManager上,数据存储到内存中。数据存储在内存中,这样可以减缓大量的shuffle操作;比如在数据join阶段,不可避免的就是大量的shuffle操作,我们可以把其中一个dataSet广播出去,一直加载到taskManager的内存中,可以直接在内存中拿数据,避免了大量的shuffle,导致集群性能下降;
广播变量创建后,它可以运行在集群中的任何function上,而不需要多次传递给集群节点。另外需要记住,不应该修改广播变量,这样才能确保每个节点获取到的值都是一致的。
一句话解释,可以理解为是一个公共的共享变量,我们可以把一个dataset 数据集广播出去,然后不同的task在节点上都能够获取到,这个数据在每个节点上只会存在一份。如果不使用broadcast,则在每个节点中的每个task中都需要拷贝一份dataset数据集,比较浪费内存(也就是一个节点中可能会存在多份dataset数据)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ve6wQRh7-1594733860426)(assets/1554344137813.png)]
- 可以理解广播就是一个公共的共享变量
- 将一个数据集广播后,不同的Task都可以在节点上获取到
- 每个节点
只存一份 - 如果不使用广播,每一个Task都会拷贝一份数据集,造成内存资源浪费
用法
- 在需要使用广播的操作后,使用
withBroadcastSet创建广播 - 在操作中,使用getRuntimeContext.getBroadcastVariable
[广播数据类型](广播名)获取广播变量
操作步骤:
1:初始化数据
DataSet toBroadcast = env.fromElements(1, 2, 3)
2:广播数据
.withBroadcastSet(toBroadcast, "broadcastSetName");
3:获取数据
Collection broadcastSet = getRuntimeContext().getBroadcastVariable("broadcastSetName");
示例
创建一个学生数据集,包含以下数据
|学生ID | 姓名 |
|------|------|
List((1, "张三"), (2, "李四"), (3, "王五"))
将该数据,发布到广播。
再创建一个成绩数据集,
|学生ID | 学科 | 成绩 |
|------|------|-----|
List( (1, "语文", 50),(2, "数学", 70), (3, "英文", 86))
请通过广播获取到学生姓名,将数据转换为
List( ("张三", "语文", 50),("李四", "数学", 70), ("王五", "英文", 86))
步骤
- 获取批处理运行环境
- 分别创建两个数据集
- 使用
RichMapFunction对成绩数据集进行map转换 - 在数据集调用
map方法后,调用withBroadcastSet将学生数据集创建广播 - 实现
RichMapFunction- 将成绩数据(学生ID,学科,成绩) -> (学生姓名,学科,成绩)
- 重写
open方法中,获取广播数据 - 导入
scala.collection.JavaConverters._隐式转换 - 将广播数据使用
asScala转换为Scala集合,再使用toList转换为scalaList集合 - 在
map方法中使用广播进行转换
- 打印测试
参考代码
package com.xu.broad
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
object BroadCast {
def main(args: Array[String]): Unit = {
// 1. 获取`ExecutionEnvironment`运行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 1. 分别创建两个数据集
val studentDataSet: DataSet[(Int, String)] = env.fromCollection(List((1, "张三"), (2, "李四"), (3, "王五")))
val scoreDataSet: DataSet[(Int, String, Int)] = env.fromCollection(List((1, "语文", 50), (2, "数学", 70), (3, "英文", 86)))
// 1. 使用`RichMapFunction`对`成绩`数据集进行map转换
// 将成绩数据(学生ID,学科,成绩) -> (学生姓名,学科,成绩)
val resultDataSet: DataSet[(String, String, Int)] = scoreDataSet.map(new RichMapFunction[(Int, String, Int), (String, String, Int)] {
var bc_studentList: List[(Int, String)] = null
// - 重写`open`方法中,获取广播数据
override def open(parameters: Configuration): Unit = {
import scala.collection.JavaConverters._
bc_studentList = getRuntimeContext.getBroadcastVariable[(Int, String)]("bc_student").asScala.toList
}
// - 在`map`方法中使用广播进行转换
override def map(value: (Int, String, Int)): (String, String, Int) = {
// 获取学生ID
val studentId: Int = value._1
// 过滤出和学生ID相同的内容
val tuples: List[(Int, String)] = bc_studentList.filter((x: (Int, String)) => x._1 == studentId)
// 构建元组
(tuples(0)._2,value._2,value._3)
}
}).withBroadcastSet(studentDataSet, "bc_student")
// 3. 打印测试
resultDataSet.print()
}
}
- 广播出去的变量存放在每个节点的内存中,直到程序结束,这个数据集不能太大
withBroadcastSet需要在要使用到广播的操作后调用- 需要手动导入
scala.collection.JavaConverters._将Java集合转换为scala集合
6. Flink的累加器
Accumulator即累加器,与MapReduce counter的应用场景差不多,都能很好地观察task在运行期间的数据变化
可以在Flink job任务中的算子函数中操作累加器,但是只能在任务执行结束之后才能获得累加器的最终结果。
Flink现在有以下内置累加器。每个累加器都实现了Accumulator接口。
- IntCounter
- LongCounter
- DoubleCounter
操作步骤:
1:创建累加器
private IntCounter numLines = new IntCounter();
2:注册累加器
getRuntimeContext().addAccumulator("num-lines", this.numLines);
3:使用累加器
this.numLines.add(1);
4:获取累加器的结果
myJobExecutionResult.getAccumulatorResult("num-lines")
示例:
遍历下列数据, 打印出单词的总数
"a","b","c","d"
开发步骤:
- 获取批处理环境
- 加载本地集合
- map转换
- 定义累加器
- 注册累加器
- 累加数据
- 数据写入到文件中
- 执行任务,获取任务执行结果对象(JobExecutionResult)
- 获取累加器数值
- 打印数值
代码:
import org.apache.flink.api.common.accumulators.IntCounter
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.configuration.Configuration
/**
* counter 累加器
* Created by zhangjingcun.tech on 2018/10/30.
*/
object BatchDemoCounter {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val data = env.fromElements("a","b","c","d")
val res = data.map(new RichMapFunction[String,String] {
//1:定义累加器
val numLines = new IntCounter
override def open(parameters: Configuration): Unit = {
super.open(parameters)
//2:注册累加器
getRuntimeContext.addAccumulator("num-lines",this.numLines)
}
var sum = 0;
override def map(value: String) = {
//如果并行度为1,使用普通的累加求和即可,但是设置多个并行度,则普通的累加求和结果就不准了
sum += 1;
System.out.println("sum:"+sum);
this.numLines.add(1)
value
}
}).setParallelism(1)
// res.print();
res.writeAsText("d:\\data\\count0")
val jobResult = env.execute("BatchDemoCounterScala")
// //3:获取累加器
val num = jobResult.getAccumulatorResult[Int]("num-lines")
println("num:"+num)
}
}
Flink Broadcast和Accumulators的区别
Broadcast(广播变量)允许程序员将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。广播变量可以进行共享,但是不可以进行修改
Accumulators(累加器)是可以在不同任务中对同一个变量进行累加操作
7. Flink的分布式缓存
Flink提供了一个类似于Hadoop的分布式缓存,让并行运行实例的函数可以在本地访问。这个功能可以被使用来分享外部静态的数据,例如:机器学习的逻辑回归模型等!
缓存的使用流程:
使用ExecutionEnvironment实例对本地的或者远程的文件(例如:HDFS上的文件),为缓存文件指定一个名字注册该缓存文件。当程序执行时候,Flink会自动将复制文件或者目录到所有worker节点的本地文件系统中,函数可以根据名字去该节点的本地文件系统中检索该文件!
注意:广播是将变量分发到各个worker节点的内存上,分布式缓存是将文件缓存到各个worker节点上
操作步骤:
1:注册一个文件
env.registerCachedFile("hdfs:///path/to/your/file", "hdfsFile")
2:访问数据
File myFile = getRuntimeContext().getDistributedCache().getFile("hdfsFile");
示例:
遍历下列数据, 并在open方法中获取缓存的文件
a,b,c,d
代码:
import org.apache.commons.io.FileUtils
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.configuration.Configuration
/**
* 分布式缓存
*/
object BatchDemoDisCache {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//隐式转换
import org.apache.flink.api.scala._
//1:注册文件
env.registerCachedFile("d:\\data\\file\\a.txt","b.txt")
//读取数据
val data = env.fromElements("a","b","c","d")
val result = data.map(new RichMapFunction[String,String] {
override def open(parameters: Configuration): Unit = {
super.open(parameters)
//访问数据
val myFile = getRuntimeContext.getDistributedCache.getFile("b.txt")
val lines = FileUtils.readLines(myFile)
val it = lines.iterator()
while (it.hasNext){
val line = it.next();
println("line:"+line)
}
}
override def map(value: String) = {
value
}
})
result.print()
}
}