Flink学习(二) job 执行流程
本片文章主要介绍以下2点:1、job代码是如何被编译成ExecutionGraph。2、任务是如何运行和调度。(以RemoteEnvironment 模式记录而非Local)。
flink job 是如何生成ExecutionGraph
首先看下简单的flink 消费Kafka的代码:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "test");
FlinkKafkaConsumer010<String> consumer = new FlinkKafkaConsumer010<String>("pepsi-test",
new SimpleStringSchema()
,properties);
env.addSource(consumer)
.process(...)
.keyBy(1)
.timeWindow(Time.seconds(10))
.aggregate(....)
.sink();
env.execute();
}
- 算子(transform)的注册 : 从代码中可看到,首先我们获取到当前运行的环境信息: StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();这个环境主要记录了并行度配置、算子信息、checkpoint 等配置信息,同时提供了整个flink作业运行的方法入口:execute方法。
这里每个操作都是一个算子(transform),如:source、process、sink、keyby(虚拟节点)等都属于算子。算子的注册就是将其添到StreamExecutionEnvironment的transformations集合中。
代码参考如下
public <R> SingleOutputStreamOperator<R> transform(String operatorName, TypeInformation<R> outTypeInfo, OneInputStreamOperator<T, R> operator) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operator,
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({
"unchecked", "rawtypes" })
SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform);
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
- StreamGraph生成 : 程序真正执行入口是
env.execute这里,这里最终调用的是StreamGraphGenerator.generate()方法生成的StreamGraph,这个方法参考如下:
public static StreamGraph generate(StreamExecutionEnvironment env, List<StreamTransformation<?>> transformations) {
return new StreamGraphGenerator(env).generateInternal(transformations);
}
//从sink开始递归迭代一直向上找,直到最开始的算子(source)为止,生成node和edge
private StreamGraph generateInternal(List<StreamTransformation<?>> transformations) {
for (StreamTransformation<?> transformation: transformations) {
transform(transformation);
}
return streamGraph;
}
//transform 方法就是根据不同的处理类型做不同的处理,这里一坨if else ,方法就不列了。
//找个具体算子处理看下transformOneInputTransform
private <IN, OUT> Collection<Integer> transformOneInputTransform(OneInputTransformation<IN, OUT> transform) {
//算子之间的是否可以嵌到一起,group
String slotSharingGroup = determineSlotSharingGroup(transform.getSlotSharingGroup(), inputIds);
//生成StreamNode(有些transform操作不会生成node,而是生成虚拟节点)
streamGraph.addOperator(transform.getId(),
slotSharingGroup,
transform.getOperator(),
transform.getInputType(),
transform.getOutputType(),
transform.getName());
//keySelect
if (transform.getStateKeySelector() != null) {
TypeSerializer<?> keySerializer = transform.getStateKeyType().createSerializer(env.getConfig());
streamGraph.setOneInputStateKey(transform.getId(), transform.getStateKeySelector(), keySerializer);
}
//为当前节点和它的依赖节点建立边
for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId, transform.getId(), 0);
}
return Collections.singleton(transform.getId());
}
这个方法有2大步构成:
1、调用generateInternal方法循环遍历算子信息生成StreamNode以及Edge。
2、将Node和edge信息连接起来。edge 类似通道作用将2个Node连接起来。
3. JobGraph生成 : 从StreamGraph 到 JobGraph 的转换可以参考StreamingJobGraphGenerator.createJobGraph方法,简单描述如下:
private JobGraph createJobGraph() {
...代码省略 主要遍历StreamGraph,为每个StreamNode生成一个byte类型hash(当算子运行失败恢复时取值是根据JobVertexID取得)。
// 设置chain,从source节点开始遍历,将可以chain到一起的算子算入一个jobVertex,不能chain的单独生成一个jobVertex。算子chain到一起需要满足很多条件(下面会具体列出来)。
setChaining(hashes, legacyHashes, chainedOperatorHashes);
//设置输入边edge,将JobVertex 的入边(StreamEdge)序列化到该 StreamConfig
setPhysicalEdges();
//根据 group name 为每个 JobVertext 指定 SlotSharingGroup
setSlotSharing();
//配置检查点
configureCheckpointing();
return jobGraph;
}
chain概念
为了更高效地分布式执行,Flink会尽可能地将operator的subtask链接(chain)在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。
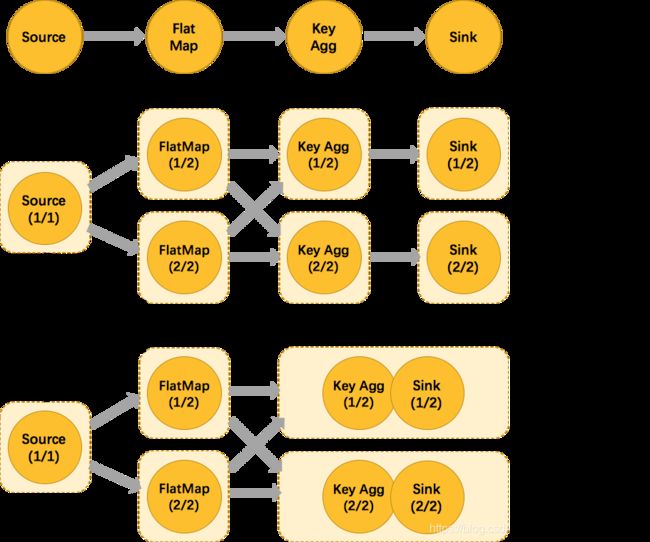
从上图可以看出将 keyagg 和 sink 算子 chain 到一起了,其实满足chain的条件比较多。参考如下描述:
public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) {
StreamNode upStreamVertex = edge.getSourceVertex();
StreamNode downStreamVertex = edge.getTargetVertex();
StreamOperator<?> headOperator = upStreamVertex.getOperator();
StreamOperator<?> outOperator = downStreamVertex.getOperator();
return //下游节点职能有一个输入
downStreamVertex.getInEdges().size() == 1
//上下游算子操作符不能为空
&& outOperator != null
&& headOperator != null
//上下游节点在一个槽位共享组内。
&& upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
//下游节点的连接策略是 ALWAYS同时上游节点的连接策略是 HEAD 或者 ALWAYS。
&& outOperator.getChainingStrategy() == ChainingStrategy.ALWAYS
&& (headOperator.getChainingStrategy() == ChainingStrategy.HEAD ||
headOperator.getChainingStrategy() == ChainingStrategy.ALWAYS)
//上下游节点分区方式是forward
&& (edge.getPartitioner() instanceof ForwardPartitioner)
//下游节点只有一个输入且上下游并行度一致
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
&& streamGraph.isChainingEnabled();
}
生成jobvertx节点
这里从source节点开始循环遍历,不能chain的单独生成一个jobvertx.将可以chain到一起的节点从最开始的节点生成一个jobvertx,其他的chain节点通过写入StreamConfig中。
在看 JobGraph 生成的时候我们发现是生成 JobGraph 后就 send 到JM 了,所以我们的 ExecutionGraph 不是在 client 端生成了,如下:
public JobSubmissionResult run(FlinkPlan compiledPlan,
List<URL> libraries, List<URL> classpaths, ClassLoader classLoader, SavepointRestoreSettings savepointSettings)
throws ProgramInvocationException {
JobGraph job = getJobGraph(flinkConfig, compiledPlan, libraries, classpaths, savepointSettings);
return submitJob(job, classLoader);
}
- ExecutionGraph生成 : 这个生成ExecutionGraph代码入口在ExecutionGraphBuilder#attachJobGraph方法中。参考代码如下:
public void attachJobGraph(List<JobVertex> topologiallySorted) throws JobException {
//循环已经排序的jobVertex,
for (JobVertex jobVertex : topologiallySorted) {
//生成 ExecutionJobVertex,1、构建 IntermediateResult、ExecutionVertex、IntermediateResultPartition等
ExecutionJobVertex ejv = new ExecutionJobVertex(
this,
jobVertex,
1,
rpcTimeout,
globalModVersion,
createTimestamp);
//构建 ExecutionEdge ,和前面生成的IntermediateResultPartition连接起来。
for (IntermediateResult res : ejv.getProducedDataSets()) {
IntermediateResult previousDataSet = this.intermediateResults.putIfAbsent(res.getId(), res);
if (previousDataSet != null) {
throw new JobException(String.format("Encountered two intermediate data set with ID %s : previous=[%s] / new=[%s]",
res.getId(), res, previousDataSet));
}
}
}
这里生成ExecutionGraph的流程也可以分为2个部分理解:
1、新建 ExecutionJobVertex。循环已排序 jobVertex,根据 jobVertex 构建IntermediateResult(个数根据下游节点的个数)
2、把每个ExecutorVertex和对应的IntermediateResult关联起来。
这样 ExecutionGraph 创建完成。
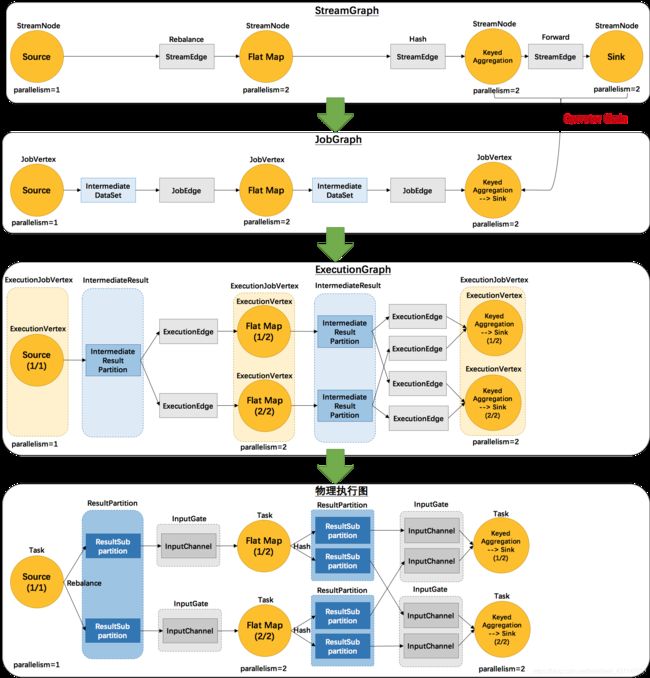
这里官网提供了3层转换的图,如下
ExecutionGraph如何被调度和执行
flink Run Time 结构
 Flink Runtime 层的主要架构如上图所示,下面主要说下Dispatcher、ResourceManager 和 JobManager。
Flink Runtime 层的主要架构如上图所示,下面主要说下Dispatcher、ResourceManager 和 JobManager。
Dispatcher 负责接收用户提供的作业,并且负责为这个新提交的作业拉起一个新的 JobManager 组件。
ResourceManager 负责资源的管理,在整个 Flink 集群中只有一个 ResourceManager。
JobManager 负责管理作业的执行,在一个 Flink 集群中可能有多个作业同时执行,每个作业都有自己的 JobManager 组件。
任务的调度
上文介绍 flink 的运行结构,这里先忽略Dispatch(有无dispatch 提交的对象不一样,没有Dispatch 则将job提交到YarnResourceManager,这里我们直接先跳过)。最终我们提交的任务会来到JobManager,生成ExecuteGraph,以及建立了很多JobManagerActors、TaskManagerActor等。最终代码如下:
private def submitJob(jobGraph: JobGraph, jobInfo: JobInfo, isRecovery: Boolean = false): Unit = {
executionGraph = ExecutionGraphBuilder.buildGraph(
executionGraph,
jobGraph,
flinkConfiguration,
futureExecutor,
ioExecutor,
scheduler,
userCodeLoader,
checkpointRecoveryFactory,
Time.of(timeout.length, timeout.unit),
restartStrategy,
jobMetrics,
numSlots,
blobServer,
log.logger)
...
executionGraph.scheduleForExecution()
...
}
最终经过executionGraph.scheduleForExecution()方法后将ExecutionVertex传给taskManager用于执行,当TaskExecutor 收到 JobManager 提交的 Task 之后,会启动一个新的线程来执行该 Task。这里设计到很多资源申请如JobManager向RM申请资源来启动任务,目前我也没有明白其中的步骤,后续会对于任务资源和调度这块会详细在梳理一下。