siamese(孪生) 网络以及迁移学习的应用
孪生,顾名思义,就是长相一样的双胞胎。对于深度学习模型来说就是一种相似性度量网络。表面上画出的网络分为两路,而这两路网络一模一样。因此,同一个输入数据分别输入到两个网络,最后的输出也一样。那么相似的输入,输出也应当很相识。基于这种特性,孪生网络特别适合带有准确标签的样本在整个样本中的比率很小,但整个的数据集的体量又很大的情况。特别是对于现在的深度学习,都是数据驱动型的。如果每个类别的样本太少,根本训练不出什么好的结果。孪生网络从数据中学习样本之间的差异或相识度,用这个学习出来的度量或特征表达去匹配新的未知类别的样本。那么确定少量的标签,通过带有标签的样本和未有标签的样本差异或相识度,或者二次学习,可以取得较好的分类效果。
原理
其网络结构图如下:
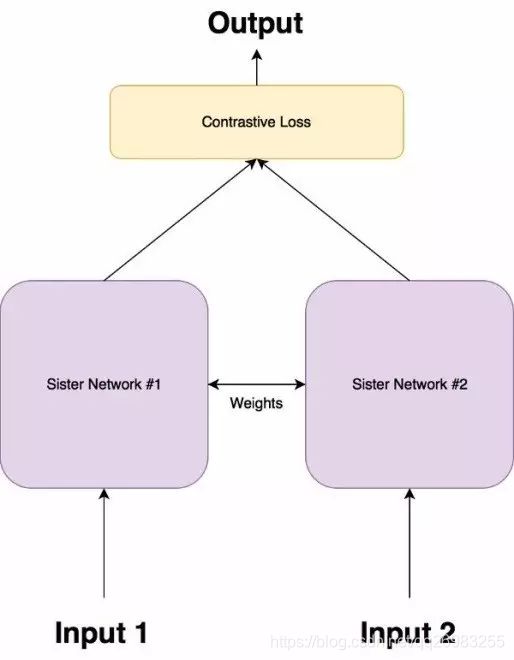
两个网络完全一样,并且共享权值。其实真实模型就是一支,不过当成两支来用,并且他们的输出是一维向量(长度可为1,也可为1024或其他长度,可以称为为特征描述子)
一方面,输出的是长度大于1的特征向量的话,类似于分类,比如说最后层的shape为1X1024的向量。
如果输入的图像是同一张或者比较相识,那么他们的输出的一维向量就相似,换句话说,两个向量之间的欧式距离比较小。
如果输入的图像差别较大,那么他们的输出向量之间的欧氏距离相对较大。

采用人物图片的例子,同一个人的两张图片之间的差异要小于不同人的两张图片。

从这个公式上看,如果一同输入的两张图片都是不同图片,就只剩后半部分。loss函数值越小证明识别的越好。
另一方面,如果输出的是一个标量,即类似于回归。‘
这样我们可以利用标量大小来区分相识度。
rankIQA:Learning from Rankings for No-reference Image Quality Assessment
我们采用一个项目来说明孪生网络的一些用法。通过这个项目,我们还可以了解到迁移学习的用法(因为需要两个阶段的训练,第二个阶段需要第一个阶段的训练结果),
该项目是通过少量的带有标签的数据集(清晰度等级分明。噪声种类分明等),通过两个阶段,一:rank_train,该阶段是一个利用孪生网络进行训练的阶段,该阶段的数据,只有数据之间的差异,没有明确的等级;即,我只知道两个图片之间有清晰度的不同,但是具体他们属于哪一等级的不知道。该项目的tensorflow版本github地址在这里
该博客已经把训练过程的注意事项整理好。但是我在这里跟rankIQA的具体训练还有点不一样(主要是数据集之间的差异)。通过该博客或者该论文,我们知道作者是通过回归的方式进行训练的。并且采用一个batch送进去不同的图片。
我们知道,神经网络在训练阶段,一个batch送进去,即为经过一个step,那么网络中的参数更新一次。所以,相当于一个batch内的数据共享权值。并且参数更新方向,也是batch内各个样本共同作用的结果,比如说batch的样本数量为5个,他们经过梯度下降法得知在某一方向(假设为y1)中的更新值为(-1,-2,3,-2, 3),他们的和为1,那么该step在y1方向的更新就为1。
所以,我们只要设计好了batch内的数据样本顺序排列就可以做到孪生网络的数据共享模式。
当然你也可以利用其他方式,在tensorflow中已经有了reuse_variables(),这种重用变量的模式:
with tf.variable_scope('siamese') as scope:
out1 = siamese(x_input_1,keep_prob)
scope.reuse_variables()
out2 = siamese(x_input_2,keep_prob)
rankIQA中,就是要学到不同图片的distortion的程度之间的差异。这个distortion的程度不需要精确的标签,只要是同类型有差异即可。
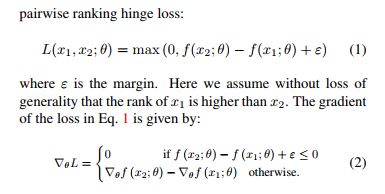
假设一个图片只有一种distortion,6个distortion等级。根据公式2,需要满足一定条件才会有梯度值。这里采用了回归的方式输出图片质量分数。原图的分数最高(当然,这里分数没有groundtrue,是相对而不是绝对分值)。如果一个batch时24,那么一共输入进去四张原图。这样在输出时,将结果reshape成4*6的矩阵R,那么每一行是原图和其对应的distortion的回归结果。例如(y1,y2,y3,y4,y5,y6)。那么他们之间的差值为(y1-y2)+(y1-y3)+(y1-y4)+(y1-y5)+(y1-y6)+(y2-y3)+(y2-y4)+(y2-y5)+(y2-y6)+(y3-y4)+(y3-y5)+(y3-y6)+(y4-y5)+(y4-y6)+(y5-y6),这样如果用for循环这太费劲,并且tensorflow框架下的循环函数很不好用。这样提供一个算子O可以达到相同效果:
mat_value = [[5, 0, 0, 0, 0],
[-1, 4, 0, 0, 0],
[-1, -1, 3, 0, 0],
[-1, -1, -1, 2, 0],
[-1, -1, -1, -1, 1],
[-1, -1, -1, -1, -1]]这样Y= [y1,y2,y3,y4,y5,y6] 叉乘 mat_value后在求和即可。即使整个的4*6的矩阵R 叉乘后,再将所有的矩阵元素求和即可。
logits = tf.reshape(tensor=logits, shape=[config.train_batch_size, config.level_num])
mat_loss = tf.matmul(logits, tf_mat_value)
mat_loss = 100.0 - mat_loss
mat_loss = tf.maximum(0.0, mat_loss)
vaule_loss = tf.reduce_mean(mat_loss, axis=[0, 1])迁移学习
迁移学习就是通过前人已经训练好的模型,微调或者只调整部分节点参数进行训练,可以很好的达到想要的结果。
tensorflow在加载ckpt模型时,可以有选择的去加载变量,比如说经常用的图像的特征提取就是舍去最后一层的全连接层。总之需要做的就是,老模型的部分参数加载->模型的训练->新模型的保存。
init = tf.global_variables_initializer()
g_list = tf.global_variables()
saver = tf.train.Saver(var_list=g_list)
params = slim.get_variables_to_restore(exclude=['resnet_v2/logits'])
restore = tf.train.Saver(params)
start_time = time.time()
tf_config = tf.ConfigProto()
# tf_config.gpu_options.per_process_gpu_memory_fraction = 0.4
with tf.Session(config=tf_config) as sess:
sess.run(init)
ckpt = tf.train.get_checkpoint_state(config.model_dir_rank)
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
print('restore model', ckpt.model_checkpoint_path)
restore.restore(sess, ckpt.model_checkpoint_path)
...............
...............
...............
saver.save(sess, checkpoint_path, global_step=global_step)其中的slim.get_variables_to_restore(include=None, exclude=None)函数中包括了包含和排除连个参数,这里时去掉了最后一层的一个参数,并且参数接收的是一个list,即可添加多个排除或包括变量名。里面是tensorflow中scope下的参数名,例子中是'resnet_v2/logits',如果是‘resnet_v2’,那么
with tf.variable_scope('resnet_v2'):
.....
..... 该scope下定义的变量全部排除。
在tf.train.Saver(var_list=None)中 定义了saver和restore. 这其中就是需要恢复或保存的变量。
保存模型权重
如果想抽取变量的具体值,或者把所有值都保存下来生成.npy文件。
from tensorflow.python import pywrap_tensorflow
import tensorflow as tf
ckpt = tf.train.get_checkpoint_state(config.model_dir)
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
reader = pywrap_tensorflow.NewCheckpointReader(ckpt.model_checkpoint_path)
var_to_shape_map = reader.get_variable_to_shape_map()
param = []
for key in var_to_shape_map:
print("var_tensor_name", key)
param.append(reader.get_tensor(key))
np.save('dnnout.npy', param)当然,这里也可以保存成字典类型,这样也可以方便根据变量名字取出其对应的变量值。
另一方面,我们在进行推理阶段经常使用pb文件,pb文件不仅可以提取OP节点的值,还可以提取变量。你只需知道变量的名字即可。在这里解释一下变量和OP节点。深度学习是模仿人类的神经系统,两个神经细胞是通过一条线连接(当然,生物学上有其具体学名),我们也经常在深度学习中这样描绘网络。那么细胞相当于什么,中间的线又是什么?细胞(节点)可以当成是OP,在这里进行计算,并得到节点值。计算参与的元素是上一细胞的节点值和连接两节点中间的线。那么中间连接的线,就可以当成是变量,我们对神经网络进行训练,也是训练这个地方。如果时起始节点,那么其值是直接喂进去的,在tensorflow中为placehold
提取变量,就需要知道变量的名字,恰巧我们在生成npy格式的数据时,用到了变量名。
with tf.Graph().as_default() as graph:
output_graph_def = tf.GraphDef()
with open(config.save_mode_pb_path, "rb") as f:
print('pb path is ', config.save_mode_pb_path)
output_graph_def.ParseFromString(f.read())
tf.import_graph_def(output_graph_def, name="")
with tf.Session() as sess:
out_tttt = sess.graph.get_tensor_by_name("conv3/weights:0")
print(sess.run(out_tttt))打印显示的即是,conv3/weights该变量的具体值。
多个模型合并
之前介绍过多个pb文件合并成一个,但是如果有多个ckpt文件该如何恢复呢。在恢复之前需要对tensorflow的sess和graph有个详细的了解,这个就不过多的介绍。总之,一个graph可以有多个sess进行操作,但是一个sess里面有多个graph这个应当当心,因为我们在恢复模型的时候,一般是
saver.restore(sess, ckpt.model_checkpoint_path)
这种恢复应当注意的是,只是恢复的变量(训练好的变量,加载到模型里面),如果一个节点不涉及变量是不影响往里面添加或者删除的。因此在使用该方法进行恢复模型的时候,需要重新写一下网络模型的具体步骤。但是,在一个sess恢复加载多个图,例如,模型1的输出是模型2的输入。这种使用该方法在一个sess进行加载是会报错的。具体想法为:在加载之前你需要写一下模型的具体步骤(两个模型都要写),恢复两个模型需要使用两次saver.restore。第一次没问题,在到达第二次时,因为之前两个模型的具体步骤都写了,那么第二个模型里面并没有第一个模型里面的变量。导致模型和参数的不匹配。
突破口在于:两个模型都是我们自己编写,熟悉其中的步骤。并且他们之间的变量名不能重复(可以使用scope),加上saver.restore恢复的方法是恢复变量。我们只需要把两个模型的变量提取出来,放入新的模型model_new中。然后在一个sess里面重写第一个第二个模型的详细步骤,使用saver.restore恢复model_new保存的变量即可:
def merge_cpks():
guide_model_path = './model_1'
main_model_path = './model_2'
save_path = './model_new'
with tf.Session() as sess:
for var_name, _ in tf.contrib.framework.list_variables(main_model_path):
# Load the variable
var = tf.contrib.framework.load_variable(main_model_path, var_name)
print(var_name)
var = tf.Variable(var, name=var_name)
for var_name, _ in tf.contrib.framework.list_variables(guide_model_path):
var = tf.contrib.framework.load_variable(guide_model_path, var_name)
print(var_name)
var = tf.Variable(var, name=var_name)
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
sess.run(var)
saver.save(sess, os.path.join(save_path, 'model.ckpt'))执行后会发现在model_new里面有四个文件。这跟正常训练保存的四个文件的格式一模一样。