Flink介绍,窗口和状态的原理及基础使用(scala)
Flink入门学习记录,窗口状态原理及基础使用
- Flink学习记录(窗口,状态原理及基础使用)
-
- Flink为什么流行
-
- 1.擅长处理有界和无界数据
- 2.部署到任意地方
- 3.运行任意规模的应用
- 4.利用内存性能
- Flink怎么运作
- Flink背后的方法支撑
-
- 1.灵活的窗口机制
- 2.有状态的计算
- 以出租车数据处理过程为例
-
- 1.环境准备与起步
- 2.行驶数据清洗(基本算子的使用)
- 3.小时最高数据(窗口的使用)
- 4.费用匹配(状态的使用)
- 5.计时器(过期状态的处理)
Flink学习记录(窗口,状态原理及基础使用)
总的来说Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。这里主要对Flink的特性,Flink的运作方式,特性背后的方法支撑,以及以出租车数据处理过程为例的对基本算子使用,窗口以及状态的使用进行介绍。
Flink为什么流行
1.擅长处理有界和无界数据
任何类型的数据都能够形成一种流,数据可以被作为无界或者有界流来处理。
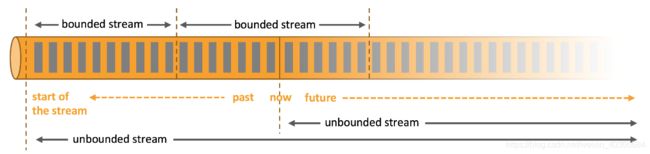
Apache Flink 擅长处理无界和有界数据集 精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
2.部署到任意地方
Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同时也可以作为独立集群运行。
3.运行任意规模的应用
Flink 旨在任意规模上运行有状态流式应用。因此,应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。而且 Flink 很容易维护非常大的应用程序状态。其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
4.利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。

Flink怎么运作
接下来介绍它的基本工作原理:
Flink在运行中主要有三个组件组成,JobClient,JobManager 和 TaskManager。主要工作原理如下图。

用户首先提交Flink程序到JobClient,经过JobClient的处理、解析形成执行计划、将相邻的Operator融合为OperatorChain优化(让一些能够在同一个节点里面进行处理的算子比如keyby后面接一个窗口,融合为一个小任务减少任务数量,提高效率)提交到JobManager进行集群资源的申请,调度任务分发到各个节点的TaskManager,最后由TaskManager(进程 ,一个JVM)中的Slot(资源划分的最小单位)执行task。
Flink背后的方法支撑
1.灵活的窗口机制
Flink提供了非常完善的窗口机制。Flink 认为 Batch是 Streaming 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。而窗口(window)就是从 Streaming 到 Batch 的一个桥梁。Flink 提供了非常完善的窗口机制。
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
窗口可以是时间驱动的(Time Window,例如:每30秒钟),也可以是数据驱动的(Count Window,例如:每一百个元素)。一种经典的窗口分类可以分成:翻滚窗口(Tumbling Window,无重叠),滚动窗口(Sliding Window,有重叠),和会话窗口(Session Window,活动间隙)。Flink 提供了下图中所有的窗口类型。

2.有状态的计算
有状态计算是指在程序计算过程中,在Flink程序内部存储计算产生的中间结果,并提供给后续Function或算子计算使用。状态数据可以维系在本地存储中,这里的存储可以是Flink的堆内存或者堆外内存,也可以借助第三方的存储介质,例如Flink中已经实现的RocksDB,当然用户也可以自己实现相应的缓存系统去存储状态信息,以完成更加复杂的计算逻辑。
举几个例子,状态计算可以将接入的事件进行存储,然后等待符合规则的事件触发:
(1)用户想按照分钟,小时、天进行聚合计算,求取当前的最大值、均值等聚合指标,这就需要利用状态来维护当前计算过程中产生的结果,例如事件的总数,平均数以及最大,最小值。
(2)用户想在Strem上实现机器学习的模型训练,状态计算可以帮助用户维护当前版本模型使用的参数
(3)流处理中,当我们的节点挂掉,我们想从某一个时间点继续开始而不是从头开始。
为了实现上面提到的状态计算,Flink 提供了许多状态管理相关的特性支持,通过这些特性相信读者能够对状态有更深的了解,其中包括:
(1)多种状态基础类型:Flink 为多种不同的数据结构提供了相对应的状态基础类型,例如原子值(value),列表(list)以及映射(map)。开发者可以基于处理函数对状态的访问方式,选择最高效、最适合的状态基础类型。
(2)插件化的State Backend:State Backend 负责管理应用程序状态,并在需要的时候进行 checkpoint。Flink 支持多种 state backend,可以将状态存在内存或者 RocksDB。RocksDB 是一种高效的嵌入式、持久化键值存储引擎。Flink 也支持插件式的自定义 state backend 进行状态存储。
(3)精确一次语义:Flink 的 checkpoint 和故障恢复算法保证了故障发生后应用状态的一致性。因此,Flink 能够在应用程序发生故障时,对应用程序透明,不造成正确性的影响。
(4)超大数据量状态:Flink 能够利用其异步以及增量式的 checkpoint 算法,存储数 TB 级别的应用状态。
(5)可弹性伸缩的应用:Flink 能够通过在更多或更少的工作节点上对状态进行重新分布,支持有状态应用的分布式的横向伸缩。
而分布式系统中的有状态计算绕不开一致性问题。举个例子,当我们想要获得集群的状态(快照),也就是说我们想要获得每个节点的状态,那么对于有状态的计算有一个难点,状态是不断变化的,由于是分布式的,那么不能共享内存或者拥有全球时钟,而也不能让整个集群停下来等待当前状态的获取与发送。Flink为了解决这个问题引入了异步屏障快照算法(ABS):
屏障由Flink的JobManager周期性产生(周期长度由StreamExecutionEnvironment. enableCheckpointing()方法来指定),并广播给所有Source算子,沿着数据流流动下去。
仍然举例说明。下图是ABS论文中给出的并行度为2的Word Count示例,注意该作业的执行计划为有向无环图(DAG)。
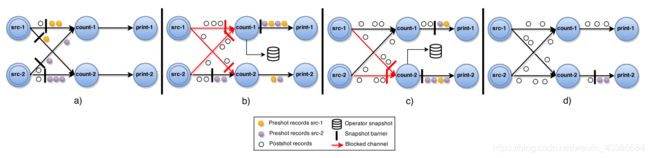
快照算法的步骤如下:
a) Source算子接收到JobManager产生的屏障,生成自己状态的快照(其中包含数据源对应的offset/position信息),并将屏障广播给下游所有数据流;
b)、c) 下游非Source的算子从它的某个输入数据流接收到屏障后,会阻塞这个输入流,继续接收其他输入流,直到所有输入流的屏障都到达(图中的count-2算子接收的两个屏障就不是同时到达的)。一旦算子收齐了所有屏障,它就会生成自己状态的快照,并继续将屏障广播给下游所有数据流;
d) 快照生成后,算子解除对输入流的阻塞,继续进行计算。Sink算子接收到屏障之后会向JobManager确认,所有Sink都确认收到屏障标记着这一周期checkpoint过程结束,快照成功。
可见,如果算子只有一个输入流的话,问题就比较简单,只需要在收到屏障之后立即做快照。但是如果有多个输入流,就必须要等待收到所有屏障才能做快照,以避免将检查点n与检查点n + 1的数据混淆。这个等待的过程就叫做对齐(alignment),图来自官方文档。注意算子内部有个输入缓冲区,用来在对齐期间缓存数据。

但是对齐过程需要时间,有一些对延迟特别敏感的应用可能对准确性的要求没有那么高。所以Flink也允许在StreamExecutionEnvironment.enableCheckpointing()方法里指定At-Least-Once语义,会取消屏障对齐,即算子收到第一个输入的屏障之后不会阻塞。这样一来,部分属于检查点n + 1的数据也会包括进检查点n的数据里,当恢复时,这部分数据就会被重复处理。
以出租车数据处理过程为例
1.环境准备与起步
程序下载地址:https://github.com/ververica/flink-training-exercises
我们将要使用的是纽约2013年中一月的出租车数据。数据构成为:
(数据id,是否已结束,开始时间,结束时间,开始地点,结束地点,乘客数量,出租车编号,驾驶员编号)
通过一个数据类TaxiRideSource将出租车数据模拟为一个实时的数据流。

一个Flink的WordCount完整程序示例:
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
object WordCountStreamingByScala {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//加载或创建数据源
val source = env.socketTextStream("192.168.1.111",9999,'\n')
//转化处理数据
val dataStream = source.flatMap(_.split(" "))
.map((_,1))
.keyBy(0)
.timeWindow(Time.seconds(2),Time.seconds(2))
.sum(1)
//输出到目的端
dataStream.print()
//执行操作
env.execute("Flink Streaming Word Count By Scala")
}
}
2.行驶数据清洗(基本算子的使用)
数据清洗是一个经典的应用场景,通常会使用map,flatMap,filter,keyBy等算子,这些算子的作用相信大家都不陌生。那么在Flink中的使用和在Spark中很类似。不同的是可以通过重写RichFlatMapFunction(I,O)这类接口函数中的flatMap方法来对对应flatMap等算子进行自定义和状态的使用。
@Public
public abstract class RichMapFunction<IN, OUT> extends AbstractRichFunction implements MapFunction<IN, OUT> {
private static final long serialVersionUID = 1L;
public RichMapFunction() {
}
public abstract OUT map(IN var1) throws Exception;
}
值得注意的是,在FlatMapFunction中,就已经有可供改写的flatMap抽象函数了,那么这里为什么还要继承AbstractRichFunction呢?实际使用中,如果仅仅是使用这个flatMap算子,那么直接继承FlatMapFunction对flatMap算子进行重写也是可以的。但是Rich系列函数通过继承AbstractRichFunction提供了两个关键方法:getRuntimeContext()与open()用于获取算子的状态和对算子进行初始化时调用。提供了对状态的使用,当重写了flatMap函数后可以在处理过程中调用这个类进行对应的处理。
//[In,Out] 不知道输入输出什么就写Any 而在函数中可以采取空着的方式解决。
class enrichedRideMapFunction extends RichMapFunction[TaxiRide, Any] {
override def map(ride:TaxiRide) =
( ride.rideId,
ride.isStart,
ride.startTime,
ride.endTime,
ride.startLon,
ride.startLat,
ride.endLon,
ride.endLat,
ride.passengerCnt,
ride.taxiId,
ride.driverId,
GeoUtils.mapToGridCell(ride.startLon, ride.startLat),
GeoUtils.mapToGridCell(ride.endLon, ride.endLat))
}
package com.ververica.flinktraining.solutions.datastream_scala.basics
import com.ververica.flinktraining.exercises.datastream_java.datatypes.TaxiRide
import com.ververica.flinktraining.exercises.datastream_java.sources.TaxiRideSource
import com.ververica.flinktraining.exercises.datastream_java.utils.ExerciseBase._
import com.ververica.flinktraining.exercises.datastream_java.utils.{
ExerciseBase, GeoUtils}
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
/**
* Scala reference implementation for the "Ride Cleansing" exercise of the Flink training
* (http://training.ververica.com).
*
* The task of the exercise is to filter a data stream of taxi ride records to keep only rides that
* start and end within New York City. The resulting stream should be printed to the
* standard out.
*
* Parameters:
* -input path-to-input-file
*
*/
object RideCleansingSolution {
//[In,Out] 不知道输入输出什么就写Any 而在函数中可以采取空着的方式解决。
class enrichedRideMapFunction extends RichMapFunction[TaxiRide, Any] {
override def map(ride:TaxiRide) =
( ride.rideId,
ride.isStart,
ride.startTime,
ride.endTime,
ride.startLon,
ride.startLat,
ride.endLon,
ride.endLat,
ride.passengerCnt,
ride.taxiId,
ride.driverId,
GeoUtils.mapToGridCell(ride.startLon, ride.startLat),
GeoUtils.mapToGridCell(ride.endLon, ride.endLat))
}
def main(args: Array[String]) {
// parse parameters
val params = ParameterTool.fromArgs(args)
val input = params.get("input", pathToRideData)
val maxDelay = 60 // events are out of order by max 60 seconds
val speed = 600 // events of 10 minutes are served in 1 second
// set up the execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(ExerciseBase.parallelism)
// get the taxi ride data stream
val rides = env.addSource(rideSourceOrTest(new TaxiRideSource(input, maxDelay, speed)))
val filteredRides = rides
.filter(r => GeoUtils.isInNYC(r.startLon, r.startLat) && GeoUtils.isInNYC(r.endLon, r.endLat))
.map(new enrichedRideMapFunction())
// print the filtered stream
printOrTest(filteredRides)
// run the cleansing pipeline
env.execute("Taxi Ride Cleansing")
}
}
3.小时最高数据(窗口的使用)
“小时最高提示”练习的任务是确定每小时赚取最多小费的驾驶员。方法是分两个步骤:首先使用一个小时的窗口,计算每个小时内每个驾驶员的小费总数,然后从该窗口结果流中,找到每个小时内小费总数最大的驾驶员。
结合前面介绍的窗口与时间的内容,可以想到以下解题思路:我们对每个司机(ID)定义一个计时窗口,当数据流通过,记录好每一个司机在每小时的小费总数,然后将这些总数作为数据流继续发出。再将这一个小时里面的数据流里的最值再通过一个计时窗口找到。只要时间范围兼容(第二组窗口的持续时间必须是第一组的倍数),就可以级联一组时间窗口。因此,可以拥有一组由driverId键控的初始小时窗口,并使用该窗口集创建(endOfHourTimestamp,driverId,totalTips)流,然后再跟另一个小时窗(此窗口未键值化) )从第一个窗口中找到具有最大totalTips的记录。可以通过以下语句定义一个时间窗口:
val fares = env.addSource(fareSourceOrTest(new TaxiFareSource(input, maxDelay, speed)))
val hourlytips =fares
.map((f:TaxiFare)=>(f.driverId,f.tip))
.keyBy(_._1)
.timeWindow(Time.hours(1))
这里我们需要使用Flink的窗口聚合函数,它分为两类,增量聚合和全量聚合。增量聚合窗口不维护原始数据,只维护中间结果,每次基于中间结果和增量数据进行聚合,如: ReduceFunction、AggregateFunction。全量聚合窗口需要维护全部原始数据,窗口触发进行全量聚合。如:ProcessWindowFunction。

通过把reduce和ProcessWindowFunction结合起来,能够在高效的同时获取到元数据的信息,这里我们想要获取的是Context(提到Context就代表可以使用状态了)提供的窗口结束时间:
// start the data generator
val fares = env.addSource(fareSourceOrTest(new TaxiFareSource(input, maxDelay, speed)))
val hourlytips =fares
.map((f:TaxiFare)=>(f.driverId,f.tip))
.keyBy(_._1)
.timeWindow(Time.hours(1))
.reduce((f1:(Long,Float),f2:(Long,Float))=>{
(f1._1,f1._2+f2._2)},new WrapwithWindowInfo())
class WrapwithWindowInfo() extends ProcessWindowFunction[(Long,Float),(Long,Long,Float),Long,TimeWindow]{
override def process(key: Long, context: Context, elements: Iterable[(Long, Float)], out: Collector[(Long, Long, Float)]): Unit = {
val sumOfTips=elements.iterator.next()._2
out.collect((context.window.getEnd,key,sumOfTips))
}
}
接下来通过窗口级联将每个司机的每小时小费总数都放到一个小时窗口内,在这个小时窗口内通过maxBy()获取最高的那条数据。
import com.ververica.flinktraining.exercises.datastream_java.datatypes.TaxiFare
import com.ververica.flinktraining.exercises.datastream_java.sources.TaxiFareSource
import com.ververica.flinktraining.exercises.datastream_java.utils.{
ExerciseBase, MissingSolutionException}
import com.ververica.flinktraining.exercises.datastream_java.utils.ExerciseBase._
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/**
* The "Hourly Tips" exercise of the Flink training
* (http://training.ververica.com).
*
* The task of the exercise is to first calculate the total tips collected by each driver, hour by hour, and
* then from that stream, find the highest tip total in each hour.
*
* Parameters:
* -input path-to-input-file
*
*/
object HourlyTipsExercise {
def main(args: Array[String]) {
// read parameters
val params = ParameterTool.fromArgs(args)
val input = params.get("input", ExerciseBase.pathToFareData)
val maxDelay = 60 // events are delayed by at most 60 seconds
val speed = 600 // events of 10 minutes are served in 1 second
// set up streaming execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(ExerciseBase.parallelism)
// start the data generator
val fares = env.addSource(fareSourceOrTest(new TaxiFareSource(input, maxDelay, speed)))
val hourlytips =fares
.map((f:TaxiFare)=>(f.driverId,f.tip))
.keyBy(_._1)
.timeWindow(Time.hours(1))
.reduce((f1:(Long,Float),f2:(Long,Float))=>{
(f1._1,f1._2+f2._2)},new WrapwithWindowInfo())
val hourlyTipsMax=hourlytips
.timeWindowAll(Time.hours(1))
.maxBy(2)
// throw new MissingSolutionException()
// print result on stdout
printOrTest(hourlyTipsMax)
// execute the transformation pipeline
env.execute("Hourly Tips (scala)")
}
class WrapwithWindowInfo() extends ProcessWindowFunction[(Long,Float),(Long,Long,Float),Long,TimeWindow]{
override def process(key: Long, context: Context, elements: Iterable[(Long, Float)], out: Collector[(Long, Long, Float)]): Unit = {
val sumOfTips=elements.iterator.next()._2
out.collect((context.window.getEnd,key,sumOfTips))
}
}
}
4.费用匹配(状态的使用)
如果出租车的支付结算平台产生另外一个流fares费用流,我们怎样把它和我们的出租车数据流通过订单id进行匹配?
Flink支持两个流通过.connect()流入同一个运算符,称为连接流。所连接的两个流必须以兼容的方式进行键控——两个流都未键控,或者两者都被键控,并且如果它们都被键控,则键值必须相同。

Flink为这种连接流提供了对应的算子接口函数,比如RichCoFlatMapFunction:
@Public
public abstract class RichCoFlatMapFunction<IN1, IN2, OUT> extends AbstractRichFunction implements CoFlatMapFunction<IN1, IN2, OUT> {
private static final long serialVersionUID = 1L;
public RichCoFlatMapFunction() {
}
}
@Public
public interface CoFlatMapFunction<IN1, IN2, OUT> extends Function, Serializable {
void flatMap1(IN1 var1, Collector<OUT> var2) throws Exception;
void flatMap2(IN2 var1, Collector<OUT> var2) throws Exception;
}
与上面说到的普通的flatmap算子的重载类似,不同的是这里提供了两个flatMap函数供重载,一个流流入flatMap1另一个流入flatMap2,它们并不同步(两个流可以竞争流过自己的算子),但是共享相同的内存空间,也就是说可以访问同一个状态。同样地提供了open()和getRuntimeContext()方法。
那么状态怎样使用呢?通过创建StateDescriptor获得对应状态的句柄,保存状态的名称,并通过这个名称使用状态。状态通过 RuntimeContext 进行访问,因此只能在 rich functions 中使用。而状态实际上是分为两种,Keyed State表示和key相关的一种state,只能用于KeyedStream类型数据集对应的Functions和Operators之上。Keyed State是Operator State的特例,区别在于Keyed State事先按照key对数据集进行了分区,每个Key State仅对应一个Operator和Key的组合。而Operator State只和并行的算子实例绑定,和数据元素中的key无关,每个算子实例中持有所有数据元素中的一部分(当前slot里)状态数据。我们最常使用的为Keyed State。

下面是一个例子,首先声明了一个空的rideState变量(指针)它的类型就是我们需要的ValueState,在下面的open方法中,我们声明了一个ValueState状态,并将rideState指向了这个状态,接下来我们就可以通过这个rideState来直接使用名称为“long ride”的单个值的状态了。
class ImplementMeFunction extends KeyedProcessFunction[Long, TaxiRide, TaxiRide] {
var rideState: ValueState[TaxiRide] =_
override def open(parameters: Configuration): Unit = {
rideState=getRuntimeContext.getState(
new ValueStateDescriptor[TaxiRide]("long ride",classOf[TaxiRide])
)
}
在介绍完了所需要的方法接口后,我们注意到这两个输入流是彼此竞争的,也就是某一个rideID的费用或者行驶记录有可能先到也有可能后到,那么可以对每一个键(rideID)定义两个状态,用来存储先来的费用或者行驶记录,当一条行驶数据到了检查该数据对应的费用状态,如果状态不为空,那么这个记录就能够对应进行输出,如果为空,那么我们将行驶数据的状态记录到状态里,等待费用记录的到来,反之亦然。这样就能够完成这样一个关联过程。
我们可以构思出以下方法来进行费用与行驶记录的匹配:

对应为编码:
import com.ververica.flinktraining.exercises.datastream_java.datatypes.{
TaxiFare, TaxiRide}
import com.ververica.flinktraining.exercises.datastream_java.sources.{
TaxiFareSource, TaxiRideSource}
import com.ververica.flinktraining.exercises.datastream_java.utils.ExerciseBase
import com.ververica.flinktraining.exercises.datastream_java.utils.ExerciseBase._
import org.apache.flink.api.common.state.{
ValueState, ValueStateDescriptor}
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.co.RichCoFlatMapFunction
import org.apache.flink.streaming.api.scala.{
StreamExecutionEnvironment, _}
import org.apache.flink.util.Collector
/**
* Scala reference implementation for the "Stateful Enrichment" exercise of the Flink training
* (http://training.ververica.com).
*
* The goal for this exercise is to enrich TaxiRides with fare information.
*
* Parameters:
* -rides path-to-input-file
* -fares path-to-input-file
*
*/
object RidesAndFaresSolution {
def main(args: Array[String]) {
// parse parameters
val params = ParameterTool.fromArgs(args)
val ridesFile = params.get("rides", ExerciseBase.pathToRideData)
val faresFile = params.get("fares", ExerciseBase.pathToFareData)
val delay = 60; // at most 60 seconds of delay
val servingSpeedFactor = 1800 // 30 minutes worth of events are served every second
// set up streaming execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(ExerciseBase.parallelism)
val rides = env
.addSource(rideSourceOrTest(new TaxiRideSource(ridesFile, delay, servingSpeedFactor)))
.filter {
ride => ride.isStart }
.keyBy("rideId")
val fares = env
.addSource(fareSourceOrTest(new TaxiFareSource(faresFile, delay, servingSpeedFactor)))
.keyBy("rideId")
val processed = rides
.connect(fares)
.flatMap(new EnrichmentFunction)
printOrTest(processed)
env.execute("Join Rides with Fares (scala RichCoFlatMap)")
}
class EnrichmentFunction extends RichCoFlatMapFunction[TaxiRide, TaxiFare, (TaxiRide, TaxiFare)] {
// keyed, managed state
// lazy val rideState: ValueState[TaxiRide] = getRuntimeContext.getState(
// new ValueStateDescriptor[TaxiRide]("saved ride", classOf[TaxiRide]))
// lazy val fareState: ValueState[TaxiFare] = getRuntimeContext.getState(
// new ValueStateDescriptor[TaxiFare]("saved fare", classOf[TaxiFare]))
var rideState: ValueState[TaxiRide] = _
var fareState: ValueState[TaxiFare] = _
override def flatMap1(ride: TaxiRide, out: Collector[(TaxiRide, TaxiFare)]): Unit = {
val fare = fareState.value
if (fare != null) {
fareState.clear()
out.collect((ride, fare))
}
else {
rideState.update(ride)
}
}
override def flatMap2(fare: TaxiFare, out: Collector[(TaxiRide, TaxiFare)]): Unit = {
val ride = rideState.value
if (ride != null) {
rideState.clear()
out.collect((ride, fare))
}
else {
fareState.update(fare)
}
}
//使用lazy和open是一样的
override def open(parameters: Configuration): Unit = {
rideState = getRuntimeContext.getState(
new ValueStateDescriptor[TaxiRide]("saved ride", classOf[TaxiRide]))
fareState=getRuntimeContext.getState(
new ValueStateDescriptor[TaxiFare]("saved fare", classOf[TaxiFare]))
}
}
}
通过上面的例子,我们通过对每一个键使用两个单值状态完成了一个费用和行驶数据匹配的操作,这里对状态没有做过多的处理,状态通过MemoryStateBackend以Java对象的形式存储在堆中,实际上还可以通过FsStateBackend、RocksDBStateBackend将状态快照写入到配置的文件目录中,或者RocksDB数据库中来支持非常大的状态。
还有一个问题,我们这里模拟了一个理想的情况,那就是费用和行驶数据一定是一一匹配的,实际上每当缺少一个事件时,同一事件的另一个事件rideId将永远保持状态。我们可以想见需要对状态做过期处理或者转存处理。
5.计时器(过期状态的处理)
在此应用情景中使用RichCoFlatMap的问题是,在实际系统中,我们必须期望某些记录会丢失或损坏。这意味着随着时间的流逝,我们将积累越来越多的不匹配记录TaxiRide和TaxiFare等待与永远不会到达的事件数据匹配的记录。最终,我们的匹配工作将耗尽内存。
这里介绍Flink另外一个可自定义算子KeyedProcessFunction(),在连接流里对应KeyedCoProcessFunction()。它和RichFlatMapFunction()类似地继承了AbstractRichFunction(),也就是说它也有open(),getRuntimeContex()等方法来对状态进行使用。同时它多了一个onTimer()方法,用于实现计时器函数,也就是说可以通过上下文中的timeService()来注册定时器,并且在所定的时间后调用onTimer()中的方法。与flatMap类似提供了processElement1和processElement2来完成flatMap1和flatMap 2的功能。
@PublicEvolving
public abstract class KeyedCoProcessFunction<K, IN1, IN2, OUT> extends AbstractRichFunction {
private static final long serialVersionUID = 1L;
public KeyedCoProcessFunction() {
}
public abstract void processElement1(IN1 var1, KeyedCoProcessFunction<K, IN1, IN2, OUT>.Context var2, Collector<OUT> var3) throws Exception;
public abstract void processElement2(IN2 var1, KeyedCoProcessFunction<K, IN1, IN2, OUT>.Context var2, Collector<OUT> var3) throws Exception;
public void onTimer(long timestamp, KeyedCoProcessFunction<K, IN1, IN2, OUT>.OnTimerContext ctx, Collector<OUT> out) throws Exception {
}
public abstract class OnTimerContext extends KeyedCoProcessFunction<K, IN1, IN2, OUT>.Context {
public OnTimerContext() {
super();
}
public abstract TimeDomain timeDomain();
public abstract K getCurrentKey();
}
public abstract class Context {
public Context() {
}
public abstract Long timestamp();
public abstract TimerService timerService();
public abstract <X> void output(OutputTag<X> var1, X var2);
public abstract K getCurrentKey();
}
}
那么为了完成过期状态地清理,我们可以想到,需要在创建状态的时候注册定时器,如果到了设定的时间,触发计时器回调函数,这个状态还没有被清除,也就是说没能完成匹配,那么就需要对这个状态进行侧面输出并且清除:


import com.ververica.flinktraining.exercises.datastream_java.datatypes.{
TaxiFare, TaxiRide}
import com.ververica.flinktraining.exercises.datastream_java.sources.{
TaxiFareSource, TaxiRideSource}
import com.ververica.flinktraining.exercises.datastream_java.utils.ExerciseBase
import com.ververica.flinktraining.exercises.datastream_java.utils.ExerciseBase._
import org.apache.flink.api.common.state.{
ValueState, ValueStateDescriptor}
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.co.KeyedCoProcessFunction
import org.apache.flink.streaming.api.scala.{
StreamExecutionEnvironment, _}
import org.apache.flink.util.Collector
/**
* Scala reference implementation for the "Expiring State" exercise of the Flink training
* (http://training.ververica.com).
*
* The goal for this exercise is to enrich TaxiRides with fare information.
*
* Parameters:
* -rides path-to-input-file
* -fares path-to-input-file
*
*/
object ExpiringStateSolution {
val unmatchedRides = new OutputTag[TaxiRide]("unmatchedRides") {
}
val unmatchedFares = new OutputTag[TaxiFare]("unmatchedFares") {
}
def main(args: Array[String]) {
// parse parameters
val params = ParameterTool.fromArgs(args)
val ridesFile = params.get("rides", ExerciseBase.pathToRideData)
val faresFile = params.get("fares", ExerciseBase.pathToFareData)
val maxDelay = 60 // events are out of order by max 60 seconds
val servingSpeedFactor = 600 // 10 minutes worth of events are served every second
// set up streaming execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(ExerciseBase.parallelism)
val rides = env
.addSource(rideSourceOrTest(new TaxiRideSource(ridesFile, maxDelay, servingSpeedFactor)))
.filter {
ride => ride.isStart && (ride.rideId % 1000 != 0) }
.keyBy(_.rideId)
val fares = env
.addSource(fareSourceOrTest(new TaxiFareSource(faresFile, maxDelay, servingSpeedFactor)))
.keyBy(_.rideId)
val processed = rides.connect(fares).process(new EnrichmentFunction)
printOrTest(processed.getSideOutput[TaxiFare](unmatchedFares))
env.execute("ExpiringState (scala)")
}
class EnrichmentFunction extends KeyedCoProcessFunction[Long, TaxiRide, TaxiFare, (TaxiRide, TaxiFare)] {
// keyed, managed state
lazy val rideState: ValueState[TaxiRide] = getRuntimeContext.getState(
new ValueStateDescriptor[TaxiRide]("saved ride", classOf[TaxiRide]))
lazy val fareState: ValueState[TaxiFare] = getRuntimeContext.getState(
new ValueStateDescriptor[TaxiFare]("saved fare", classOf[TaxiFare]))
override def processElement1(ride: TaxiRide,
context: KeyedCoProcessFunction[Long, TaxiRide, TaxiFare, (TaxiRide, TaxiFare)]#Context,
out: Collector[(TaxiRide, TaxiFare)]): Unit = {
val fare = fareState.value
if (fare != null) {
fareState.clear()
context.timerService.deleteEventTimeTimer(ride.getEventTime)
out.collect((ride, fare))
}
else {
rideState.update(ride)
// as soon as the watermark arrives, we can stop waiting for the corresponding fare
context.timerService.registerEventTimeTimer(ride.getEventTime)
}
}
override def processElement2(fare: TaxiFare,
context: KeyedCoProcessFunction[Long, TaxiRide, TaxiFare, (TaxiRide, TaxiFare)]#Context,
out: Collector[(TaxiRide, TaxiFare)]): Unit = {
val ride = rideState.value
if (ride != null) {
rideState.clear()
context.timerService.deleteEventTimeTimer(ride.getEventTime)
out.collect((ride, fare))
}
else {
fareState.update(fare)
// as soon as the watermark arrives, we can stop waiting for the corresponding ride
context.timerService.registerEventTimeTimer(fare.getEventTime)
}
}
override def onTimer(timestamp: Long,
ctx: KeyedCoProcessFunction[Long, TaxiRide, TaxiFare, (TaxiRide, TaxiFare)]#OnTimerContext,
out: Collector[(TaxiRide, TaxiFare)]): Unit = {
if (fareState.value != null) {
ctx.output(unmatchedFares, fareState.value)
fareState.clear()
}
if (rideState.value != null) {
ctx.output(unmatchedRides, rideState.value)
rideState.clear()
}
}
}
}