[矩阵分解]基于隐式反馈的矩阵分解ALS(spark实现)
目录
一、ALS模型
1、模型定义
2、参数求解
3、推荐计算
二、pyspark实现ALS模型
三、矩阵分解模型与协同过滤模型比较
一、ALS模型
1、模型定义
用户u对商品i的偏好:
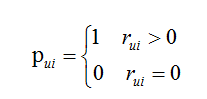
其中,在隐式反馈中无法获取用户对商品明确的评分,在视频推荐场景中rui表示为视频观看的时长比例,在商品推荐场景中rui表示为对商品点击次数等。
用户的隐式反馈属于One-class问题,把预测用户行为看成一个二分类问题,猜用户会不会做某事,实际上收集到的数据只有明确一类:用户干了某事,而用户明确不干某事的数据却没有明确表达。那些没有反馈的缺失值,就是取值为0的评分非常多,导致正负类别样本非常不均衡,严重倾斜,应对这个问题的做法就是负样本采样:挑选部分缺失值作为负类别样本。
负样本采样方法:
- 随机均匀采样和正类别一样多。
- 按照物品的热门程度采样(在实践中经过了检验)。该采样方法的思想是,一个越热门的物品,用户越可能知道它的存在,这种情况下用户还没对它有反馈就表明,这很可能是真正的负样本。
用户u对商品i偏好度pui的可信度:
![]()
用户隐式反馈的可信度,正比于用户反馈的次数,反馈次数越多,越确信用户对物品的喜欢。
损失函数定义为:
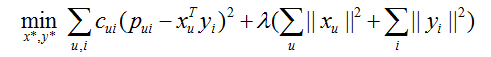
损失函数包含误差平方和(偏差)和正则项(方差)两部分。
2、参数求解
ALS(alternating-least-squares):如果用户特征矩阵或者商品特征矩阵固定,损失函数为二次函数,存在全局最优值,所以交替地计算用户和商品特征矩阵,每一步保证损失函数达到最优值。(利用最小二乘法交替计算用户和商品特征矩阵)
计算用户特征矩阵:
![]()
计算商品特征矩阵:

迭代步数默认值为10.
3、推荐计算
在得到分解后的矩阵后,每个用户得到了隐因子向量,用于代表他的兴趣,同时每个物品也得到一个隐因子向量,代表它的语义或主题。这两者是一一对应的,用户的兴趣体现在物品的语义维度上。
用户和物品的隐因子向量两两相乘,计算点积就可以得到所有的推荐结果了,但是对于用户数量和物品数量都特别大时,计算复杂度很高。FaceBook提出了两种方法,计算用户的推荐结果。
第一种,利用专门设计的数据结构(ball tree)存储所有物品的隐因子向量,从而实现通过一个用户向量可以返回最相似的k个物品。开源有Faiss(FaceBook)、NMSLIB等。
第二种,将物品的隐因子向量先做聚类,海量的物品会减少为少量的聚类,然后再逐一计算用户和每个聚类中心的推荐分数,给用户推荐物品就变成给用户推荐物品聚类。得到给用户推荐的聚类后,再从每个聚类中挑选少许几个物品作为最终推荐结果。这样做的好处除了大大减少计算量之外,还可以控制推荐结果的多样性,因为可以控制在每个类别中选择的物品数量。
二、pyspark实现ALS模型
class pyspark.ml.recommendation.ALS(self, rank=10, maxIter=10, regParam=0.1, numUserBlocks=10, numItemBlocks=10, implicitPrefs=false, alpha=1.0, userCol="user", itemCol="item", seed=None, ratingCol="rating", nonnegative=false, checkpointInterval=10, intermediateStorageLevel="MEMORY_AND_DISK", finalStorageLevel="MEMORY_AND_DISK", coldStartStrategy="nan")
Rank:模型中隐藏因子数目
maxIter:算法迭代次数
regParam:正则项权重
Alpha:用户对物品偏好的可信度
implicitPrefs:数据集是隐式反馈还是显示反馈
Nonnegative:商品推荐分数是否是非负的
利用网格搜索,遍历最优参数:
(train,test) = sampleData.randomSplit([0.80, 0.20])
evalData = []
for ranks in [10,20,30,50,60]:
for maxIters in [20]:
for regParams in [0.001,0.01,0.1,1]:
for alphas in [0.1,1,10,20,30]:
als = ALS(rank = ranks, maxIter = maxIters, regParam=regParams, alpha = alphas,\
implicitPrefs = True,userCol = 'customers_id', itemCol = 'categories_id', ratingCol = 'pronum',nonnegative=True)
model = als.fit(train)
testPredic = model.transform(test).fillna(0)
testPredicData = testPredic.select('customers_id','categories_id','pronum','label',testPredic.prediction.cast("Double"))
evaluator = BinaryClassificationEvaluator(rawPredictionCol='prediction',labelCol='label')
auc = evaluator.evaluate(testPredicData,{evaluator.metricName: 'areaUnderROC'})
evalData.append([ranks,maxIters,regParams,alphas,auc])
print(ranks,maxIters,regParams,alphas,auc)
三、矩阵分解模型与协同过滤模型比较
|
|
矩阵分解 |
协同过滤 |
| 理论基础 |
是一种学习方法,将用户商品的稀疏矩阵映射到低维空间(有效信息提取和无效信息摒弃),模型精度更高 |
是一种基于统计的方法,并没有学习的过程 |
| 实时推荐 |
用户有新的行为,推荐列表不能实时更新 |
用户有新的行为,会导致推荐列表的改变 |
| 冷启动 |
推荐结果是用户隐因子和物品隐因子的乘积,无法解决用户或物品的冷启动问题 |
userCF解决物品冷启动问题 itemCF解决用户冷启动问题 |
| 推荐解释 |
无法解释,计算出的隐因子很难用自然语言描述 |
ItemCF可以利用用户的历史行为解释推荐结果 |
参考文献:
《Collaborative filtering for implicit feedback datasets》
https://time.geekbang.org/column/article/5033
https://spark.apache.org/docs/preview/ml-collaborative-filtering.html
https://jaceklaskowski.gitbooks.io/mastering-apache-spark/content/spark-mllib/spark-mllib-alternating-least-squares.html
https://dataplatform.cloud.ibm.com/exchange/public/entry/view/99b857815e69353c04d95daefb3b91fa