【C语言->数据结构与算法】->哈夫曼压缩&解压缩->终局->如何做一个自己独有的压缩软件
哈夫曼压缩&解压缩
-
- Ⅰ 前言
- Ⅱ 需求分析&主函数带参的应用
-
- A. 需求分析
- B. 压缩部分
- B. 解压缩部分
- Ⅲ 哈夫曼压缩
-
- A. 代码分析
- B. 从文件中读取内容生成频度表
- C. 将编码写入文件
- D. 哈夫曼压缩完整代码
- E. 运行结果
- Ⅳ 哈夫曼解压缩
-
- A. 代码分析
- B. 从压缩文件中读取频度表
- C. 解码
- D. 哈夫曼解压缩完整代码
- E. 运行结果
- Ⅴ 一些补充
Ⅰ 前言
在之前的文章里,我先介绍了如何构造哈夫曼树及实现哈夫曼编码,并用程序完成了这个部分。
【C语言->数据结构与算法】->树与二叉树概念&哈夫曼树的构造
【C语言->数据结构与算法】->哈夫曼压缩&解压缩->第一阶段->哈夫曼编码&解码的实现
这个程序的框架已经构架完成,可以完成最终的部分了。在第一阶段中,我们完成了对任意字符串的编码和解码,现在要做的是,如何把这个字符串变成文件的内容。
我先把第一阶段的函数部分代码放在这里。
#include 我们现在需要思考的是,在对文件进行编码压缩解压缩的过程中,和对字符串进行这个操作的过程中,哪些部分是共通的?哪些部分是需要改变的?
Ⅱ 需求分析&主函数带参的应用
A. 需求分析
在用户要压缩文件时,我们需要用户输入一个TA需要压缩的文件名,要生成的文件名可输入可不输入。
在用户要解压缩文件时,我们需要用户输入TA需要解压缩的文件,并输入要生成的文件名,因为我们不知道用户的文件到底是什么类型的,所以需要用户自己输入要生成的文件名包括扩展名,以此来生成他需要的文件类型。
根据这两个需求,我们如何让用户做到这一点呢?答案便是主函数带参。
若对这个知识点有疑问的同学可以看我下面这篇文章,可以大概了解这里的内容。
【C语言->数据结构与算法】->关于主函数带参
B. 压缩部分
如果用户没有输入要生成的文件名,按照其他的压缩软件的规则,会生成一个和源文件名字相同但是扩展名相同的文件。
比如我要压缩下面这个文件
![]()
则会弹出以下窗口,如果我没有改变文件名,默认名字就是源文件名+压缩软件独有的扩展名。

所以我们就需要一个自己的扩展名。我用宏定义了一个我的扩展名
#define TYZ_COP_EXTENSION ".TyzHuf"
在用户输入一个需要压缩的文件名后,我们需要先检测这个文件是否存在,由于这个函数可能会比较常用,所以我把它放在我常用的头文件对应的.c文件tyz.c中
boolean isFileExist(const char *filename) {
FILE *fp;
fp = fopen(filename, "r");
if (NULL == fp) {
return FALSE;
}
fclose(fp);
return TRUE;
}
如果源文件存在,接下来就是对要生成的文件进行操作。若用户没有输入要生成的文件,则我们需要一个源文件名+我们自己的扩展名的文件名,若用户输入了一个要生成的文件名,则我们需要将用户输入的文件名的扩展名改为自己的扩展名。
函数如下,我仍将其放在tyz.c中
char *creatFilename(const char *sourceFilename, const char *extensionName, char *targetFilename) {
int index;
int dotIndex = -1;
char filename[200];
if ('.' != extensionName[0]) {
strcpy(filename, ".");
strcat(filename, extensionName);
} else {
strcpy(filename, extensionName);
}
for (index = 0; sourceFilename[index]; index++) {
if (sourceFilename[index] == '.') {
dotIndex = index;
}
}
if (-1 == dotIndex) {
strcpy(targetFilename, sourceFilename);
strcat(targetFilename, extensionName);
return targetFilename;
}
strcpy(targetFilename, sourceFilename);
targetFilename[dotIndex] = 0;
strcat(targetFilename, extensionName);
return targetFilename;
}
由于一个文件中可以有很多点,所以我们只取第一个点,将后面的内容变为扩展名。
所以压缩部分的主函数代码如下
int main(int argc, char const *argv[]) {
char sourceFilename[200];
char targetFilename[200];
if (argc != 2 && argc != 3) {
printf("用法:hufCompress 源文件 目标文件\n");
return -1;
}
strcpy(sourceFilename, argv[1]);
if (!isFileExist(sourceFilename)) {
printf("source file[%s] did not exist\n", sourceFilename);
return -2;
}
if (argc == 3) {
strcpy(targetFilename, argv[2]);
} else {
creatFilename(sourceFilename, TYZ_COP_EXTENSION, targetFilename);
}
compress(sourceFilename, targetFilename);
return 0;
}
通过主函数的参数,我们就可以判断用户有没有输入要生成的文件名。如果格式不符合要求,我们会给用户一个提示。

接下来是解压缩部分。
B. 解压缩部分
如我们分析的,我们只需要判断用户输入的命令参数个数即可。
int main(int argc, char const *argv[]) {
char sourceFilename[200];
char targetFilename[200];
if (argc != 3) {
printf("用法:hufDecompress 源文件 还原文件\n");
return -1;
}
strcpy(sourceFilename, argv[1]);
if (!isFileExist(sourceFilename)) {
printf("source file[%s] did not exist\n", sourceFilename);
return -2;
}
strcpy(targetFilename, argv[2]);
decompress(sourceFilename, targetFilename);
return 0;
}
Ⅲ 哈夫曼压缩
A. 代码分析
要压缩一个文件,我们需要改变的只是从键盘输入读取字符串,变成从文件中读取字符。文件的本质还是由数据构成的,所以我们要做的就是将数据从文件中读出来,然后和字符串操作一样,做同样的事,根据其频度得到频度表,然后构建哈夫曼树,最后生成编码。
所以和第一阶段的代码对比,我们需要改变的只有两个部分,一个是从用户输入的字符串统计其频度,改成从文件中读取数据并统计其频度;一个是编码,这个阶段我们需要用位运算,将编码写入新生成的压缩文件中。
所以接下来,我们就来完成这两个部分。
B. 从文件中读取内容生成频度表
这一部分没有什么复杂的地方,对于文件操作有疑问的同学可以看我下面这篇文章。
【C语言基础】->文件操作详解->一篇文章读懂关于文件的庞杂函数使用
ATTRIBUTE *initAttributeList(u32 *ascii, u16 *characterCount, const char *sourceFilename) {
u8 ch;
u32 i;
u32 index = 0;
u16 count = 0;
FILE *fpIn;
ATTRIBUTE *attributeList;
fpIn = fopen(sourceFilename, "r");
ch = fgetc(fpIn);
while (!feof(fpIn)) {
ascii[ch]++;
ch = fgetc(fpIn);
}
for (i = 0; i < 256; i++) {
count += (ascii[i] != 0);
}
*characterCount = count;
attributeList = (ATTRIBUTE *) calloc(sizeof(ATTRIBUTE), count);
for (i = 0; i < 256; i++) {
if (ascii[i] != 0) {
attributeList[index].character = (u8) i;
attributeList[index++].frequency = ascii[i];
}
}
fclose(fpIn);
return attributeList;
}
通过fgetc()函数从文件中一个字节一个字节读取,生成频度表。需要注意的是while循环
ch = fgetc(fpIn);
while (!feof(fpIn)) {
ascii[ch]++;
ch = fgetc(fpIn);
}
我在文件操作的博文里讲过,feof()函数是一个动作标识函数,不是状态标识符,所以要注意要把读取操作放在循环的最后。
C. 将编码写入文件
我通过一个文件来分析这里的内容。我打开一个bmp文件,比如下面这个
我用二进制编辑器将这个文件打开,会得到这样的内容
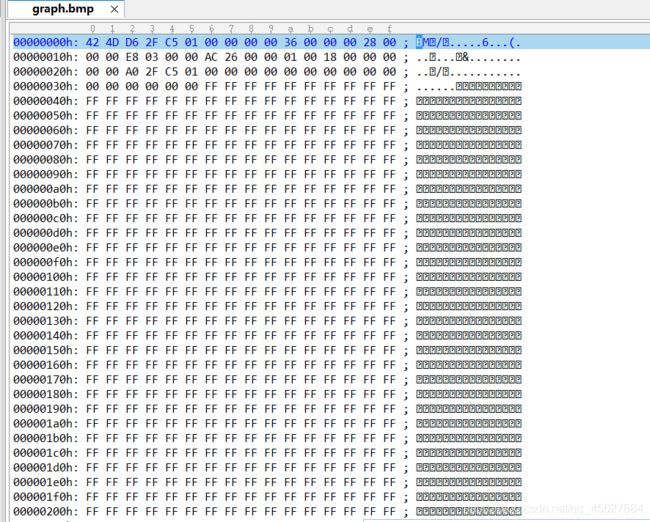
这就是这个bmp文件在计算机中的内容,其中大量FF FF FF是白色的意思。可以看到文件的头部有这样的内容

首三位是BMP,也就是这个文件的拓展名,这是识别一个文件的方式,后面的数据标记了这个文件的各种数据,用以识别。
所以我们压缩文件的时候,也要参照这种方式。首先是识别码,然后是文件的字符种类数量,然后是哈夫曼编码的总位数。
如果要进行解码,在第一阶段做的,我们是根据哈夫曼树进行解码的,所以为了得到哈夫曼树,我们必须得到频度表,因此我们压缩时,也需要将频度表写入文件中。
所以这四个部分,识别码,文件的字符数量,哈夫曼编码的位数,以及频度表,就是我们要先写入文件中的内容。
typedef struct FILE_HEAD {
u8 flag[3];
u16 characterCount;
u32 bitCount;
u8 unused[7];
}FILE_HEAD;
这个结构体就是要写入文件头部的内容,包括识别码,文件的字符数量和哈夫曼编码的位数,最后一个u8 unused[7];,是为了将这个结构体凑成2的整数次方,这样存储进去就是完整的,方便查找后面的内容。
现在我们看写入部分。
首先是得到哈夫曼编码的总位数。
u32 getBitCount(u16 characterCount, HUFMAN_TREE_NODE *hufmanTreeNode) {
u16 i;
u32 sum = 0;
for (i = 0; i < characterCount; i++) {
sum += hufmanTreeNode[i].attribute.frequency * strlen(hufmanTreeNode[i].hufmanCode);
}
return sum;
}
然后是编码,也就是将哈夫曼编码写入压缩的文件中的部分。
void coding(const char *sourceFilename, const char *targetFilename, HUFMAN_TREE_NODE *hufmanTreeNode,
u32 *orientate, u16 characterCount, ATTRIBUTE *attributeList) {
u32 ch;
u8 *hufCode;
u32 temp;
u32 bitIndex = 0;
u32 codeIndex;
FILE_HEAD fileHead = {
0};
FILE *fpIn;
FILE *fpOut;
fpIn = fopen(sourceFilename, "r");
fpOut = fopen(targetFilename, "wb");
fileHead.flag[0] = 'T';
fileHead.flag[1] = 'Y';
fileHead.flag[2] = 'Z';
fileHead.characterCount = characterCount;
fileHead.bitCount = getBitCount(characterCount, hufmanTreeNode);
printf("characterCount = %d\nbitCount = %d\n", characterCount, fileHead.bitCount);
fwrite(&fileHead, sizeof(FILE_HEAD), 1, fpOut);
fwrite(attributeList, sizeof(ATTRIBUTE), characterCount, fpOut);
ch = fgetc(fpIn);
while (!feof(fpIn)) {
hufCode = hufmanTreeNode[orientate[ch]].hufmanCode;
for (codeIndex = 0; hufCode[codeIndex]; codeIndex++) {
hufCode[codeIndex] == '1' ? SET(temp, bitIndex)
: CLEAR(temp, bitIndex);
if (++bitIndex >= 8) {
fputc(temp, fpOut);
bitIndex = 0;
temp = 0;
}
}
ch = fgetc(fpIn);
}
if (bitIndex > 0) {
fputc(temp, fpOut);
}
fclose(fpIn);
fclose(fpOut);
}
通过hufCode,暂时存储得到的ch所对应的哈夫曼编码,然后遍历这个编码,如果是0就通过位运算的清位,将temp的对应位变成0,就这样通过位运算的清位和置位,将temp的一个字节写完,然后将其写入文件中。
这里有一个地方我犯了错,看了很久才发现这个漏洞。
if (bitIndex > 0) {
fputc(temp, fpOut);
}
最后一步,其他的八个位的信息都写入了,但是如果哈夫曼编码的总位数不是八的倍数,就会有单独几位多出来,这个也是要写进文件的,但是这时候temp的大于bitIndex的位上是上一个字节写入的信息,由于新写入的最后几位不足八位,所以没有完全覆盖掉,这时候就会有问题。
所以,我在上一步,每次写入一个文件的信息后,多加了一步,将temp归0,这样就可以避免这种错误的发生了。
if (++bitIndex >= 8) {
fputc(temp, fpOut);
bitIndex = 0;
temp = 0;
}
这就是编码的内容。由于这一阶段,我们的主函数做了改变,所以我们还需要一个函数,来充当第一阶段主函数的作用。
void compress(const char *sourceFilename, const char *targetFilename) {
u8 code[256];
u16 characterCount;
u32 ascii[256] = {
0};
u32 orientate[256] = {
0};
ATTRIBUTE *attributeList = NULL;
HUFMAN_TREE_NODE *hufmanTreeNode = NULL;
attributeList = initAttributeList(ascii, &characterCount, sourceFilename);
//printf("频度表如下:\n");
//showAttributeList(characterCount, attributeList);
hufmanTreeNode = initHufmanTreeNode(characterCount, orientate, attributeList);
hufmanTreeNode = initHufmanTreeNode(characterCount, orientate, attributeList);
creatHufmanTree(characterCount, hufmanTreeNode);
creatHufmanCode(code, 0, 2*characterCount-2, hufmanTreeNode);
//printf("编码如下:\n");
//showHufmanTreeNode(2*characterCount-1, hufmanTreeNode);
coding(sourceFilename, targetFilename, hufmanTreeNode, orientate, characterCount, attributeList);
destoryAttributeList(attributeList);
destoryHufmanTreeNode(2*characterCount-2, hufmanTreeNode);
}
D. 哈夫曼压缩完整代码
首先是tyz.h的内容
#ifndef _TYZ_H_
#define _TYZ_H_
#define TRUE 1
#define FALSE 0
#define NOT_FOUND -1
#define SET(value, index) (value |= 1 << (index ^ 7))
#define CLEAR(value, index) (value &= ~(1 << (index ^ 7)))
#define GET(value, index) (((value) & (1 << ((index) ^ 7))) != 0)
typedef unsigned char boolean;
typedef unsigned int u32;
typedef unsigned short u16;
typedef boolean u8;
int skipBlank(const char *str);
boolean isRealStart(int ch);
boolean isFileExist(const char *filename);
char *creatFilename(const char *sourceFilename, const char *extensionName, char *targetFilename);
#endif
接着是tyz.c的部分
#include 接着是压缩部分的头文件hufCompress.h的内容
#ifndef _TYZ_HUF_COMPRESS_H_
#define _TYZ_HUF_COMPRESS_H_
#include "tyz.h"
typedef struct ATTRIBUTE {
u8 character;
u32 frequency;
}ATTRIBUTE;
typedef struct HUFMAN_TREE_NODE {
boolean visited;
u8 *hufmanCode;
u32 leftChild;
u32 rightChild;
ATTRIBUTE attribute;
}HUFMAN_TREE_NODE;
typedef struct FILE_HEAD {
u8 flag[3];
u16 characterCount;
u32 bitCount;
u8 unused[7];
}FILE_HEAD;
void compress(const char *sourceFilename, const char *targetFilename);
ATTRIBUTE *initAttributeList(u32 *ascii, u16 *characterCount, const char *sourceFilename);
void destoryAttributeList(ATTRIBUTE *attributeList);
void showAttributeList(u16 characterCount, ATTRIBUTE *attributeList);
HUFMAN_TREE_NODE *initHufmanTreeNode(u16 characterCount, u32 *orientate, ATTRIBUTE *attributeList);
void destoryHufmanTreeNode(u32 count, HUFMAN_TREE_NODE *hufmanTreeNode);
void showHufmanTreeNode(u32 count, HUFMAN_TREE_NODE *hufmanTreeNode);
void creatHufmanTree(u16 characterCount, HUFMAN_TREE_NODE *hufmanTreeNode);
u32 searchMinimumNode(u32 count, HUFMAN_TREE_NODE *hufmanTreeNode);
void creatHufmanCode(u8 *code, u32 index, u32 root, HUFMAN_TREE_NODE *hufmanTreeNode);
void coding(const char *sourceFilename, const char *targetFilename, HUFMAN_TREE_NODE *hufmanTreeNode,
u32 *orientate, u16 characterCount, ATTRIBUTE *attributeList);
u32 getBitCount(u16 characterCount, HUFMAN_TREE_NODE *hufmanTreeNode);
#endif
最后是主体部分,hufCompress.c
#pragma pack(push)
#pragma pack(1)
#include E. 运行结果

![]()
graph.TyzHuf就是新生成的压缩文件。
其部分内容如下
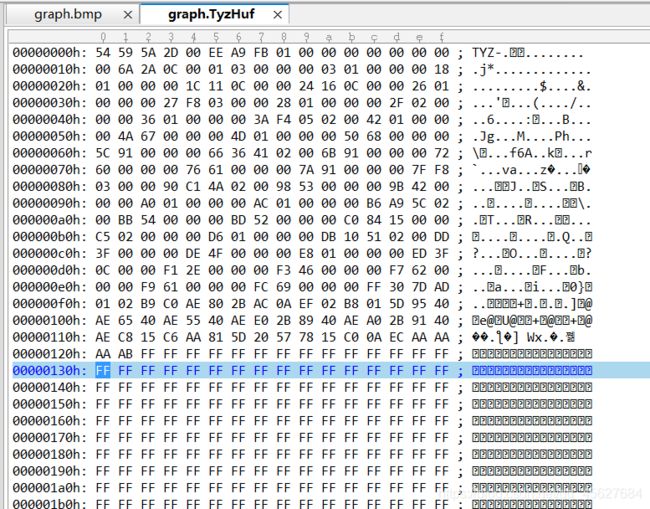
可以清楚看到头部内容就是TYZ三个标识符。
Ⅳ 哈夫曼解压缩
A. 代码分析
回忆第一阶段完成的部分,我们需要根据哈夫曼树才能完成解码,因此第一步,我们仍是得到频度表,只不过是从我们压缩进去的文件中得到频度表。压缩的时候我们已经将必要的信息写入文件了。
接下来其他部分是和第一阶段保持不变的,根据频度表我们可以生成哈夫曼树,然后就可以根据哈夫曼树来进行对压缩文件中的数据进行解码了。
B. 从压缩文件中读取频度表
ATTRIBUTE *initAttributeList(u32 *bitCount, u16 *characterCount, const char *sourceFilename) {
FILE *fpIn;
ATTRIBUTE *attributeList = NULL;
FILE_HEAD fileHead = {
0};
fpIn = fopen(sourceFilename, "r");
fread(&fileHead, sizeof(FILE_HEAD), 1, fpIn);
if (fileHead.flag[0] != 'T'
|| fileHead.flag[1] != 'Y'
|| fileHead.flag[2] != 'Z') {
printf("文件无法识别^-^\n");
return NULL;
}
*characterCount = fileHead.characterCount;
*bitCount = fileHead.bitCount;
attributeList = (ATTRIBUTE *) calloc(sizeof(ATTRIBUTE), *characterCount);
fread(attributeList, sizeof(ATTRIBUTE), *characterCount, fpIn);
return attributeList;
}
这一部分也是很简单的。在开始的时候我们需要判断标识码,如果一个文件开头不是TYZ,那么说明这不是我们的压缩文件,无法解码。
读取了文件头的结构体,我们就可以知道哈夫曼编码的总位数bitCount和字符类型数characterCount。
接下来就是读取我们存放的频度表了。之后就是根据这个频度表再生成哈夫曼树,和第一阶段的代码是相同的。
C. 解码
void decoding(const char *sourceFilename, const char *targetFilename,
HUFMAN_TREE_NODE *hufmanTreeNode, u16 characterCount, u32 bitCount) {
u32 ch;
u32 bitIndex = 0;
u32 pointIndex = 0;
u32 root = 2 * characterCount - 2;
FILE *fpIn;
FILE *fpOut;
fpIn = fopen(sourceFilename, "rb");
fpOut = fopen(targetFilename, "wb");
printf("characterCount = %d\nbitCount = %d\n", characterCount, bitCount);
fseek(fpIn, sizeof(FILE_HEAD) + sizeof(ATTRIBUTE) * characterCount, SEEK_SET);
ch = fgetc(fpIn);
while (pointIndex <= bitCount) {
if (-1 == hufmanTreeNode[root].leftChild) {
fputc((int) hufmanTreeNode[root].attribute.character, fpOut);
root = 2 * characterCount - 2;
continue;
}
root = GET(ch, bitIndex) == 0
? hufmanTreeNode[root].leftChild
: hufmanTreeNode[root].rightChild;
pointIndex++;
if (++bitIndex >= 8) {
ch = fgetc(fpIn);
bitIndex = 0;
}
}
fclose(fpIn);
fclose(fpOut);
}
这个过程其实和第一阶段的解码是差不多的,只是多了几步文件的操作。
通过位运算的取位,我们得到从压缩文件中读取的信息,这样就完成了解码。
D. 哈夫曼解压缩完整代码
tyz.c, tyz.h的内容和哈夫曼压缩的内容一样,我不再赘述。
以下是hufDecompress.h的内容
#ifndef _TYZ_HUF_COMPRESS_H_
#define _TYZ_HUF_COMPRESS_H_
#include "tyz.h"
typedef struct ATTRIBUTE {
u8 character;
u32 frequency;
}ATTRIBUTE;
typedef struct HUFMAN_TREE_NODE {
boolean visited;
u8 *hufmanCode;
u32 leftChild;
u32 rightChild;
ATTRIBUTE attribute;
}HUFMAN_TREE_NODE;
typedef struct FILE_HEAD {
u8 flag[3];
u16 characterCount;
u32 bitCount;
u8 unused[7];
}FILE_HEAD;
void decompress(const char *sourceFilename, const char *targetFilename);
ATTRIBUTE *initAttributeList(u32 *bitCount, u16 *characterCount, const char *sourceFilename);
void destoryAttributeList(ATTRIBUTE *attributeList);
void showAttributeList(u16 characterCount, ATTRIBUTE *attributeList);
HUFMAN_TREE_NODE *initHufmanTreeNode(u16 characterCount, u32 *orientate, ATTRIBUTE *attributeList);
void destoryHufmanTreeNode(u32 count, HUFMAN_TREE_NODE *hufmanTreeNode);
void showHufmanTreeNode(u32 count, HUFMAN_TREE_NODE *hufmanTreeNode);
void creatHufmanTree(u16 characterCount, HUFMAN_TREE_NODE *hufmanTreeNode);
u32 searchMinimumNode(u32 count, HUFMAN_TREE_NODE *hufmanTreeNode);
void creatHufmanCode(u8 *code, u32 index, u32 root, HUFMAN_TREE_NODE *hufmanTreeNode);
void decoding(const char *sourceFilename, const char *targetFilename,
HUFMAN_TREE_NODE *hufmanTreeNode, u16 characterCount, u32 bitCount);
#endif
最后是hufDecompress.c的内容
#pragma pack(push)
#pragma pack(1)
#include E. 运行结果


可以看到生成的gra.bmp和源文件是一模一样大小的,解压缩的十分完美。
Ⅴ 一些补充
有的同学可能会有疑惑,我在程序的开头写的伪指令
#pragma pack(push)
#pragma pack(1)
结尾也有一行。这个是为了阻止内存对齐模式,使得压缩达到更高的效率,如果你对内存对齐模式有疑问,可以看我的下面这篇文章
【C语言基础】->内存对齐模式->为什么我的结构体大小我猜不透
关于这个项目,还牵扯到以下几个知识点:
【C语言基础】->位运算详细解析->位运算的使用
【C语言基础】->文件操作详解->一篇文章读懂关于文件的庞杂函数使用
【C语言基础】->递归调用->八皇后问题
【C语言->数据结构与算法】->树与二叉树概念&哈夫曼树的构造
【C语言->数据结构与算法】->哈夫曼压缩&解压缩->第一阶段->哈夫曼编码&解码的实现
另,感谢朱洪先生的指导。