计算机基本概念之字符编码,字符集
本博文主要介绍计算机基本存储单位单位、字符编码及字符集。
作 者:asushiye
创建日期:2014-11-03
修改日期:2016-01-08
当前版本:1.3v
一、文档控制
文档版本
| 日期 |
作者 |
版本号 |
变更 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
文档名说明
文档主题
本文档用于指导字符集,字符编码,数量法及其他语言的表示方法。
二、数据单位
最小的单元是位(bit),接着是字节(Byte),一个字节=8位,英语表示是1 byte=8 bits 。
机器语言的单位Byte。
1KB=1024 Byte; 1 MB=1024 KB; 1 GB=1024 MB ; 1TB=1024 GB。
2.1、位(bit)
位(bit):是计算机存储数据的最小单位。只存储0或1,0表示断电,1表示通电。通常二进制使用位来表示。
2.2、字节(byte)
由8位二进制来表示一个字节,它是计算机存储数据的基本单位。一个字节可以存放一个字母或数字。二或二个以上字节来存放一个汉字。
2.3、字符(char)
字符由一个字节或多个字节组成,可以表示字母,数字,英文,汉字,外文或特殊符号等等。
从机器存储的字节到显示器的输出字符,或将输入的字符存储到机器中,需要一套编码规则转换,才能进行。编码方式有:ASCII,GB2312, GBK,Unicode等等。
三、进制
3.1、常用数制

下面二进制,八进制,10进制,16进制表示方法:
| Binary(2) |
Octal(8) |
Decimal(10) |
Hex(16) |
| 0000 |
0 |
0 |
0 |
| 0001 |
1 |
1 |
1 |
| 0010 |
2 |
2 |
2 |
| 0011 |
3 |
3 |
3 |
| 0100 |
4 |
4 |
4 |
| 0101 |
5 |
5 |
5 |
| 0110 |
6 |
6 |
6 |
| 0111 |
7 |
7 |
7 |
| 1000 |
10 |
8 |
8 |
| 1001 |
11 |
9 |
9 |
| 1010 |
12 |
10 |
A |
| 1011 |
13 |
11 |
B |
| 1100 |
14 |
12 |
C |
| 1101 |
15 |
13 |
D |
| 1110 |
16 |
14 |
E |
| 1111 |
17 |
15 |
F |
例如:
一个字节可以使用8位的二进制来表示,而只要2个十六进制就可以表示。
10101011(二进制) = AB(十六进制)= 171(十进制)
四、字符编码和字符集
4.1、概念
字符:是指能被用户所理解的信息。字符可以是字母,数字,汉字,韩文信息及特殊符号等等,存储到机器时,按照编码方式转换字节存储。
字符编码:按一个规则约定字符和字节的映射关系,由二进制存储在机器中。比如ASCI码,GB2312码,GBK, Unicode编码等等。
字符集:按同一套字符编码规则指定的所有字符收集到一处,组成字符集。比如ASCI字符集,GB2312字符集。
4.2、编码及字符集
4.2.1、ASCII
ASCII编码是现今最通用的单字节编码系统,使用一个字节来表示字符,最高位为0和其他7位表示一个字符。编码范围是[0-127]。因此总共字符有128个。
ASCII字符集:包含52个大小写英文、10个阿拉伯数字、32符号,以及34个不可见的控制符,共128个。
请下面ASCII码表

52大小写英文:
65~90为26个大写英文字母,97~122为26个小写英文字母
10个阿拉伯数字:
其中第48~57号为0~9十个阿拉伯数字;,其余为一些标点符号、运算符号等
控制符34个:
从0到32及127是控制字符或通讯专用字符,如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BEL(振铃)等;通讯专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等
32个符号:其他32个常用符号。
这些ASCII字符,组成ASCII字符集
4.2.2、GB2312
GB2312编码:兼容ASCII编码。
GB2312字符集是用于汉字编码字符集,有字母,数字,符号,控制符用一个字节存储,汉字使用两个字节存储。
对字节进行判断,如值<=127,则意义等同于ASCII编码;如值>127,则它需要跟其后的另一个字节合并表示一个字符。其理论汉字编码空间为128X256,超过3万个字符。ex7F)是控制符,其余的都是些可见字符。
GB2312字符集:ASCII字符集+7000左右汉字字符。
请看GB2312编码表:

4.2.3、GBK
GBK字符集:GB2312字符集+20000左右汉字字符。
GBK编码:兼容GB2312编码。利用了GB2312编码闲置的编码空间。
GB18030:
GB18030字符集:GBK字符集+若干汉字+若干少数民族字符,为目前国内最新的字符集。
GB18030编码:兼容GBK编码。继续利用GBK编码闲置的编码空间,对于超出编码空间的则采用4个字节表示。
4.2.4、BIG5
BIG5字符集:ASCII字符集+13000左右汉字(繁体)。
BIG编码:兼容ASCII编码。其编码模式类似于GB2312.
4.2.5、Unicode
Unicode字符集编码支持世界上超过650种语言的国际字符集,允许在同一服务器上混合使用不同语言组的不同语言。
它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
它固定使用16bits(两个字节)来表示一个字符,共可以表示65536个字符。
Unicode 标准始终使用十六进制数字.
Unicode 标准的编码字符集的字符编码方案有:
UTF-8, UTF-16,UTF-32等。
UTF-8
UTF-8使用可变长度字节来储存 Unicode字符,例如ASCII字母继续使用1字节储存,重音文字、希腊字母或西里尔字母等使用2字节来储存,而常用的汉字就要使用3字节。辅助平面字符则使用4字节
UTF-16、UTF-32
①UTF-32编码:固定使用4个字节来表示一个字符,存在空间利用效率的问题。
②UTF-16编码:对相对常用的60000余个字符使用两个字节进行编码,其余的(即’补充字符supplementary characters’)使用4字节。
不同编码的字符十六进制值。
实例说明:
| 字符 |
ASCII |
UTF-8 |
UTF-16 |
| me |
6D 65 |
EF BB BF 6D 65 |
FF FE 6D 00 65 00 |
| 我 |
CE D2 |
EF BB BF E6 88 91 |
FF FE 11 62 |
当我们使用软件加载一个文本文件时,如何区分编码方式呢?
最标准的途径是检测文本最开头的几个字节,开头字节 Charset/encoding,如下表:
无任何十六进制:ASCII
EF BB BF :UTF-8
FF FE :UTF-16/UCS-2, little endian
FE FF :UTF-16/UCS-2, big endian
FF FE 00 00: UTF-32/UCS-4, little endian.
00 00 FE FF: UTF-32/UCS-4, big-endian.
4.2.6、Base64
Base好处:用Base64编码不仅比较简短,同时也具有不可读性。常用余网络上的数据传输,简单加密。
原理
转前:s 1 3
先转成ascii:对应115 49 51
2进制: 0111001100110001 00110011
6个一组(4组)011100110011000100110011
然后才有后面的 011100 110011 000100 110011
然后计算机是8位8位的存数 6不够,自动就补两个高位0了
所有有了高位补0
科学计算器输入 00011100 00110011 00000100 00110011
得到28 51 4 51
查对下照表 c z E z
先以“迅雷下载”为例: 很多下载类网站都提供“迅雷下载”的链接,其地址通常是加密的迅雷专用下载地址。
其实迅雷的“专用地址”也是用Base64"加密"的,其过程如下:
一、在地址的前后分别添加AA和ZZ
二、对新的字符串进行Base64编码
总结:每三个8Bit的字节转换为四个6Bit的字节(3*8= 4*6 = 24),然后把6Bit再添两位高位0,组成四个8Bit的字节,也就是说,转换后的字符串理论上将要比原来的长1/3。
提示:
标准的Base64并不适合直接放在URL里传输,因为URL编码器不能对标准的Base64中的“/”和“+”等特殊字符进行编码。
为解决此问题,可采用一种用于URL的改进Base64编码,它在末尾填充'='号,并将标准Base64中的“+”和“/”分别改成了“-”和“_”,这样就免去了在URL编解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
另有一种用于正则表达式的改进Base64变种,它将“+”和“/”改成了“!”和“-”,因为“+”,“*”以及前面在IRCu中用到的“[”和“]”在正则表达式中都可能具有特殊含义。
4.3、编码的转换
在使用应用过程中,不同的编码使用规则
4.3.1、URL编码
URL编码(URLencoding),也称作百分号编码(Percent-encoding), 是特定上下文的统一资源定位符 (URI)的编码机制。它用于通过HTTP的请求操作(request)提交的数据进行编码。
URI所允许的字符分作正常字符与特殊字符.
特殊字符是那些具有特殊含义的字符. 例如, 斜线字符用于URL 不同部分的分界符,因此必须转换,通过百分号编码把保留字符表示为特殊字符序列.
提示:上述情形随URI与URI的不同版本规格会有轻微的变化。
特殊字符有:
| 序号 |
字符 |
十六进制值 |
URL编码 |
| 1 |
+ |
URL 中+号表示空格 |
%2B |
| 2 |
空格 |
URL中的空格可以用+号或者编码 |
%20 |
| 3 |
/ |
分隔目录和子目录 |
%2F |
| 4 |
? |
分隔实际的 URL 和参数 |
%3F |
| 5 |
% |
指定特殊字符 |
%25 |
| 6 |
# |
表示书签 |
%23 |
| 7 |
& |
URL 中指定的参数间的分隔符 |
%26 |
| 8 |
= |
URL 中指定参数的值 |
%3D |
常见应用场景:
PHP开发的API接口给JAVA调用。
容易出现的问题,特殊字符不能传输或在传输过程中丢失。
特殊字符在URL中是不能直接传递,也是不能自动进行URL编码,需要手工进行编码替代。
编码的格式为:%加字符的ASCII码,即一个百分号%,后面跟对应字符的ASCII(16进制)码值。例如 空格的编码值是"%20"。
三、Oracle中的编码与字符集
Oracle中有两个字符集:数据库字符集和国家字符集。
3.1、为什么需要两个字符集?
如果只需要英文,设置数据库字符集=US7ASCII,
如果只需要西欧字符,设置数据库字符集=WE8MSWIN1252或者WE8ISO89859P1,或者干脆就用AL32UTF8。
这里只需要设定“数据库字符集”,那么“国家字符集”有什么必要呢?
其实,考虑到历史遗留问题以及数据库创建者们无法避免的“短视”,很多现有数据库都无法支持UNICODE字符集,
例如要在现有的US7ASCII数据库字符集的数据库中存储中文,这个时候“国家字符集”+NVARCHAR2这样的组合就能救你一命了。对于数据类型为NVARCHAR2(以及NCHAR, NCLOB)的字段,它使用是国家字符集,与数据库字符集的设置无关。自9i以后,国家字符集可选的只有AL16UTF16与AL32UTF8,UTF-16与UTF-8都是UNICODE编码标准的实现,因些可以表示世界上几乎所有的文字。
当然,如果数据库字符集本身就使了UNICODE字符集,就没有必要使用NVARCHAR2, NCHAR, NCLOB这些类型了。
安装过程参考: http://www.cnblogs.com/totozlj/archive/2012/11/23/2784569.html
3.2、常见字符集
3.2.1、字符集名称规则
名称=支持国家简称+支持字符位数+编码
例如:AL32UTF8 = AL(All Language)+32(每个字符最多占用32位)+UTF8(编码为UTF8)
3.2.2、常见字符名称
①AL32UTF8
【AL】支持所有语言(All Language)。
【32】每字符最多占用32位(4字节)。
【UTF8】编码为UTF-8。
②WE8MSWIN1252
【WE】支持西欧语言(Western Europe)。
【8】每字符需要占用8位(单字节)。
【MSWIN1252】编码为CP1252。
③US7ASCII
【US】表示美国(United States)。
【7】每字符需要占用7位。
【ASCII】编码为ASCII。
其它如ZHS16GBK,ZHT16BIG5,US8PC437(编码为OEM cp437),都可以类推。
3.3、Oracle字符集查询
3.3.1、数据库参数设置
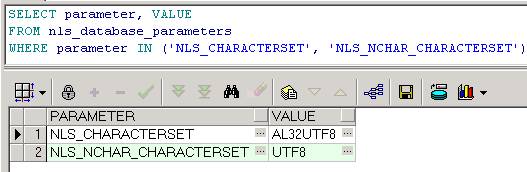
SELECTparameter, VALUE
FROMnls_database_parameters
WHEREparameter IN ('NLS_CHARACTERSET', 'NLS_NCHAR_CHARACTERSET')
九、变更记录&常见问题&参考资料
9.1、变更记录
9.2、常见问题
9.3、参考资料