使用MNIST数据集实现生成式对抗网络
1、简介
可以参考https://blog.csdn.net/u010089444/article/details/78946039
生成式对抗网络(Generative Adversarial Networks,简称GANs)包含两部分,生成模型(Generative Model, 简称G)和判别模型(Discriminative Model, 简称D)。生成式对抗模型可以简单用下图来描述。
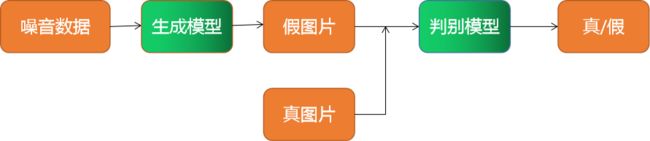
通过上图来说明下生成式对抗网络中生成模型G和判别模型D的作用:
- 生成模型G:沿着 “噪音数据->生成模型->假图片->判别模型->真/假” 这条路线,目的就是要使得噪音数据经过生成模型生成的假图片让判别模型判断为真。即不断学习真实图片的数据分布,让随机生成的噪音数据作为输入可以生成以假乱真的图片,让假图片与真图片越相似越好。
- 判别模型D:沿着整个路线,先让噪音数据经过生成模型生成假图片,然后真假图片分别经过判别模型,判别模型判别真图片为真,假图片为假,这样可以区分哪个是真图片哪个是假图片。
可以明显看出,生成模型G使得假图片与真图片越相似越好,而判别模型D使得假图片与真图片能够区分出来,也就是让两个模型进行博弈,在训练过程中两个模型不断增强,从而可以让随机生成的假图片在没有大量先验知识的前提下也能很好得去学习来逼近真实数据,最终可以让模型判断不出哪个是真图片哪个是假图片。
2、监督式的生成式对抗网络在MNIST数据集的应用
参考https://github.com/keras-team/keras/blob/master/examples/mnist_acgan.py
该部分讨论在监督学习(即数据存在标签)下,如何使用生成式对抗网络,以在MNIST数据集的应用为例。所以此时判别模型不只是判断哪个照片是真哪个照片是假了,还要判断照片应该属于哪个类别。
具体代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# author:袁阳平 yyp
# time:2019/9/1
# 写代码==我开心
from __future__ import print_function
from collections import defaultdict
try:
import cPickle as pickle
except ImportError:
import pickle
from PIL import Image
from six.moves import range
from keras.datasets import mnist
from keras import layers
from keras.layers import Input, Dense, Reshape, Flatten, Embedding, Dropout
from keras.layers import BatchNormalization
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import Conv2DTranspose, Conv2D
from tensorflow.examples.tutorials.mnist import input_data
from keras.models import Sequential, Model
from keras.optimizers import Adam
from keras.utils.generic_utils import Progbar
import numpy as np
import tensorflow as tf
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.4
with tf.Session(config =config ) as sess:
sess.run(tf.global_variables_initializer())
np.random.seed(1337)
num_classes = 10
def build_generator(latent_size):
# 利用keras构建网络
cnn = Sequential()
cnn.add(Dense(3 * 3 * 384, input_dim=latent_size, activation='relu'))
cnn.add(Reshape((3, 3, 384)))
# 上采样至 (7, 7, 192)
cnn.add(Conv2DTranspose(192, 5, strides=1, padding='valid',
activation='relu',
kernel_initializer='glorot_normal'))
cnn.add(BatchNormalization())
# 上采样至 (14, 14, 96)
cnn.add(Conv2DTranspose(96, 5, strides=2, padding='same',
activation='relu',
kernel_initializer='glorot_normal'))
cnn.add(BatchNormalization())
# 上采样至 (28, 28, 1)
cnn.add(Conv2DTranspose(1, 5, strides=2, padding='same',
activation='tanh',
kernel_initializer='glorot_normal'))
# 随机生成latent向量和类别
latent = Input(shape=(latent_size, ))
image_class = Input(shape=(1,), dtype='int32')
# 通过随机生成的latent向量与类别生成假图片
cls = Embedding(num_classes, latent_size,
embeddings_initializer='glorot_normal')(image_class)
h = layers.multiply([latent, cls])
fake_image = cnn(h)
return Model([latent, image_class], fake_image)
def build_discriminator():
# 使用keras构建网络
cnn = Sequential()
cnn.add(Conv2D(32, 3, padding='same', strides=2,
input_shape=(28, 28, 1)))
cnn.add(LeakyReLU(0.2))
cnn.add(Dropout(0.3))
cnn.add(Conv2D(64, 3, padding='same', strides=1))
cnn.add(LeakyReLU(0.2))
cnn.add(Dropout(0.3))
cnn.add(Conv2D(128, 3, padding='same', strides=2))
cnn.add(LeakyReLU(0.2))
cnn.add(Dropout(0.3))
cnn.add(Conv2D(256, 3, padding='same', strides=1))
cnn.add(LeakyReLU(0.2))
cnn.add(Dropout(0.3))
cnn.add(Flatten())
# 输入真图片或者假图片
image = Input(shape=(28, 28, 1))
# 将图片输入网络来提取图片特征
features = cnn(image)
# 输出:
# fake:判断图片为真图片还是假图片
# aux:识别图片是哪个类型,即0-9的哪一个数字
fake = Dense(1, activation='sigmoid', name='generation')(features)
aux = Dense(num_classes, activation='softmax', name='auxiliary')(features)
return Model(image, [fake, aux])
if __name__ == '__main__':
# 所有的参数设置都是来源与论文中https://arxiv.org/abs/1511.06434
epochs = 100
batch_size = 100
latent_size = 100
adam_lr = 0.0002
adam_beta_1 = 0.5
# 构建判别器discriminator
print('Discriminator model:')
discriminator = build_discriminator()
# 二分类用的是“binary_crossentropy”,多分类用的是“sparse_categorical_crossentropy”
discriminator.compile(
optimizer=Adam(lr=adam_lr, beta_1=adam_beta_1),
loss=['binary_crossentropy', 'sparse_categorical_crossentropy']
)
discriminator.summary()
# 构建生成器generator
generator = build_generator(latent_size)
# 随机生成噪音和类别
latent = Input(shape=(latent_size, ))
image_class = Input(shape=(1,), dtype='int32')
# 根据随机生成的噪音和类别生成假图片
fake = generator([latent, image_class])
# 构建联合器,在训练联合器时,只有生成器的参数会变化,判别器的参数不变
print('Combined model:')
discriminator.trainable = False
fake, aux = discriminator(fake)
combined = Model([latent, image_class], [fake, aux])
combined.compile(
optimizer=Adam(lr=adam_lr, beta_1=adam_beta_1),
loss=['binary_crossentropy', 'sparse_categorical_crossentropy']
)
combined.summary()
# 得到MNIST数据集
with np.load("./MNIST_data/mnist.npz") as file:
x_train = file["x_train"]
y_train = file["y_train"]
x_test = file["x_test"]
y_test = file["y_test"]
x_train = (x_train.astype(np.float32) - 127.5) / 127.5
x_train = np.expand_dims(x_train, axis=-1)
x_test = (x_test.astype(np.float32) - 127.5) / 127.5
x_test = np.expand_dims(x_test, axis=-1)
num_train, num_test = x_train.shape[0], x_test.shape[0]
num_batches = int(np.ceil(x_train.shape[0] / float(batch_size)))
train_history = defaultdict(list)
test_history = defaultdict(list)
for epoch in range(1, epochs + 1):
print('Epoch {}/{}'.format(epoch, epochs))
# 训练的时候会显示进度条
progress_bar = Progbar(target=num_batches)
epoch_gen_loss = []
epoch_disc_loss = []
for index in range(num_batches):
# 得到一个batch的图片和标签
image_batch = x_train[index * batch_size:(index + 1) * batch_size]
label_batch = y_train[index * batch_size:(index + 1) * batch_size]
# 得到一个batch对应的噪音noise和对应的标签
noise = np.random.uniform(-1, 1, (len(image_batch), latent_size))
sampled_labels = np.random.randint(0, num_classes, len(image_batch))
# 通过生成器生成假图片
generated_images = generator.predict(
[noise, sampled_labels.reshape((-1, 1))], verbose=0)
x = np.concatenate((image_batch, generated_images))
# 使用soft real/fake label=0:0.9,来自https://arxiv.org/pdf/1606.03498.pdf (Section 3.4)
soft_zero, soft_one = 0, 0.9
y = np.array(
[soft_one] * len(image_batch) + [soft_zero] * len(image_batch))
aux_y = np.concatenate((label_batch, sampled_labels), axis=0)
# 给discriminator设置权重
disc_sample_weight = [np.concatenate((np.ones(len(image_batch)),
np.ones(len(image_batch)))),
np.concatenate((np.ones(len(image_batch)),
np.zeros(len(image_batch))))]
# 训练discriminator
epoch_disc_loss.append(discriminator.train_on_batch(
x, [y, aux_y], sample_weight=disc_sample_weight))
# 生成新的噪音noise和标签训练联合器comined,thick为假定假图片为软真实图片
noise = np.random.uniform(-1, 1, (2 * len(image_batch), latent_size))
sampled_labels = np.random.randint(0, num_classes, 2 * len(image_batch))
trick = np.ones(2 * len(image_batch)) * soft_one
epoch_gen_loss.append(combined.train_on_batch(
[noise, sampled_labels.reshape((-1, 1))],
[trick, sampled_labels]))
# 更新进度条
progress_bar.update(index + 1)
print('Testing for epoch {}:'.format(epoch))
# 评估测试集的损失误差
# 随机生成噪音noise和标签
noise = np.random.uniform(-1, 1, (num_test, latent_size))
sampled_labels = np.random.randint(0, num_classes, num_test)
# 生成假图片
generated_images = generator.predict(
[noise, sampled_labels.reshape((-1, 1))], verbose=False)
# 连接假图片和测试集以及假图片的标签来求discriminator的测试集损失值
x = np.concatenate((x_test, generated_images))
y = np.array([1] * num_test + [0] * num_test)
aux_y = np.concatenate((y_test, sampled_labels), axis=0)
discriminator_test_loss = discriminator.evaluate(
x, [y, aux_y], verbose=False)
########################### 求解discriminator的真假判别以及类别识别的准确率 ###########
predict_y, predict_aux_y = discriminator.predict(x)
# 1、求解真实图片的真假正确率
accuracy_y_trueImg = np.sum(predict_y[0:num_test]> 0.5)/num_test
# 2、求解假图片的真假准确率
accuracy_y_fakeImg = np.sum(predict_y[num_test:] < 0.5) / num_test
# 3、求解真实图片的分类准确率
predict_aux_y = np.argmax(predict_aux_y, axis=-1)
accuracy_aux_trueImg = np.sum(predict_aux_y[0:num_test]==aux_y[:num_test])/num_test
# 4、求解假图片的分类准确率
accuracy_aux_fakeImg = np.sum(predict_aux_y[num_test:] == aux_y[num_test:]) / num_test
print("############# accuracy ################")
print("accuracy_y_trueImg: ",accuracy_y_trueImg)
print("accuracy_y_fakeImg: ", accuracy_y_fakeImg)
print("accuracy_aux_trueImg: ", accuracy_aux_trueImg)
print("accuracy_aux_fakeImg: ", accuracy_aux_fakeImg)
########################################################################################
# dicriminator的训练集损失值
discriminator_train_loss = np.mean(np.array(epoch_disc_loss), axis=0)
# 随机生成新的噪音和标签来求解generator和combined的测试集损失值
noise = np.random.uniform(-1, 1, (2 * num_test, latent_size))
sampled_labels = np.random.randint(0, num_classes, 2 * num_test)
trick = np.ones(2 * num_test)
generator_test_loss = combined.evaluate(
[noise, sampled_labels.reshape((-1, 1))],
[trick, sampled_labels], verbose=False)
# generator和combined的训练集损失值
generator_train_loss = np.mean(np.array(epoch_gen_loss), axis=0)
# 收藏损失值
train_history['generator'].append(generator_train_loss)
train_history['discriminator'].append(discriminator_train_loss)
test_history['generator'].append(generator_test_loss)
test_history['discriminator'].append(discriminator_test_loss)
# 打印损失值
print('{0:<22s} | {1:4s} | {2:15s} | {3:5s}'.format(
'component', *discriminator.metrics_names))
print('-' * 65)
ROW_FMT = '{0:<22s} | {1:<4.2f} | {2:<15.4f} | {3:<5.4f}'
print(ROW_FMT.format('generator (train)',
*train_history['generator'][-1]))
print(ROW_FMT.format('generator (test)',
*test_history['generator'][-1]))
print(ROW_FMT.format('discriminator (train)',
*train_history['discriminator'][-1]))
print(ROW_FMT.format('discriminator (test)',
*test_history['discriminator'][-1]))
# 保存每个epoch的权重
generator.save_weights(
'params_generator_epoch_{0:03d}.hdf5'.format(epoch), True)
discriminator.save_weights(
'params_discriminator_epoch_{0:03d}.hdf5'.format(epoch), True)
# 随机生成噪音以及标签并生成假图片
noise = np.random.uniform(-1, 1, (100, latent_size))
sampled_labels = np.array([
[i] * 10 for i in range(10)
]).reshape(-1, 1)
generated_images = generator.predict(
[noise, sampled_labels], verbose=0)
img = (np.concatenate([r.reshape(-1, 28)
for r in np.split(generated_images, 10)],
axis=-1) * 127.5 + 127.5).astype(np.uint8)
# 保存假图片
Image.fromarray(img).save(
'./acgan/plot_epoch_{0:03d}_generated.png'.format(epoch))
with open('acgan-history.pkl', 'wb') as f:
pickle.dump({'train': train_history, 'test': test_history}, f)
经过100个epoch之后,准确率的结果如下:
accuracy_y_trueImg: 0.1627
accuracy_y_fakeImg: 0.8732
accuracy_aux_trueImg: 0.994
accuracy_aux_fakeImg: 0.9999
如果想让判别模型判断图片为真假的准确率accuracy_y_trueImg、
accuracy_y_fakeImg都接近0.5,可以调整权重,对下列代码进行修改即可。
# 给discriminator设置权重
disc_sample_weight = [np.concatenate((np.ones(len(image_batch)),
np.ones(len(image_batch)))),
np.concatenate((np.ones(len(image_batch)),
np.zeros(len(image_batch))))]
20个epoch之后生成的假图片如下
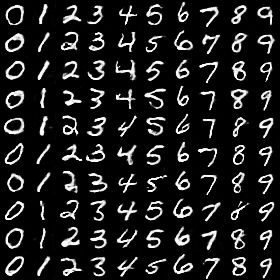
100个epoch之后生成的假图片如下:

在上述代码中有两个输入:随机生成的噪音以及随机生成的类别。如果只输入随机生成的类别,那么生成的假图片会如何呢?
20个epoch后生成的假图片:

另外本人也试了无监督式的,但是只需要在上述代码稍作修改即可,但是生成的图片没法看,那就说明完全几乎完全可以区分真图片还是假图片,计算了下准确率,真图片判别为真的准确率为99%,假图片判别为假的准确率为100%。这就说明判别模型的权重过高,调整权重,增加生成模型的权重,或者减少判别模型的权重。