个人Hadoop学习笔记
大数据 启蒙
分治思想
适用于以下场景:
- Redis集群
- ElasticSearch
- HBase
- Hadoop生态
- 等等场景
大数据重点核心思想
- 分而治之
- 并行计算
- 计算向数据移动
- 数据本地化读取
Hadoop的项目中,包含了如下模块
-
Hadoop Common
-
Hadoop Distributed File System (HDFS)
-
Hadoop YARN(分布式资源管理)
-
Hadoop MapReduce
1、2、4在1.X的Hadoop的版本中已经存在,到2.X版本时才推出了YARN。
Hadoop相关的其他较为重要的apache项目
- HBase
- Hive
- Spark
- ZooKeeper
Hadoop—HDFS(Hadoop Distributed File System)
引出疑问:为何已经有那么多的分布式文件系统了,hadoop项目还要再开发出一个HDFS文件系统?
答:为了更好地支持分布式计算
存储模型
-
将文件,线性地,按字节切割成块(block),有id和offset(偏移量)
-
按字节切割,会把一个字符对应多个字节给切"坏"了,比如,"中"字,按照UTF-8的编码,是3个字节,这样有可能会分在两个不同的块之中。
这就需要后期计算时去修复这个问题。
-
-
文件与文件的的block可以不一样
- A文件可以每个块4M,而B文件可以是每个块8M。
-
一个文件除了最后一个块,其他的块,大小一致
- 因为最后一个块可能不够一个块的标准那么大。
-
块(block)的大小,应该依据硬件的I/O特性进行调整
-
块(block)被分散存放在集群的节点中,需要具有location
-
块(block)需要具有副本(replication),没有主从概念,副本不能出现在同一个节点。
- 这里需要区分一下,主从和主备。
-
副本是满足可靠性和性能的关键
-
文件上传可以指定块的大小和副本的数量,上传后只能修改副本的数量
- 上传后,块的大小是不支持修改的,若修改文件的某个块,该块及其后面的块的偏移量为了保持正确,需要将各自的块内容进行修改,这样集群中的机器则需要大量的资源参与该行为(泛洪效应)!
-
一次写入,多次读取,不支持修改
- 如上一条
-
文件支持追加数据(追加新的块)
架构设计
- HDFS是一个主从(Master/Slaves)架构
- 由一个NameNode和若干个DataNode组成
- 面向文件,包含文件数据(data)和文件元数据(metadata)
- NameNode负责存储和管理文件元数据,并维护了一个层次型的文件目录树
- DataNode负责存储文件数据(block块),并提供block块的读写
- DataNode和NameNode维持心跳,并汇报自己持有的block块信息
- Client和NameNode交互元数据,和DataNode交互文件block块数据

角色功能
- NameNode
- 完全基于内存存储文件元数据、目录结构、文件block块的映射
- 基于内存是要快速对请求进行响应
- 需要持久化方案保证数据可靠性
- 由于基于内存,所以需要将数据持久化,以保证数据可靠性
- 提供副本放置策略
- 完全基于内存存储文件元数据、目录结构、文件block块的映射
- DataNode
- 基于本地磁盘存储block块(文件形式)
- 并保存block块的校验和数据,保证block块的可靠性
- 类似于常用的MD5值的校验
- 与NameNode保持心跳,并汇报block块列表状态
元数据持久化
方案一:日志文件(记录实时发生的增删改的操作);优点:完整性好;缺点:加载恢复数据慢,并且日志文件占空间特别大
方案二:镜像、快照、dump、db,间隔一段时间,内存中全量数据基于某一个时间点,向磁盘的溢写。优点:恢复速度快。缺点:由于是间隔,容易丢失部分数据。
HDFS中,两种方案都使用了,日志文件使用的是EditLog,快照则是使用FsImage。HDFS是使用最近时点的FsImage和增量的EditLog。
- 任何对文件系统元数据产生修改的操作,NameNode都会使用一种叫EditLog的事务日志j记录下来
- 使用FsImagec存储内存所有的元数据状态
- 使用本地磁盘保存EditLog和FsImage
- EditLog具有完整性,数据丢失少,但恢复速度慢,并有体积膨胀风险
- FsImage具有恢复速度快,体积与内存数据相当,但不能实时保存,数据丢失多
- NameNode使用了FsImage + EditLog整合的方案
- 滚动将增量的EditLog更新到FsImage,以保证更近时点的FsImage和更小的EditLog体积
安全模式
- HDFS搭建时会格式化,格式化操作会产生一个空的FsImage
- 当NameNode启动时,它从硬盘中读取EditLog和FsImage
- 将所有的EditLog中的事务作用在内存中的FsImage上
- 并将新版本的FsImage从内存中保存到本地磁盘上
- 然后删除旧的EditLog,因为这个EditLog的事务已经作用到FsImage上了
PS:NameNode恢复FsImage中,只恢复了文件的元数据信息,和块的名称,而块的位置,是不会恢复的,因为没有持久化块的位置信息,这时候就是在启动后,由DataNode向NameNode汇报,从而重新获取块的位置信息
Q:什么是安全模式
A:
- NameNode启动后,会进入一个称为安全模式的特殊状态
- 处于安全模式的NameNode不会进行数据块的复制
- NameNode从所有的DataNode接收心跳信号和块状态报告
- 每当NameNode检测确认某个数据块的副本数目达到某个值之后,那么该数据块就会被认为是**副本安全(safely replicated)**的
- •在一定百分比(这个参数可配置)的数据块被NameNode检测确认是安全之后(加上一个额外的30秒等待时间),NameNode将退出安全模式状态。
- 接下来它会确定还有哪些数据块的副本没有达到指定数目,并将这些数据块复制到其他DataNode上。
HDFS中的SNN
SecondaryNameNode(SNN)
- 在非Ha模式下,SNN一般是独立的节点,周期完成对NN的EditLog向FsImage合并,减少EditLog大小,减少NN启动时间
- 根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒
- 根据配置文件设置edits log大小 fs.checkpoint.size 规定edits文件的最大值默认是64MB

Block的副本放置策略
PS:服务器分为塔式服务器,机架服务器和刀片服务器。
- 第一个副本:放置在上传文件的DataNode;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
- 第二个副本:放置在与第一个副本不同机架的节点上。
- 第三个副本:与第二个副本相同机架的其他节点上。
- 更多的副本:随机节点。
早期1.X版本的第二个副本是放在与第一个副本同机架的其他节点,这样若是副本数设为2,那这两个副本将会放在同一个机架上,若该机架的交换机或电源出现问题,则直接就GG了!
HDFS的读写流程
HDFS的写流程
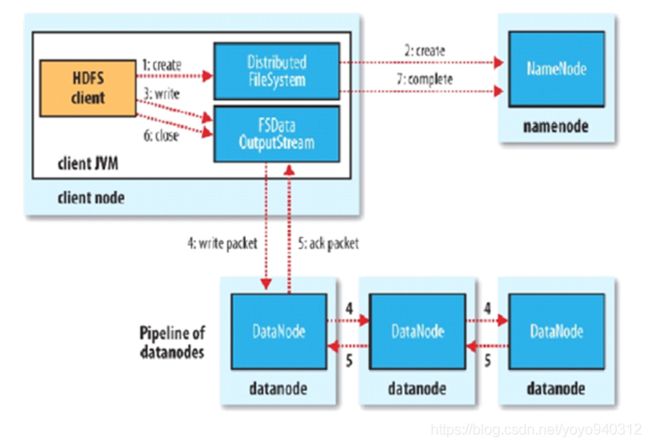
- HDFS的客户端Client向NameNode请求,交互文件的元数据
- 包括检查目标文件是否存在,父目录是否存在,判定元数据是否有效等。
- NameNode则根据block的副本放置策略返回一个有序的DataNode列表。这中间还有一个,距离的计算。
- Client客户端,会与返回的第一个DataNode建立管道连接(Pipeline,本质上是RPC调用)
- 这里并不是Client客户端与每个DataNode建立连接,而只与第一个DataNode建立连接。
- 客户端与第一个DataNode的管道中,会将block切分成更小的packet。
- 客户端把block切割成更小的packet是为了让DataNode副本之间的传输,形成流水线,而对于客户端,也是只传输一次block。
- packet的大小是64KB,并且其中使用chunk(512B)和chunksum(4B)填充。
- chunksum,是chunk的校验和
- 即每512B的内容,会生成一个校验和(4B)
- 第一个DataNode在接收完block的第一个packet后,则会向第二个DataNode传输这第一个packet并且继续接收客户端发送过来的第二个packet。
- 同理,第二个接收完第一个DataNode传过来的第一个packet后,则会向第三个DataNode传输这第一个packet并且继续接收第一个DataNode发送过来的第二个packet,以此类推,形成一个流水线。
- 当block传输完成时,DataNode们各自向NameNode汇报,同时Client继续传输下一个block
PS:Client的传输和block的汇报是并行的!
传输过程中,若其中一个节点"挂"了的情况,分
- 第一个节点挂了,那么客户端,与第二个节点建立pipeline连接,继续从第二个节点接收的packet开始继续传
- 中间节点挂了,则上一节点直接向下一节点直接续传packet。
- 结尾节点挂了,则上一节点不向这个结尾节点传packet。
挂掉导致的block块缺失,会在DataNode与NameNode汇报的时候发现,并且由其他的副本DataNode复制出一份给缺失的节点。
HDFS的读流程
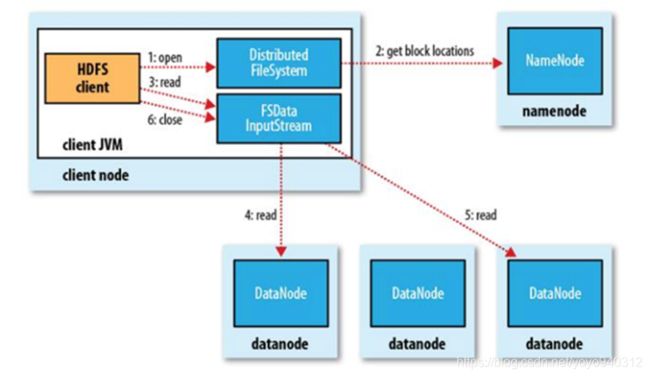
- 客户端与NameNode进行交互,取回文件的block的位置信息
- 客户端从每个block的各个副本之中,选出离自己最近的DataNode,进行下载block块
•为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。
•如果在读取程序的同一个机架上有一个副本,那么就读取该副本。
•如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本。
•语义:下载一个文件:
• Client和NN交互文件元数据获取fileBlockLocation
• NN会按距离策略排序返回
• Client尝试下载block并校验数据完整性
•语义:下载一个文件其实是获取文件的所有的block元数据,那么子集获取某些block应该成立
• Hdfs支持client给出文件的offset自定义连接哪些block的DN,自定义获取数据
• 这个是支持计算层的分治、并行计算的核心
HDFS解决方案
单点故障
- 高可用方案:HA(High Available)
- 多个NameNode,主备切换
- Hadoop 2.x的版本只支持HA的一主一备
压力过大(内存受限)
- 联帮机制:Federation(元数据分片)
- 多个NaneNode管理不同的元数据
HDFS-HA解决方案:

CAP原则
C:Consistency,一致性
A:Availability,可用性
P:Partition tolerance,分区容忍性

修改HDFS的配置
- core-site.xml
<property> <name>fs.defaultFSname> <value>hdfs://myclustervalue> property> <property> <name>ha.zookeeper.quorumname> <value>node02:2181,node03:2181,node04:2181value> property>
- hdfs-site.xml
<property> <name>dfs.nameservicesname> <value>myclustervalue> property> <property> <name>dfs.ha.namenodes.myclustername> <value>nn1,nn2value> property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1name> <value>node01:8020value> property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2name> <value>node02:8020value> property> <property> <name>dfs.namenode.http-address.mycluster.nn1name> <value>node01:50070value> property> <property> <name>dfs.namenode.http-address.mycluster.nn2name> <value>node02:50070value> property> <property> <name>dfs.namenode.shared.edits.dirname> <value>qjournal://node01:8485;node02:8485;node03:8485/myclustervalue> property> <property> <name>dfs.journalnode.edits.dirname> <value>/var/bigdata/hadoop/ha/dfs/jnvalue> property> <property> <name>dfs.client.failover.proxy.provider.myclustername> <value> org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider value> property> <property> <name>dfs.ha.fencing.methodsname> <value>sshfencevalue> property> <property> <name>dfs.ha.fencing.ssh.private-key-filesname> <value>/root/.ssh/id_dsavalue> property> <property> <name>dfs.ha.automatic-failover.enabledname> <value>truevalue> property>
部署HDFS
节点配置
这里用4个node节点
分别是node01,node02,node03,node04
一、基础设施
- 设置网络
①设置IP,若用虚拟机需要看虚拟机中NAT模式的DHCP配置,
系统中则是在 /etc/sysconfig/network-scripts/**ifcfg-…**的文件,具体需要看各自的系统中网络配置的名称
DEVICE=eth0
#HWADDR=00:0C:29:42:15:C2
TYPE=Ethernet
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.150.11
NETMASK=255.255.255.0
GATEWAY=192.168.150.2
DNS1=223.5.5.5
DNS2=114.114.114.114
②设置主机名
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node01
③设置ip与主机名映射
vi /etc/hosts
这里我四个节点的对应关系是
| 节点 | node01 | node02 | node03 | node04 |
|---|---|---|---|---|
| IP | 192.168.74.11 | 192.168.74.12 | 192.168.74.13 | 192.168.74.14 |
| pub文件名 | node01.pub | node02.pub | node03.pub | node04.pub |
192.168.74.11 node01
192.168.74.12 node02
192.168.74.13 node03
192.168.74.14 node04
- 关闭防火墙
cmd:
service iptables stop
chkconfig iptables off
- 关闭selinux
vi /etc/selinux/config
SELINUX=disabled
- 时间同步
yum install ntp -y
vi /etc/ntp.conf
server ntp1.aliyun.com
cmd:
service ntpd start
chkconfig ntpd on
- 安装JDK
①下载rpm安装文件
rpm -i jdk-8u231-linux-x64.rpm
PS: 有些软件的java路径只认**"/usr/ava/default"**,所以用rpm安装,默认就是在该地址
②修改环境变量
vi /etc/profile
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin
③重新加载环境变量
cmd:
source /etc/profile
或
. /etc/profile
- 配置ssh免密登录
先让系统自己生成~/.ssh文件夹,使用ssh命令登录自己先
命令行输入:“ssh localhost”,然后输入用户名密码
主要有两个作用:
Ⅰ. 验证自己还没有免密
Ⅱ. 让系统自动生成/root/.ssh
①生成公钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
-t : 后面接加密的方式,还有rsa等加密方式
-P : 后面接密码
-f : 输出的路径
②公钥加入authorized_keys
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
将自己的公钥加入到免密登录列表
后面,4个节点的id_dsa.pub文件将会互相传递,并加入免密登录,这样4台机器则可以免密登录
后续我将把4个节点对应的id_dsa.pub文件统一分别改成node01.pub, node02.pub, node03.pub, node04.pub,并且放到各台机器的~/.ssh目录中,并且加入到免密登录中
cat ~/.ssh/node01.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/node02.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/node03.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/node04.pub >> ~/.ssh/authorized_keys
PS: 自己的pub可以不用加,因为之前已经将id_dsa.pub加到authorized_keys
二、ZooKeeper集群搭建
-
配置ZooKeeper的环境变量
vi /etc/profile
#配置ZooKeeper的环境变量,并加到PATH中
export ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.4.14
export Path=…;$ZOOKEEPER_HOME/bin
-
修改zoo.cfg(将$ZOOKEEPER_HOME/conf/zoo_sample.cfg复制改为zoo.cfg)
#增加一下的配置
datadir=/var/bigdata/hadoop/zk
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
-
分发ZooKeeper到各个机器中
-
zoo.cfg中对应的各个机器的id需要修改
对应机器中的/var/bigdata/hadoop/zk/myid文件(若没有则需要新增该文件)中,写入ID
例如node02则写1,node03写2,node04写3
-
ZooKeeper集群的所有机器启动ZooKeeper
zkServer.sh start
三、Hadoop搭建配置
| NameNode | JournalNode | ZKFC | ZK | DataNode | ResourceManager | NodeManager | |
|---|---|---|---|---|---|---|---|
| Node01 | * | * | |||||
| Node02 | * | * | * | * | * | * | |
| Node03 | * | * | * | * | * | ||
| Node04 | * | * | * | * |
(PS:上下这两个是一样的只是转了下方向)
| Node01 | Node02 | Node03 | Node04 | |
|---|---|---|---|---|
| NameNode | * | * | ||
| JournalNode | * | * | ||
| ZK | * | * | * | |
| ZKFC | * | * | ||
| DataNode | * | * | * | |
| ResourceManager | * | * | ||
| NodeManager | * | * | * |
- 规划路径:
mkdir /opt/bigdata
cd /opt/bigdata
tar xf hadoop-2.6.5.tar.gz
解压出了一个文件夹名为"hadoop-2.6.5"
- 设置环境变量:
vi /etc/profile
export JAVA_HOME=/usr/java/default
export HADOOP_HOME=/opt/bigdata/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
- 配置hadoop的角色:
由于Hadoop是基于Java的,所以需要给Hadoop配置JavaHome路径,否则会找不到。
vi $HADOOP_HOME/etc/hadoop/hadoop-en.sh
“export JAVA_HOME=/usr/java/default”
-
配置NameNode角色和Zookeeper位置
vi $HADOOP_HOME/etc/hadoop/core-site.xml<property> <name>fs.defaultFSname> <value>hdfs://myclustervalue> property> <property> <name>ha.zookeeper.quorumname> <value>node02:2181,node03:2181,node04:2181value> property> -
配置HDFS
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml<property> <name>dfs.replicationname> <value>3value> property> <property> <name>dfs.namenode.name.dirname> <value>/var/bigdata/hadoop/ha/dfs/namevalue> property> <property> <name>dfs.datanode.data.dirname> <value>/var/bigdata/hadoop/ha/dfs/datavalue> property> <property> <name>dfs.namenode.checkpoint.dirname> <value>/var/bigdata/hadoop/local/dfs/secondaryvalue> property> <property> <name>dfs.namenode.secondary.http-addressname> <value>node02:50090value> property> <property> <name>dfs.namenode.shared.edits.dirname> <value>qjournal://node01:8485;node02:8485;node03:8485/myclustervalue> property> <property> <name>dfs.journalnode.edits.dirname> <value>/var/bigdata/hadoop/ha/dfs/jnvalue> property> <property> <name>dfs.nameservicesname> <value>myclustervalue> property> <property> <name>dfs.ha.namenodes.myclustername> <value>nn1,nn2value> property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1name> <value>node01:8020value> property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2name> <value>node02:8020value> property> <property> <name>dfs.namenode.http-address.mycluster.nn1name> <value>node01:50070value> property> <property> <name>dfs.namenode.http-address.mycluster.nn2name> <value>node02:50070value> property> <property> <name>dfs.client.failover.proxy.provider.myclustername> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue> property> <property> <name>dfs.ha.fencing.methodsname> <value>sshfencevalue> property> <property> <name>dfs.ha.fencing.ssh.private-key-filesname> <value>/root/.ssh/id_dsavalue> property> <property> <name>dfs.ha.automatic-failover.enabledname> <value>truevalue> property> -
配置DataNode角色
vi $HADOOP_HOME/etc/hadoop/slavesnode01 node02 node03 node04
-
初始化&启动:
1)到对应JournalNode节点中,启动JournalNode
hadoop-daemon.sh start journalnode2)选择一个NameNode进行格式化(只有第一次搭建需要进行这一步,以后的不用做)
hdfs namenode -format3)启动格式化后的NameNode,以备另一台NameNode同步
hadoop-daemon.sh start namenode4)在另外一台NameNode中,启动standbyNameNode
hdfs namenode -bootstrapStandby5)格式化zkfc(只有第一次搭建需要做,以后就不用做了)
hdfs zkfc -formatZK6)启动hdfs
start-dfs.sh
初始化NameNode,会创建目录,并且初始化一个空的FsImage
Hadoop—MapReduce
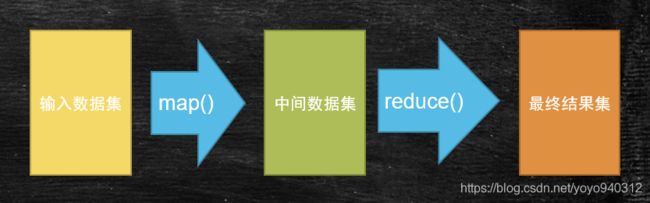
MapReduce是一种计算模型。分为两种阶段,分别是Map阶段和Reduce阶段,是一种阻塞关系。
Map阶段:对单条记录加工和处理
Reduce阶段:按组,对多条记录进行加工和处理
实现:
计算向数据移动
hdfs暴露数据的位置
1)资源管理
2)任务的调度
角色:
1)JobTracker
i . 资源管理
ii. 任务调度
2)TaskTracker
i . 任务管理
ii. 资源汇报
3)Client
i . 会根据每次的计算数据,咨询NameNode元数据(block) => 算:split,得到所有切片的清单
ii. 生成计算程序未来运行时的相关配置的文件
iii.未来的移动,应该要相对可靠,所以client要将jar包,split清单,相关配置文件上传到hdfs的目录中(副本数是10)。
iv. client调用JobTracker,通知要启动一个计算程序了,并且告知文件都放在了hdfs的哪些地方。
计算向数据移动的流程:
- Client阶段:
1)根据NameNode返回元数据情况,计算出split的清单
2)生成计算程序运行时的配置文件
3)将jar包、split清单和相关配置文件上传到hdfs的目录中
4)调用JobTracker,通知启动计算,并且告知文件存放在hdfs中的位置
- JobTracker
1)从hdfs中取回所有split清单;
2)根据自己收到的TaskTracker汇报的资源,最终确定每一个split对应的map应该去到哪一个节点(确定节点)
3)
- TaskTracker
1)在向JobTracker心跳的同时取回分配给自己的任务信息;
2)取回任务信息后,从hdfs中下载jar包和运行时相关配置文件到本机
3)最终启动任务描述中的MapTask或ReduceTask
使用JobTracker会产生3个弊端:
-
单点故障问题
-
压力过大
-
JobTracker集成了资源管理和任务调度,两者耦合,
产生的弊端:未来的计算框架不能复用资源管理,因为各自实现资源管理,但是他们的资源是相同的一批硬件,因为各自的资源管理隔离,所以不能感知对方的使用,会造成资源的争抢。
因此,此时产生了Hadoop中的Yarn。
Hadoop—Yarn(资源管理)

配置
-
配置mapred-site.xml,说明mapreduce是基于yarn上的
<property> <name>mapreduce.framework.namename> <value>yarnvalue> property> -
配置yarn-site.xml
<property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.resourcemanager.ha.enabledname> <value>truevalue> property> <property> <name>yarn.resourcemanager.zk-addressname> <value>node02:2181,node03:2181,node04:2181value> property> <property> <name>yarn.resourcemanager.cluster-idname> <value>mycluster-yarnvalue> property> <property> <name>yarn.resourcemanager.ha.rm-idsname> <value>rm1,rm2value> property> <property> <name>yarn.resourcemanager.hostname.rm1name> <value>node03value> property> <property> <name>yarn.resourcemanager.hostname.rm2name> <value>node04value> property> -
启动yarn
start-yarn.sh这个命令其实只启动了NodeManager,没有启动ResourceManager,需要手动去机器启动ResourceManager
-
启动yarn的ResourceManager
yarn-daemon.sh start resourcemanager
工作流程
- Client联系ResourceManager,ResourceManager会从所有的NodeManager节点中,找一台不那么忙的机器,作为一个ApplicationMaster。
* ApplicationMaster是一个去除掉资源管理的JobTracker,即只有任务调度的功能角色。每一个客户端启动的调度,都会有一个独立的ApplicationMaster。
- ApplicationMaster从hdfs获取到切片清单后,再依赖ResourceManager确定计算向哪些NodeManager节点移动,确定了NodeManager后,启动了Container
- Container再向ApplicationMaster汇报(反向注册),然后开始跑程序(从hdfs获取程序等)。
Container是容器,用来泛指各种资源,它可以是CPU,也可以是I/O资源、内存资源等,也可以是一个jvm进程。
- NodeManager会有线程监视container的资源情况,超额的话,NodeManager会直接将其kill掉。
- codegroupn内核级技术,在启动jvm进程时,由kernel约束。
ResourceManager(主)
简要作用:负责整体资源的管理
NodeManager(从)
简要作用:向ResourceManager汇报心跳,提交自己的资源情况
MR运行:MapReduce on Yarn
- MR-Cli准备切片清单 / 配置文件 / jar 传到hdfs,然后访问ResourceManager申请ApplicationMaster;
- ResourceManager选择一台不太忙的NodeManager节点启动一个container,在里面反射一个MR的ApplicationMaster;
- 启动MR的ApplicationMaster,向hdfs下载切片清单,然后向ResourceManager申请资源;
- 由ResourceManager根据自身掌握的情况,确定出一个最终的切片清单,并且通知NodeManager来启动container;
- container启动后,反向注册到对应的ApplicationMaster进程;
- MR的ApplicationMaster最终将任务发送给container(发送消息);
- container会反射相应的Task类对象,调用方法执行;
PS:计算框架都有Task失败重试的机制。
结论:
1. 在Yarn中,每一个Application由一个自己的ApplicationMaster调度,每个Application都是独立的。
2. 在Yarn中,每一个Application有自己的ApplicationMaster负责自己的调度,由于不同的ApplicationMaster是在不同的节点中启动,默认已经有了负载的作用。
3. 因为Yarn统一负责了整个框架的资源管理,只要计算框架继承的Yarn的ApplicationMaster,就都可以使用这个这个统一的资源管理。
Hadoop-1.x中,JobTracker和TaskTracker都是MapReduce的常服务,而升级到2.x之后,没有了这些常服务,都变成了临时服务。
Hadoop—MapReduce

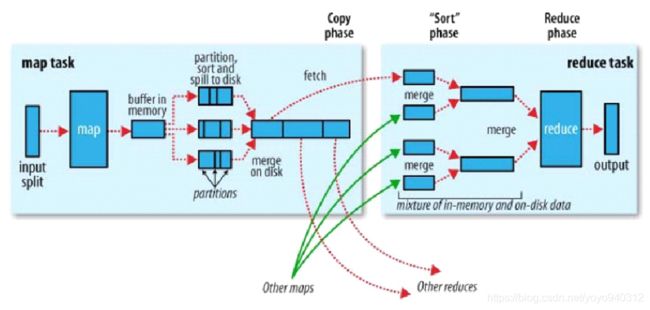
步骤:
- 切片将block格式化成记录,以一条记录为单位,调用map;
- map处理数据,输出映射(K-V),K-V会参与一次分区计算,根据key,计算出Partition(分区号),最终其实是输出K-V-P;(MapTask输出的是一个文件,存在于本地的文件系统中)
- 内存缓冲区溢写时,做一个2次排序,达到[分区有序,且分区内key有序],这样未来,相同的key会相邻的排在一起;
- Reduce的归并算法其实可以和reduce方法的计算同时发生,尽量减少IO(因为有迭代器模式的支持);
一、split:
split一般情况下,默认等于block,加一个split是用来解耦。block是物理的,split是逻辑的。split的数量可以在后续编程时支持修改。split可以控制并行度。
Map的并行度,由split的数量决定。
二、组(分区、Partition)
reduce的并行度是由开发人员决定,框架默认reduce的数量为1。
PS:如果有数据倾斜?比如key有1和2两种,key为1的有1亿条,key为2的有2条,这样reduce并行度为2的话,按照默认的执行,执行出来的时间其实远差于平均时间,这样的话该如何解决?(这个是我个人自身的思考的问题,在google里可以搜索[MapReduce key 数据倾斜],我个人目前还没看完
数据倾斜我看了一下知乎上有人回答,链接如下:数据倾斜
1. 聚合数据源 2. 提高Shuffle操作Reduce并行度 3. 随机key实现双重聚合 4. 将reduce join 转换为map join 5. sample采样倾斜key进行二次join 6. 使用随机数以及扩容表进行join三、各个名词间的数量关系
Block 与 Split
- 1:1
- N:1
- 1:N
Split 与 Map
- 1:1
Map 与 Reduce
- 1:1
- 1:N
- N:1
- N:N
Group(Key) 与 Partition
- 1:1
- 1:N
- N:N
总结:数据已一条记录为单位经过map方法映射成KV,相同的key为一组,这一组数据调用一次reduce方法,在方法内迭代计算着一组数据。
代码提交的方式:
-
开发工具打包成jar包,上传至集群中的某一个节点,使用命令"hadoop jar ooxx.jar oo.xx in out";
-
嵌入的集群方式,嵌入到linux或windows,on yarn
hadoop默认都是linux上运行的,所以windows是异构平台,需要修改一个异构的配置:
conf.set("mapreduce.app-submission.cross-platform", "true");运行时需要设置jar的地址
job.setJar("D:\\WorkSpace\\HadoopMapReduce\\target\\HadoopMapReduce-1.0-SNAPSHOT.jar");集群:流程是Client -> ResourceManager -> ApplicationMaster
mapreduce.framework.name -> yarn
-
Local,单机运行,一般用于自测
hadoop
mapreduce.framework.name -> local
主程序的传参数使用main函数的args传入,这里有一个框架给的工具类GenericOptionsParser,大致用法就是
GenericOptionsParser parser = new GenericOptionsParser(conf, args);
String[] otherArgs = parser.getRemainingArgs();
Client
Client没有实际的业务计算发生,但是十分重要,它支撑了计算向数据移动和计算的并行度。
源码分析:
1. 检查信息,输入路径输出路径等信息;
2. 计算切片信息,这里有个输入格式化类(InputFormat)可以通过配置"mapreduce.job.inputformat.class",默认是"org.apache.hadoop.mapreduce.lib.input.TextInputFormat"类;
计算过程:
①minSize——默认是1,可以通过配置**“mapreduce.input.fileinputformat.split.minsize”**或者代码TextInputFormat.setMinInputSplitSize(job, 999);设置
②maxSize——默认是Long.MAX_VALUE,可以通过配置**“mapreduce.input.fileinputformat.split.maxsize”**或者代码TextInputFormat.setMaxInputSplitSize(job, 99999);
③blockSize——每个文件有自己blockSize
④splitSize,公式是:Math.max(minSize, Math.min(maxSize, blockSize))。默认splitSize=blockSize。如果想要得到一个比blockSize大的splitSize,要修改minSize,反之修改maxSize。
Split有四个重要的属性:
①file,属于哪个文件的
②offset,对于文件开头的偏移量
③length,大小
④hosts,主机——这个属性支撑了计算向数据移动,决定了计算可以向哪些机子移动。
3.上传必要的文件到hdfs中,on yarn的默认路径是"/tmp/hadoop-yarn/staging"
MapTask
- 映射、变换、过滤
- 1进N出
源码分析:
1. MapTask通过反射,获得Mapper,配置项是"mapreduce.job.map.class"。
2.MapTask通过反射,获得InputFormat,配置项是"mapreduce.job.inputformat.class"
3.获得属于自己的split信息
4.读取记录(默认是TextInputFormat,返回行记录读取器LineRecordReader)
PS:在计算过程中,那些被切割的数据如何恢复,则是在LineRecordReader的initialize方法中,将除了第一个split的第一行舍弃,并将其给上一个split,这样被切割的数据就拼合在一起了。
5.计算分区(使用分区器,默认的分区器是HashPartitioner,配置项是"mapreduce.job.partitioner.class")
计算分区号,公式是**"(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks"**,所以,相同的key会去到同一个分区里。到这一步,输出的要素就是有k(ey), v(alue), p(artition)三个要素,将这三要素放到缓存区里。
6.buffer容器输出(默认的buffer输出类是MapOutputBuffer,配置项是"mapreduce.job.map.output.collector.class")
buffer容器初始化的时候,这里会有一个溢写的阈值(配置项**“mapreduce.map.sort.spill.percent”),默认是80%,还有buffer容器默认的大小(配置项"mapreduce.task.io.sort.mb"),默认是100(MB)**,后续可以通过这两个参数去进行调优。
这中间包含一个排序的过程,sorter,默认是QuickSort(快排),而排序需要有比较器(Comparator),优先取用户自定义的(配置项"map.sort.class"),否则是用Key这个类型自身的比较器。
MapOutputBuffer
模型中包含数据和索引(16个字节Byte),索引的数据中放了4个元素:
- P(artition),分区。1个整形数值,4个字节Byte;
- K(ey)S(tart),Key数据开始的下标。1个整形数值,4个字节Byte;
- V(alue)S(tart),Value数据开始的辖标。1个整形数值,4个字节Byte;
- V(alue)L(ength),Value的长度。1个整形数值,4个字节Byte。
通过KS和VS,则可以确定Key的内容;
通过VS和VL,则可以确定Value的内容;
在数据内容达到阈值后,则会开始溢写,在开始溢写到磁盘前,会先进行排序。
MapOutputBuffer的数据模型是一个环形缓冲区,先在环形缓冲区中,设置一个起点[赤道],向左是存放数据,向右是存放索引,当达到阈值时,原本的内存锁住进行溢写,在剩余的内存中再重新设置一个起点[赤道],同样是一个方向是数据,一个方向是索引(这里两个的方向要一致,一致的意思是,两次起点[赤道]之间的内容需要是一致的,都是数据,或者都是索引!)
PS:本质环形缓冲区还是一个线性结构!!!
溢写前,进行排序,排序后,需要将位置进行交换,而由于数据的长度是不定,而索引的长度是固定的,所以交换过程中,是交换索引的顺序,而非数据的顺序 ,后面溢写的时候再根据索引的顺序去获取数据即可。
7.combiner环节
combiner是一个有点类似预reduce的一个过程。
combiner默认是没有的。
PS:
- 其实就是map里的reduce,也是需要按组统计;
- 发生的时间点:
① 内存溢写之前,排序之后,这样溢写的I/O会变少;
② 有一个minSpillsForCombine(配置项是"mapreduce.map.combine.minspills",默认为3)的参数。map输出结束后,当溢写次数≥这个参数时,会将多次溢写的小文件合并成一个大文件(避免小文件的碎片化对未来reduce拉取数据造成的随机读写)期间,也会出发combiner。
- combine有一个注意点!!!combine的计算必须是幂等的!
例如:求和就是幂等计算,求平均数就不是幂等计算。
ReduceTask
- 分解、缩小、归纳
- 一组进N出
- (Key,Value)
- 键值对的键划分数据分组
源码分析:
主要分为3步,
①shuffle:拉取数据;
②sort:这里的sort是指将map排好序的一堆小文件做归并排序;
里面有一个grouping comparator(分组比较器),
③reduce。
1.拉取数据
shuffle拉取回来一个迭代器。即reduce拉取回属于自己的数据,并包装成迭代器,然后获取分组比较器(getOutputValueGroupingComparator,分组比较器优先取用户设置的,否则取默认的Key自身的比较器)
分组比较器与排序比较器: 排序比较器:返回值是1、0和-1,分别表示大于、等于和小于。 分组比较器:返回值是true和false,分别表示是和不是,即布尔值。 排序比较器是可以做分组比较器的,1和-1表示为false,0表示为true即可。2.迭代器迭代组
hasMore、nextKeyIsSame。迭代器在迭代的时候,会多取一组,去判断当前key和下一组的key是否是一样的。
nextKeyIsSame: