Spark组件之SparkR学习1--安装与测试
更多代码请见:https://github.com/xubo245/SparkLearning
环境:
ubuntu:Spark 1.5.2(已装)、R3.2.1
Window: Rstudio
1Ubuntu下配置
1.1.R安装:
Spark安装后直接启动SparkR会报错,R找不到,故需要装R
1.1.1R下载:
https://cran.r-project.org/src/base/R-3/
或者:
https://cran.rstudio.com/src/base/R-3/
1.1.2安装:解压后
./configure
make
sudo make install卸载:
sudo make uninstall1.1.3 环境变量配置
vi /etc/profile
source /etc/profile再启动SparkR就可以进入SparkR shell中了
1.2使用
1.2.1启动:
./bin/sparkRsparkR里面已经初始化了sc等:
sc <- sparkR.init()
sqlContext <- sparkRSQL.init(sc)1.2.2 examples:
1.2.2.1 R自带faithful数据集:
> df <- createDataFrame(sqlContext, faithful)
> head(df)
eruptions waiting
1 3.600 79
2 1.800 54
3 3.333 74
4 2.283 62
5 4.533 85
6 2.883 55
1.2.2.2 json数据读入
需要先就spark目录下的examples上传到hdfs的根目录下,或者自定义目录
> people <- read.df(sqlContext, "/examples/src/main/resources/people.json", "json")
> head(people)
age name
1 NA Michael
2 30 Andy
3 19 Justin> printSchema(people)
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
1.2.2.3存储dataFrame文件:
> write.df(people, path="/xubo/spark/people.parquet", source="parquet", mode="overwrite")
NULL
前后:
hadoop@Master:~$ hadoop fs -ls /xubo/spark
Found 5 items
drwxr-xr-x - hadoop supergroup 0 2016-03-29 21:24 /xubo/spark/data
drwxr-xr-x - hadoop supergroup 0 2016-04-14 15:55 /xubo/spark/dataSQL
drwxr-xr-x - hadoop supergroup 0 2016-04-14 16:45 /xubo/spark/examples
drwxr-xr-x - xubo supergroup 0 2016-04-15 10:56 /xubo/spark/file
drwxr-xr-x - xubo supergroup 0 2016-03-29 15:32 /xubo/spark/output
hadoop@Master:~$ hadoop fs -ls /xubo/spark
Found 6 items
drwxr-xr-x - hadoop supergroup 0 2016-03-29 21:24 /xubo/spark/data
drwxr-xr-x - hadoop supergroup 0 2016-04-14 15:55 /xubo/spark/dataSQL
drwxr-xr-x - hadoop supergroup 0 2016-04-14 16:45 /xubo/spark/examples
drwxr-xr-x - xubo supergroup 0 2016-04-15 10:56 /xubo/spark/file
drwxr-xr-x - xubo supergroup 0 2016-03-29 15:32 /xubo/spark/output
drwxr-xr-x - hadoop supergroup 0 2016-04-20 00:34 /xubo/spark/people.parquet
hadoop@Master:~$ hadoop fs -ls /xubo/spark/people.parquet
Found 5 items
-rw-r--r-- 3 hadoop supergroup 0 2016-04-20 00:34 /xubo/spark/people.parquet/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 277 2016-04-20 00:34 /xubo/spark/people.parquet/_common_metadata
-rw-r--r-- 3 hadoop supergroup 750 2016-04-20 00:34 /xubo/spark/people.parquet/_metadata
-rw-r--r-- 3 hadoop supergroup 537 2016-04-20 00:34 /xubo/spark/people.parquet/part-r-00000-9d377482-1bb6-46c3-bb19-d107a7da660a.gz.parquet
-rw-r--r-- 3 hadoop supergroup 531 2016-04-20 00:34 /xubo/spark/people.parquet/part-r-00001-9d377482-1bb6-46c3-bb19-d107a7da660a.gz.parquet
1.2.2.4 对DataFrame的操作:
> df <- createDataFrame(sqlContext, faithful)
> df
DataFrame[eruptions:double, waiting:double]
> head(select(df, df$eruptions))
eruptions
1 3.600
2 1.800
3 3.333
4 2.283
5 4.533
6 2.883
> head(select(df, "eruptions"))
eruptions
1 3.600
2 1.800
3 3.333
4 2.283
5 4.533
6 2.883
> head(filter(df, df$waiting < 50))
eruptions waiting
1 1.750 47
2 1.750 47
3 1.867 48
4 1.750 48
5 2.167 48
6 2.100 49
1.2.2.5 Grouping, Aggregation
> head(summarize(groupBy(df, df$waiting), count = n(df$waiting)))
waiting count
1 81 13
2 60 6
3 93 2
4 68 1
5 47 4
6 80 8
> waiting_counts <- summarize(groupBy(df, df$waiting), count = n(df$waiting))
> head(arrange(waiting_counts, desc(waiting_counts$count)))
waiting count
1 78 15
2 83 14
3 81 13
4 77 12
5 82 12
6 84 10
> df$waiting_secs <- df$waiting * 60
> head(df)
eruptions waiting waiting_secs
1 3.600 79 4740
2 1.800 54 3240
3 3.333 74 4440
4 2.283 62 3720
5 4.533 85 5100
6 2.883 55 3300
1.2.2.7 Running SQL Queries from SparkR
> people <- read.df(sqlContext, "/examples/src/main/resources/people.json", "json")
> registerTempTable(people, "people")
> teenagers <- sql(sqlContext, "SELECT name FROM people WHERE age >= 13 AND age <= 19")
> head(teenagers)
name
1 Justin> df <- createDataFrame(sqlContext, iris)
Warning messages:
1: In FUN(X[[i]], ...) :
Use Sepal_Length instead of Sepal.Length as column name
2: In FUN(X[[i]], ...) :
Use Sepal_Width instead of Sepal.Width as column name
3: In FUN(X[[i]], ...) :
Use Petal_Length instead of Petal.Length as column name
4: In FUN(X[[i]], ...) :
Use Petal_Width instead of Petal.Width as column name
> model <- glm(Sepal_Length ~ Sepal_Width + Species, data = df, family = "gaussian")
> head(df)
Sepal_Length Sepal_Width Petal_Length Petal_Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
> summary(model)
$coefficients
Estimate
(Intercept) 2.2513930
Sepal_Width 0.8035609
Species__versicolor 1.4587432
Species__virginica 1.9468169
> predictions <- predict(model, newData = df)
> head(select(predictions, "Sepal_Length", "prediction"))
Sepal_Length prediction
1 5.1 5.063856
2 4.9 4.662076
3 4.7 4.822788
4 4.6 4.742432
5 5.0 5.144212
6 5.4 5.385281
由于没有搭建hive,故没有尝试hive的操作
2.Windows下配置:
2.1R安装
2.1.1 下载:
https://cran.r-project.org/mirrors.htmlhttps://mirrors.tuna.tsinghua.edu.cn/CRAN/2.1.2安装:简单。。。
2.2 RStudio安装:windows 7
2.2.1 下载:
https://www.rstudio.com/products/rstudio/download/
2.2.2安装:简单...
2.3 配置RStudio与SparkR
2.3.1下载编译好的spark到本地,比如:spark-1.5.2-bin-hadoop2.6.tar
2.3.2在RStudio中导入:
# Set this to where Spark is installed
Sys.setenv(SPARK_HOME="D:/1win7/java/spark-1.5.2-bin-hadoop2.6")
# This line loads SparkR from the installed directory
.libPaths(c(file.path(Sys.getenv("SPARK_HOME"), "R","lib"), .libPaths()))
library(SparkR)
sc <- sparkR.init(master="local")
sqlContext <- sparkRSQL.init(sc)
测试:
print("SparkR")
df <- createDataFrame(sqlContext, faithful)
head(df)
print(df)
people <- read.df(sqlContext, "D:/all/R/examples/src/main/resources/people.json", "json")
head(people)
print(people)
print("end")输出:
> source('D:/all/R/1.R')
[1] "SparkR"
DataFrame[eruptions:double, waiting:double]
DataFrame[age:bigint, name:string]
[1] "end"2.4 RStudio上使用SparkR:
2.4.1 自带数据集:
> df <- createDataFrame(sqlContext, faithful)
> head(df)
eruptions waiting
1 3.600 79
2 1.800 54
3 3.333 74
4 2.283 62
5 4.533 85
6 2.883 55> sc <- sparkR.init(sparkPackages="com.databricks:spark-csv_2.11:1.0.3")
Re-using existing Spark Context. Please stop SparkR with sparkR.stop() or restart R to create a new Spark Context
> sqlContext <- sparkRSQL.init(sc)
> sparkR.stop()
> sc <- sparkR.init(sparkPackages="com.databricks:spark-csv_2.11:1.0.3")
Launching java with spark-submit command D:/1win7/java/spark-1.5.2-bin-hadoop2.6/bin/spark-submit.cmd --packages com.databricks:spark-csv_2.11:1.0.3 sparkr-shell C:\Users\xubo\AppData\Local\Temp\RtmpaGdWr8\backend_porte9c63a41172
> sqlContext <- sparkRSQL.init(sc)2.4.3 Json操作,文件在spark里面的examples文件夹
> people <- read.df(sqlContext, "D:/all/R/examples/src/main/resources/people.json", "json")
> head(people)
age name
1 NA Michael
2 30 Andy
3 19 Justin> printSchema(people)
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)2.4.4 1.R文件运行代码:
# Set this to where Spark is installed
#Sys.setenv(SPARK_HOME="D:/1win7/java/spark-1.5.2-bin-hadoop2.6")
# This line loads SparkR from the installed directory
#.libPaths(c(file.path(Sys.getenv("SPARK_HOME"), "R","lib"), .libPaths()))
#library(SparkR)
#sc <- sparkR.init(master="local")
#sqlContext <- sparkRSQL.init(sc)
print("SparkR")
df <- createDataFrame(sqlContext, faithful)
head(df)
print(df)
people <- read.df(sqlContext, "D:/all/R/examples/src/main/resources/people.json", "json")
head(people)
print(people)
printSchema(people)
print("end")运行结果:
> source('D:/all/R/1.R')
[1] "SparkR"
DataFrame[eruptions:double, waiting:double]
DataFrame[age:bigint, name:string]
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
[1] "end"2.4.5 存储为parquet:
write.df(people, path="D:/all/R/people.parquet", source="parquet", mode="overwrite")
结果:
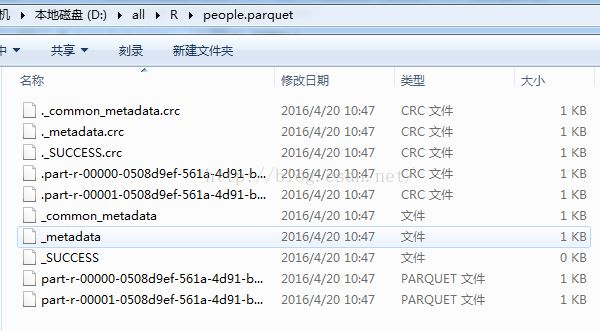
2.4.6 Hive的操作:
> hiveContext <- sparkRHive.init(sc)
> sql(hiveContext, "CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
DataFrame[result:string]
> sql(hiveContext, "LOAD DATA LOCAL INPATH 'D:/all/R/examples/src/main/resources/kv1.txt' INTO TABLE src")
DataFrame[result:string]
>
> results <- sql(hiveContext, "FROM src SELECT key, value")
> head(results)
key value
1 238 val_238
2 86 val_86
3 311 val_311
4 27 val_27
5 165 val_165
6 409 val_4092.4.7 DataFrame的 操作
> # Create the DataFrame
> df <- createDataFrame(sqlContext, faithful)
>
> # Get basic information about the DataFrame
> df
DataFrame[eruptions:double, waiting:double]
> ## DataFrame[eruptions:double, waiting:double]
>
> # Select only the "eruptions" column
> head(select(df, df$eruptions))
eruptions
1 3.600
2 1.800
3 3.333
4 2.283
5 4.533
6 2.883
> ## eruptions
> ##1 3.600
> ##2 1.800
> ##3 3.333
>
> # You can also pass in column name as strings
> head(select(df, "eruptions"))
eruptions
1 3.600
2 1.800
3 3.333
4 2.283
5 4.533
6 2.883
>
> # Filter the DataFrame to only retain rows with wait times shorter than 50 mins
> head(filter(df, df$waiting < 50))
eruptions waiting
1 1.750 47
2 1.750 47
3 1.867 48
4 1.750 48
5 2.167 48
6 2.100 49
> ## eruptions waiting
> ##1 1.750 47
> ##2 1.750 47
> ##3 1.867 482.4.8 Grouping, Aggregation
> # We use the `n` operator to count the number of times each waiting time appears
> head(summarize(groupBy(df, df$waiting), count = n(df$waiting)))
waiting count
1 81 13
2 60 6
3 93 2
4 68 1
5 47 4
6 80 8
> ## waiting count
> ##1 81 13
> ##2 60 6
> ##3 68 1
>
> # We can also sort the output from the aggregation to get the most common waiting times
> waiting_counts <- summarize(groupBy(df, df$waiting), count = n(df$waiting))
> head(arrange(waiting_counts, desc(waiting_counts$count)))
waiting count
1 78 15
2 83 14
3 81 13
4 77 12
5 82 12
6 84 10
>
> ## waiting count
> ##1 78 15
> ##2 83 14
> ##3 81 132.4.9 Operating on Columns
> # Convert waiting time from hours to seconds.
> # Note that we can assign this to a new column in the same DataFrame
> df$waiting_secs <- df$waiting * 60
> head(df)
eruptions waiting waiting_secs
1 3.600 79 4740
2 1.800 54 3240
3 3.333 74 4440
4 2.283 62 3720
5 4.533 85 5100
6 2.883 55 3300
> ## eruptions waiting waiting_secs
> ##1 3.600 79 4740
> ##2 1.800 54 3240
> ##3 3.333 74 44402.4.10 Running SQL Queries from SparkR
> # Load a JSON file
> people <- read.df(sqlContext, "D:/all/R/examples/src/main/resources/people.json", "json")
>
> # Register this DataFrame as a tabllse.
> registerTempTable(people, "people")
>
> # SQL statements can be run by using the sql method
> teenagers <- sql(sqlContext, "SELECT name FROM people WHERE age >= 13 AND age <= 19")
> head(teenagers)
name
1 Justin
> ## name
> ##1 Justin2.4.11 Machine Learning
> # Create the DataFrame
> df <- createDataFrame(sqlContext, iris)
Warning messages:
1: In FUN(X[[i]], ...) :
Use Sepal_Length instead of Sepal.Length as column name
2: In FUN(X[[i]], ...) :
Use Sepal_Width instead of Sepal.Width as column name
3: In FUN(X[[i]], ...) :
Use Petal_Length instead of Petal.Length as column name
4: In FUN(X[[i]], ...) :
Use Petal_Width instead of Petal.Width as column name
>
> # Fit a linear model over the dataset.
> model <- glm(Sepal_Length ~ Sepal_Width + Species, data = df, family = "gaussian")
>
> # Model coefficients are returned in a similar format to R's native glm().
> summary(model)
$coefficients
Estimate
(Intercept) 2.2513930
Sepal_Width 0.8035609
Species__versicolor 1.4587432
Species__virginica 1.9468169
> ##$coefficients
> ## Estimate
> ##(Intercept) 2.2513930
> ##Sepal_Width 0.8035609
> ##Species_versicolor 1.4587432
> ##Species_virginica 1.9468169
>
> # Make predictions based on the model.
> predictions <- predict(model, newData = df)
> head(select(predictions, "Sepal_Length", "prediction"))
Sepal_Length prediction
1 5.1 5.063856
2 4.9 4.662076
3 4.7 4.822788
4 4.6 4.742432
5 5.0 5.144212
6 5.4 5.385281
> ## Sepal_Length prediction
> ##1 5.1 5.063856
> ##2 4.9 4.662076
> ##3 4.7 4.822788
> ##4 4.6 4.742432
> ##5 5.0 5.144212
> ##6 5.4 5.3852812.5 记录:开始配置不成功:
> library(SparkR)
Error in library(SparkR) : 不存在叫‘SparkR’这个名字的程辑包# Set this to where Spark is installed
Sys.setenv(SPARK_HOME="D:/1win7/java/spark-1.5.2")
# This line loads SparkR from the installed directory
.libPaths(c(file.path(Sys.getenv("SPARK_HOME"), "R"), .libPaths()))
library(SparkR)
sc <- sparkR.init(master="local")
sqlContext <- sparkRSQL.init(sc)
df <- createDataFrame(sqlContext, faithful)
head(df)
print("end")SparkR从集群编译好的地方下载,然后放到本地
> source('D:/all/R/1.R')
Launching java with spark-submit command D:/1win7/java/spark-1.5.2/bin/spark-submit.cmd sparkr-shell C:\Users\xubo\AppData\Local\Temp\RtmpwpZOpB\backend_port2cd416031ca9
Error in sparkR.init(master = "local") :
JVM is not ready after 10 secondsSpark在windows系统中没有转,明天试试编译好的spark
参考:
【1】 http://spark.apache.org/docs/1.5.2/sparkr.html
【2】http://www.csdn.net/article/1970-01-01/2826010
【3】http://files.meetup.com/3138542/SparkR-meetup.pdf
【4】https://github.com/amplab-extras/SparkR-pkg