论文阅读(2)-Toward Real-Time Pedestrain Detection Based on a Deformable Template Model
背景介绍:
作者:Marco Pedersoli ,Jordi Gonzàlez
巴塞罗那自治大学 ,在读博士
IEEE Transactions on Intelligent Transportation Systems
2014.1月
汽车辅助系统:
自动抱闸,安全气囊 (比较成熟)
自动倒车报警
绕过障碍,选择路径(比较复杂)
这篇文章主要是通过安装在车子上的一个简单的摄像头来实现行人检测,与激光雷达相比,普通摄像头更经济,在低档车上会更实用。
现在的人脸识别技术已经很成熟,那行人检测是不是也比较简单可靠了呢?
答案是否定的, 为什么? 1,行人的姿态,外表变化更大。2.对检测性能要求更高,因为误报或漏报产生的后果都很严重
与其他检测的一些不同的地方:
1因为是在道路上进行行人检测,天空等一些部分就可以排除。2视角的一些特性(平的,运动的人由小变大)
特殊要求:实时性和准确性都要很好
之前的一些理论和工作:
1、通过采用多传感器或者立体相机来实现检测
2. 通过检测后用粒子滤波来跟踪
3.通过排除一些区域
4.词袋模型和模板匹配 (虽然词袋模型比较强大,但是要先进行量化,复杂度O(WF),F为特征数,W为词数)
5.可变形目标检测
这篇论文主要有三个贡献点:
1.使用了多分辨率层次表示以及采用粗到精的方法来加速行人检测(2011年他们的另外一篇论文中粗到精的目标检测)
2.介绍了一种针对图像中的尺寸比较小的行人进行检测
3.通过GUP来加速实现
检测系统
步骤:1.计算HOG特征,(改进的HOG特征,经过了PCA)2.CtF进行检测搜索 3.通过非极大值抑制选出最好匹配结果(前1000)
A. CtF进行搜索检测
我们检测每个位置,与用SVM学习到的模板进行点乘
,X=(x,y,s) xy是 位置,s是尺度
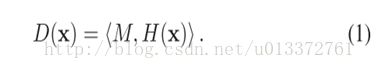
通常来说,精细的特征表示得到的分类器的分辨能力越强。同时模型越复杂。我们如果要用很精细的特征来表示,在进行匹配的时候计算量将会变得很大用CtF的思路就是先最目标进行粗略特征表示得到一些预选结果,然后在此基础上在进一步精细的特征进行匹配
匹配得分为:

我们要注意的是在精细的特征表示的时候不再是整个目标的表示了,我们可以选取某些部分,比如人的头或者手这些局部特征了。
且因为我们在计算精细特征匹配的时候不再是整张图片,而是粗选结果的附近,所以计算量节省了不少。
B。deformations的CtF搜索
显然,加入形变之后,对目标的检测效果会更好,尤其是对行人来说,走动的时候本来就有很多姿势,加入形变可以有效的提高单一模板匹配的不足。然后加入这个形变之后计算量的增加是非常巨大的,有多大?因为要对每个部分都要找到最好的位置。
??有个
广义距离变换法节省计算量 来找到最好的部件??
如下图所示,整体的人的粗略特征表示是一个部件,然后分成中层,是P个部件,再分成更细的部件。与之间的DPM模型有个显著差别是这里是分成P是固定的,也就是在分的时候有可能切过某个真实的人体部分,如从眼睛这里分割了。

于是评价函数变成了如下的:

R是表示的不同的分辨率的层数(第二层是第一层的2倍),p表示的是子部件。这类似一个往下逐渐加深的过程
同时,特征也要发生变化,由一个分界成多个,且上下两层之间有某种关系
具体步骤:
比如在第一层检测到可疑目标,则在其周围寻找 在下一分辨层的最大得分值的目标,(整个还是部件?)应该是整体,然后在这个层面上就应该要检测分部的模糊定位
C、小的行人检测
如果像素比较低的话,则要将目标进行分别出来刚比较困难。
作为小的行人的话就无法同过细层的特征来表达了,因而如果按上面那个累积和的话,其得分就会比较低了,为了应对这个问题,采取如下表示。(想想看,在原来的大图片上要用小的行人的粗模板来匹配,计算量其实也是蛮大的,第一层图片上要匹配了所有的粗模板。)

与之前(4)的差别是特征中多了一项,hr,其值可取0或者1,这个特征可以当成是像素层的特征,表面了该特征在某分辨率下是否有特征值。1表示这层特征有,0表示没有。
其作用是在学习的时候,那些模板小,分辨率高,有高层(高层表示分辨率低的层),没低层的在训练时对应的权重增加。
D。学习
使用SVM学习

这里再加入一个潜在变量?k,表示的是子部件相对于其父部件的位置,于是问题变成了

样本只给定 了正负样本,正样本画好了框,然后通过上面的公式学习模型,部件的模型呢?好像并没有针对具体的部件模型啊。
训练后的模型要放到负样本去继续训练,因为这个模型有可能在负样本中找到一些和其匹配很好的目标,要将这些做为负样本来再一次训练。
实时性
因为之前的目标检测主要用在滑动窗口上(采用的特征比较细),通过这种层次结构后,主要的时间将是用在计算特征上面了。
扫描时间可以降为1/10,而计算特征的计算可以GPU来进行加速(在未列为种子区域时,可以不用计算细层特征吧)
且因为摄像机基本固定,有些部分是不可能有人出现,所以可以排除这些区域。
GPU
设计成并行处理方式,在单指令多线程的结构上进行处理
另外,普通的HOG特征计算是
先规定比如6*6作为一个CELL,然后统计9个方向,行程一个9维的数,然后将4个这样的cell组成一个BLOCK,所以是36维作为一个特征描述。
改进的是?用了对比度敏感和不敏感的方向通道,但是不是对多个归一化而是附加一个归一化特征。最后是31维了
GPU执行

正常应该是计算一层特征,然后送到主机,在进行下一层计算,直到计算完,但是设备到主机的传输很耗时。
所以讲特征计算完之后再传回主机
40层的时候,大概提高10倍的速度
兴趣区域的选择:通过3D定位?这篇论文仅仅丢弃上面三分之一的部分,节省时间30%。
实验
Shog 是simplified HOG
其他的对比表没列出来了,反正是效果很不错啊
总结:
1是用到了CtF来加快图片的扫描
2,加入了形变
3.针对这种比较小的目标的一个策略
总之,感觉论文在想法上和方法上都是对之前的方法的进行一种整合和一些稍微的改进。方法不新奇,算法也不复杂,效果确实还可以。