【目标检测系列】非极大值抑制(NMS)的各类变体汇总
关注上方“深度学习技术前沿”,选择“星标公众号”,
技术干货,第一时间送达!

【导读】前面已经先后为大家详细介绍过了目标检测领域的基础知识:【目标检测基础积累】常用的评价指标 和 目标检测算法基础概念:边框回归和NMS。
所以本文针对目标检测中的NMS作进一步研究,基本的NMS方法,利用得分高的边框抑制得分低且重叠程度高的边框。NMS方法虽然简单有效,但在更高的目标检测需求下,也存在如下缺点:
将得分较低的边框强制性地去掉,如果物体出现较为密集时,本身属于两个物体的边框,其中得分较低的也有可能被抑制掉,降低了模型的召回率。
速度:NMS的实现存在较多的循环步骤,GPU的并行化实现不是特别容易,尤其是预测框较多时,耗时较多。
将得分作为衡量指标。NMS简单地将得分作为一个边框的置信度,但在一些情况下,得分高的边框不一定位置更准。
阈值难以确定。过高的阈值容易出现大量误检,而过低的阈值则容易降低模型的召回率,超参很难确定。
针对这些问题陆续产生了一系列改进的方法,具体有:Soft NMS、Softer NMS、Adaptive NMS、IoUNet等
标准的NMS
首先我们还是来简要回顾一下NMS的算法流程:
标准的NMS流程:
(1)将所有的框按类别划分,并剔除背景类,因为无需NMS。
(2)对每个物体类中的边界框(B_BOX),按照分类置信度降序排列。
(3)在某一类中,选择置信度最高的边界框B_BOX1,将B_BOX1从输入列表中去除,并加入输出列表。
(4)逐个计算B_BOX1与其余B_BOX2的交并比IoU,若IoU(B_BOX1,B_BOX2) > 阈值TH,则在输入去除B_BOX2。
(5)重复步骤3~4,直到输入列表为空,完成一个物体类的遍历。
(6)重复2~5,直到所有物体类的NMS处理完成。
(7)输出列表,算法结束
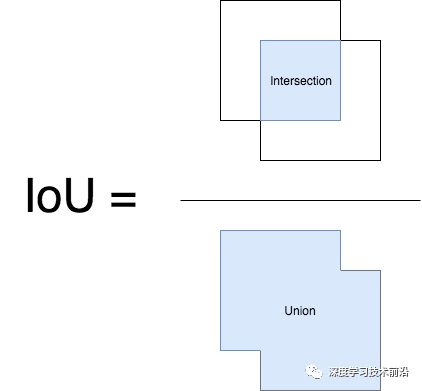
在这里,我们再来回顾一下交并比,并附上它的代码实现:
交并比(Interp over Union)是目标检测NMS的依据,衡量边界框位置,常用交并比指标,交并比(Injection Over Union,IOU)发展于集合论的雅卡尔指数(Jaccard Index),被用于计算真实边界框Bgt(数据集的标注)以及预测边界框Bp(模型预测结果)的重叠程度。IoU是预测框或者是检测结果(DetectionResult)与Ground truth的交集和并集的比值。
交并比的代码实现:
import numpy as np
def compute_iou(box1, box2, wh=False):
"""
compute the iou of two boxes.
Args:
box1, box2: [xmin, ymin, xmax, ymax] (wh=False) or [xcenter, ycenter, w, h] (wh=True)
wh: the format of coordinate.
Return:
iou: iou of box1 and box2.
"""
if wh == False:
xmin1, ymin1, xmax1, ymax1 = box1
xmin2, ymin2, xmax2, ymax2 = box2
else:
xmin1, ymin1 = int(box1[0]-box1[2]/2.0), int(box1[1]-box1[3]/2.0)
xmax1, ymax1 = int(box1[0]+box1[2]/2.0), int(box1[1]+box1[3]/2.0)
xmin2, ymin2 = int(box2[0]-box2[2]/2.0), int(box2[1]-box2[3]/2.0)
xmax2, ymax2 = int(box2[0]+box2[2]/2.0), int(box2[1]+box2[3]/2.0)
## 获取矩形框交集对应的左上角和右下角的坐标(interp)
xx1 = np.max([xmin1, xmin2])
yy1 = np.max([ymin1, ymin2])
xx2 = np.min([xmax1, xmax2])
yy2 = np.min([ymax1, ymax2])
## 计算两个矩形框面积
area1 = (xmax1-xmin1) * (ymax1-ymin1)
area2 = (xmax2-xmin2) * (ymax2-ymin2)
inter_area = (np.max([0, xx2-xx1])) * (np.max([0, yy2-yy1]))#计算交集面积
iou = inter_area / (area1+area2-inter_area+1e-6)#计算交并比
return iouSoft NMS
Soft NMS,只靠改进一行代码,便登上ICCV舞台,其核心思想值得思考,有时候一些比较有创新的细微改动,也可以带来很好的效果。
基本思想->改进基本NMS计算公式
基本NMS计算公式:
公式中Si代表了每个边框的得分,M为当前得分最高的框,bi为剩余框的某一个,Nt为设定的阈值,可以看到,当IoU大于Nt时,该边框的得分直接置0,相当于被舍弃掉了,从而有可能造成边框的漏检。
而SoftNMS算法对于IoU大于阈值的边框,没有将其得分直接置0,而是降低该边框的得分,线性Soft NMS计算方法是:
从公式中可以看出,利用边框的得分与IoU来确定新的边框得分,如果当前边框与边框M的IoU超过设定阈值Nt时,边框的得分呈线性的衰减。
但是,上式并不是一个连续的函数,当一个边框与M的重叠IoU超过阈值Nt时,其得分会发生跳变,这种跳变会对检测结果产生较大的波动。
因此还需要寻找一个更为稳定、连续的得分重置函数,最终Soft NMS给出了如下式所示的重置函数。高斯Soft NMS计算公式:
采用这种得分衰减方式,对于某些得分很高的边框,在后续计算中还有可能被作为正确检测框,而不像NMS那样“一棒子打死”,因此可以有效地提升模型召回率。
Soft NMS代码实现:
def box_soft_nms(bboxes, scores, labels, nms_threshold=0.3, soft_threshold=0.3, sigma=0.5, mode='union'):
"""
soft-nms implentation according the soft-nms paper
:param bboxes: all pred bbox
:param scores: all pred cls
:param labels: all detect class label,注:scores只是单纯的得分,需配合label才知道具体对应的是哪个类
:param nms_threshold: origin nms thres, for judging to reduce the cls score of high IoU pred bbox
:param soft_threshold: after cls score of high IoU pred bbox been reduced, soft_thres further filtering low score pred bbox
:return:
"""
unique_labels = labels.cpu().unique().cuda() # 获取pascal voc 20类标签
box_keep = []
labels_keep = []
scores_keep = []
for c in unique_labels: # 相当于NMS中对每一类的操作,对应step-1
c_boxes = bboxes[labels == c] # bboxes、scores、labels一一对应,按照label == c就可以取出对应类别 c 的c_boxes、c_scores
c_scores = scores[labels == c]
weights = c_scores.clone()
x1 = c_boxes[:, 0]
y1 = c_boxes[:, 1]
x2 = c_boxes[:, 2]
y2 = c_boxes[:, 3]
areas = (x2 - x1 + 1) * (y2 - y1 + 1) # bbox面积
_, order = weights.sort(0, descending=True) # bbox根据score降序排序,对应NMS中step-2
while order.numel() > 0: # 对应NMS中step-5
i = order[0] # 当前order中的top-1,保存之
box_keep.append(c_boxes[i]) # 保存bbox
labels_keep.append(c) # 保存cls_id
scores_keep.append(c_scores[i]) # 保存cls_score
if order.numel() == 1: # 当前order就这么一个bbox了,那不玩了,下一个类的bbox操作吧
break
xx1 = x1[order[1:]].clamp(min=x1[i]) # 别忘了x1[i]对应x1[order[0]],也即top-1,寻找Inp区域的坐标
yy1 = y1[order[1:]].clamp(min=y1[i])
xx2 = x2[order[1:]].clamp(max=x2[i])
yy2 = y2[order[1:]].clamp(max=y2[i])
w = (xx2 - xx1 + 1).clamp(min=0) # Inp区域的宽、高、面积
h = (yy2 - yy1 + 1).clamp(min=0)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
# 经过origin NMS thres,得到高IoU的bboxes index,
# origin NMS操作就直接剔除掉这些bbox了,soft-NMS就是对这些bbox对应的score做权重降低
ids_t= (ovr>=nms_threshold).nonzero().squeeze() # 高IoU的bbox,与inds = np.where(ovr >= nms_threshold)[0]功能类似
weights[[order[ids_t+1]]] *= torch.exp(-(ovr[ids_t] * ovr[ids_t]) / sigma)
# soft-nms对高IoU pred bbox的score调整了一次,soft_threshold仅用于对score抑制,score太小就不考虑了
ids = (weights[order[1:]] >= soft_threshold).nonzero().squeeze() # 这一轮未被抑制的bbox
if ids.numel() == 0: # 竟然全被干掉了,下一个类的bbox操作吧
break
c_boxes = c_boxes[order[1:]][ids] # 先取得c_boxes[order[1:]],再在其基础之上操作[ids],获得这一轮未被抑制的bbox
c_scores = weights[order[1:]][ids]
_, order = c_scores.sort(0, descending=True)
if c_boxes.dim()==1:
c_boxes=c_boxes.unsqueeze(0)
c_scores=c_scores.unsqueeze(0)
x1 = c_boxes[:, 0] # 因为bbox已经做了筛选了,areas需要重新计算一遍,抑制的bbox剔除掉
y1 = c_boxes[:, 1
x2 = c_boxes[:, 2]
y2 = c_boxes[:, 3]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
return box_keep, labels_keep, scores_keep # scores_keep保存的是未做权重降低的score,降低权重的score仅用于soft-nms操作加权平均:Softer NMS
基本思想
来自于NMS时用到的score仅仅是分类置信度得分,不能反映Bounding box的定位精准度,既分类置信度和定位置信非正相关的。
NMS只能解决分类置信度和定位置信度都很高的,但是对其它三种类型:“分类置信度低-定位置信度低”,“分类置信度高-定位置信度低”,“分类置信度低-定位置信度高“都无法解决。
基于此现象,Softer NMS进一步改进了NMS的方法,新增加了一个定位置信度的预测,使得高分类置信度的边框位置变得更加准确,从而有效提升了检测的性能。
论文首先假设Bounding box的是高斯分布,ground truth bounding box是狄拉克delta分布(即标准方差为0的高斯分布极限)。KL 散度用来衡量两个概率分布的非对称性度量,KL散度越接近0代表两个概率分布越相似。
论文提出了一种基于KL(Kullback-Leibler)散度的边框回归损失函数(KL loss),即为最小化Bounding box regression loss - 预测边框分布越接近于真实物体分布,损失越小。既Bounding box的高斯分布和ground truth的狄拉克delta分布的KL散度。直观上解释,KL Loss使得Bounding box预测呈高斯分布,且与ground truth相近。而将包围框预测的标准差看作置信度。
论文提出的Softer-NMS,基于soft-NMS,具体过程与NMS大体相同,只是对预测标注方差范围内的候选框加权平均,使其更精准,在多个数据集上提高了检测边框的位置精度
Softer NMS的实现过程,其实很简单,预测的四个顶点坐标,分别对IoU>Nt的预测加权平均计算,得到新的4个坐标点。第i个box的x1计算公式如下(j表示所有IoU>Nt的box):

可以看出,Softer NMS对于IoU大于设定阈值的边框坐标进行了加权平均,希望分类得分高的边框能够利用到周围边框的信息,从而提升其位置的准确度。
Adaptive NMS
研究背景
为了解决行人检测任务中目标过于密集的问题,本文对soft-NMS又进行了优化,提出了一种自适应的非极大值抑制(Adaptive NMS)的行人检测后处理方法,通过网络预测目标周边的密集和稀疏的程度,采用不同的去重策略。该方法对于双阶段和单阶段的检测器都有效果,在密集行人数据库CityPersons和CrowdHuman上都能提升现有的检测器的效果。本文已被CVPR2019接受为Oral。
Adaptive NMS算法流程:

我们要使得在人群密集的地方,NMS阈值较大,而人群稀疏的地方NMS阈值较小。但是问题在于怎么判断人群是否密集,又怎么根据密集程度定NMS阈值呢?对于第一个问题。。。当然是用CNN啦!于是文章就定义了第i个物体处的密度如下:
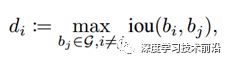
有了密度之后,soft-NMS就改进成了:

其中Nm代表adptive-NMS中M的抑制阈值,dM是M的目标密度
将抑制策略分成三类进行讨论:
(1)当邻框远离M时(即IoU (2)当M处于密集区域时(即Nm>Nt),目标密度dM作为NMS的抑制阈值; (3)当M处于稀疏区域时(即Nm≤Nt),初始阈值Nt作为NMS的抑制阈值。 由于在训练CNN时,每次还需要求出密度作为监督信号,训练网络能够拟合这个密度函数,即输入一张图片,能输出每个位置的物体密度,因此adaptive-NMS保持着greedy-NMS和soft-NMS的效率,还多了一步目标密度的预测,论文设计了一个Density-subnet对目标密度进行回归预测。模型如下: IoU-Net:定位置信度 目标检测的分类与定位通常被两个分支预测。对于候选框的类别,模型给出了一个类别预测,可以作为分类置信度,然而对于定位而言,回归模块通常只预测了一个边框的转换系数,而缺失了定位的置信度,即框的位置准不准,并没有一个预测结果。 定位置信度的缺失也导致了在前面的NMS方法中,只能将分类的预测值作为边框排序的依据,然而在某些场景下,分类预测值高的边框不一定拥有与真实框最接近的位置,因此这种标准不平衡可能会导致更为准确的边框被抑制掉。 基于此,旷视提出了IoU-Net,增加了一个预测候选框与真实物体之间的IoU分支,并基于此改善了NMS过程,进一步提升了检测器的性能。 IoU-Net的基础架构与原始的Faster RCNN类似,使用了FPN方法作为基础特征提取模块,然后经过RoI的Pooling得到固定大小的特征图,利用全连接网络完成最后的多任务预测。 同时,IoU-Net与Faster RCNN也有不同之处,主要有3点: 1. 在Head处增加了一个IoU预测的分支,与分类回归分支并行。图中的Jittered RoIs模块用于IoU分支的训练。 2. 基于IoU分支的预测值,改善了NMS的处理过程。 3. 提出了PrRoI-Pooling(Precise RoI Pooling)方法,进一步提升了感兴趣区域池化的精度。 IoU分支用于预测每一个候选框的定位置信度。需要注意的是,在训练时IoU-Net通过自动生成候选框的方式来训练IoU分支,而不是从RPN获取。 具体来讲,Jittered RoIs在训练集的真实物体框上增加随机扰动,生成了一系列候选框,并移除与真实物体框IoU小于0.5的边框。实验证明这种方法来训练IoU分支可以带来更高的性能与稳健性。IoU分支也可以方便地集成到当前的物体检测算法中。 在整个模型的联合训练时,IoU预测分支的训练数据需要从每一批的输入图像中单独生成。此外,还需要对IoU分支的标签进行归一化,保证其分布在[-1,1]区间中。 由于IoU预测值可以作为边框定位的置信度,因此可以利用其来改善NMS过程。IoU-Net利用IoU的预测值作为边框排列的依据,并抑制掉与当前框IoU超过设定阈值的其他候选框。此外,在NMS过程中,IoU-Net还做了置信度的聚类,即对于匹配到同一真实物体的边框,类别也需要拥有一致的预测值。具体做法是,在NMS过程中,当边框A抑制边框B时,通过下式来更新边框A的分类置信度。 RoI Align的方法,通过采样的方法有效避免了量化操作,减小了RoIPooling的误差,如图下图所示。但Align的方法也存在一个缺点,即对每一个区域都采取固定数量的采样点,但区域有大有小,都采取同一个数量点,显然不是最优的方法。 以此为出发点,IoU-Net提出了PrRoI Pooling方法,采用积分的方式实现了更为精准的感兴趣区域池化,如下图中的右图所示。 与RoI Align只采样4个点不同,PrRoI Pooling方法将整个区域看做是连续的,采用积分公式求解每一个区域的池化输出值,区域内的每一个点(x, y)都可以通过双线性插值的方法得到。这种方法还有一个好处是其反向传播是连续可导的,因此避免了任何的量化过程。 总体上,IoU-Net提出了一个IoU的预测分支,解决了NMS过程中分类置信度与定位置信度之间的不一致,可以与当前的物体检测框架一起端到端地训练,在几乎不影响前向速度的前提下,有效提升了物体检测的精度。 1. https://zhuanlan.zhihu.com/p/117417789 2. https://www.jianshu.com/p/86ce2bf3a013 3. https://mp.weixin.qq.com/s/y5IQNmS5ZuIuafQQeL3nfw 4. https://zhuanlan.zhihu.com/p/68677880 5. https://zhuanlan.zhihu.com/p/78504109 重磅!DLer-目标检测交流群已成立! 为了能给大家提供一个更好的交流学习平台!针对特定研究方向,我建立了目标检测微信交流群,目前群里已有百余人!本群旨在交流目标检测、密集人群检测、关键点检测、人脸检测、人体姿态估计等内容。 进群请备注:研究方向+学校/公司+昵称(如目标检测+上交+小明) ???? 长按识别添加,邀请您进群! 原创不易,在看鼓励!比心哟!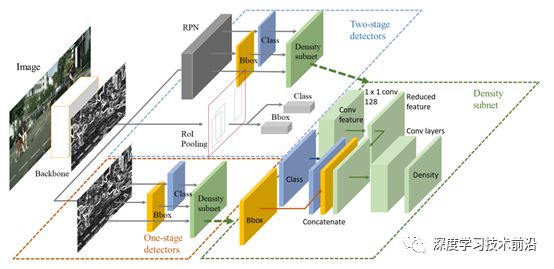
研究背景介绍

IoU预测分支
基于定位置信度的NMS

PrRoI-Pooling方法


参考链接:


