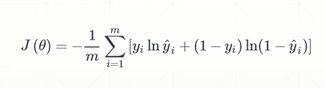过拟合与欠拟合
文章目录
-
-
- 1. 什么是过拟合与欠拟合
-
- 欠拟合(underfitting):
- 过拟合(overfitting):
- 2. 如何验证overfitting
- 3.如何避免overfitting
-
- ①more data
- ②constraint model complexity
- ③dropout
- ④data argumentation
- ⑤early stooping
-
1. 什么是过拟合与欠拟合
欠拟合(underfitting):
模型的表达能力 < 真实的复杂度,train acc.(train loss) 和 test acc.(test loss) 都不能令人满意。
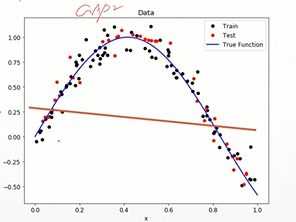
过拟合(overfitting):
模型的复杂度 > 真实的复杂度,即为了让loss更低,从而靠近每一个数据点,train acc.(train loss) 会特别好,但是 test acc.(test loss)会特别差且泛化能力差。
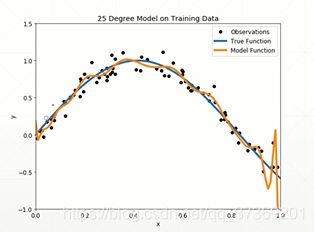
三种模型示例:
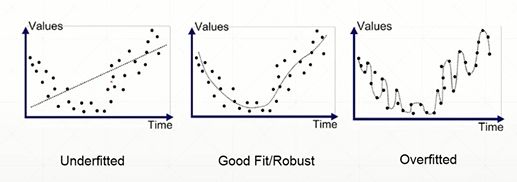
2. 如何验证overfitting
方法一:划分数据集为train set和test set
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
#测试以选择模型参数,提前终止training,来防止overfitting
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28 * 28)
logits = forward(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
logits = forward(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
方法二:更常用的方法是把数据集划分为三部分:train set 、val set和test set
print('train:', len(train_db), 'test:', len(test_db))
train_db, tval_db = torch.utils.data.random_split(train_db, [50000, 10000])
print('db1:', len(train_db), 'db2:', len(val_db))
train_loader = torch.utils.data.Dataloader(
train_db,
batch_size = batch_size,shuffle = True
)
val_loader = torch.utlis.data.Dataloader(
val_db,
batch_size = batch_size, shuffle = True
)
3.如何避免overfitting
①more data
②constraint model complexity
方法一:当数据集有限的时候,不用选太深的、表达能力太强的模型。
方法二:regularization