计算机如何“看懂”图片?达摩院提出新的研究方法
简介: 本文的部分内容基于英文论文"Learning in the frequency domain"翻译而来,英文论文已经被计算机视觉顶级会议Computer Vision and Pattern Recognition (CVPR) 2020接收。该论文的公开链接为:https://arxiv.org/abs/2002.12416
近年来,基于深度神经网络的机器学习方法在计算机视觉上获得的巨大的成功。我们现在应用的主流的深度神经网络都基于对空间域信号的处理和分析,即图像或视频的RGB信号。我们知道,现有的图像视频分析系统由多个模块组成。例如,实时图像分析系统由图像获取(capture),图像压缩(compression),图像传输(transmission),图像解压缩(decompression),图像推理(inference)组成。而对于非实时的图像分析系统,这些保存在存储中的图像已经经过压缩,因此需要经过解压缩和图像推理的模块。以实时图像分析系统为例,这个系统整体的性能(包括延时,功耗,精度等)取决于其中每一个模块的性能。以往的瓶颈来自于图像推理引擎,因为其中包含了非常大规模的计算量。由于这些计算具有结构性和并行度的特征,近年来在GPU和人工智能专用芯片的帮助下,图像推理引擎的性能得到了极大的提升。
因此,图像压缩/解压缩在整个系统中的占比会越来越大。例如在Figure 1中,我们看到在一个GPU的系统中图像处理的时间占比已经大约为图像推理(inference)的两倍之多[1]。这篇文章介绍图像分析系统的基本组成,以及我们如何利用频域特征来进行图像推理,从而省略频域到空间域的转换,因为这个转换是图像压缩/解压缩中计算量最大的步骤。同时我们可以在频域选择重要的信息,进一步减少系统中模块之间的数据传输量。因为模块之间的数据带宽往往远小于模块内部的数据带宽,减小模块间的数据传输量便可以提升整个系统的性能。
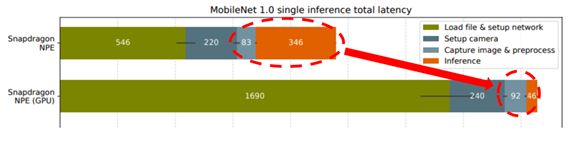
Figure 1. Latency breakdown in a single inference
本文的主要贡献如下:
第一,我们提出了一种系统方法可以在基本不改变现有的卷积神经网络(如ResNet,MobileNet等)的前提下做基于频域的机器识别。
第二,由于基于频域的机器识别可以在不增加计算量的前提下,接受空间域尺寸更大的图片,因此提高了图像识别的精度。
第三,我们提出了一种系统方法来区分每个频域分量对于机器学习的重要性,并且发现仅有很少部分的频域分量实际上对机器学习有贡献。
第四,之前基于频域的机器学习只完成了单一物体的图像分类 (single object recognition),我们首次将基于频域的机器学习扩展到了图像的物体检测(object detection)和语义/实例分割(instance segmentation)任务中,通常物体检测和语义/实例分割被定义为高级视觉(High level vision) 任务。
本文的概要如下:
第一部分我们介绍了一个传统图像分析系统的基本框架,并分析的这个系统中计算量的瓶颈位置。
第二部分我们介绍了在频域实现机器学习的系统方法,以及我们提出了一种基于Gumbel softmax开关的选择频率信息重要性的方法。
第三部分我们介绍了利用我们提出的方法在频率域做图像分类(image classification)和实例分割(instancesegmentation)的结果。
1. 图像传输/存储/分析系统的基本框架

Figure 2. A framework for image transmission and analysis
Figure 2描述了一个实时图像分析系统的框架。图像输入(In)通常是RGB的空间域信号,在编码端经过RGB-to-YCbCr的转化,离散余弦变换(DCT),量化(Quantization), 以及熵编码(Entropy coding),得到压缩后用来传输的信号。这个信号传输到解码端,经过对应的熵解码(Entropy decoding),反量化(dequantization),逆离散余弦变换(IDCT),YCbCr-to-RGB转化得到原图像的重建图像。这个基于RGB空间域的重建图像作为深度神经网络的输入,经过分析可以得到所需要的结果。以下我们简要介绍以上这些操作,并分析它们的计算复杂度。
1.1 YCbCr-RGB conversion
YCbCr(有时也称YUV)是一系列表示图像/视频的色彩空间(color space)。通常RGB color space中三个通道的信号强相关,同时很难说明其中哪一个通道的信号更重要。YCbCr信号是RGB信号的一个点对点的可逆线性变换,其中Y信号表示的是亮度(luma)信息,而Cb和Cr表示的是色彩(chroma)信息(seeFigure 3)。对于人类的视觉系统,亮度信息比色彩信息更重要,因此我们可以通过不同的压缩方法来达到最佳的压缩性能。例如对Cb和Cr通道进行降采样。由于YCbCr和RGB信号的转换是point-wise linear,所以所需的计算量相对较小。

Figure 3. Conversion from RGB to YCbCr
1.2 Discrete cosine transform(DCT) and inverse discrete cosine transform (IDCT)
离散余弦变换是一种二维的可逆线性变换,它将呈现出图像不同的频率信息。以一个8x8的图像为例,它的二维DCT信号矩阵包含了直流分量(通常是(0,0)号元素), 低频信号分量,以及高频信号分量。从Figure 4中可以看到,直流分量衡量了这个信号整体的幅度,而两个方向上不同的分量分别衡量了这个二维信号在x方向和y方向上不同的震荡频率。由于DCT(以及IDCT)是矩阵变换,而通常的图像压缩标准使用的是8x8的DCT变换,所需的计算量占据的整个压缩系统中的大部分。

Figure 4. Coefficients in a discrete cosine transform
1.3 Quantization
量化模块将信号由浮点数floating-point转换为整型表示。它对DCT变换后的对应位置的信号进行point-wise的量化。量化模块所需的计算量因此也相对较小,和矩阵的尺寸成正比。由于人类视觉系统对低频信号比较敏感,因此量化矩阵的左上角数字相对比较小。Figure 5展示了一个量化矩阵的例子。由于量化的操作是不可逆的操作,因此量化模块是图像压缩传输系统中有损的操作。
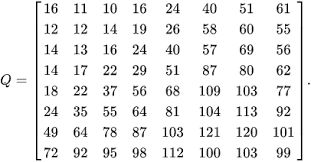
Figure 5. A quantization table for JPEG
1.4 Entropy coding
传输所需的信号是一维信号,而我们经过量化的信号是二维信号,因此我们首先通过Zig-zag的方式将二维信号转换为一位信号(see Figure 6)。由于量化矩阵中高频信号的量化间隔较大,因此许多信号矩阵中对应高频,也就是对应一维信号中靠后位置的信号将被量化为0. 这个一维信号经过Run length coding [2](see Figure 7)和Huffman coding [3](在视频压缩中会有更复杂的Arithmetic coding [4] 以及Context-adaptive binaryarithmetic coding [5])被压缩成为用来传输/存储的信号. Entropy coding基于很成熟的算法和加速结构,所需的计算量也较小,和图像矩阵的尺寸称正比。由于Zig-zag转换和Entropy coding都是可逆的,因此这个模块也是无损的。
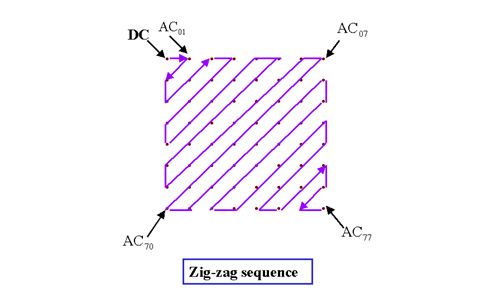
Figure 6. A zig-zag serialization from 2D to 1D
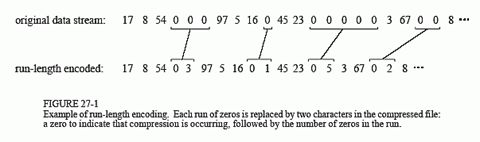
Figure 7. An example of run-length coding
以上各个模块在解码端都可以用对应的逆模块(inverse module)来实现,同时这些逆模块的计算复杂度和编码端对应的模块基本一致。
通过以上的介绍我们可以看出,在整个图像分析系统中,除去最后的图像推理(inference)引擎,前期的压缩,传输,解压缩的瓶颈在于其中的DCT和IDCT模块,因为这两个变换是矩阵变换,而其他的操作基本都是point-wise的操作。我们知道矩阵变换的计算复杂度远大于点变换的计算复杂度,因此如果我们能够减少,甚至省略这两个模块,将会对图像分析系统的前半部分带来极大的性能提升。
2. 基于频域信息的机器学习
在解码端,传统的图像传输系统使用IDCT将频域信号转换为空间域信号的目的是为了让人类视觉系统服务的。然而,在机器学习任务中,我们可以思考是否需要做IDCT这个对计算量需求较大的操作。如果我们可以省略IDCT的模块,我们就可以减少解码端的延时和功耗(see Figure 8)。

Figure 8. A framework of image transmission and analysis directly from the frequency domain.
我们面临两个问题,第一,我们如何利用频域的信息来进行机器学习,即如何将重建出的DCT的信号接入合适的深度神经网络。第二,我们如何利用不同频域信号的重要性来节省从解码端到图像推理引擎所需的带宽(see Figure 9)

Figure 9. A framework of image transmission and analysis from selected frequency component to reduce memory bandwidth between decoder and AI engine.
2.1 如何利用频域的信息来进行机器学习
首先考虑亮度通道(Y channel)。假设我们使用图像压缩标准中默认的8x8作为块的尺寸(blocksize)。对于每一个块(block),我们会得到64个DCT的信号,对应了64个不同的频率分量。如果我们原始的图像的尺寸是W x H, 那么我们将会有W/8 x H/8 个DCT信号组成的块。每个块中相同位置的频率分量可以组成一个尺寸为W/8 x H/8的特征图片(feature map),这样我们会产生8x8=64个feature map。同样的对于Cb和Cr通道,我们也可以各自产生64个feature map。总共产生了64x3=192个feature map,这个过程如Figure 10(a)所示。假设W=H=448, 那么现有的基于频域的feature map的尺寸为56x56x192。现在的问题是如何将这些feature map合理的输入到一个已有的DNN网络结构中,使得feature map的尺寸和已有DNN网络的尺寸吻合。

Figure 10 (a). The data pre-processing pipeline for learning in the frequency domain
为了便于理解,我们以ResNet-50作为基础的图像分类举例。ResNet-50通常接受的图片输入尺寸为224x224. 在经过一次convolutional layer (stride=2)和pooling之后,此时网络的feature map的尺寸为56x56,和我们产生的频率信号的feature map尺寸吻合。我们可以将192个56x56的频域feature map全部或者部分直接接在ResNet-50的第一个Residue Block之前,从而达到不改变ResNet-50的结构而实现从频域做机器识别的目的。如果我们从192个feature map中选取的64个,则和一个标准的ResNet-50在这一层的feature map个数相同,则网络结构和ResNet-50达到了完全一致。这个过程如Figure10(b)所示。值得注意的是,由于我们做了8x8的DCT变换,我们实际输入的图片大小为448x448,是标准ResNet-50输入(224x224)的两倍。正因为我们提高了输入图片在空间域的分辨率,我们在后续的实验中可以得到更好的识别精度。
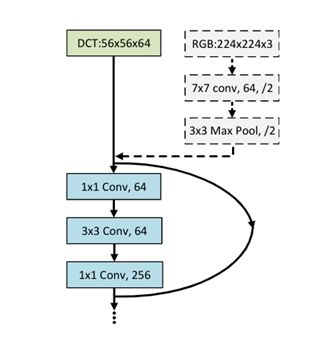
Figure 10 (b). Connecting the pre-processed input features in the frequency domain to ResNet-50. The three input layers (the dashed gray blocks) in a vanilla ResNet-50 are removed to admit the 56×56×64 DCT inputs.
2.2. 频域信息重要性提取
图像压缩理论的基础是人眼对于不同色彩空间和频率分量有不同的敏感度,因此我们可以对Cb,Cr通道降采样,也可以对每个DCT信号中高频分量设置更大的量化区间。然而,我们对于这些频率分量对于机器学习的重要性并不了解。如果我们可以忽略掉其中不重要的feature map,就可以不用将这部分数据从图像解码模块传输到图像推理引擎中,从而节省这部分可能成为瓶颈的带宽。
我们现在面临的问题是如何在这192个feature map中做出选择。类比人类视觉系统,在这192个feature map中,我们能否猜想Y通道和低频分量对应的feature map似乎更重要?如果是这样的话,我们如何确定Y通道中应该选择多少个feature map,而CbCr通道有应当选择多少个feature map?在这一部分,我们提出了利用机器学习中添加gate的方法来学习每一个feature map的重要性。在训练中,不仅图像推理的DNN中的weights被训练出来,同时每一个feature map的重要性也被确定。

FIgure 11. A gating method to select important frequency components
Figure 11展示了利用gate来选择重要的feature map的方法。原始所有频率分量组成的feature map的尺寸为WxHxC,其中C代表了feature map的个数,正如我们前面介绍的那样,在实验中使用的是C=192. 每个feautre map通过average pooling将会生成一个1x1xC的特征向量,其中每个数值代表了对应feature map。这个特征向量通过一个fully connected layer生成一个1x1xCx2的特征向量对。每一对数字表示这个对应的feature map是否重要,如果index为0的数字比index为1的数字更大,那么这个feature map被认为不重要,整个feature map将会被忽略而不参与后续DNN的计算;反过来说,如果index为1的数字比index为0的数字更大,那么这个feature map被认为重要,将会参与后续DNN的计算。这个操作等效于使用了一个开关(gate)来控制每一个频率信息组成的feature map是否流通到后续的计算中。
具体而言,由于我们使用了argmax函数来选择更大的index进而表示feature map是否被选择参与计算,我们需要一种特殊的方法在训练中将gradient传播到这C个开关的控制网络中。这种方法名为Gumbel-softmax [7]。
由于频率分量对应的开关被选为通过的数量决定了输入DNN的数据带宽,我们把选择为通过的开关的比例作为loss function中的一项,另一项就是对应机器学习任务中原始的loss。通过最小化loss function来实现机器学习任务精度和输入DNN数据带宽的平衡。
现在我们拥有了选择重要的feature map的方式,我们有两种方案来减少从图像解码模块到图像推理引擎的数据带宽,这两种方式我们称之为动态(Dynamic)方式和静态(Static)方式。
所谓动态方式,就是每一个频率分量的选择开关由当前输入的图像决定,这种方法可以自适应每一次图像推理(inference)的不同输入。由于选择开关的网络十分简单,我们可以将其放在图像解码模块中。这样从图像解码模块到图像推理引擎之间只需要对被选择的频率分量对应的feature map进行数据传输,可以极大的减少这两个模块之间的带宽需求(see 3rdrow in Figure 12)。
所谓静态方式,就是我们通过训练(training)得到最重要的一些频率分量。在做图像推理(inference)的时候,我们事先就确定只用这些事先确定好的频率分量对应的featuremap,而不会根据不同的图像进行自适应选择。这种静态方式在inference的时候无需选择开关的网络。这种方式不仅可以节省图像解码模块到图像推理引擎的带宽,还可以在编码模块中忽略不重要的频率分量,进而减少图像编码的计算量,延时,以及网络传输的带宽(see 4th row in Figure 12)。值得一提的是,通常网络传输的带宽远小于机器内部组件之间的带宽。

Figure 12. Comparisons of image transmission and analysis system
3. 结果展示
为了演示基于频率分量的机器学习系统和方法,我们选取了两个有代表性的机器学习任务,即图像分类(image classification)和实例分割(instancesegmentation)。
3.1 Image Classification
图像分类的任务是对给定的图像进行类别的区分。我们使用ImageNet作为数据集,其中包括大约128万张训练图像和5万张测试图像,总共1000个类别。我们使用了ResNet-50 [8] 和MobilenetV2 [9]作为DNN的网络结构。MobilenetV2使用了depth-wise convolution的方式,极大的减少了深度神经网络的计算量和网络的参数量。因此MobilenetV2有很大的潜力作为移动端图像推理引擎。
经过我们的训练,我们得到了一张不同频率分量重要性的Heat map。Figure 13描述了对应192个频率分量的重要性程度。我们可以看出,和我们直觉一致的是,Y通道的重要性高于Cb和Cr通道,同时低频分量的重要性高于高频分量。利用我们提出的gated方法,我们可以通过一次训练就了解该如何分配带宽资源。以Figure 13为例,我们可以使用14个Y通道,5个Cb通道5个Cr通道,共计24个feature map来做图像分类的任务,而不用将最初的192个feature map的数据都从图像解码模块传输到图像推理引擎中。这样我们的传输带宽需求降低为原来的八分之一,而推理的精度(accuracy)反而从标准ResNet-50的75.78%提升至77.196% (see DCT-24 in Table 14 (a))。同样的,在MobileNetV2的实验中,我们通过选取最重要的24个频率分量,得到的识别精度从标准MobileNetV2的71.702%提升至72.364% (see DCT-24 in Table 14(b) ). 其它的结果,例如选取64,48,12,6个频率分量的精度也展现在Table14中。值得一提的是,根据Figure 13的展示,我们发现低频分量在识别中相对重要,因此我们也尝试了使用heuristic的方式,选取了一个上三角的区域。例如对于DCT-24,我们直觉选取的是Y channel的[0-13],Cb和Cr channel的[0-4]编号的频率分量。这些频率分量和Figure 13中的heatmap略有不同,但是识别的精度几乎没有区别 (See DCT-64T, DCT-48T, and DCT-24T in Table 14(a) )。这说明我们并不需要对于每个不同的任务都尝试首先获得heatmap,然后严格的按照heatmap来选取频率分量。我们直观上可以选择低频分量(例如这些上三角得到区域),达到和严格按照heatmap选择相同的精度。

Figure 13. A heat map of different frequency components being used in image classification tasks (a) and instance segmentation tasks (b)
(a)

(b)
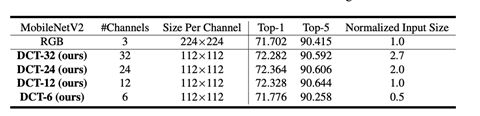
Table 14. Accuracy comparison for image classification from RGB and DCT domain using ResNet-50 (a) and MobileNetV2 (b)
3.2 Instance segmentation
实例分割(instance segmentation)结合了物体检测(object detection) 和语义分割(semanticsegmentation)的需求,它的任务是检测出图像中的每个物体对应的像素点,同时将每一个检测出的物体分类。如Figure 15所示,实例分割任务需要检测出物体(例如,人,足球)的boundingbox,还需要在这个bounding box中将属于该物体的像素标注出来。

Figure 15. An example of instance segmentation (from selected frequency domain)
我们使用了COCO的数据集,其中包含了约10万张训练图像和5千张测试图像。我们使用了Mask RCNN [10]作为深度神经网络结构。Mask RCNN首先会检测出物体的bounding box,然后在bounding box内部的每个像素做二分,确定其是否属于该物体。
Table 16展示了我们在DCT频域做物体识别和实例分割的精度对比。可以看到,从频域做这两个任务,我们可以提升大约0.8%的精度(37.3%到38.1% 以及 34.2%到35.0%)。

(a)

(b)
Table 16. Accuracy comparison from RGB and DCT domain on object detection (a) and instance segmentation (b)
以下是另外几个利用在频域选择重要的feature map做实例分割的visual demo。




4. 未完成的工作以及思考
4.1 Figure 12展示了Dynamic和Static两种选取频率分量feature map的方式,现阶段我们使用的是dynamic的方式,主要考虑的因素是static的方式需要对压缩编码端进行修改才能实现编码端的性能提升和信道带宽节省。这部分改变将会需要视频获取设备的改动,而这通常不是我们集团可以控制的部分。我们相信作为这个方向有很大的研究价值,它可以对图像编码标准进行优化。
4.2 现有的实验均基于图像的压缩传输系统。下一步我们的目标是对视频压缩系统做类似的尝试。由于视频压缩标准中包含了帧间运动预测/补偿和帧内预测,对应的频域信息也会有比较大的差别。
4.3 通过我们利用频域信息来做机器学习的研究,我们的思考是:机器学习的目标和人眼观测图像/视频的方式不同,什么样的信息才是对于机器学习更友好,更有用的信息呢?传统的机器学习算法的输入都是空间域的RGB图像,然而我们是否可以设计更适合机器学习的特征来过滤掉空间域冗余的信息,从而真正做到节省解码端到推理引擎间的数据带宽。
Acknowledgement
本文的工作基于实习生Kai Xu在阿里巴巴达摩院实习期间的研究以及和Prof. Fengbo Ren (Arizona State University)的合作。在这个工作中,我们十分感谢来自于计算技术实验室其他同学许多重要的建议和意见。
Reference
[1] Jussi Hanhirova, Teemu Kämäräinen, Sipi Seppälä, Matti Siekkinen, Vesa Hirvisalo, Antti Ylä-Jääski, Latency and throughput characterization of convolutionalneural networks for mobile computer vision, In Proceedings of the 9th ACM Multimedia Systems Conference,MMSys ’18, pages 204–215, New York, NY, USA, 2018. ACM.[2] Robinson, A.H.; Cherry, C. (1967). "Results of a prototype television bandwidthcompression scheme". Proceedings of the IEEE. IEEE. 55 (3): 356–364. doi:10.1109/PROC.1967.5493
[3]Huffman, D. (1952). "A Method for the Construction ofMinimum-Redundancy Codes" (PDF). Proceedings of the IRE. 40 (9): 1098–1101. doi:10.1109/JRPROC.1952.273898.
[4]MacKay, David J.C. (September 2003). "Chapter6: Stream Codes". Information Theory, Inference, and LearningAlgorithms.Cambridge University Press. ISBN0-521-64298-1. Archived from the original (PDF/PostScript/DjVu/LaTeX)on 22 December 2007. Retrieved 30 December 2007.
[5]Marpe, D., Schwarz, H., and Wiegand, T., Context-Based Adaptive Binary ArithmeticCoding in the H.264/AVC Video Compression Standard, IEEE Trans. Circuits andSystems
[6]Lionel Gueguen, Alex Sergeev, Ben Kadlec, Rosanne Liu, and Jason Yosinski. Fasterneural networks straight from JPEG. In S. Bengio, H. Wallach, H.Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances inNeural Information Processing Systems 31, pages 3933–3944. Curran Associates,Inc., 2018
[7]E. Jang, S. Gu, and B. Poole. Categorical reparameterization withgumbel-softmax. arXiv preprint arXiv:1611.01144, 2016.
[8]K. He, X. Zhang, S. Ren, J.Sun, Deep Residual Learning for ImageRecognition, arXiv:1512.03385, 2015
[9]M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen. Mobilenetv2:Inverted residuals and linear bottlenecks. CVPR, 2018.
[10]K. He, G. Gkioxari, P. Dollar, and R. Girshick. Mask R-CNN. arXiv:1703.06870, 2017.