COUNT(ROWID), COUNT(1),COUNT(*),COUNT(主键),COUNT(非索引字段) 区别
COUNT(ROWID), COUNT(1),COUNT(*),COUNT(主键),COUNT(非索引字段) 区别
COUNT() 用于返回括号中非NULL值的累计数,在书中或网上经常看到些提示,建议不要使用 count(*)而应使用 count(1)或count(rowid)忧化性能,因为count(*)会全表扫描 (我自己手上就有这样一本, 《Oracle Database 11g SQL 开发指南》 Jason Price 著 史新元 北英 译 清华大学出版社出版,P110),所以我一直都是信的,直到今天。
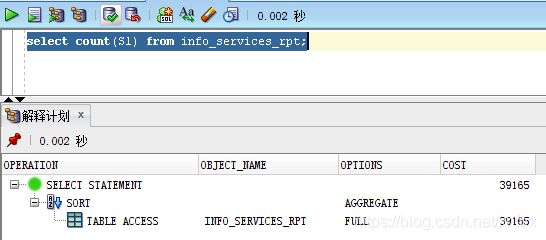
首先看一下各种方法的执行计划:
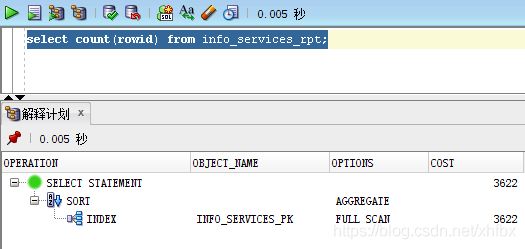
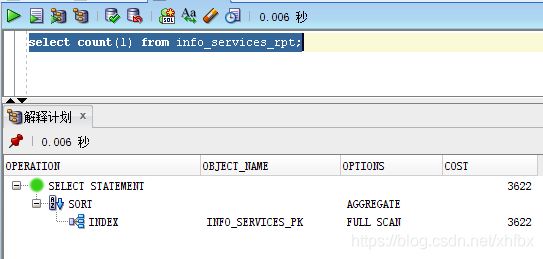
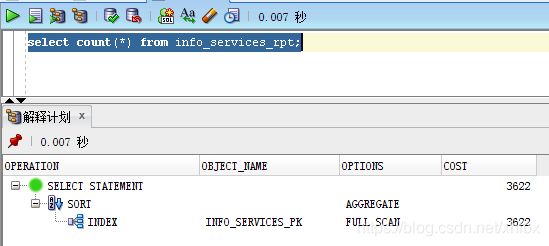

其中 count(rowid) , count(1) ,count(*), count(result_key) 都是走索引 //result_key 是主键字段
而 count(S1) 全表扫描 //S1 非索引字段
为了检查它们的速度,写如下代码:
set serveroutput on
declare
s number; e number;
t1 number; t2 number; t3 number; t4 number; t5 number;t6 number;
x int; q int;
begin
t1:=0;t2:=0;t3:=0;t4:=0; t5:=0;t6:=0;
for x in 1..3 loop
dbms_output.put_line('开始第 '|| x ||' 轮');
s:=dbms_utility.get_time();
select count(rowid) INTO q from info_services_rpt;
e:=dbms_utility.get_time();
t1:=t1+(e-s);
dbms_output.put_line('count(rowid) 获取数量:' || q ||' 耗时:' || (e-s));
s:=dbms_utility.get_time();
SELECT count(1) INTO q FROM INFO_SERVICES_RPT;
e:=dbms_utility.get_time();
t2:=t2+(e-s);
dbms_output.put_line('count(1) 获取数量:' || q ||' 耗时:' || (e-s));
s:=dbms_utility.get_time();
SELECT count(*) INTO q FROM INFO_SERVICES_RPT;
e:=dbms_utility.get_time();
t3:=t3+(e-s);
dbms_output.put_line('count(*) 获取数量:' || q ||' 耗时:' || (e-s));
s:=dbms_utility.get_time();
SELECT count(RESULT_KEY) INTO q FROM INFO_SERVICES_RPT;
e:=dbms_utility.get_time();
t4:=t4+(e-s);
dbms_output.put_line('count(RESULT_KEY) 获取数量:' || q ||' 耗时:' || (e-s));
s:=dbms_utility.get_time();
SELECT count(s1) INTO q FROM INFO_SERVICES_RPT;
e:=dbms_utility.get_time();
t5:=t5+(e-s);
dbms_output.put_line('count(S1) 获取数量:' || q ||' 耗时:' || (e-s));
s:=dbms_utility.get_time();
select count(rowversion) INTO q from info_services_rpt;
e:=dbms_utility.get_time();
t6:=t6+(e-s);
dbms_output.put_line('count(rowversion) 获取数量:' || q ||' 耗时:' || (e-s));
dbms_output.put_line(' ');
end loop;
dbms_output.put_line('count(rowid) 平均耗时:' || (t1/3));
dbms_output.put_line('count(1) 平均耗时:' || (t2/3));
dbms_output.put_line('count(*) 平均耗时:' || (t3/3));
dbms_output.put_line('count(RESULT_KEY) 平均耗时:' || (t4/3));
dbms_output.put_line('count(S1) 平均耗时:' || (t5/3));
dbms_output.put_line('count(rowversion) 平均耗时:' || (t6/3));
end ;
//S1 是表中靠前字段 rowversion是表尾字段
结果:
开始第 1 轮
count(rowid) 获取数量:8339447 耗时:4861
count(1) 获取数量:8339447 耗时:4616
count(*) 获取数量:8339447 耗时:4604
count(RESULT_KEY) 获取数量:8339447 耗时:4608
count(S1) 获取数量:4062970 耗时:4345
count(rowversion) 获取数量:275 耗时:4429
开始第 2 轮
count(rowid) 获取数量:8339447 耗时:4907
count(1) 获取数量:8339447 耗时:4777
count(*) 获取数量:8339447 耗时:4605
count(RESULT_KEY) 获取数量:8339447 耗时:5084
count(S1) 获取数量:4062970 耗时:4539
count(rowversion) 获取数量:275 耗时:4511
开始第 3 轮
count(rowid) 获取数量:8339447 耗时:4680
count(1) 获取数量:8339447 耗时:5045
count(*) 获取数量:8339447 耗时:4670
count(RESULT_KEY) 获取数量:8339447 耗时:4635
count(S1) 获取数量:4062970 耗时:4393
count(rowversion) 获取数量:275 耗时:4580
count(rowid) 平均耗时:4816
count(1) 平均耗时:4812.666666666666666666666666666666666667
count(*) 平均耗时:4626.333333333333333333333333333333333333
count(RESULT_KEY) 平均耗时:4775.666666666666666666666666666666666667
count(S1) 平均耗时:4425.666666666666666666666666666666666667
count(rowversion) 平均耗时:4506.666666666666666666666666666666666667
在平均耗时中可以看到 count(rowid),count(1),count(*),count(RESULT_KEY) 相差并不多
(跟执行顺序也是有关系的)
但count(S1)、与count(rowversion)就有些意思了,count(S1)的平均耗时最少,而且在每一轮中都比其它方法耗时少,但解释计划中 count(S1) 是全表扫描,理论上最慢的啊。
但在看到获取数量时,发现 count(S1) 获取数量:4062970 ,count(*) 获取数量:8339447 ,少了一倍,跟这有关?难道 count 是这样工作的
Class count(){
IF 字段值 IS NOT NULL THEN
计数器++
}
因为 S1 中有只有一半的值非NULL,所以不用去执行 计数器++ ,所以节约时间?
为了证实,将所有S1填充
UPDATE info_services_rpt SET S1='A';
再跑一下时间,结果:
count(S1) 获取数量:8339447 耗时:40667
时间多了近十倍,说明想法是对的
还有一个问题,在第三轮结果中,count(rowversion)比count(S1)数量少,但耗时反而多呢,其实这是因为列的偏移量决定性能,列越靠后,访问的开销越大。在这个测试表中,字段是有一百多个的,而S1在第四个,rowversion 在最后一个,所以虽然rowversion字段值中非NULL值少,但一样也慢啊。