腾讯AI Lab语音技术中心应用与研究介绍

“CCF语音对话与听觉专业组走进企业系列活动”第十期之“走进腾讯”研讨会于上周六圆满闭幕,本次研讨会由上海交通大学钱彦旻副教授主持,并邀请到四位专家介绍腾讯语音及对话领域的最新成果,分别是:
腾讯AI Lab语音技术中心副总监苏丹博士,腾讯AI Lab资深算法专家卢恒博士,腾讯语言算法专家黄申博士,腾讯多媒体实验室高级总监商世东。
其中,腾讯 AI Lab语音技术中心副总监苏丹博士作了题为《腾讯AI Lab语音技术中心应用与研究介绍》的学术报告,主要介绍了腾讯AI Lab语音技术中心的主要应用落地,分享了近期在多个方向包括阵列前端,语音识别,语音分离及多模态交互技术方面研究进展,预告下半年即将对业界开放的语音技术工具平台PiKa和一套大规模多模态数据集。

腾讯AI Lab是腾讯的企业级AI实验室,于2016年4月在深圳成立,目前在中国和美国有100多位顶尖研究科学家及300多位应用工程师。借助腾讯丰富应用场景、大数据、计算力及一流人才方面的长期积累,AI Lab立足未来,开放合作,致力于不断提升AI的认知、决策与创造力,向“Make AI Everywhere”的愿景迈步。
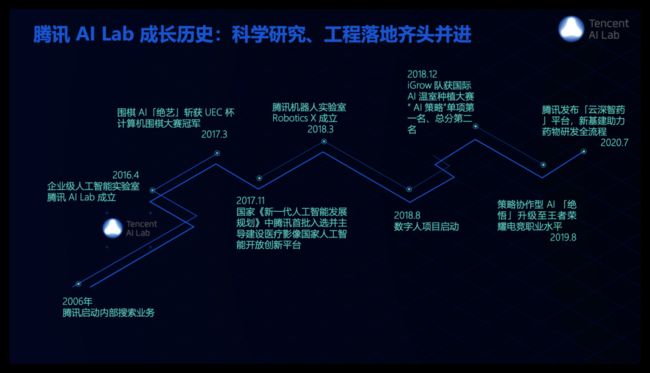
腾讯AI Lab强调研究与应用并重发展,基础研究关注机器学习、计算机视觉、语音识别及自然语言处理等四大方向,技术应用聚焦在社交、游戏、内容与医疗AI四大领域。在语音技术方向,我们也在积极探索前沿的技术。在近年来语音会议上保持较多的论文发表,覆盖语音各个技术方向,当然其中也有一些是跟院校老师合作的工作。

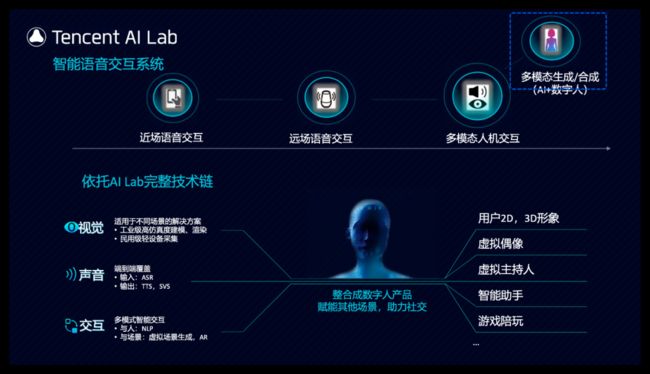
我们看到近些年来,语音交互形态不断延展,大的发展脉络比较清晰,主要是由近场语音交互拓展为远场语音交互,再进一步到多模态人机交互,新的形态产生并不意味着原来形态的问题都已经解决,而是原来的应用场景依然在扩大并且面向更难更复杂的问题不断改进。我们主要也是沿着这条主线持续推进研究与应用的工作,我们在17到18年前后建立起了完整的覆盖整个近场和远场语音交互技术链条并实现了落地。
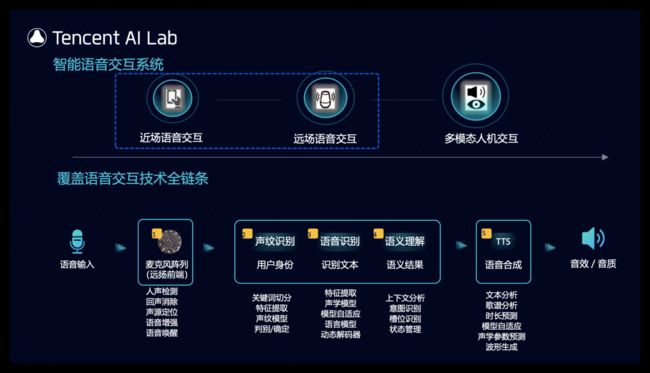
在智能硬件方面,在17到18年前后,我们建立了自主研发的前端系统,覆盖了多种阵列类型,(包括2麦,4麦,6麦,环形,线型等不同阵列形态);从麦克风硬件设计到远场信号增强,语音唤醒及识别、合成的全栈能力,支持了腾讯内部多款自研智能音箱,电视及车载产品;在智能音箱方面:比如早期的腾讯听听,还有腾讯叮当带屏音箱,腾讯叮当智能屏获得信通院智能化等级评级L7级认证,成为目前获得智能化评价级别最高的产品之一。王者机器人音箱是一款有特色的音箱,不但具有游戏角色的外形,与游戏后台联通,在玩家打游戏的过程中可以智能指导,智能陪玩。

在智能电视方面:我们联合腾讯视频,对内支持了企鹅极光智能盒子,对外支持了索尼,飞利浦等多款高端机型20-21年搭载AI Lab远场语音交互能力。
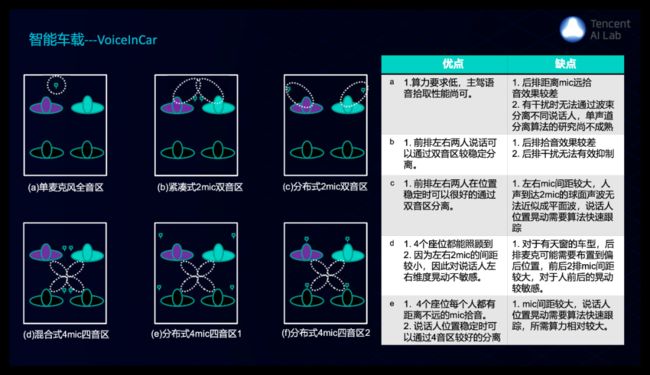
在智能车载方面,这里列出了各种车载麦克风阵列分布形式,及其优缺点;我们经过一年的打磨实现了叫做VoiceInCar的车载语音前端解决方案,针对车载回声消除和麦克风阵列波束形成提出了创新性的算法。通过不同配置可以满足不同车厂不同麦克风数量、不同麦克风布局、不同音区数量、不同硬件计算能力的车载语音需求,提供从项目前期设计指导、项目硬件检测到车载语音算法的整体方案,目前与腾讯车联网业务中心合作在大量前装车机,柳汽、长城汽车、长安汽车等车厂的众多车型陆续落地。
在完成远场语音交互的打磨和落地之后我们拓展到多模态人机交互方面的技术研发,多模态人机交互是未来的发展趋势,通过融合多种模态的信息可以使得交互更高效,更自然。围绕多模态人机交互我们实现并完善了新的模块,这些模块经过了多轮迭代,也已达到工程落地的阶段。
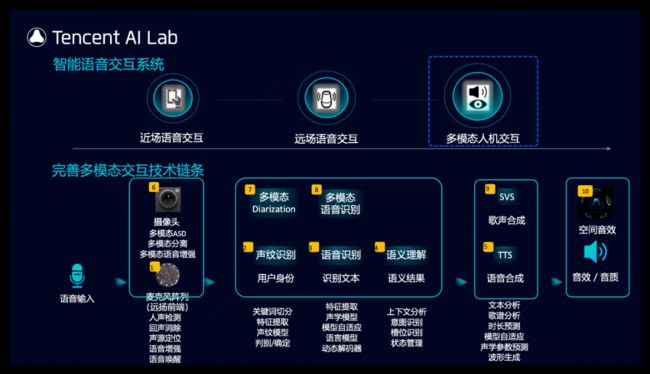
多模态交互分为输入理解和反馈呈现这两个方面,其中反馈呈现这部分,或者叫多模态生成,合成,在技术研发和行业应用方面目前都是一个热点,我们在18年确立了以多模态生成/合成为重点的AI数字人作为我们一个主要的方向,AI数字人依托AI Lab视觉中心,语音中心,nlp中心形成完整技术链,很好地应用了我们多项基础研究能力,并且通过多模态的方式呈现给用户;我们希望他具有这样一些要素:针对不同场景的拟人或卡通形象,工业级高仿真度的建模渲染,灵活轻量的采集与生成过程。更丰富的交互环境,包括虚拟场景生成,增强现实,虚拟现实及全息技术;更自然的语音合成,歌声合成,适用于不同场景的文本语义分析和自然语言生成。
在2019年,我们在多模态交互领域取得了研究的多项进展,包括高自然度的Durian声音合成技术,还有领先的口型合成技术,可以通过文字自动驱动口型和动作,在此基础上,我们打造了不同类别的数字人,包括了支持多情感多语言的高拟真渲染虚拟人,支持文本、动作舞蹈自驱动的二次元虚拟主播,还有利用神经网络渲染打造的高自然度数字人。

2020年,我们继续加速数字人技术在各行各业的落地应用:包括探索AI在规模化游戏内容和IP生态构建上的应用,语音/文本驱动口型技术落地多个游戏项目,包括《镜》、天美Wedo项目人物口型驱动等,提升了美术制作效率。
我们也将跟斗鱼、企鹅电竞试点AI主播的落地,为用户提供24小时的解说、点歌等互动功能;另外我们打通了歌词创作 -歌声实时合成/转换完整流程能力,歌唱合成技术初步落地到文娱行业如王者IP主题曲、王俊凯互动H5等,实现了AI歌唱的实时生成,还将进一步的落地于全民K歌的修音、千人千面创作歌曲等应用。
我们还在B站上线了24小时AI主播艾灵,大家可以登录这个网址去与艾灵进行点歌互动,艾灵上线以来曲目不断增加,目前以每周新上线15到18首的生产速度,已支持140多首流行歌曲,我们的歌声合成流程自动化程度高,需要很少的后期调校,上线两个月以来,已经收获2万多粉丝,我们会持续打磨AI主播艾灵,探索AI互动能力,进行玩法验证和用户验证。

在研究工作方面,今天主要跟大家分享我们在几个基础方向的近期的工作,包括阵列前端,语音识别,语音分离和多模态交互技术方向。
1. 阵列前端
1.1 语音唤醒
在阵列前端方面,首先介绍语音唤醒,唤醒性能是评估前端系统效果的最直观用户感受的最主要的指标,因此我们持续在唤醒方面进行了深入的打磨。语音唤醒的主要问题是低功耗,高准确度之间的矛盾,主要挑战是在复杂声学环境,如噪声及多人干扰时语音的质量。这是我们唤醒技术的一个演进,在搭建起固定唤醒和自定义唤醒系统之后,我们围绕结合前端阵列和唤醒模型进行了深入的优化。
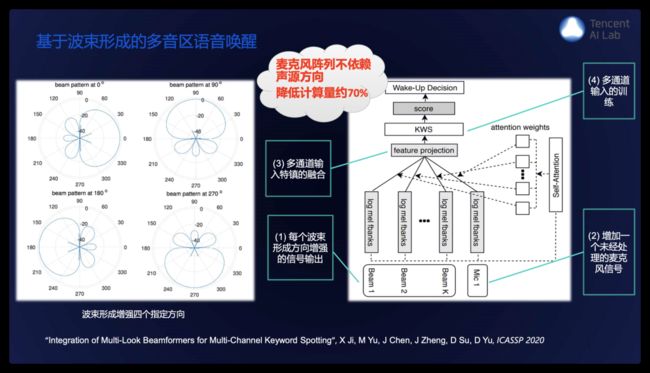
语音唤醒的挑战在于噪声条件下尤其有多干扰人讲话的情况,此时无法准确判断目标语音的方向,因此不妨就让它同时关注多个方向,我们提出设置多个固定波束,同时增加一个未经处理的麦克风信号,但缺点是要检测每路波束是否唤醒,计算量则因此增大。
针对这个问题我们引入了一个自注意力机制,将固定波束得到的多路结果进行自动融合,该方法不仅唤醒性能提升,在如图4个固定波束配置下计算量降低约70%。进一步地我们提出多通道多音区神经网络增强和唤醒模型的联合优化,首先就是采用神经网络取代传统固定波束增强,具体是基于一个多通道神经网络增强模型,引入多个指定方向的directional feature,即空间方位特征,训练过程中模拟唤醒和背景干扰人的情况,使得模型能够增强离各个指定方向最近的声源信号,然后将多音区增强模型和唤醒模型进行联合优化,右下方的实验结果可以看出,该方法总体性能较好,尤其在信干比低的情况下唤醒性能获得大幅提升。
1.2 ADL-MVDR(ALL deep learning MVDR)
我们最新的一个全神经网络MVDR的工作:传统MVDR公式如下面所示,其中需要更好的确定语音和噪声部分,因此已经部分的结合了神经网络,通过神经网络估计时频点上的mask,来改进性能,但仍需要进行噪声协方差矩阵求逆以及计算方向导矢需要进行pca,而这两方面都存在数值不稳定的可能,并且如果是以逐帧递归的方式来估计协方差矩阵,其中的加权系数是一种经验的heuristic的方式。
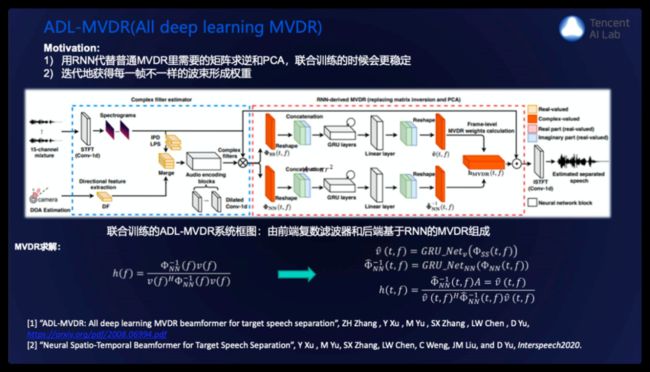
我们提出一种完全采用深度学习MVDR的方法,采用rnn来分别取代进行协方差矩阵求逆和pca的操作,另外我们采用complexratio filtering取代时频点的mask使得训练过程更加稳定,对目标语音和噪声的估计也更加准确。
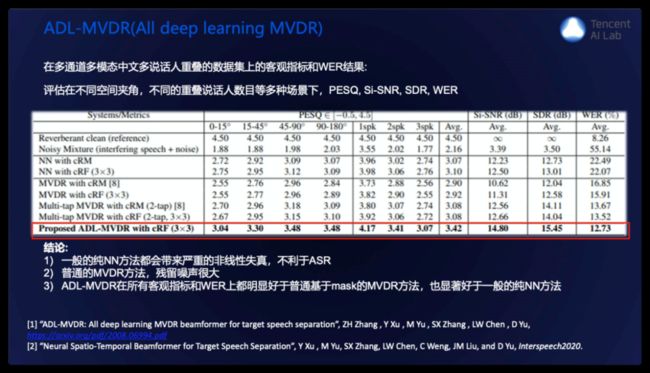
我们在一个比较复杂的,多通道多模态的多说话人重叠的数据任务上进行了实验,可以看到在不同空间夹角,不同的重叠说话人数目等多种场景下,PESQ,Si-SNR, SDR, WER的一个结果。从实验结果得到的结论是,一般的纯NN方法都会带来严重的非线性失真,不利于ASR,普通的MVDR方法,残留噪声很大;而我们提出的ADL-MVDR方法,在所有客观指标和WER上都明显好于普通基于mask的MVDR方法,也显著好于一般的纯神经网络方法。
2. 语音识别
在语音识别方向,主要的提升可以归纳为来自两个方面,框架准则和模型结构,去年我们在RNN Transducer模型基础上做了一些改进工作,主要是实现验证的RNNT上的区分训练和外部语言模型的引入,在当时还没有看到有文章报告RNN Transducer模型上的区分训练的结果。
2.1 RNNT模型改进
这里主要针对的问题大家都比较清楚了,就是rnnt的训练准则与最终WER/CER衡量标准存在一定的不匹配,同时RNNT训练时Decoder采用teacher-forcing (Decoder输入采用真实标注序列),但推理解码时Decoder依赖于前一个解码输出的符号,第二个问题是RNNT端到端模型训练时所见到的文本数据有限,长尾词识别能力较弱。
针对第一个问题 我们采用最小贝叶斯风险((MBR)训练,最小化标注序列与在线生成Nbest之间的期望Levenshtein距离,同时保留原始RNNT准则做多任务训练。
针对第二个问题,我们引入外部语言模型来进行改进,包括在RNNT beamsearch解码时引入外部神经网络或Ngram语言模型做on-the-flyrescore,以及在最小贝叶斯风险((MBR)训练在线产生Nbest时引入外部语言模型,将外部语言模型信息注入模型训练中。我们在一个较强的基线系统上进行实验,模型结构是TDNN和transformer的混合模型结构,在两个测试集上进行测试均获得了明显的收益。后续我们也在继续做一些尝试,包括低延时流式RNNT端到端识别,结合LAS的二遍rescore的工作。
2.2 DFSMN-SAN-MEM模型结构
我们近期在模型结构方面的工作,对于时序分类任务,可以归纳为这样两种典型连接关系,一种是RNN,如LSTM或者GRU,一种是类卷积的模型,如FSMN,TDNN等,另外self-attention结构也可以看作是这一类,只不过它的连接采用了复杂的attention机制,并且是要在整句上面进行处理。类卷积模型的优点是并行性好,可灵活调节上下文范围,模型可以堆的更深。在工业级的应用中, 数据量可达到几万甚至十几万小时数据进行训练,这个时候并行性和训练速度就是一个更重要的考虑因素。
我们采用SAN(self-attention)引入FSMN网络中,进行了大量实验,探索出一种最优的网络结构,模型包含3个DFSMN-SAN blocks,每个block包含10层DFMSN模型和1层self-attention layer结构,得到的主要结论是:我们提出的DFSMN-SAN结构明显优于纯DFSMN模型,也优于纯SAN模型,纯SAN网络对超参敏感且计算量大。通过在FSMN网络中高层穿插引入SAN可达到更优效果,说明低层次特征只需要用简单模型结构提取,在中高层穿插引入SAN即可。我们在SAN模型的实验中发现一个现象就是,由于SAN有很好的综合上下文的能力,利用的上下文越长性能越好,因此一个想法就是如何进一步利用比句子更大范围的上下文信息。我们提出在SAN层进一步引入memory的结构,具体提出了两种方式,使得模型可以利用更多的全局信息,在实验中相比不加memory的模型获得了进一步显著的提升。
2.3 NAS在大规模语音识别系统中的应用
在模型结构方面这里也重点介绍我们最近的一个工作,就是NAS(Neural Architecture Search)在大规模语音识别系统中的应用,这里大规模指训练数据至少上万小时规模,工业产品应用至少上万小时训练数据量级。我们看到NAS在视觉领域取得了成功,其技术在不断快速的演进,从初期的基于强化学习框架,动辄几千GPU-DAYs,到如今的几个GPU-DAYs,效率已经大幅提升。由于语音任务,从输入维度和输出类别数以及sample的规模来说,比图像识别任务复杂度更高,所以我们重点考察了NAS在语音识别任务上的可行性,包括搜索训练时间及显存资源是否负担的起;我们实验了在小数据集上搜索模型架构,然后扩展迁移到大规模数据上训练这样一个方案。
在NAS具体方法上,DARTS提出了一种可微分结构搜索框架,训练的过程中同时学习网络参数(传统的神经网络参数)和结构系数,候选操作的重要性由结构系数决定,以此生成最终的搜索网络。PDARTs在DARTs基础上提出一种progressive的方式,在PDARTs中,搜索分多个阶段,网络的层数逐级增加,每个阶段末尾删除重要性低的候选操作,来缓解搜索阶段和评估阶段网络层数不同带来的性能损失。
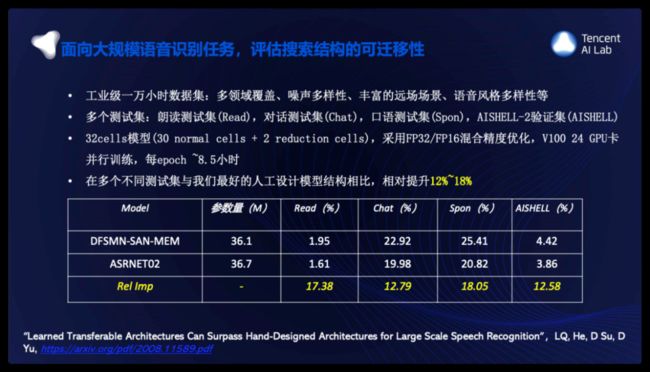
针对语音识别任务我们选择首先在aishell-1这样一个150小时的数据集上,进行了大量候选集合的搜索实验,我们的一个主要工作,是为达到较好的识别率和模型复杂度的平衡,改进了搜索候选空间,上图是最终搜索得到的Normal Cell和Reduction Cell结构,在此结构的基础上,我们将其迁移到大的数据集上进行模型训练实验,在AIshell2,一个1千小时数据集上的结果表明,识别率显著提升,我们改进候选集合搜索得到的模型相比原始搜索空间的模型复杂度也减小近一半。
我们进一步将NAS搜索的模型应用到上万小时这样一个工业级数据规模上进行训练,数据包含多领域,噪声多样性,远场模拟,不同风格等多样性,我们基于搜索出的cell结构加深网络,调整初始channel数目,整体模型为32cells,采用FP32/FP16混合精度优化,V100 24 GPU卡并行训练,每epoch ~8.5小时,整个训练约可在一周左右完成,是一个完全可接受的周期范围;可以看到与我们目前最优的人工设计的DFSMN-SAN-MEM模型相比,在多个测试集上获得了相对12%到18%的提升,这是一个非常鼓舞人心的结果,预示着NAS在识别系统中仍有非常大的空间,不久或许就可以摆脱人工对模型的精雕细琢,我们也在NAS框架下引入时延的限制搜索适用于流式识别任务的网络架构。
这里介绍一下我们的语音工具平台,语音工具包Kaldi虽然已是被广泛采用的完备的语音工具集,但它的神经网络部分无论从灵活性和效率来看仍不及主流深度学习框架;我们是比较早结合pytroch和kaldi框架打造我们自己的训练工具平台,兼备Kaldi完备语音功能以及主流深度学习框架的灵活高效;这个工具平台也在公司开源协同的倡导推动下,跟兄弟部门一起不断完善。包括语音识别,语音合成,声纹识别,语音分离,关键词检测等各个方向都统一集成到这个平台上面。
我们的平台取名叫做PiKa,意思是pytorch和kaldi的结合,Pika在英文中是一种叫做“鼠兔”的动物,正好也是两种动物的结合,寓意着轻巧和灵活。我们计划将该工具平台从年底开始逐步对业界开源,它的主要功能包括支持各类传统系统,也支持各类新的端到端系统;它的特色包括:围绕中文任务,高效的在线加噪dataloader以及多机多卡分布式Trainer,上万小时大规模数据性能验证及速度优化,训练速度为kaldi4~5倍,另外也支持AILab新的算法改进的集成,比如LSTMp(LSTM with projection) pytorch的底层实现,SpecSwap,DFSMN-SAN-MEM等。

3. 语音分离
我们在语音分离方面的几项工作,这里主要是单通道语音分离,我们关注了三个方面,一是语音分离本身的性能,二是语音分离的推广下,三是改善分离语音的识别性能。
3.1 结合局部递归和全局注意力的分离模型
首先是提升语音分离的性能,这里的性能不单单是指SISNR这样的客观指标,还包括计算复杂度,因为当前的几种最优的模型如Conv-Tasnet或DPRNN其实都是计算量相当复杂的,DPRNN相当于包含2、30层单向LSTM,一个100小时左右规模的数据要训练一周左右的时间,我们经过大量实验,提出一种GALR(Globally Attentive Locally Recurrent Networks)模型,它的关键点是 :
(1)以递归神经网络记忆和处理在波形局部节段内的信息
(2)以注意力机制提取信号在节段和节段间的全局相关性
从实验结果可以看到,1.5M大小的模型能达到跟2.6MDPRNN相当的分离性能;同时最多减少36.1%的GPU记忆和49.4%的计算量;在公开数据WSJ0-2mix,同样配置下比DPRNN有更优的性能;在2000h的中文数据中,分离目标语音的SISNR比DPRNN高9%。

3.2 语音分离半监督学习算法
众所周知,分离模型的泛化能力一直是学术界和工业界想极力解决的问题。分离的推广性是一个更严重的问题。因为多种声音的组合它的可能性是更多的,可能造成更的不匹配,另外对于已经混合的数据,没有办法进行有效的标注。MBT(Mixup-Breakdown Training)是我们提出的一种很容易实现的基于一致性的半监督学习算法,称为混合-分解训练方法,可用于语音分离任务。MBT首先引入平均教师模型预测输入混合信号的分离结果,其输入混合信号包括有标注的数据,也包括无标注数据;
然后对这些中间输出(所谓“Breakdown”)结果进行随机插值混合,得到伪的“有标注”的混合信号(所谓“Mixup”);最后,通过优化教师模型和学生模型之间的预测一致性,来更新学生模型。这是我们所看到的第一个工作提出在语音分离任务上采用半监督学习的方法有效提升对不匹配应用场景的泛化性能。
3.3 改善分离语音的识别性能
在实际应用场景中,很多时候是需要进行语音识别,语音分离最终的目标是获得更高的识别准确率,但是分离模型处理过程不可避免引入信号误差和失真,因此反而会使识别性能变差。常见的解决方法是通过对声学模型与语音分离模型联合训练,在这方面我们有两个主要结论:
一个是联合训练可以采用一个较轻量的识别模型进行,然后将联合优化后的分离模块与线上大的识别系统进行对接,依然可以获得明显的提升。
第二个是引入一个在fbank特征层面的损失准则进行多任务优化,对于减小分离带来的失真也有一定的效果。
我们另外提出了另一种端到端的神经网络框架EAR(全称Extract,Adapt and Recognize),在分离和识别直接引入一个适配器(Adaptor),适配器的角色是显式通过神经网络,对从掩蔽频谱适应到识别特征一种过渡表征进行学习,测试集上面跟其他方法比較的结果可以看出来我们设计的EAR网络框架具有很强的鲁棒性,能在含噪语音中仍表现很好的识别性能。从多个测试集上面可以看出来我们提出的声学模型在各个测试集上都有大幅提升。

我们综合以上语音分离技术,应用于复杂音乐背景语音分离与识别,围绕视频语音的转写和字幕生成任务,其中背景音乐噪声是一个尤其典型的问题,背景音乐在短视频中广泛存在,具有非常高的比例,然而现有语音识别系统在较强的背景音乐的条件下识别性能会明显下降。通过采用我们上述的分离和联合优化技术在大规模语音与背景音乐数据上的训练,在多个音乐背景测试集上均获得识别率相对提升超过20%,并且无需背景音乐判别模块,在无背景音乐的测试集也可获得1%~3%的相对提升。
4. 多模态技术
4.1 多模态语音分离
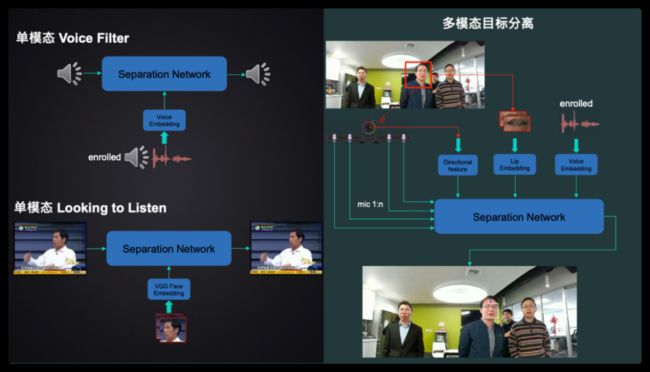
这是我们多模态语音分离的系统,输入设备是一个麦克风阵列和摄像头。
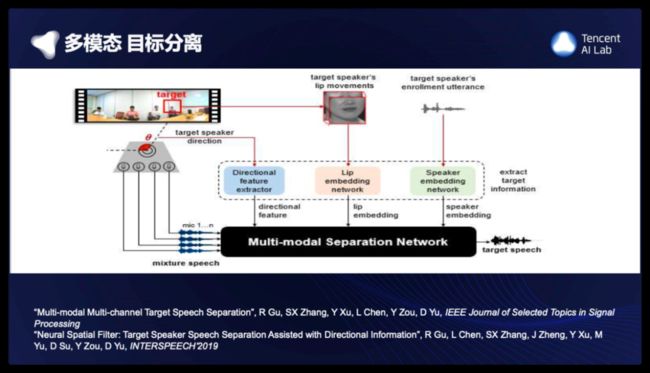
首先系统检测到n个人,以其中红色框的这个人为例作为目标说话人,第一个模态,人脸检测告诉我们,目标说话人在这个方向,第二个模态,脸部的关键点可以告诉我们,目标说话人嘴唇的形状;第三个模态,目标人如果有事先注册的语音,可以告诉我们他的声纹信息。下一步就可以把三个多模态的信息,送给三个特征提取网络,提取目标说话人的信息。这些信息和多通道的语音信号,一起送给分离网络,输出目标人的语音,在搭建这个系统的时候,这是我们知道的第一个使用三个模态,语音分离的工作。具体的模型结构,模态融合的方法,联合训练的算法,具体细节请参考我们的论文。
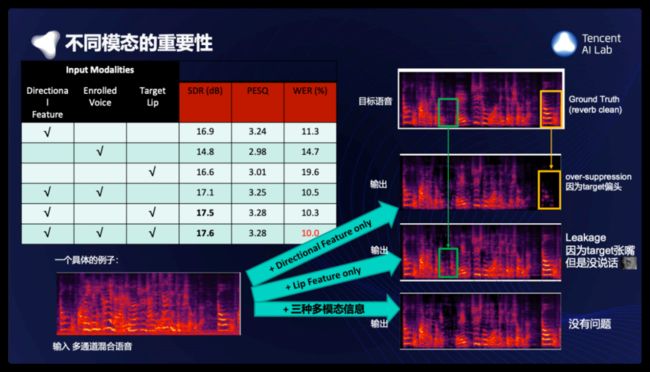
通过实验不同模态信息组合的结果,可以评估不同模态的重要性,方向信息,lip信息,和声纹信息,这三个模态,对系统的影响是不一样的。从结果上来看,总的来说:方向信息最强,Lip信息和其它模态最互补,三个模态都是互补的,可以看到三个模态一起用的话,WER可以从19%降到10%;下面是三个模态互补的一个例子,这个例子说明了用3个模态,可以解决几乎所有的cornercase,例如target侧脸说话,只张嘴不说话,等等。
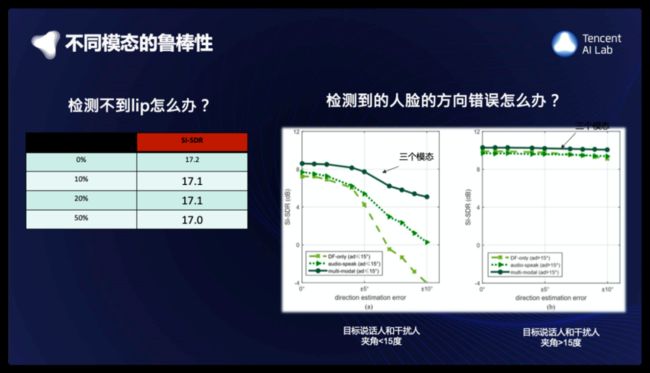
我们测试了各个模态的鲁棒性,例如Lip检测不到的情况,我们在测试的时候使用了不同的dropout,可以看到系统的性能对Lip比较鲁棒。另一个测试是,方向信息的鲁棒性,这里方向信息的错误可能是人脸检测因为玻璃光线的反射引起false alarm错误,或者侧脸说话造成的人脸方向,并不是audio的方向。从深绿色的曲线上可以看到,在target和干扰人夹角<15的情况下,对方向信息 人为加上5度左右的干扰,会有不到0.5dB左右的下降;在target和干扰人夹角>15的情况下,对方向信息人为加上5度左右的干扰,不会有性能的下降。
这里我们比较一下2个单模态的系统和我们的多模态系统的分离效果;第一个单模态系统是Google的VoiceFilter;第二个单模态系统是Google的Look-into-Listen;第三个是我们的多模态系统。
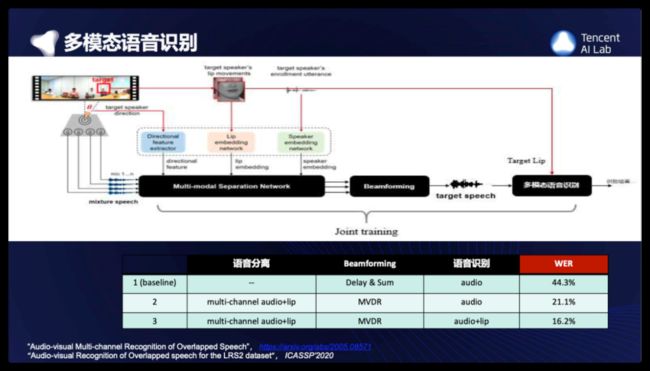
4.1 多模态语音识别
我们还做了一些多模态audio-visualASR的工作。这里是最新的工作,把多模态分离+beamforming+多模态ASR,进行联合训练。这个表格只是我们结果的很少的一部分,更多的细节欢迎大家去看看我们列出来的论文,baseline 这里是常见的方法,就是用groundtruth的方向,做delayand sum beamforming, 然后做audio-only的传统的ASR(AM都是TDNN,E2Emodel的结果更差一些具体请见论文),第2行,是前面讲的多模态分离+audio-only的传统的ASR,WER有相对50%的巨大提升,第3行,是多模态分离+MVDR+audio-visualASR的系统,WER又有相对24%的提升。我们提出了新的ASR多模态融合的方案,论文里有讨论。这也是我们所知的,第一个多通道-多模态-语音识别的工作。
我们近期会开源一个 3500hr的多模态数据集(来自腾讯视频等的中文数据),帮助大家一起解决鸡尾酒会问题。会是目前最大的 多通道+音频+视频的有标注的数据,标注包括:文本的humantranscriptions,speaker的label,声源的方向,人脸检测的boundingbox和landmark等等。
测试集是用我们AILab自研的设备,录制的真实环境的多通道+音频+视频的录音。该数据集可以帮助大家一起攻克,解决鸡尾酒会问题中的3个关键问题:diarization,separation和ASR。
敬请期待!
后台回复关键词【AI Lab】可获取嘉宾分享PPT。
云+社区沙龙 online 第5期
【架构演进】专题直播正在进行
扫码预约直播

