【论文翻译】A Deep Learning Approach for Multi-Frame In-Loop Filter of HEVC
A Deep Learning Approach for Multi-Frame
In-Loop Filter of HEVC
Tianyi Li, Mai Xu, Senior Member, IEEE, Ce Zhu, Fellow, IEEE, Ren Yang, Zulin Wang and Zhenyu Guan
摘要—针对高效视频编码(HEVC)标准,为了减少压缩伪影,提高编码效率,人们对环路滤波器进行了广泛的研究。然而,在现有的方法中,在不利用多帧之间的内容相关性的情况下,始终将环路滤波器应用于每个单个帧。本文提出了一种用于HEVC的多帧循环滤波器(MIF),它利用相邻帧来提高每个编码帧的视觉质量,具体地说,我们首先构造一个包含编码帧及其对应的各种内容的原始帧的大型数据库,用于学习循环滤波器,接下来,我们发现编码帧的质量和相似内容通常存在多个参考帧。因此,设计了参考帧选择器(RFS)来识别这些帧。然后,利用该帧的空间信息和相邻高质量帧的时间信息,开发了一种用于MIF的深层神经网络(简称MIF网),以提高每个编码帧的质量。MIF网是建立在最近发展的DenseNet上的,它得益于其改进的泛化能力和计算效率。此外,设计了一种新的块自适应卷积层,并将其应用于MIF网络中,以解决HEVC中编码树单元(CTU)结构对伪影的影响。大量实验表明,我们的MIF方法在标准测试集上平均节省了11.621%的Bjøntegaard delta比特率(BD-BR),在HEVC和其他最新方法中明显优于标准环路滤波器。
索引项—高效视频编码,环路滤波,深度学习,多帧。
I.介绍
近年来,高清晰度视频的迅速发展带来了越来越多的视觉体验,但同时也对海量视频数据的传输和存储提出了挑战。为了应对这一挑战,视频编码联合协作小组(JCT-VC)提出了用于视频压缩的高效视频编码(HEVC)标准[1]。与以前的H.264/高级视频编码(AVC)标准[2]相比,HEVC平均可以节省大约50%比特率。这得益于先进的编码技术的集成,例如,基于灵活四叉树的编码树单元(CTU)结构,增加了帧内预测模式的数量和更精确的运动补偿插值。然而,各种压缩伪影(例如,方块、模糊和振铃伪影)[3]仍然存在于压缩视频中,特别是在低比特率下。这些伪影主要来自于块预测和量化,精度有限。为了减少压缩伪影,在最近的视频编码标准中采用了环路滤波器作为关键部件,通过提高每个编码帧的质量并提供更高质量的连续参考帧。因此,采用环路内滤波器可以进一步提高编码效率。
共有三种内置环路滤波器用于标准HEVC,包括去块滤波器(DBF)[4]、采样自适应偏移(SAO)滤波器[5]和自适应环路滤波器(ALF)[6]。这些在环滤波器是在HEVC中顺序实现的。具体地说,DBF首先用于去除阻塞伪影。然后,SAO滤波器通过向每个采样添加自适应偏移来减少采样失真。此外,还考虑在SAO滤波器之后实现ALF,从而进一步减小基于Wiener滤波器的重建帧与原始帧之间的均方误差。然而,ALF不能提供更好的视觉质量,因此在HEVC的最终版本中没有采用。除了HEVC的内置环路滤波器外,还提出了一些其它的环路滤波方法,包括启发式方法和基于学习的方法。在启发式方法[7]-[10]中,利用视频编码的一些先验知识建立压缩伪影的统计模型,然后基于该模型导出用于提高每个视频帧质量的滤波过程。近年来,深度学习在数据压缩的许多领域得到了成功的应用,如视频编码[11]、质量增强[12]和特征编码[13]、[14]。此外,基于学习的方法成功地提高了环路内滤波的性能[15]-[20]。这些方法通常采用卷积神经网络(CNN)来学习参考帧中内容的空间相关性。例如,Dai等人[16] 介绍了一种可变滤波器尺寸的残差学习CNN(VRCNN)代替标准DBF和SAO的帧内模式。与单路径CNN相比,[16 ]中的可变滤波器大小能够在不同的空间尺度上进行特征提取,网络复杂度低,训练过程加快。最近,张等人[20] 提出了一种适用于帧内和帧间视频编码的残差通道CNN(RHCNN),它是在标准SAO之后使用的。然而,上述基于学习的方法都没有在HEVC中使用多个相邻帧进行环路内滤波。在本文中,HEVC编码帧中存在视觉质量的高波动,因此通过参考其相邻的高质量帧可以提高低质量帧。因此,受多帧超分辨率(multi-frame super-resolution)[21]-[27]中的工作的启发,通过使用其相邻帧,可以进一步减少环路滤波器中每个编码帧的压缩伪影。
本文在深度学习的基础上,开发了一种用于HEVC的多帧环路滤波器(MIF),取代了原有的DBF和SAO。具体来说,我们首先在HEVC1中构建了一个用于循环过滤的大型数据库。我们的数据库包含失真帧及其对应的原始帧,它们是由200个原始视频序列在四个量化参数(QP)值下生成的。接下来,我们需要检查编码帧在HEVC中的质量波动。为此,我们设计了一个参考帧选择器(RFS)来搜索更高质量的参考帧,给出了一个基于帧质量和内容相似性的未滤波重建帧(URF)。如果RFS提供足够的参考帧,URF将通过一个深度神经网络(称为MIF网)来利用一帧内的空间信息和帧间的时间信息。在MIF网络中,首先通过运动补偿将每个参考帧的内容与URF对齐,然后利用来自多个帧的信息增强URF。在RFS没有选择足够的参考帧的情况下,采用一种简单的用于环路滤波器的深层神经网络(IF-Net)来增强URF。MIF网和IF网都是建立在最近开发的DenseNet[28]的基础上的,这得益于它在提高泛化能力和计算效率方面的巨大成功。另外,考虑到受CTU划分结构的影响,该网络还可以通过在CU和TU网格的不同位置改变卷积核来适应HEVC中的编码单元(CU)和变换单元(TU)划分。最后,设计了一种模式选择方案和相应的语法,在三种可能的选择(MIF-Net、IF-Net和标准in-loop滤波器)中选择最佳模式,保证了方法的整体性能。图1显示了我们的MIF方法的一个示例。这里,将当前的第182帧编码为URF,然后选择第177帧和第178帧作为其参考,具有更高的质量和类似的内容。然后,将URF和两个参考帧输入MIF网络。因此,MIF网利用两个参考帧的信息,可以显著地增强URF中具有明显伪影(气泡后面的脸和耳朵)的内容。

本文先前在2019年数据压缩会议[29]上提出,有以下改进。首先,HIF数据库的训练和验证集从[29]中的93个序列扩大到160个序列。此外,本文还对压缩HEVC的帧质量和内容相似性进行了全面分析,以此作为我们MIF方法的基础。 接下来,我们通过开发语法规则来改进我们的MIF方法。 最后,我们通过各种设置和消融研究提供了更广泛的实验结果,验证了我们的MIF方法的有效性和泛化能力。 简而言之,本文的主要贡献总结如下。
- 我们建立了一个学习HEVC环路滤波器的大型数据库,为进一步研究HEVC编码环路滤波器的设计提供了可能。
- 我们研究了HEVC中编码帧的质量波动,并设计了一个RFS来寻找高质量的URFs参考帧。
- 我们提出了一个MIF网和一个IF网,通过同时利用空间和时间信息来显著提高帧质量
本文的其余部分安排如下。第二节回顾了HEVC环路滤波和多帧超分辨率的相关工作。第三节介绍了构建的HIF数据库,并对HEVC中的帧质量波动进行了分析。在第四节中,我们提出了用于循环内过滤的MIF方法,第五节规定了相应的语法。第六节报告了实验结果,以验证所提出方法的有效性。最后,第七节对本文进行了总结。
II. 相关工作
近年来,为了提高HEVC的编码效率,人们提出了许多环路内滤波的方法来减少压缩伪影。随着HEVC的发展,设计了三种内置环路滤波器,包括DBF[4]、SAO滤波器[5]和ALF[6]。具体地说,在H.264的基础上,采用DBF作为HEVC的第一个环路内滤波器来消除预测单元(PU)或TU边界处的阻塞伪影。之后,SAO过滤器在平滑和纹理区域细化样本。为此,SAO过滤器将样本划分为不同的类别,然后根据类别向每个样本添加偏移量。此外,在HEVC的开发过程中,还考虑了ALF,即在编码器端使用维纳滤波器估计合适的滤波器系数,然后将系数发送到解码器端。然而,由于它无法产生视觉上更好的质量,因此最终没有在HEVC中采用。
除上述HEVC内置滤波器外,还提出了一些其它的环路内滤波方法。这些方法可以分为两类,即启发式方法和基于学习的方法。在启发式方法[ 7 ](10)中,根据一些先验知识(如纹理复杂性和相似帧补丁的数量)对工件的统计特性进行建模,然后根据模型导出过滤过程。例如,Matsumura等人[7] 在HEVC中引入了一种非局部均值(NLM)滤波器,该滤波器利用非局部相似帧块的加权平均值来减少伪影。非局部设计补偿了先前存在的环路滤波器仅利用帧的局部信息的缺点。马埃艾尔[9] 开发了一个基于组的循环内滤波器,以利用局部和非局部的相似性。根据得到的相似性,首先将重建的帧划分为多个斑块组,每个斑块组形成一个矩阵。然后,将软阈值或硬阈值应用于所形成矩阵的奇异值,以实现稀疏表示,同时滤除压缩伪影。同样基于群矩阵的奇异值分解,Zhang等人[10] 将循环内滤波问题转化为对每个斑块组具有低阶约束的优化问题,建立了稀疏表示的自适应软阈值模型。尽管上述启发式方法大大提高了编码效率,但这些方法中的先验知识需要人工挖掘。因此,手工特征提取在一定程度上导致了上述启发式方法的效率低下。同时,建立一个多变量滤波模型也是一个难点,从而导致上述方法对编码效率的提高有限。
最近,为了解决启发式方法的不足,人们提出了许多基于学习的循环内滤波器。基于学习的方法可以自动学习压缩伪影的广泛特征,并用足够的可训练参数优化环路滤波器。由于环路滤波器的输入始终是二维的帧补丁,这些方法通常采用CNN来学习补丁内容的空间相关性。具体来说,Park等人[15] 利用四层超分辨率CNN(SRCNN)[30]在编码过程中替换SAO。Dai等人[16]引入了VRCNN代替DBF和SAO,与单路径CNN相比,[16 ]中的可变滤波器大小有助于在不同空间尺度上提取特征,网络复杂度低,训练过程加快。随着CNN技术的发展,一些新的CNN结构也被应用于环路滤波中。例如,Kang等人[17]提出了多模式/多尺度CNN,以取代现有的DBF和SAO。该结构主要包含两个不同规模的卷积子网络,并利用CU和TU边界作为输入。Meng等人[19] 开发了一种多通道长-短期依赖残差网络(MLSDRN),用于将失真帧映射到其关联的原始帧,插入DBF和SAO之间。Zhang等人[20] 调查了利用不同内部结构的残差单元的性能,提出了一种RHCNN来建立重建帧与原始帧之间的精确映射,并在SAO后将RHCNN用作高维滤波器,不与现有的环路滤波器相冲突。
值得一提的是,通用视频编码(VVC)标准正由联合视频探索团队(JVET)开发,作为HEVC的继承者。JVET的一些建议已经研究了VVC中基于深度学习的环路内滤波器,它包含两大类,即序列相关和序列无关方法。在与序列相关的方法中,对某些帧在线训练一个深度神经网络模型,然后对同一视频序列的所有帧进行循环滤波。例如,Xiao等人[31]提出将luma和chroma两块编码块放在一起,然后用三层CNN对其进行处理,以预测增强的块,CNN只在时间ID为0或1的帧上训练,以减少计算开销。尹等人[32]提出在每个随机访问段的8个编码帧上训练多达6个CNN模型。因此,可以为所有编码帧的每个CTU选择最佳CNN模型。这些与序列相关的方法可以学习一个适合于视频序列中特定内容的模型,但同时也存在在线训练不可避免地带来计算开销的缺点。相反,与序列无关的方法得到了更广泛的研究,其中网络模型离线训练并用于任何视频序列。具体来说,Kawamura等人[33]在VVC的DBF之后,提出了一种3×3抽头的四层CNN。Lin等人[34]考虑QP,设计了一个更深层次的CNN,取代了帧内模式下的DBF和SAO滤波器。利用更先进的网络类型。Dai等人[35]将剩余学习技术应用到深度CNN中,同时共享一些可训练的参数,以节省内存使用并防止过度拟合。此外,Wang等人[36]开发了一种基于循环滤波器的密集残差CNN,跨层具有更灵活的路径。
然而,据我们所知,目前尚无工作在HEVC编码器中采用多个相邻帧进行环路滤波。在本文中,我们发现有可能通过使用每个编码帧的相邻帧来进一步减少其压缩伪影,这是受以下多帧质量增强和超分辨率研究的启发。最近,Yang等人 [37]提出了一种用于HEVC的解码器端质量增强方法。在文献[37]中,基于支持向量机的峰值质量帧(PQF)检测器首先将PQF与其它的PQF进行区分,然后采用一种新的CNN结构,在运动补偿后根据相邻的PQF对每个非PQF进行增强。除了提高图像质量外,还提出了更多的多帧超分辨率算法。早期文献[21]、[22]提出了一些传统的多帧超分辨率信号处理和机器学习方法,参考高分辨率关键帧来提高视频分辨率。后来,深度学习在这一领域得到了广泛的应用。例如,Kappeler等人[23]开发了一个视频超分辨率网络(VSRnet),其中连续帧首先通过运动补偿对齐,然后馈入输出超分辨率帧的CNN。后来,李等人[24]提出用基于残差学习的更深层网络来代替VSRnet。最近,Huang等人人[25]提出了一种高效多帧超分辨率的双向递归卷积网络(BRCN),在性能和速度上都有了较大的提高,此外[26]和[27]还提出了其他基于深度学习的视频超分辨率方法。
上述超分辨率方法[21] – [23],[25] – [27]和解码器端质量增强方法[37]是基于以下假设:相同的对象或场景可能出现在几个连续的帧中。因此,可以从其相邻的高分辨率/质量帧中推断出低分辨率/质量帧中的内容。 因此,我们首次尝试在编码器端应用MIF,据我们推断,它有很大的潜力来提高编码效率。
III. HEVC环路滤波器数据库
A. 数据库建设
我们为HEVC环路滤波器构建了一个大型数据库(称为HIF数据库),为所提出的方法提供足够的训练数据,并为后续工作提供便利。为了构建HIF数据库,收集了182个原始视频序列,其中6个序列来自[38],87个序列来自Xiph.org[39],89个序列来自视频质量专家组(VQEG)[41]的消费者数字视频库[40]。这182个序列可以自由地用于研究,没有任何商业用途。请注意,来自视频编码联合协作小(JCT-VC)测试集[42]的18个A∼E类序列也用于评估我们的MIF方法。但是,这些JCT-VC序列受版权保护,因此不包含在我们的HIF数据库中。尽管如此,我们的数据库包含182个可下载的视频序列,足以训练一个基于深度学习的环路内滤波器。表一列出了序列的详细信息。考虑到HM[43]只支持最小CU大小(默认为8×8)的倍数分辨率,通过移除帧的底边,将NTSC序列裁剪为720×480,此外,超过10秒的序列被裁剪为10秒,以防止数据库中的视频文件过大。

我们的HIF数据库中的所有序列被分为非重叠训练集(120个序列)、验证集(40个序列)和测试集(22个序列)。注意,22个测试序列是从[38]、[39]、[41]中随机选择的,具有5种不同的分辨率和不同的内容。在4个QPs{22、27、32、37}下,用HM 16.5[43]对序列进行了低延迟P(LDP)(使用encoder Low Delay P main.cfg)、低延迟B(LDB)(使用encoder lowdelay main.cfg)和随机存取(RA)(使用encoder randommaccess main.cfg)的编码。在编码过程中,所有的urf(即DBF和SAO之前的重建帧)被提取为MIF网络的输入,其对应的原始帧是GT。此外,由于HECC中的块划分结构对压缩伪影的影响很大,因此也提取了所有帧的Cu和TU分割结果作为辅助特征。结果,HIF数据库中的每个逐帧样本由四部分组成,即URF、其相关的原始帧和两个表示整个帧的CU和TU深度的矩阵。最后得到12个子数据库,分别对应于不同的QPs和配置。如表一所示,每个子数据库包含51335帧,因此为整个HIF数据库收集了616020帧样本。需要注意的是,每一帧样本可以分成多个块样本进行数据扩充,并且每个块样本在帧样本中的位置是可变的,这进一步增加了训练样本的多样性。因此,HIF数据库可以为我们基于深度学习的MIF提供足够的数据。
B. 数据分析
在这一部分中,我们分析了编码帧的质量波动和内容相似性,这是提出MIF的前提。对于这种分析,使用LDP、LDB和RA配置的默认设置,其中具有周期性质量波动的帧的分层编码是固有特征。然而,据我们所知,在设计HEVC的环路滤波器时,周期性的质量波动并没有被量化。本节旨在量化压缩帧的帧质量和内容相似性。首先用峰值信噪比(PSNR)来衡量视频帧的质量,并用PSNR的标准差(STD)来评价视频帧的质量波动。图2显示了两个选定序列中PSNR的波动,作为例子,在不同的配置下编码。可以看出,在同一视频序列中,帧间总是存在明显的波动,为了进行全面的分析,我们进一步计算了每个序列的帧级PSNR的STD,如表二所示。此外,还提供了HEVC中原始DBF和SAO(表II中命名为IDS)的PSNR增量,以进行比较。注意,PSNR的STD和IDS在所有160个训练和验证序列中是平均的。由该表可以看出,在LDP、LDB和RA配置下,帧质量的平均STD分别为0.891db、0.882db和0.929db,远远大于DBF和SAO增加的0.064db、0.048db和0.050db。这表明在不同的配置下,HEVC编码后帧的波动性很大。如此高的帧质量波动显示了设计MIF的潜力,该MIF可以显著优于HEVC中的原始环路滤波器。


除了质量波动外,内容相似性也是该方法的一个关键因素,因为URF与其高质量参考帧之间的运动补偿通常在共享相似内容时起作用。通过计算两帧之间亮度矩阵和色度矩阵的相关系数(CC)来度量相似度。图3显示了在所有训练和验证序列中,以HEVC编码顺序在不同帧距离处具有标准差的CC曲线。对于亮度(即Y)和色度(即U和V)信道,CC始终为正,显示帧内容的相似性。此外,三条具有标准差的CC曲线是相似的,这意味着Y、U和V通道之间的CC是一致的。虽然帧距离是根据编码顺序而不是显示顺序计算的,但是帧距离的增加通常会导致CC的减小。还可以观察到,在大多数情况下,10帧内的CC大于0.7,这表明帧内容具有显著的相似性。因此,通过对URF的相邻帧进行搜索,可以始终为URF获得足够的相似帧。
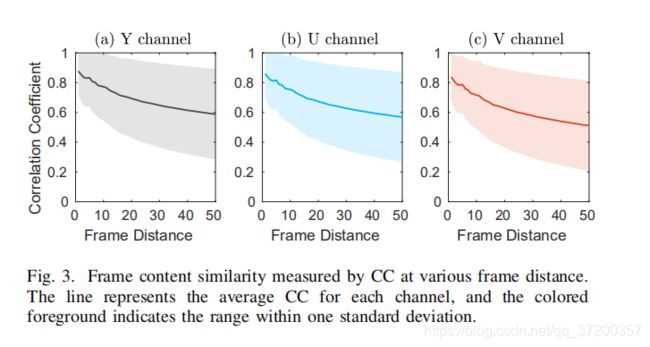
最后,我们分析了MIF中URF可用参考帧的组成,同时考虑了帧质量和内容相似性。图4-(a)根据PSNR的增加来计算每个URF的高质量帧的数目,亮度和色度CC都大于某个阈值。此图中的统计数据是在四个QP值{22、27、32、37}的训练和验证序列中所有预测帧的平均值。可以发现,在LDP、LDB和RA配置下,对于URF,平均9.9、9.8和10.2个先前编码过的CC>0.7和∆PSNR>0.5dB的帧是可用的。在CC>0.9的更严格约束下,在这三种配置下,仍有8.0、7.9和8.3个先前编码的帧可用,且∆PSNR>0.5dB。可以预期,质量大幅度提高的参考帧(例如,∏PSNR>2dB)更有帮助。此外,图5以在QP=32处上升的序列气球的第69编码帧为例说明了URF的参考帧的主观质量。如图所示,共有42个CC>0.7的高质量参考帧可用于URF,通常,较高的峰值信噪比也对应着更好的主观视觉感知,特别是在有纹理和移动的区域(例如,连接在热气球上的绳索)。此外,在内容方面,图5中所示的帧似乎相似。因此,基于客观和主观的检验,可以合理地期望找到足够数量的质量更高且类似于URF的参考帧。


IV. 提议的MIF方法
A. 框架
我们的MIF方法的框架如图6所示。在标准的HEVC中,每个原始帧通过模式内/模式间预测、离散变换和量化进行编码。然后,预测帧和剩余帧形成URF。随后,使用DBF和SAO对URF进行滤波以提高质量。与标准的HEVC不同,我们提出了一种基于深度学习的环路滤波器,利用相邻帧的信息来增强URF。首先,RFS选择高质量和高相关帧作为参考,将在第IV-B节中介绍。接下来,将两种可能的滤波模式之一应用于URF,如下所述。
- **模式1:MIF网络。**假设MIF网络需要M个参考帧。如果RFS选择至少M帧,则MIF-Net处理URF生成的增强帧。MIF网络由运动补偿和质量增强两部分组成。在MIF网络中,首先用一个运动补偿网络将每个参考帧与URF在内容上对齐,然后将所有对齐的参考帧和URF送入一个质量增强网络,利用这些帧的空间和时间相关性输出重建的帧。注意,这两个网络被组合成一个端到端的模型,可以通过中间训练有效地优化。
- **模式2:IF网络。**在URF没有足够的参考帧的情况下,使用另一个深度神经网络IF-Net作为MIF-Net的简单对应。与MIF网相比,IF网只把URF作为输入,不考虑多帧。IF网的结构类似于MIF网的质量增强网络,因此IF网的大部分训练参数可以由MIF网的训练参数初始化。这样的设计提高了训练程序的有效性,因为不需要从头开始训练IF-Net。
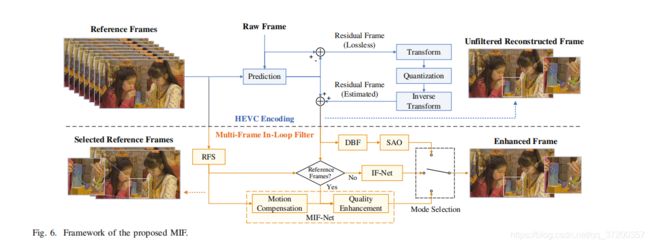
在模式1和模式2中,MIF网和IF网都适用于CU和TU划分,其中卷积核的参数随CU和TU划分而变化。第四章C节和第四章D节分别介绍了MIF网和IF网的体系结构,第四章E节给出了训练协议,如果MIF网/IF网不能提高帧质量,标准DBF和SAO也可以作为补充模式。最后,在三种可能的选择(即MIF-Net、IF-Net和标准in-loop过滤器)中选择最佳模式作为实际选择,确保了我们方法的整体性能。
B. RFS的设计
在我们的方法中,RFS被设计用来为每个URF选择参考帧,作为MIF的基础。对于视频序列中的第n个URF(用FUn表示),RFS检查其先前的n个编码帧作为参考帧池,每个帧池用FP表示(n - N ≤ i ≤ n - 1),然后计算反映质量差和内容相似性的6个度量,如下所示。
- ∆PSNRY(i,n), ∆PSNRU(i,n) and ∆PSNRV(i,n):对于Y、U和V通道,FPi的PSNR增量高于FUn。
- CCY(i,n), CCU(i,n) and CCV(i,n):Y,U和V通道的FP(i)和FU(n)之间的帧内容的CC值
基于上述指标,RFS的过程如图7所示。RFS首先将参考帧池划分为有效参考帧和无效参考帧,然后将所有有效参考帧送入RFS网络,选择M帧用于增强FU(n)的视觉质量。更具体地说,二进制值Vi,n表示池中的参考帧是否有效。对于FP(i)的至少一个信道,如果PSNR增加为正并且CC值高于阈值τ,即V(i,n) =1 in(1),则FP(i)被视为有效参考帧。

如果存在至少m个有效参考帧,则每个有效参考帧FP(I)的六个度量满足n - N ≤ i ≤ n - 1和V(i,n) = 1形成一个6维向量,然后将它们输入到一个两层完全连接的网络(称为RFS Net),以生成标量R i,n作为输出,如图8所示。这里,Rˆ(i,n)是一个连续变量,表示FP(i)作为FU(n)参考的潜力。更大的Rˆ(i,n)表明FP(i)比其他参考帧更有潜力增强FU(n)。注意Rˆ(i,n)是RFS Net的预测值,相应的GT由R(i,n)表示。
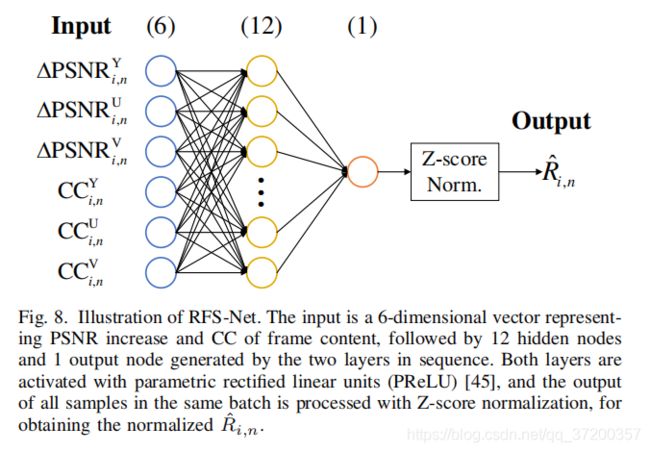
生成R(i,n)和训练RFS网的过程如下所示。与典型神经网络的随机选择训练批不同,RFS网络的一个训练批中的样本仅从一个URF的有效参考帧中提取。这样的样本组织是基于RFS的所有预测值{Rˆ(i,n)|n - N ≤ i ≤ n n-1, V(i,n) = 1}用于增强一个特定的URF的FUn,而不考虑其他URFs。在RFS网络中,当参考帧与FU(n)对齐后,地面真实值 {R(i,n)|n - N ≤ i ≤ n - 1, V(i,n) = 1}应反映有效参考帧的质量。为了实现内容对齐,我们将MIF网络中的运动补偿网络应用于每一个有效的参考帧FP(i)以产生补偿帧FC(i)。然后,FC(i)与第n个原始帧(用Fn表示)之间的差异能够量化R(i,n),即FP(i)增强FU(n)的潜力。这里,标准化PSNR用于计算每个有效参考框架的Ri,n,公式如下:

其中PSNR(·,·)表示补偿帧与其对应的原始帧之间的PSNR,而μPSNR(Fn)和σPSNR(Fn)分别表示{PSNR(FC(i),Fn)| n - N ≤ i ≤ n - 1,V(i,n) = 1}上的平均值和标准偏差。归一化后,一批的地面真值均值为0,标准差为1,符合归一化预测值{Rˆ(i,n) | n- N ≤ i ≤ n - 1,V(i,n) = 1}。因此,R(i,n)和Rˆ(i,n)具有相似的尺度,可以用l2损失来衡量它们之间的差异。考虑到整个训练批对FU(n)的增强,将RFS网的损失函数表示为:

它是由Adam算法优化的[44]。利用训练的RFS网络模型,可以得到所有有效帧{Rˆ(i,n) | n - N ≤ i ≤ n - 1,V(i,n) = 1}的参考潜力。然后RFS选择M帧作为输出,用![]() 表示,其中索引M指示FR(m,n)是所有有效参考帧中Rˆ(i,n)的第M个最高的帧。在特殊情况下,有效参考帧的数量小于M,则RFS不起作用,而使用IF-Net来增强FU(n)。
表示,其中索引M指示FR(m,n)是所有有效参考帧中Rˆ(i,n)的第M个最高的帧。在特殊情况下,有效参考帧的数量小于M,则RFS不起作用,而使用IF-Net来增强FU(n)。
C. MIF-Net的体系结构
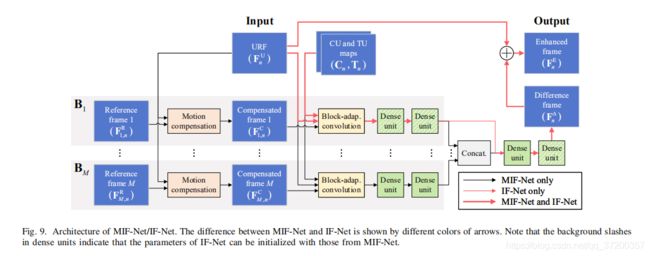
在我们的方法中,根据RFS选择的帧数,MIF-Net或IF-Net可以提高每个URF的质量。本节主要讨论MIF-Net的体系结构,IF-Net和MIF-Net的区别在第四节D中说明。图9说明了MIF-Net/IF-Net的总体体系结构。如图所示,MIF-Net以URF FU(n)及其M个参考帧![]() 为输入,生成增强帧FE(n)作为输出。MIF网综合来自M个并行分支
为输入,生成增强帧FE(n)作为输出。MIF网综合来自M个并行分支![]() 的信息,每个分支Bm处理对应的参考帧FR(m,n)。在分支Bm中,首先通过运动补偿网络将参考帧FR(m,n)与URF FU(n)对齐,产生补偿帧,用FC(m,n)表示。然后,在FU(n)的CTU划分结构(块自适应卷积层)的指导下,利用一种新的卷积层对FU(n)和FC(m,n)进行处理,以探索不同来源的低层特征,并结合CU和TU划分合并特征。然后,低层特征通过两个连续的基于DenseNet的单元(称为稠密单元)[28]来提取Bm中更全面的特征。最后,将所有M个分支提取的特征串接在一起,用两个稠密单元进一步处理,提取高层次特征。为了便于训练,最后一个稠密单元(用F△(n)表示)的输出被视为差分帧,而增强帧FE(n)是F△(n)和FU(n)的总和。MIF-Net组件的详细信息如下所示。
的信息,每个分支Bm处理对应的参考帧FR(m,n)。在分支Bm中,首先通过运动补偿网络将参考帧FR(m,n)与URF FU(n)对齐,产生补偿帧,用FC(m,n)表示。然后,在FU(n)的CTU划分结构(块自适应卷积层)的指导下,利用一种新的卷积层对FU(n)和FC(m,n)进行处理,以探索不同来源的低层特征,并结合CU和TU划分合并特征。然后,低层特征通过两个连续的基于DenseNet的单元(称为稠密单元)[28]来提取Bm中更全面的特征。最后,将所有M个分支提取的特征串接在一起,用两个稠密单元进一步处理,提取高层次特征。为了便于训练,最后一个稠密单元(用F△(n)表示)的输出被视为差分帧,而增强帧FE(n)是F△(n)和FU(n)的总和。MIF-Net组件的详细信息如下所示。
运动补偿网络。 一般来说,由于帧间的时间运动,参考帧FR(m,n)的内容不同于FU(n)的内容。因此,我们提出了基于空间变压器运动补偿(STMC)模型[46]的运动补偿网络,用于FR(m,n)和FU(n)之间的内容对齐,如图10-(a)所示。在文献[46]中,STMC模型以FR(m,n)和FU(n)为输入,得到一个补偿帧作为输出,用FSTMC(m,n)表示,STMC由两条分别用于预测两个输入帧之间的粗略和精细运动矢量(MV)映射的路径(×4和×2下标度路径)组成。每个路径包含一系列卷积层和一个上尺度层,并且将×2下尺度路径的精细MV映射应用于FR(m,n)以输出FSTMC(m,n)。在STMC中,x 2和x 4下采样能够估计各种运动尺度。但是,由于下采样,STMC的精度受到限制,STMC的体系结构也可以得到改进。为了解决这个问题,我们提出了一个运动补偿网络,它比[46]中的STMC有以下改进。
- 除了×2和×4缩减路径外,还添加了不缩减采样的满采样路径,以提高MV估计的精度。如图10-(a)所示,将来自STMC的FR(m,n)、FU(n)、FSTMC(m,n)和×2mv映射串接在一起并输入到该路径,然后通过卷积层进行处理以生成最终的MV映射。此路径上的所有卷积层的步长为1,保持特征映射的大小与FR(m,n)和FU(n)相同。
- 受ResNet [47]的启发,在卷积层旁边总共添加了6个快捷方式,以提高网络容量并易于训练。请注意,根据每个快捷方式前后的特征图数量/大小,将同时使用标识快捷方式和投影快捷方式。
- 激活STMC中卷积层的所有整流线性单元(ReLU)[48]被PReLU取代,以自适应地学习整流参数[45]。
通过上述修改,满标度路径输出两个MV图,MX(m,n)和BY(m,n)表示从FR(m,n)到FU(n)的所有像素的水平和垂直运动。最后,通过
![]()
其中x和y是像素的坐标,Bil{·}表示双线性插值,考虑到运动可能是非整数像素。
块自适应卷积层。 在MIF-Net的每个分支中,对补偿帧FC(m,n)和URF FU(n)进行卷积层处理,以适应HEVC中的CU和TU划分。这个层的输入是三个特征映射的串联,包括FC(m,n)、FU(n)和FC(m,n) - FU(n)。除了FC(m,n)和FU(n),FC(m,n) - FU(n)也有意义。这是因为FC(m,n) - FU(n)反映了FC(m,n)作为FU(n)的参考框架的可靠性,因为FC(m,n)和FU(n)的两个共同U(n)位置部分之间的过大距离可能表明这些部分的运动补偿无效。在这一层中,FU(n)的CU和TU分区分别由Cn和Tn两个特征映射表示。Cn或Tn的大小等于FU(n)的大小,每个映射中的值根据分区结构进行分配。如果像素(x,y)位于CU或TU的边界上,则相应的值Cn(x,y)或Tn(x,y)设置为1。否则,该值设置为-1。然后,块自适应卷积层的目标是输出一定数量的特征映射,提供三个特征映射作为输入,两个特征映射作为引导。对于这个问题,我们在算法1中提出了一种引导卷积操作,假设分别使用PI、PG和PO特征映射作为输入、引导和输出。该算法包括两个主要步骤:
- 中间图提取(第1行):从引导特征图提取各种特征,同时确保中间特征图的数量等于输出通道PO。
- 中间卷积(第2∼9行):根据中间特征映射自适应调整权重的卷积。
与在整个特征映射中共享空间无关权重的典型卷积层相比,该算法的主要进步在于根据引导生成的空间相关权重(见算法1的第5行),有助于提高网络容量。此外,由于中间图提取只增加了卷积而不增加全连接,因此可训练参数的个数没有急剧增加,导致过拟合的风险很小。对于MIF-Net中的每个块自适应卷积层,如上所述PI=3和PG=2,并且输出映射的数目被设置为PO=12。
提高质量的密集单元。 在[28]中,Huang等人提出了一种有效的CNN变体DenseNet,它在输入和输出之间引入了不同长度的连接。与普通CNN或ReNET[ 47 ]相比,DenseNet训练深度网络的效率主要来自于消除梯度消失、鼓励特征重用和降低计算复杂度。考虑到这些显著的优点,我们的MIF网采用了(2M+2)个密集单元来提高质量,即在每个分支中使用2个密集单元,在MIF网的末端使用2个密集单元来合成所有M个分支的特征。这里,所有的密集单元都具有相同的结构,如图10-(b)所示。每个密集单元包含4个卷积层,并且在每一层之前,来自前面所有层的特征连接在一起。因此,密集单元包括10个层间连接,比只有4个连接的4层普通CNN要多得多。在密集单元的每一层,输出通道的数目是12个,除了最终密集单元的最后一层,它只输出1个通道作为FE(n)和FU(n)之间的差分帧。

D. MIF-Net 和 IF-Net 之间的区别
上一节详细介绍了我们的MIF-Net,下面介绍了IF-Net,它是MIF-Net的一种较简单的对应形式,如果找不到足够的URF参考帧,则采用该形式。IF-Net和MIF-Net之间的唯一区别在于IF-Net中不存在FU(n)的M个参考帧。 因此,在IF-Net中仅采用没有运动补偿的质量增强网络,如图9中的红色箭头所示。与MIF-Net相比,在IF-Net中仅存在一个没有补偿帧的分支B1,并且级联 省略了合成M个分支的步骤。尽管很简单,但在IF-Net中仍然存在引导卷积层和四个连续的密集单元,从而确保了足够的网络容量来提高质量。

E. MIF-Net 和 IF-Net 的训练
通过在M个分支中同时进行运动补偿和质量增强,MIF-Net是一种端到端的深度神经网络,可能难以通过直接最小化FE(n)和F(n)之间的差异来对其进行训练。为解决此问题,我们建议进行训练 具有中间监督的MIF-Net [49],通过在MIF-Net中引入两个损失函数来优化整个阶段的整个网络。 首先,FU(n)与M个补偿帧FC(m,n)中的每一个之间的差可以衡量运动补偿网络的性能,因此将其定义为中间损耗

其中![]() 表示两帧之间的“2-范数差”。其次,FEn和Fn之间的“2-范数差”表示整个MIF网络的性能,全局损失定义为
表示两帧之间的“2-范数差”。其次,FEn和Fn之间的“2-范数差”表示整个MIF网络的性能,全局损失定义为
![]()
结合上述两个损失函数,我们的MIF-Net的损失L是它们的加权和,公式如下
![]()
在这里,α和β是可变权重,L通过Adam[44]进行了优化。 由于质量增强的最佳性能取决于训练有素的运动补偿网络,因此应在训练的早期阶段通过将α>>β设置为较大的权重来优化中间损失LINT。 在LINT收敛后,我们改为设置β>>α,以便更多地强调全局损失LGLO的优化。 通过两个训练阶段,可以使用M个选定的参考系显着增强URF FU(n)。与MIF-Net相比,考虑到没有运动补偿,IF-Net的训练过程更加容易。在IF-Net中,三个密集单元中的可训练参数可以由训练良好的MIF-Net中的参数初始化,无需从头训练。此外,如果IF-Net的损失与MIF-Net的LGLO相同,Adam可以直接对其进行优化。
V. 语法规范
在我们的MIF方法中,一些关于RFS和滤波模式选择的控制数据应该由编码器和解码器共享,因此,为每个URF FU(n)调整相应的语法,如表3所示。语法调整的细节如下所示。
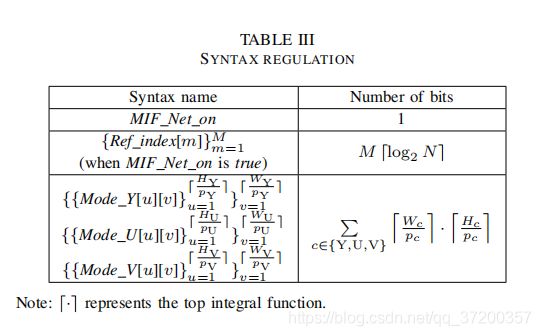
RFS的语法。 首先,MIF_Net_on会根据RFS选择的参考帧的数量,发出是否采用MIF-Net的信号。如果MIF_Net_on为true,则激活Ref_index以表示M个参考帧的索引,这些参考帧是由RFS从N帧池中选择的。为了节省比特率,只对参考帧和FUn之间的距离(即|i - n|满足n - N ≤ i ≤ n - 1)进行编码,而不是对绝对帧索引N进行编码。因此,用于编码参考索引的比特数是M ![]()
滤波模式选择的语法。 除RFS外,滤波模式的选择也被编码以指示URF是由所提出的网络处理还是由标准的环路内滤波器处理。对于每个信道c∈{Y,U,V},假设帧的大小是Wc×Hc。考虑到同一滤波模式可能不适合帧的不同块,在pc×pc块中进行选择。这里,帧可以被划分为![]() 不重叠的块,语法模式_c[u][v]表示所提出的网络是否用于(u,v)-th块。如果由MIF Net处理的修补程序的质量或如果Net高于由标准DBF和SAO过滤的修补程序的质量,则模式c[u][v]设置为true,否则设置为false。考虑到可调块宽度,较小的pc表示更精细的模式选择易于获得更好的帧质量,但由于语法Mode c的编码位而引入了更多的比特率冗余。 相反,较大的pc意味着较少的语法位,同时导致较低的帧质量。因此,需要权衡选择一个合理的pc,第VI-A节讨论了pc的价值。
不重叠的块,语法模式_c[u][v]表示所提出的网络是否用于(u,v)-th块。如果由MIF Net处理的修补程序的质量或如果Net高于由标准DBF和SAO过滤的修补程序的质量,则模式c[u][v]设置为true,否则设置为false。考虑到可调块宽度,较小的pc表示更精细的模式选择易于获得更好的帧质量,但由于语法Mode c的编码位而引入了更多的比特率冗余。 相反,较大的pc意味着较少的语法位,同时导致较低的帧质量。因此,需要权衡选择一个合理的pc,第VI-A节讨论了pc的价值。
VI. 实验结果
在这一部分中,我们通过实验结果来评估我们的MIF方法的性能。第VI-A节介绍了实验中的设置。在第VI-B节中,我们对RA配置下MIF方法的客观和主观表现进行了评估,并与HM基线和两种最新方法进行了比较,[10]和[20]。在第VI-C节中,我们进一步验证了MIF方法在不同环境下的有效性和泛化能力。最后,在第VI-D节中进行了消融研究。
A. 设置
实验配置。 在我们的实验中,所有的环路滤波方法都被纳入了HEVC参考软件HM 16.5[43]。RA配置是使用文件编码器randomaccess_main.cfg[50]在四个QPs{22、27、32、37}下应用于网络训练和性能评估的。我们的HIF数据库中的120个训练序列被用来训练网络,并在40个验证序列上调整超参数。请注意,所有视频序列都是YUV格式的。在训练阶段,MIF-Net和IF-Net只输入Y通道。这是因为Y通道是包含大多数视觉信息的亮度。因此,在测试阶段,在Y通道上训练的模型直接用于所有三个通道。在测试阶段,我们将块宽度(在第V节中介绍)设置为pY = pU = pV = 256。对于性能评估,测量Bjøntegaard delta比特率(BD-BR)和Bjøntegaard delta PSNR(BD-PSNR)[51]以评估速率失真(RD)性能。总共对40个视频序列进行了评估,其中包含JCT-VC标准测试集的所有18个序列[42]和我们的HIF数据库中的22个测试序列,称为补充测试集。注意,测试序列与训练和验证序列不重叠。所有的实验都是在一台4.2ghz的英特尔(R)酷睿i7-7700kcpu、32gb RAM和Ubuntu 16.04(64位)操作系统的计算机上进行的。此外,还使用了GeForce GTX 1080 GPU来加速训练过程。
网络设置。 在我们的方法中,为每个评估的QP训练了一个MIF-Net模型和一个IF-Net模型,而所有QP都共享相同的训练后的RFS-Net模型。表IV列出了针对这些网络调整的超参数。 为了训练MIF-Net和IF-Net的模型,将所有帧分割为64×64的块。考虑到训练的效率,QP=32时的IF-Net或MIF-Net模型是从头开始训练的,而QPs{22、27、37}时的模型是从训练模型中微调的。

B. 性能分析
客观的RD性能。 首先,我们根据BD-BR和BD-PSNR评估MIF方法的客观RD性能,并与HM基线(标准DBF和SAO)、启发式方法[10]和基于学习的方法[20]进行比较。为了公平比较,我们在HIF数据库中重新训练了[20]的模型。表V列出了所有四种方法的RD结果,其中未使用环路内滤波器的原始HM用作锚定。如表V-(a)所示,我们的MIF方法的BD-BR在18个标准测试序列中平均为-11.621%,优于DBF和SAO的-5.031%,[10]的-6.295%和[20]的-9.227%。此外,表V-(b)显示,我们的方法的平均BD-BR比补充测试集高出-12.607%,并且它也显著优于其他三种方法,即DBF和SAO的-4.449%,[10]的-5.746%和[20]的-9.942%。在BD-PSNR方面,我们的方法在标准测试集中达到了0.391db,在补充测试集中达到了0.502db,也大大优于DBF和SAO(0.162db和0.167db),[10](0.201 dB和0.219db)和[20](0.305dB和0.392db)。产生这种性能的可能原因包括:(1)多个相邻帧的利用率;(2)有效密集块;(3)提出的块自适应卷积层。它们对RD增益的贡献将在第VI-D节中进行分析。


主观视觉质量。 接下来,我们比较所有四种方法的主观质量。图11举例说明了在QP=37时压缩的压缩视频序列的一些区域和RA配置。对于RaceHorses,可以观察到当被DBF和SAO,[10]和[20]压缩时,马尾的边缘会严重模糊。相比之下,在我们的MIF方法增强后,马尾的边缘更加清晰。此外,与其他三种方法相比,通过我们的方法,PeopleOnStreet中的行人和FourPeople中的手,显着减少了阻塞伪像。这些示例表明,我们的方法可能具有更好的压缩视频视觉质量,并且在帧的移动区域可能更容易观察到质量增强。 此外,我们还在线上传了由我们的MIF方法和标准HEVC编码的22个测试序列的比特流文件。使用相应的解码器,我们的MIF方法可以观察到所有帧的视觉质量。

时间复杂度。 此外,我们分析了我们的MIF方法和其他自适应环路滤波器[10],[20]引入的复杂性开销。首先,用T(HM)表示的HM[43]中编码一帧的运行时间在表VI中给出。首先,用T(HM)表示的在HM[43]中编码一个帧的运行时间在表VI中提供。基于此,我们还测量了每个环路内滤波器引入的时间开销T(f),并将表VI其余部分中的比率![]() 制成表格。较大的比率
制成表格。较大的比率![]() 表示环路内滤波器的相对较多的时间开销。请注意,此表中的结果是所有具有相同分辨率的JCT-VC测试序列的平均值。考虑到GPU可以显着加速基于学习的环路滤波器,因此对于我们的MIF方法和RHCNN [20],都提供了使用和不使用GPU的结果。在这里,上述基于学习的方法是在开源机器学习框架TensorFlow(TM)[53]上实现的。对于我们的方法和[20],我们分别记录了仅使用CPU和使用CPU + GPU的计算时间。我们可以从表VI中观察到,当仅使用CPU时,启发式方法[10]会在三种方法中引入最少的时间开销。但是,得益于GPU加速,我们的MIF方法和基于RHCNN的环路滤波器可以得到大幅加速。结果,在表VI中,我们使用GPU的方法消耗的时间最少,分别比使用GPU的RHCNN [20]和仅使用CPU的启发式环路滤波器[10]快2.4到23.5倍。从以上分析可以看出,提出的MIF作为基于学习的环路滤波器,在时间复杂度方面是一种有效的方法。
表示环路内滤波器的相对较多的时间开销。请注意,此表中的结果是所有具有相同分辨率的JCT-VC测试序列的平均值。考虑到GPU可以显着加速基于学习的环路滤波器,因此对于我们的MIF方法和RHCNN [20],都提供了使用和不使用GPU的结果。在这里,上述基于学习的方法是在开源机器学习框架TensorFlow(TM)[53]上实现的。对于我们的方法和[20],我们分别记录了仅使用CPU和使用CPU + GPU的计算时间。我们可以从表VI中观察到,当仅使用CPU时,启发式方法[10]会在三种方法中引入最少的时间开销。但是,得益于GPU加速,我们的MIF方法和基于RHCNN的环路滤波器可以得到大幅加速。结果,在表VI中,我们使用GPU的方法消耗的时间最少,分别比使用GPU的RHCNN [20]和仅使用CPU的启发式环路滤波器[10]快2.4到23.5倍。从以上分析可以看出,提出的MIF作为基于学习的环路滤波器,在时间复杂度方面是一种有效的方法。

C. 各种设置的分析
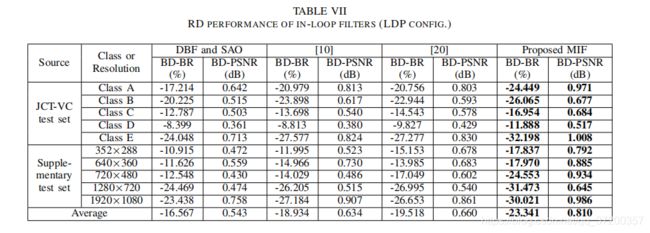
传输到LDP配置。 在这一部分中,我们首先通过传输学习来评估我们的MIF方法在LDP配置下的RD性能,以验证其泛化能力。MIF-Net和IF-Net在所有四个QPs{22、27、32、37}处的模型都是由对应QPs处的RA配置的模型初始化的。然后,他们对LDP配置的HIF数据库进行了微调。文件编码器lowdelay P main.cfg[50]在传输学习和性能评估期间应用,而其他实验设置遵循RA配置,如第VI-A节所述。表VII显示了所有四种方法在LDP配置下的RD性能。请注意,结果是通过JCT-VT标准测试集和我们的补充测试集以不同类别/分辨率报告的所有序列的结果。从表VII可以看出,我们的MIF方法平均达到BD-BR的-23.341%,优于DBF和SAO的-16.567%,[10]的-18.934%和[20]的-19.518%。在BD-PSNR方面也可以找到类似的结果。总之,我们的MIF方法在LDP配置下的有效性和泛化能力得到了验证。
帧质量统计 为了更好地理解我们的MIF方法的性能,分析不同的环路滤波器对帧质量的统计数据很有帮助。除了PSNR,还加入了结构相似性(SSIM)[54]来评价视频序列的视觉质量。正如在[54]中所测试的,SSIM比PSNR对主观视觉质量的预测要好得多。图12-(a)举例说明了序列kristandsara的前100帧的质量波动,以我们的MIF方法、标准HEVC和两种最新方法[10]、[20]为例进行了评估。可以看出,我们的MIF方法在总体PSNR和SSIM方面优于其他三种方法。而且,我们的方法的质量波动小于其他方法。为了更全面的分析,我们进一步比较了四种方法编码的视频序列的PSNR和SSIM的统计信息,如图12-(b)所示。在这里,结果在所有18个JCT-VC测试序列中以QPs{22,27,32,37}的RA配置进行平均。从图12-(b)分析,我们的方法达到了37.533db的平均峰值信噪比,大大高于其他三种方法。此外,我们的方法的PSNR标准偏差为0.776db,小于标准HEVC的0.791db,[10]的0.787db和[20]的0.786db。对于SSIM的平均值和标准差,可以找到类似的结果。以上分析验证了我们的MIF方法可以达到更好的整体质量和更低的压缩视频质量波动。这得益于多帧设计,在多帧设计中,使用其他高质量帧可以显著增强低质量帧。

与基于学习的JVET环路滤波器的比较。 考虑到JVET提出的基于学习的环路内滤波器已经取得了显著的成绩,对其性能进行评估也是非常必要的。为此,我们将MIF方法与两个序列无关的VVC滤波器,即剩余权重共享CNN[35]和稠密剩余CNN[36]进行了比较。注意,过滤器[35],[36]在HM[43]中为HEVC重新实现。为了进行公平的比较,[35],[36]的模型都在我们的HIF数据库上进行了重新训练。表VIII显示了三种方法在QPs为{22,27,32,37}的RA配置下的RD性能。在这个表中我们可以发现我们的方法的平均BD-BR是-12.184%,优于[35]的-7.875%和[36]的-9.004%。在BD-PSNR方面,也有类似的结果。仔细观察,就BD-BR和BD-PSNR而言,在表VIII中两个测试集的每个分辨率上,我们的方法也比其他两种方法表现更好。因此,与JVET中两种新的环路滤波方法相比,我们的MIF方法的有效性和稳定性得到了验证。
D.消融研究
我们进一步进行了一系列的烧蚀实验来研究我们方法中主要成分的有效性。我们的消融研究从标准的环路滤波器开始,然后逐步添加某些成分,最终达到所提出的MIF方法。图13显示了RA配置的RD性能。更多细节将在下面讨论。
普通CNN与标准环路滤波器。 在标准DBF和SAO中,过滤过程是预先确定的,没有任何可训练的参数,这在减少具有不同内容的压缩伪像方面受到限制。相比之下,我们用一个简单的基于CNN的滤波器代替了标准的DBF和SAO,提供了足够的可训练参数。为简单起见,普通CNN由4个连续卷积层组成,用于生成差分帧F,不需要任何密集单元、块自适应卷积层和多帧利用。从图13可以看出,与标准DBF和SAO相比,普通CNN节省BD-BR,提高RD性能4.381%,增加BD-PSNR 0.147db。
有密集单位的CNN和普通的CNN对比。 为了分析网络拓扑结构的影响,我们用4个连续的稠密单元替换了普通CNN中的4个卷积层,即将普通CNN变换成不带块自适应卷积的IF网络。注意,在有和没有稠密单元的两个网络中,可训练参数的数目是相同的,每个都包含47196个卷积权重。 从图13中可以看出,当在建议的环路滤波器中实现时,密集单元的性能优于CNN的普通类型,可节省BD-BR 0.891%,并增加0.032 dB BD-PSNR。 如[28]中讨论的,致密单元有效的一些可能原因包括:(1)特征重用以提高参数效率,(2)具有不同深度的柔性拓扑以便于收敛,(3)隐式深度监督使中间层学习区分特征。
IF-Net带或不带块自适应卷积对比。 在HEVC中,灵活的CTU分区结构对压缩伪影有明显的影响,尤其是对块效应的影响,因此提出了一种块自适应卷积层来处理这种伪影。通过对两个有无块自适应卷积的网络进行性能评估,分析了其有效性,在RD性能方面,有块自适应卷积的IF-Net优于无块自适应卷积的IF网络,BD-BR下降0.411%,PSNR增加0.015db。块自适应卷积算法优于典型卷积算法,因为CTU结构对HEVC中的压缩伪影,特别是块伪影有影响。
IF-Net加MIF-Net和仅有IF-Net对比。 在我们的MIF方法中,多帧的利用是提高每个URF质量的主要贡献。在这里,我们研究了使用和不使用MIF-Net的方法的RD性能。请注意,在使用MIF-Net评估性能时启用了RFS。如图13所示,我们使用IF-Net和MIF-Net的方法优于仅使用IF Net的设置(BD-BR减少0.907%,BD-PSNR增加0.035db)。这些结果验证了利用多个帧进行循环内过滤器的有效性。多帧设计是有效的,因为相邻帧之间总是存在相当大的质量波动,并且低质量帧可以通过其相邻的高质量帧来增强。
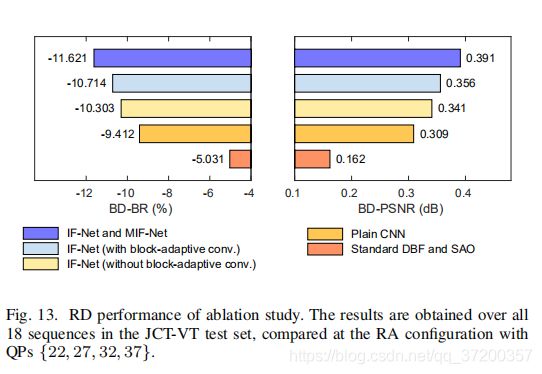
通过以上分析,与普通CNN相比,三种主要的网络结构有助于提出MIF方法。其中,性能的提高主要得益于多帧的利用率和高效的密集单元。同时,新的块自适应卷积在一定程度上提高了RD的性能。因此,这种网络配置有益的原因在于高级拓扑本身(即密集单元)和压缩伪影的特定特性(即多帧设计和块自适应卷积)。
VII. 结论
本文针对HEVC提出了一种基于深度学习的MIF方法。与现有的基于单个帧的环路滤波方法不同,我们的MIF方法通过利用多个相邻帧来学习增强一帧的视觉质量。为此,我们首先构建了一个大规模的HIF数据库,发现通常有足够数量的参考帧具有较高的质量和相似的内容。根据我们的观察,我们设计了选择这些参考框架的RFS。利用HIF数据库,提出了一种深度MIF网络模型,利用URF的空间信息和所选参考帧的时间信息来提高各URF的质量。MIF-Net模型是由新开发的DenseNet构建的,具有更好的泛化能力和计算效率。同时,考虑到HEVC中CTU结构对块效应的影响,提出了一种新的块自适应卷积层。最后,客观实验和主观实验都表明,我们的MIF方法明显优于标准的环路滤波器和其他最新的HEVC方法。对于未来的工作,还可以利用与压缩伪影(例如跳跃模式、预测单元划分、运动矢量和残余帧)相关的更多各种细节,有可能进一步提高环路内滤波器的性能。此外,使用一些技术可以加速深层神经网络的实现[55]。因此,未来另一项工作是应用这些技术加速我们的MIF方法。