Lucene介绍与入门使用
lucence简介
先来叭叭一段lucence的简介
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
从这段描述中可以提取关键词全文检索,什么是全文检索呢?
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
从检索的描述中再普及一个知识点:结构化数据和非结构化数据
(1)结构化数据:指具有固定格式或有限长度的数据,如orcal或者mysql等数据库,元数据等。
(2)非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件
对于结构化数据,比如数据库中的数据存储是有规律的,有行有列而且数据格式、数据长度都是固定的。搜索就很容易实现,通常都是使用sql语句进行查询,而且能很快的得到查询结果。
而对于非结构化数据,就是采用顺序扫描法(比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。)全文检索等方法
Luncence全文检索的图片如下。
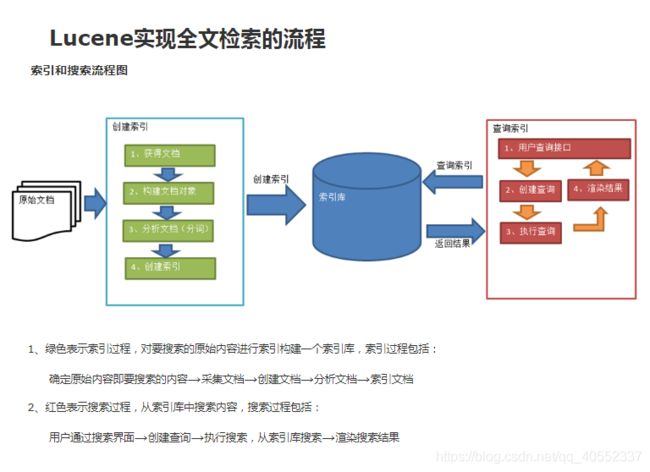
对于这种图片的解释。可以查看下面博客。https://www.cnblogs.com/xiaobai1226/p/7652093.html 写的很清楚
1.创建索引
①获取原始文档。原始文档是指要索引和搜索的内容。原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。
使用搜索引擎进行网络爬虫。或者通过IO流,sql语句都可以获得表中的数据。
②构建文档对象(Document)
一个Document对象中方的可以是一个网页的内容,一个文件的内容,或一个数据库表中的某条数据等等。
③分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元,可以将语汇单元理解为一个一个的单词。
比如:What is diffrence between Lucence and Solr
按照 空格分词,处理大小写,停用词,标点符号 等方式进行分析文档操作,可得到如下
diffrence luncence Solr
④创建索引(存储)
分析后的格式,比如 name:luncence (其中name是自定义的域名称,此域中的值 name:luncence 就是一个词汇term
一个文档中可以有多个域
注意:创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。
比如说查字典,我们可以按照部署或者拼音首字母去查。一个部署或者一个拼音定位到一个字。从小到大。这种索引的结构 叫 倒 排索引结构。
2 .查询索引
①用户查询接口。就是用户用来输入查询关键词的地方
②创建查询
③执行查询
④渲染结果
=====================================================================
现在来个入门案例(给磁盘的文件创建索引)
需要的核心jar包:lucence-core-4.10.3.jar luncen-amalyzers-common-4.10.3.jar,common-io-2.4.jar
引入上述包之后,执行以下代码
public class FirstDemo {
public static void main(String[] args) throws IOException {
//1.先指定索引的位置
Directory directory = FSDirectory.open(new File("C:\\demofile\\indexRepo"));
// 指定分词器
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
// 2、创建写入索引的对象
IndexWriter indexWriter = new IndexWriter(directory, config);
// 3、获取源文档
File srcFile = new File("C:\\demofile\\searchsource");
File[] listFiles = srcFile.listFiles();
for (File file : listFiles) {
Document doc = new Document();
// 1、文件名称
String fileName = file.getName();
Field nameField = new TextField("name", fileName, Store.YES);
doc.add(nameField);
// 2、文件大小
long fileSize = FileUtils.sizeOf(file);
Field sizeField = new TextField("size", fileSize+"", Store.YES);
doc.add(sizeField);
// 3、文件路径
String filePath = file.getPath();
Field pathField = new TextField("path", filePath, Store.YES);
doc.add(pathField);
// 4、文件内容
String fileContent = FileUtils.readFileToString(file);
Field contentField = new TextField("content", fileContent, Store.YES);
doc.add(contentField);
// 4、把文档写入索引库
indexWriter.addDocument(doc);
}
// 5、关闭资源
indexWriter.close();
}
} 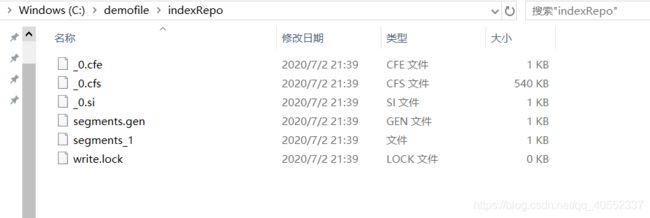
生成的文件如上。生成的文件是无法直接打开的。需要使用luke打开。
运行lukeall,如果需要加载第三方分词器,需通过-Djava.ext.dirs加载jar包:
可简单的将第三方分词器和lukeall放在一块儿,cmd下运行:
java -Djava.ext.dirs=. -jar lukeall-4.10.3.jar
上面是将查询的结果创建索引存入某个地方。现在再写一个demo来读取。
public class SecondDemo {
public static void main(String[] args) throws IOException {
//1、指定索引库的位置
Directory directory = FSDirectory.open(new File("C:\\demofile\\indexRepo"));
// 2、创建读取索引对象
// IndexWriter
IndexReader indexReader = DirectoryReader.open(directory);
// 3、创建查询索引对象
IndexSearcher searcher = new IndexSearcher(indexReader);
// 4、执行查询方法 query:指定条件, n:查询数据量的限制
Query query = new TermQuery(new Term("content", "spring"));
// 5、获取查询结果
TopDocs topDocs = searcher.search(query, 100);
System.out.println("总记录数:"+topDocs.totalHits);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int docID = scoreDoc.doc;
Document doc = searcher.doc(docID);
// 获取文档的内容
System.out.println("文件名:"+doc.get("name"));
System.out.println("文件大小:"+doc.get("size"));
System.out.println("文件路径:"+doc.get("path"));
// System.out.println("文件内容:"+doc.get("content"));
System.out.println("************************************************************************");
System.out.println("************************************************************************");
}
// 6、关闭资源
indexReader.close();
}
}
上述代码的步骤总结如下
1.创建索引
①指定索引库的位置(Directoty) ②创建写入索引的对象(IndexWriter) ③获得原始文档IO流
④把文档写入索引库(indexWriter.addDocument(doc)); ⑤关闭资源IndexWriter
2.查询索引
①指定索引库的位置 ②创建读取索引对象 ③创建查询索引对象 ④执行查询方法 query:指定条件, n:查询数据量的限制
⑤获取查询结果 ⑥关闭资源
分析器
分析器(Analyzer)的执行过程

从一个Reader字符流开始,创建一个基于Reader的Tokenizer分词器,经过三个TokenFilter生成语汇单元Token。
要看分析器的分析效果,只需要看Tokenstream中的内容就可以了。每个分析器都有一个方法tokenStream,返回一个tokenStream对象。
先使用标准分词器,代码效果演示如下:
public static void main(String[] args) throws IOException {
//创建一个标准分析器对象
Analyzer analyzer = new StandardAnalyzer();
//获得tokenStream对象
//第一个参数:域名,可以随便给一个
//第二个参数:要分析的文本内容
TokenStream tokenStream = analyzer.tokenStream("test", "The Spring Framework provides a comprehensive programming and configuration model.");
//添加一个引用,可以获得每个关键词
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
//将指针调整到列表的头部
tokenStream.reset();
//遍历关键词列表,通过incrementToken方法判断列表是否结束
while(tokenStream.incrementToken()) {
//取关键词
System.out.println(charTermAttribute);
}
tokenStream.close();
}

对于中文,有 CJKAnalyzer分词器(二分法分词:按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”“国人”)
这个分词效果不太好。建议使用SmartChineseAnalyzer(对中文支持较好,但扩展性差,扩展词库,禁用词库和同义词库等不好处理)
效果如下

使用第三方分词器
使用方法:
第一步:把jar包添加到工程中
IKAnalyzer2012FF_u1.jar
第二步:把配置文件和扩展词典和停用词词典添加到classpath下
比如我再src同级目录下放入三个文件。

其中xml文件里面的配置如下
IK Analyzer 扩展配置
ext.dic;
stopword.dic;
注意:mydict.dic和ext_stopword.dic文件的格式为UTF-8,注意是无BOM 的UTF-8 编码。
其余步骤和上述相似。
只不过创建分词器对象改为 Analyzer analyzer = new IKAnalyzer();
Analyzer使用时机
①输入关键字进行搜索,当需要让该关键字与文档域内容所包含的词进行匹配时需要对文档域内容进行分析,需要经过Analyzer分析器处理生成语汇单元(Token)。分析器分析的对象是文档中的Field域。当Field的属性tokenized(是否分词)为true时会对Field值进行分析,如下图:
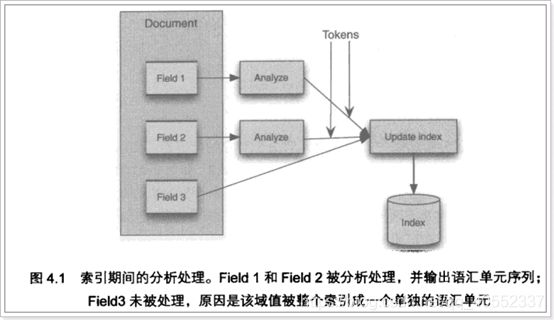
对于一些Field可以不用分析:
1、不作为查询条件的内容,比如文件路径
2、不是匹配内容中的词而匹配Field的整体内容,比如订单号、身份证号等。
② 搜索时使用Analyzer
对搜索关键字进行分析和索引分析一样,使用Analyzer对搜索关键字进行分析、分词处理,使用分析后每个词语进行搜索。比如:搜索关键字:spring web ,经过分析器进行分词,得出:spring web拿词去索引词典表查找 ,找到索引链接到Document,解析Document内容。
对于匹配整体Field域的查询可以在搜索时不分析,比如根据订单号、身份证号查询等。
注意:搜索使用的分析器要和索引使用的分析器一致。