语音识别WFST核心算法讲解(1. WFST的基本概念)
本系列主要介绍语音识别WFST中的常用算法, Composition, Determinization, Minimization, Epsilon Removal, Weight Pushing 等。了解这些算法的前提是熟悉WFST基本概念,了解Semiring(半环代数理论), 对图中各类算法(深度优先搜索DFS,最大强连通域SCC)等。因此我们首先介绍WFST的基本概念。
伪代码和部分图片参考自书本《Speech Recognition Algorithms Using Weighted Finite-State Transducers》作者是TakaakiHori AtsushiNakamura.
半圆环的官方解释如下:
A semiring is similar to a ring, which is also an algebraic structure, but the existence of additive inverse is not required. A semiring is defined as (K, ⊕, ⊗, 0 ̄ , 1 ̄ ), where K is a set of elements, ⊕ and ⊗ are two formally defined binary operations, i.e., “addition” and “multiplication,” over K, 0 ̄ is an additive identity element, and 1 ̄ is a multiplicative identity element
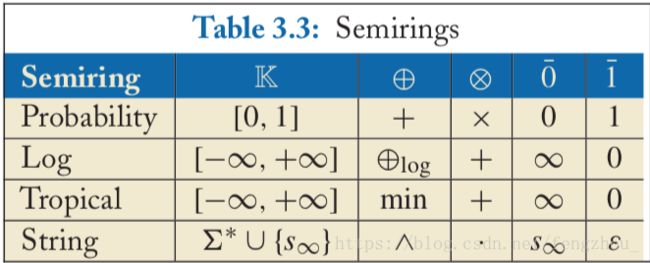
语音识别WFST中的半圆环通常是Tropical Semiring。
A WFST over a set of weight elements K is formally defined by an 8-tuple (∑, ∆, Q, I, F, E, λ, ρ) where:
1. ∑ 是输入集合
2. ∆ 是输出集合
3. Q 是所有的状态集合
4. I ⊆ Q 是初始状态集合,Openfst中一般只有1个
5. F ⊆Q 是终止状态集合, 通常有1个或多个
6. E⊆Q×(∑∪{ε})×(∆∪{ε})×K×Q 代表所有状态之间的转移集合
7. λ : I → K 是初始状态的权重
8. ρ : F →K 是终止状态的权重
在此举个例子详细解释,如下图为某个WFST:
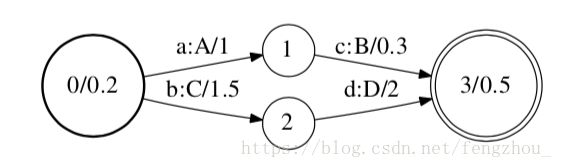
如上图,0是起始状态,λ(0) = 0.2, 3是终止状态,ρ(3) = 0.5,Q = {0, 1, 2, 3}, ∑={a, b, c, d}, ∆ = {A, B, C, D}.
对一些之后会用到的符号的意义解释如下,给定WFST =(∑,∆,Q,I,F,E,λ,ρ), 对任意状态q ∈Q, E[q]为从q出发的所有转移集合, 对于每个转移 e ∈ E, 输出label是 i[e], 输出label是o[e], 出发状态 p[e], 到达状态 n[e], 转移上的权重 w[e]. 一系列转移组成路径 π = e1, … , ek , 明显可以知道 n[ej−1] = p[ej ] 对于 j = 2,…,k. 用 n[·] 和p[·] 表示路径 n[π] = n[ek] and p[π] = p[e1].
如果路径中n[e1]∈I 并且n[ek ] ∈ F, 则这条路径叫做 successful path。
如果一个状态能通过一系列转移从起点到达并且能通过转移到达某个终点,这个状态是coaccessible的, 所有coaccessible的状态都在至少一条successful path上。 其他状态叫做dead states。去除所有dead states这一操作叫做trimming或者 connect,Openfst的中wfst的Connect的算法(仅一次遍历整个图)是使用Tarjan’s Algorithm寻找最大强连通域SCC,在此不做详细解释。
WFST基本的概念和一些表示符号介绍如上,其他一些概念会在介绍相应算法时引入。