一文理解Redis的数据结构
Redis基础篇
介绍一下redis的历史、SQL和NoSQL的一些区别、redis的安装、常用的五种数据类型的存储原理,其它4中数据类型只是简单做了一下了解。希望能够从中学习到一些数据结构设计的思想。关于命令的操作文中有链接,其中的命令描述非常详细,这里就不在写了。
1、Redis的历史
2008年意大利的一个叫做antirez的老哥,搭建了一个可以记录网站访问情况的一个网站LLOOGG.com,最初它最多查看一万条最新的记录,它为每一个网站创建了一个列表,不同网站的访问情况对应不同的列表,这些列表存储在了Mysql中。但是当列表满了的时候,它会删除掉最早的记录,并且在用户增加的情况下,维护列表的数量也会增加,那么记录和删除的操作也会比较频繁,由于数据是存储在Mysql中,也就是磁盘中,限制了网站的性能,因此antirez就考虑将数据放在内存中,这样添加和删除的效率将会大大提高。
Redis的全称是REmote DIctionary Service,也就是远程字典服务的意思。
2、Redis的定位和特性
首先了解一下SQL和NoSQL的一些区别:
2.1SQL和NoSQL
关系型数据库
特点
1.数据是以表格的形式存储,也就是行存储,是一个二维的结构,存储结构化的数据。
2.表格有相应的结构
3.表格之间是有关联的
4.基本上都支持SQL标准
5.支持事务的操作,事务特性ACID
限制:
1、扩容只能向上扩容,水平扩容需要使用分库分表技术
2、数据存储的格式有限制,也就是表结构固定后,修改比较麻烦
3、高并发、数据量大的情况下,基于磁盘的读写压力比较大
非关系型数据库
non-relational | not only SQL
特点
1、存储的非结构化的数据,可以存储图片、视频、音频等数据。
2、表与表之间没有关联,扩展性强
3、没有事务特性,遵循BASE理论
4、数据不是存储在磁盘,支持海量存储,支持高并发
5、分布式,实现水平扩容和分片存储更加简单
2.2 Redis的特性
1、丰富的数据结构
2、进程内与跨进程;单机与分布式
3、提供了丰富的功能和高级特性,比如发布订阅、持久化、内存淘汰(过期)策略等
4、客户端支持多种编程语言
5、高可用性, 主从、哨兵
配置修改方式
1、配置文件redis.conf
2、启动参数 --require
3、config set命令动态修改
3、Redis的安装
Vmware 14的CentOs 7上安装的Redis-5.0.5的版本
由于Redis是C语言开发的,在安装之前要先安装gcc编译器,使用yum命令安装
yum install gcc
第一步:下载redis
cd /usr/local/software
wget http://download.redis.io/releases/redis-5.0.5.tar.gz
第二步:解压
tar -zxvf redis-5.0.5.tar.gz
第三步:编译安装
cd redis-5.0.5
make MALLOC=libc
cd src
make install
第四步:修改配置文件
cd redis-5.0.5
vim redis.conf
后台启动参数
daemonize no 改为 daemonize yes
主机绑定参数,如果不修改只能本机访问服务端
bind 127.0.0.1 改为0.0.0.0
rdb快照文件目录
dir ./ 改为dir /usr/local/software/redis-5.0.5
其它参数后面用到再说
服务端和客户端启动的命令太长,可以配置别名
alias redis='/usr/local/software/redis-5.0.5/src/redis-server /usr/local/software/redis-5.0.5/redis.conf'
alias rcli='/usr/local/softeware/redis-5.0.5/src/redis-cli'
关闭服务端
ps -aux | grep redis
kill -9 pid
或者在客户端中关闭
192.168.75.26> shutdown
4、Redis的数据类型和基本操作
Redis是字典结构的存储方式,也就是K-V的形式存储,K和V的最大长度限制都是512M,Redis提供了丰富的数据类型,根据这些数据类型的特点,可以被应用到不同的业务场景中。
4.1数据库操作:
默认是16个数据库,数据库索引值为0-15,默认使用第一个0,数据库的个数可以在配置文件中修改dababases参数的值
databases 16
切换数据库
set 1
清空当前数据库
flushdb
清空所有数据库
flushall
查看所有键
keys *
获取键的总数
dbsize
查看键是否存在
exists key_test
重命名键
rename key_test key_test_rename
查看键类型
type key_test
4.2基本数据类型
这里只介绍简单常用的命令,详细的命令可以参考http://redisdoc.com/index.html
4.2.1、String 字符串
-
存储类型:可以存储字符串、整数、浮点数。官网中字符串类型描述的是binary safe String(二进制安全字符串)原因后面解释。
-
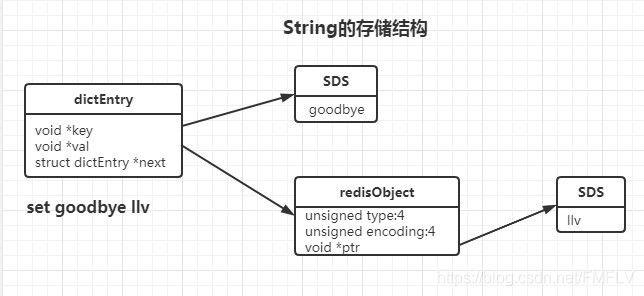
存储原理:因为Redis是KV型的数据库,每个键值对都是一个dictEntry,里面存储了指向Key和Value的指针,next指向了下一个dictEntry。key是作为字符串存储的,但是并没有直接使用C的字符数组,而是使用自定义的SDS(Simple Dynamic Strings)存储,value既不是直接作为字符串存储,也不是直接存储在SDS中,而是存储在redisObject中,redisObjec中存储了指向value的指针。
下面是dictEntry的定义,源码位置在src/dict.h,
typedef struct dictEntry {
void *key; /* key的定义 */
union {
void *val;/* value的定义 */
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;/* 指向下一个键值对 */
} dictEntry;
下面是redisObject的定义,源码位置在src/server.h
常用的五种基本数据类型都是通过redisObject来存储的。
typedef struct redisObject {
unsigned type:4;/* 对象的类型 */
unsigned encoding:4;/* 具体的数据结构 */
unsigned lru:LRU_BITS; /* 24位,与内存回收有关 */
int refcount;/* 引用计数 */
void *ptr;/* 指向对象实际的数据类型 */
} robj;
各个字段的含义:
/* type字段:4位存储,可以通过type命令查看数据类型*/
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4
/* encoding字段:表示该类型的物理编码方式,同一数据类型可能有不同的编码方式,可以通过object encoding命令查看编码方式*/
#define REDIS_ENCODING_RAW 0 /* Raw representation */
#define REDIS_ENCODING_INT 1 /* Encoded as integer */
#define REDIS_ENCODING_HT 2 /* Encoded as hash table */
#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */
#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
-
字符串的内部编码,由小内存编码->大内存编码
1、int:存储8个字节的长整型
2、embstr:代表embstr格式的SDS,存储小于44字节的字符串,3.2版本之前是39字节
3、raw:存储大于44字节的字符串
-
几个常见的问题:
1、embstr和raw的区别
embstr的使用只分配一次内存(因为redisObject和SDS是连续的),而raw需要分配两次内存(分别为redisObject和SDS分配空间),因此embr和raw相比,创建时少分配一次内存和删除时少释放一次内存,对象的所有数据连在一起,方便查找,embstr如果字符串的长度增加时需要重新分配内存,整个redisObject和SDS都需要重新分配,因此Redis中embstr实现为只读。
2、int和embstr转化到row的条件
当int数据不再是整数或者大小超出了2^63-1时转化为embstr,只要是修改了embstr类型的对象,无论是否达到了44字节的限制,都会转化为row,因为embstr是只读的,对其进行修改时,都会先转化为row。
3、当长度小于阈值时,会还原吗
Redis内部编码的转换只能从小内存编码向大内存编码转换,编码转换在写入数据时完成,转换过程不可逆
4、为什么Redis对底层的数据结构进行了一次封装
通过封装,可以根据对象的类型动态的选择存储结构、动态的选择可以使用的命令,实现节省空间和优化查询速度
-
SDS介绍
C语言中字符串是以字符数组实现,使用字符数组必须先给目标变量分配足够的空间,否 则可能会溢出;获取字符串长度时,就要遍历字符数组,时间负责度O(n);字符串长度的变化会对字符数组进行内存重分配;二进制不安全:字符串的结尾是以\0来标记的,因此不能存储图片、音频、视频、压缩文件等二进制保存的内容。所以Redis对其进行了改造。SDS不用担心内存溢出问题,如果需要会对SDS进行扩容;采用预分配冗余空间和惰性空间释放的方式来减少内存的频繁分配;定义了len属性,获取字符串长度的时间复杂度为O(1);判断是否结束的标志是len属性,它同样以\0结尾,这样就部分兼容了C。
在3.2之后的版本,SDS又有了多种结构体:sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64用于存储不同长度的字符串,以sdshdr16为例,介绍结构体中的参数含义(源码在src/sds.h):
struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; /* used 字符数组长度 */ uint16_t alloc; /* 字符数组总共分配的内存大小 */ unsigned char flags; /* 字符数组的属性,标识是sdshr16 */ char buf[];/* 存储字符 */ }; -
应用场景
缓存:热点数据缓存,提高访问速度
分布式数据共享:分布式session,比如sping-session-data-redis
分布式锁:setnx命令
全局ID:incyby命令,利用这个命令的原子性
计数器:incy命令
位统计:bit相关命令
4.2.2、Hash 哈希
-
存储类型
包含键值对的无序散列表,value只能是字符串
hash和string的区别?hash是把相关的值聚集到一个key上,节省内存空间;只使用一个key,减少哈希冲突;批量获取值的时候,使用一个命令,减少IO次数。hash类型的field字段不能单独设置过期时间,没有位操作,value值非常大的时候,不能分布到多个节点。
-
存储原理
Reids本身是一个KV的结构,使用了hashtable(数组+链表)的存储结构,而hash类型的数据,Value本身也是一个KV结构,这个就是内层的哈希,底层使用了两种数据结构实现:ziplist 也就是压缩列表或hashtable 哈希表。
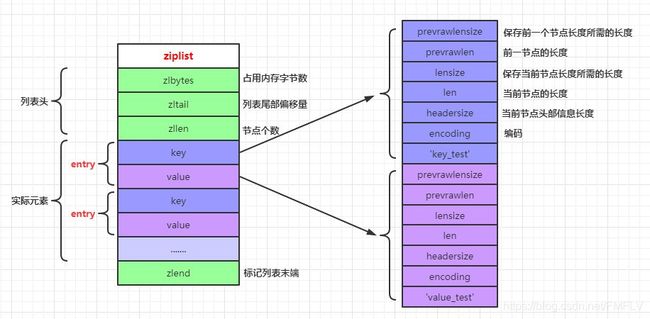
1、ziplist介绍
ziplist是一个经过特殊编码的连续内存块组成的顺序性链表结构,但它并没有存储指向上一个或下一个链表节点的指针,而是存储的是上一个节点的长度和当前节点的长度,是通过时间换空间的思想来提高内存的空间利用率。只用在字段个数少,字段值小的场景。
ziplist的布局定义在src/ziplist.c中:
/*... */ 记录整个压缩列表占用的内存字节数,在内存重分配或者计算zlend时使用 记录压缩列表尾节点到头节点有多少字节,可以快速定位到尾部节点 记录压缩列表的节点数量 压缩列表的节点 标记压缩列表末端 */ zlentry的结构定义:
typedef struct zlentry { unsigned int prevrawlensize; /* 保存前一个节点长度所需的长度*/ unsigned int prevrawlen; /* 前一节点的长度,用于从后往前遍历使用 */ unsigned int lensize; /* 保存当前节点长度所需的长度 */ unsigned int len; /* 当前节点的长度 */ unsigned int headersize; /* 当前节点头部信息长度=参数1+参数3,表示非数据域的大小 */ unsigned char encoding; /* 编码*/ unsigned char *p; /* 压缩列表以字符串的形式保存,该指针指向当前节点的起始位置 */ } zlentry; 编码定义:
#define ZIP_STR_06B (0 << 6)/*长度小于等于63字节*/ #define ZIP_STR_14B (1 << 6)/*长度小于等于16383字节*/ #define ZIP_STR_32B (2 << 6)/*长度小于等于4294967295字节*/ 当hash对象键和值的长度都超过64字节或者哈希对象保存的键值对数量超过512个时,底层会转化为hashtable存储。
配置文件中的参数(redis.conf)hash-max-ziplist-value 64 hash-max-ziplist-entries 5122、hashtable介绍
前面我们知道了Redis的KV结构是通过一个dictEntry实现的,dictEntry又被放到了一个dictht(hashtable)里面,而这个dictht又被放到了dict中,下面简单了解一下这几个结构体:
typedef struct dictht { dictEntry **table;/* 哈希表数组 */ unsigned long size;/* 哈希表大小 */ unsigned long sizemask;/* 掩码大小,用于计算索引值=size-1*/ unsigned long used;/*已有节点数*/ } dictht;typedef struct dict { dictType *type;/* 字典类型 */ void *privdata;/* 私有数据 */ dictht ht[2];/* 一个字典有两个哈希表 */ long rehashidx; /* rehash索引 */ unsigned long iterators; /* 当前正在使用的迭代器数量 */ } dict;
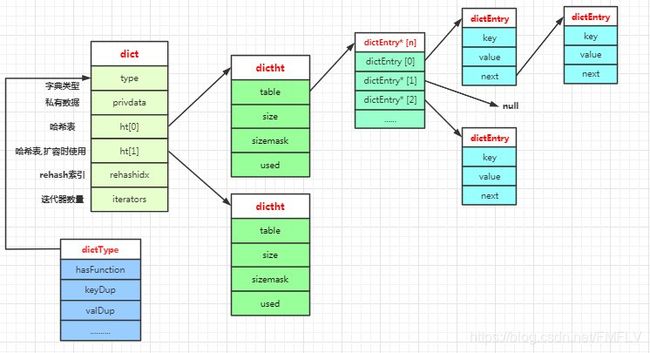
为什么这里定义了两个哈希表?
hash默认使用的是h[0],h[1]不会初始化和分配空间,dictht使用拉链法来解决哈希碰撞的,当数组的每一个位置只挂载一个dictEntry时,性能最高,如果挂载的dictEntry变多的时候,性能就会下降,这里用一个参数ratio表示哈希表的大小(size属性)和它保存的节点数量(used)的比率,当ratio值太大的时候就会触发扩容(rehash),定义两个哈希表就跟JVM运行时数据区的from区和to区进行数据迁移的原理相同。首先为h[1]分配内存,然后把h[0]的节点rehash到h[1]上,最后释放h[0]的空间并将h[1]设置为h[0],创建新的h[1],为下次rehash做准备。
扩容操作:当ratio值大于1:5时触发扩容
缩容操作:
-
应用场景
存储对象类型的数据:节省了Key的空间,数据便于集中管理
4.2.3、List 列表
-
存储类型
存储有序的字符串,元素可以重复。
列表的头在左边
rpush+lpop命令结合相当于队列操作
lpush+lpop命令结合相当于栈操作
-
存储原理
在3.2版本之前,数据量较小时用ziplist存储,达到临界值时转换为linkedlist存储,3.2版本之后统一用quicklist存储。
quicklist介绍:
quicklist存储了一个双向链表,每个节点都是一个ziplist,它结合了压缩列表和链表的特点。结构定义如下:
typedef struct quicklist { quicklistNode *head;/* 链表头 */ quicklistNode *tail;/* 链表尾 */ unsigned long count;/* 所有的ziplist中总共存储了多少个元素 */ unsigned long len;/* 双向链表的长度,quicklistNode的数量 */ int fill : 16;/* 单个node的填充因子 */ unsigned int compress : 16; /* 压缩深度 */ } quicklist;typedef struct quicklistNode { struct quicklistNode *prev; /* 前一个节点 */ struct quicklistNode *next; /* 后一个节点 */ unsigned char *zl; /* 指向实际的ziplist */ unsigned int sz; /* 当前ziplist占用的字节 */ unsigned int count : 16; /* 当前ziplist中存储了多少个元素,占16位,也就是做多为65536个 */ unsigned int encoding : 2; /* 是否采用了LZF压缩算法RAW==1 or LZF==2 */ unsigned int container : 2; /* 未来可能支持其他结构存储NONE==1 or ZIPLIST==2 */ unsigned int recompress : 1; /* 当前ziplist是不是已经被解压出来用作临时使用 */ unsigned int attempted_compress : 1; /* 测试时使用 */ unsigned int extra : 10; /* 预留给未来扩展使用 */ } quicklistNode;
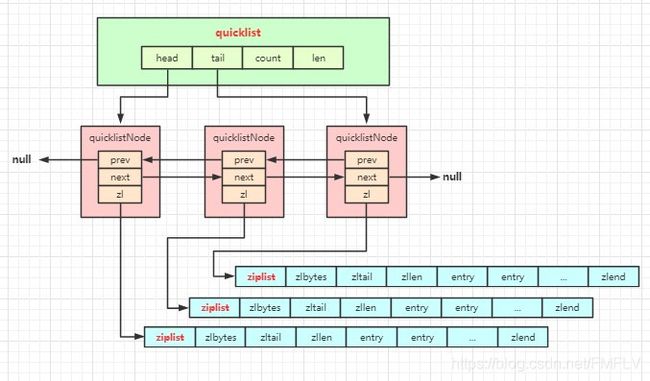
相关参数的配置信息(redis.conf)
list-max-ziplist-size 正数表示单个ziplist最多包含的entry个数,负数表示单个ziplist的大小,默认为8k。-1:4K;-2:8K;-3:16K;-4:32K;-5:64K。
list-compress-depth 0 压缩深度,默认为0,1表示首尾的ziplist不压缩,2表示第一个第二个和倒数第一个倒数第二个不压缩,以此类推
至于ziplist这里就不再重复说明了。
-
应用场景
时间线:根据list有序的特点
消息队列:blpop和brpop命令是阻塞式的弹出操作,还可以设置超时时间
4.2.4、Set 集合
-
存储类型
存储的是String类型的无序集合,最大存储数量2^32-1个,元素不允许重复
-
存储原理
如果元素都是整数类型就用intset存储
如果不是整数类型,就用hashtable存储
注意:key就是存储的元素的值,value为null
如果元素的个数超过了512个,就是用hashtable存储
相关参数配置信息redis.conf:
set-max-intset-entries 512 -
应用场景
抽奖:spop命令随机弹出一个元素
打卡、点赞:sadd命令、srem、sismember、smembers、scard
筛选:sdiff 、sinter、sunion取差集、交集、并集操作
4.2.5、ZSet 有序集合
-
存储类型
顾名思义,存储的是有序的set集合,每个元素都有一个score,score相同时,按照key的ASCII码排序,元素不能重复
-
存储原理
当元素数量少于128个并且所有元素的长度小于64字节时,采用的是ziplist编码存储,按照score递增的顺序存储,插入数据时要移动之后的数据。
当上面两个条件不满足的时候采用skiplist+dict存储
skiplist介绍
跳跃表使用概率均衡技术而不是使用强制性均衡,因此,对于插入和删除结点比传统上的平衡树算法更为简洁高效。与有序数组通过二分查找的思想类似,通过分段的思想,使得查找更加高效。
看一下源码的定义src/server.h:
typedef struct zskiplist { struct zskiplistNode *header, *tail;/*指向跳跃表的头节点和尾节点*/ unsigned long length;/*跳跃表的节点数*/ int level;/*最大的层数*/ } zskiplist;typedef struct zskiplistNode { sds ele;/*zset的元素*/ double score;/*分值*/ struct zskiplistNode *backward;/*后退指针*/ struct zskiplistLevel { struct zskiplistNode *forward;/*前进指针,对应具体level的下一个节点*/ unsigned long span;/*从当前节点到下一个节点跨越的节点数*/ } level[];/*分层值的集合,*/ } zskiplistNode;typedef struct zset { dict *dict;/*dictEntry*/ zskiplist *zsl;/*zskiplist*/ } zset; 这里看一下节点获取分层值的函数src/t_zset.c:
int zslRandomLevel(void) { int level = 1; while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)) level += 1; return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL; } -
应用场景
排行榜:利用有序的特点
范围查找:
4.2.6、Hyperloglog
提供了一种不太准确的基数统计方法,这种方法存在一定的误差
4.2.7、Geo
可以将经纬度格式的地理坐标信息存储在Redis中,并且可以对这些坐标执行距离计算、范围查找等。
4.2.8、bitmap
在字符串类型上定义的一些位操作。
4.2.9、Streams
Redis5.0新推出的类型,支持多播的可持久化的消息队列,可以实现发布订阅的功能,借鉴了kafka的设计
*/
} zset;
这里看一下节点获取分层值的函数src/t_zset.c:
```c
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level-
应用场景
排行榜:利用有序的特点
范围查找:
4.2.6、Hyperloglog
提供了一种不太准确的基数统计方法,这种方法存在一定的误差
4.2.7、Geo
可以将经纬度格式的地理坐标信息存储在Redis中,并且可以对这些坐标执行距离计算、范围查找等。
4.2.8、bitmap
在字符串类型上定义的一些位操作。
4.2.9、Streams
Redis5.0新推出的类型,支持多播的可持久化的消息队列,可以实现发布订阅的功能,借鉴了kafka的设计