一文看懂RabbitMQ
RabbitMQ笔记
1、RabbitMQ是什么?
1.1、概念:
MQ(Message Queue)消息队列,是指用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。本质上就是一个存储、转发消息的中间件。
1.2、MQ历史发展:
最早的消息队列软件TIB(The Information Bus)实现了生产者和消费者的解耦,它的成功引起了IBM的注意,之后IBM研发了自己的IBM Websphere,微软也研发了MicroSoft Message Queue,但是这些产品由于协议和API的不同,没有一套标准接口来实现它们的互通,2001年SUN公司发布JMS规范,这使得我们只要使用合适的MQ驱动即可,就像JDBC规范一样,但是这是跟JAVA语言绑定的,无法实现跨语言。2006年AMQP协议规范的发布,促进了MQ的发展,它是跨语言和跨平台的。2007年Rabbit公司基于AMQP规范开发了RabbitMQ。
1.3、MQ的主要特点:
- MQ是一个独立运行的服务
- 采用队列(先进先出)作为数据结构
- 具有发布订阅的功能
1.4、MQ可以实现的功能:
- 实现异步通信
- 实现系统解耦
- 实现流量削峰,在访问量剧增时,MQ中的队列可以减少突发访问的情况。
2、RabbitMQ的基本特性
- 可靠性,RabbitMQ提供了发送应答、发布确认、持久化等机制来保证可靠性。
- 灵活的路由:通过交换机来实现消息的灵活路由。
- 支持多客户端:对主流开发语言(Python、Java、PHP、C#、JavaScript、Go)都有客户端实现。
- 支持多协议:除了原生的AMQP协议,还支持STOMP、MQTT、HTTP and WebSockets等其它消息中间件协议。
- 集群与扩展性:多个RabbitMQ节点可以组成集群,支持负载。
- 高可用队列:通过镜像队列实现队列中的数据复制。
- 权限管理:通过用户和VHost实现权限管理。
- 插件系统:支持各种丰富的插件扩展。
- 管理界面:提供了一个简单易用的用户界面。
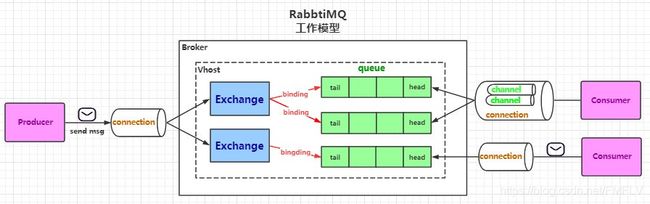
3、RabbitMQ的工作模型
-
Broker
意为中介/代理,指的就是RabbitMQ服务,默认端口5672。我这里安装在Windows上,也可以安装 在Linux上,或者docker中。
-
VHost
VHost就跟我们在Windows上安装多台虚拟机一样,主要作用是提高硬件资源的利用率,实现资源的隔离和权限的控制。不同的Vhost中可以有同名的交换机和队列。
-
Connection
生产者或者消费者跟Broker之间的连接,这个连接是TCP长连接。
-
Channel
channel是一个虚拟的连接,由于TCP连接是非常宝贵的资源,创建和释放比较消耗时间,通过channel就可以在TCP长连接中创建和释放channel,这样就减少了资源的消耗,channel是TCP连接的多路复用。channel同时也是RabbitMQ中重要的编程接口,定义交换机、队列、绑定关系,发送和消费消息都是通过channel来完成的。
-
Exchange
交换机实际上就是一个绑定列表,用来实现消息的灵活路由。队列使用绑定建和交换机建立绑定关系,通过生产者发送消息携带的路由键来决定将消息路由到那个与它绑定的交换机上。
交换机的类型
- Direct 直连类型。直连类型的交换机和队列绑定时,需要一个精确的绑定建。生产者发送的消息的路由键和绑定建完全匹配时消息才会被路由到指定的队列上。
- Toptic 主题类型。主题类型的交换机和队列绑定时,绑定建可以使用通配符,#表示0个或多个单词,*表示1个单词。注意这里单词的意思是指用"."隔开的字符。
- Fanout 广播类型。广播类型的交换机与队列绑定时,不需要指定绑定建,生产者发送消息不需要携带路由键,消息会发送到与交换机绑定的所有队列上。
-
Queue
队列是用来存储消息的,是一个独立运行的进程,有自己的数据库(Mnesia),队列具有先进先出的特点,队列头的消息被消费者接受后,才会把这条消息删除掉。
-
BindingKey
用来绑定队列和交换机的绑定关系,需要注意的是,交换机和队列、队列和消费者都是多对多的关系。
-
Producer&Consumer
生产者负责生产消息,消费者负责消费消息,分布式系统中,它们都是一个一个的应用进程,一个应用既可以是生产者,也可以是消费者。
4、RabbitMQ的功能
4.1、消息的过期时间TTL(Time To Live)
-
Message TTL (优先级高)
单条消息的过期时间,在发送消息时指定消息的属性来设置。
-
Queue TTL
队列中的消息超过过期时间后,该队列的消息都会过期,通过队列属性x-message-ttl的值来设置
4.2、死信队列Dead Letter
-
消息什么情况下变成死信
- 消息过期了
- 消息在被消费者拒绝并且没有设置重回队列(nack||Reject)&&requeue==false
- 队列达到了最大长度,超过了max-length或者max-length-bytes,最先入队的消息会被发送到死信队列。
-
死信队列
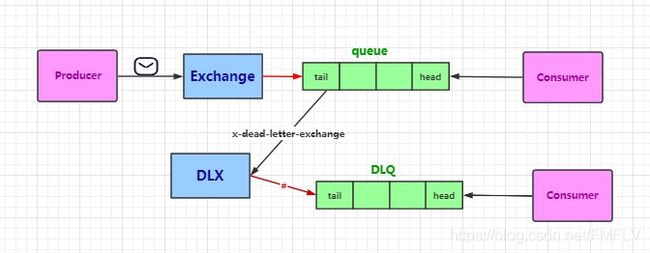
队列在创建的时候可以指定一个死信交换机DLX(Dead Letter Exchange),DLX绑定的队列就是死信队列DLQ(Dead Letter Queue),需要注意的是死信队列也是普通队列。通过队列属性x-dead-letter-exchange指定死信交换机,然后将死信交换机和死信队列绑定起来。
4.3、延迟队列
RabbitMQ本身不支持延迟队列,这里有几种解决方案
-
利用数据库实现,将消息存储到数据库,采用定时任务来发送。
-
利用TTL和DLX实现,整体的流程就像这样:

这样也会带来比较明显的缺点:如果使用Message TTL可能会导致队列的消息阻塞,后面的消息无法投递(前面的过期时间大于后面的);如果使用Queue TTL在消息延迟梯度比较多的情况下,需要创建大量的交换机和队列。 -
利用延迟队列插件类实现(rabbitmq-delayed-message-exchange)
4.4、流量控制
当生产者的生产速率远大于消费者的消费速率时,会产生大量消息堆积的情况;当消费者处理消息的能力有限,导致消费端本地缓存消息数量过多,导致内存溢出,针对这些情况,可以通过服务端流控和消费端限流来控制。
4.4.1、服务端流控
-
内存控制
RabbitMQ启动时会检测机器的内存大小,当占用超过40%(默认)的内存时,会阻塞所有连接。可以通过配置文件rabbitmq.config中的vm_memory_high_watermark属性来进行设置。
-
磁盘控制
当磁盘空间低于50MB(默认)时,会触发限流,通过配置文件中的disk_free_limit.ralative和disk_free_limit.absolute属性来设置,前者是百分比,后者是绝对大小。
4.4.2、消费端限流
由于消费端会缓存消息,当缓存的消息过多时,如果能够在一定数量的消息消费完成之前,不再推送消息,这样就可以完成消费端限流了。
基于Consumer或者Channel设置prefetch count值。表示consumer端的最大unacked messages数量,当超过这个数值的消息未被确认时,会停止投递新的消息给该消费者。比如channel的prefetch count值为10时,当消费端有10条消息没有发送ack后,将不再给这个消费者投递消息。
5、消息的可靠性
RabbtMQ在异步通信的时候,消息传递的可靠性可以从RabbitMQ工作模型看出,保证消息发送、消息路由、消息存储、消息投递这四个过程的可靠性,就能确保消息的可靠性。下面来逐个分析。
5.1、消息发送到服务端
RabbitMQ中提供了两种服务端确认机制,事务(Transaction)模式和确认(Confirm)模式。
5.1.1、Transaction模式
String msg = "Hello Rabbit MQ";
channel.queueDeclare(QUEUE_NAME, false, false, false, null);// 声明队列
try {
channel.txSelect();//将channel设置为事务模式
// String exchange, String routingKey, BasicProperties props, byte[] body
channel.basicPublish("", QUEUE_NAME, null, (msg).getBytes());
// int i =1/0;
channel.txCommit();
System.out.println("消息发送成功");
} catch (Exception e) {
channel.txRollback();
System.out.println("消息已经回滚");
}
这种模式下发送消息是阻塞的,对服务器性能影响很大,所以使用的很少。
5.1.2、Confirm模式
确认模式有三种:
5.1.2.1、普通确认模式
String msg = "Normal Confirm";
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
channel.confirmSelect();// 开启确认模式
channel.basicPublish("", QUEUE_NAME, null, msg.getBytes());
if (channel.waitForConfirms()) {
// 发送一条,确认一条
System.out.println("SUCCESS" );
}
这种模式效率不高。
5.1.2.2、批量确认模式
String msg = "Batch Confirm";
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
try {
channel.confirmSelect();// 开启确认模式
for (int i = 0; i < 5; i++) {
channel.basicPublish("", QUEUE_NAME, null, (msg +":"+ i).getBytes());
}
channel.waitForConfirmsOrDie();
// 批量确认结果,ACK如果是Multiple=True,表示Delivery-Tag之前的消息都被确认了
//只要有一个未确认就会发生异常,之前的所有确认的消息都要重发
System.out.println("BATCH SUCCESS");
} catch (Exception e) {
// 发生异常,处理
e.printStackTrace();
}
5.1.2.3、异步确认模式
5.2、消息从交换机路由到队列
当消息无法路由时,可以通过服务端重发给生产者或者让这些消息都路由到备份的交换机上来处理。
5.2.1、消息回发
使用mandatory参数和ReturnListener将消息回发给生产者。
channel.addReturnListener(new ReturnListener() {
//指定ReturnListener
public void handleReturn(int replyCode,String replyText,String exchange,
String routingKey,
AMQP.BasicProperties properties,byte[] body)throws IOException {
System.out.println("被返回的消息"+"replyText:"+replyText+"exchange:"+exchange+"routingKey:"+routingKey+"message:"+new String(body));
}
});
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.deliveryMode(2)
.contentEncoding("UTF-8").build();
// 第三个参数是mandatory,如果为true,结合ReturnListener消息回发,如果false,直接丢弃消息
channel.basicPublish("","gupaodirect",true, properties,"hello future".getBytes());
5.2.2、消息路由到备份机
//在声明交换机的时候指定备份交换机
Map<String,Object> properties = new HashMap<String,Object>();
properties.put("alternate-exchange","ALTERNATE_EXCHANGE");
channel.exchangeDeclare("TEST_EXCHANGE","topic", false, false, false, properties);
5.3、消息在队列中存储
当服务发生故障中时,会导致内存中的数据丢失,因此需要将消息本身和元数据(交换机、队列、绑定关系)都持久化到磁盘中。
5.3.1、队列和交换机的持久化
在声明队列和交换机时将durable参数设置为true。
// 声明交换机
// 参数说明String exchange, String type, boolean durable, boolean autoDelete, Map arguments
channel.exchangeDeclare(EXCHANGE_NAME,"direct",true, false, null);
// 声明队列
// String queue, boolean durable, boolean exclusive, boolean autoDelete, Map arguments
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
5.3.2、消息的持久化
在发送消息时将消息设置为持久化消息
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.deliveryMode(2) // 2表示持久化消息
.contentEncoding("UTF-8")
.build();
// 发送消息
channel.basicPublish("", "TEST_DLX_QUEUE", properties, msg.getBytes());
5.4、消息投递到消费者
消费者在收到消息后或者处理时发生异常,都会导致消息投递失败。RabbitMQ提供了消费者的消息确认机制来确保可靠性,分为自动发送ACK和手动发送ACK两种。服务端没有收到ACK,等到消费者断开连接后,会将这条消息发送给其他消费者,如果没有其它消费者,消费者重启后会重新消费这条消息。
消费者订阅队列时,可以指定autoAck参数,若为false,则表示手工ack,服务端会等待消费端显式回复ack后才会移除消息。
(spingboot整合amqp中)通过setAcknowledgeMode(AcknowledgeMode.AUTO)来设置。取值有AUTO/NONE/MANUAL。
NONE表示自动ack。
MANUAL表示手动ack。
AUTO:如果方法没有抛出异常,则发送ack。如果抛出AmqpRejectAndDontRequeueException则消息会被拒绝,且不会重新入队。如果抛出ImmediateAcknowledgeAmqpException则发送ack。如果是其他的异常并且requeue参数值为true,则消息会被拒绝并且重新入队。
6、其他问题
6.1、生产者如何知道消费者有没有成功消费?
- 调用生产者API
- 发送响应给生产者
6.2、消息幂等性
对于重复发送的消息,生成一个唯一的业务ID,通过日志来做重复控制。
6.3、消息的顺序性
当一个队列有多个消费者时,由于不同的消费者的消费速度是不同的,顺序性无法保证,因此只有当一个队列仅有一个消费者的情况下才能保证顺序性。
7、集群
RabbitMQ集群用于实现高可用和负载均衡。集群有两种模式:普通集群和镜像集群。集群中的结点有两种类型:磁盘结点和内存结点。磁盘结点会将元数据放在磁盘中,内存结点将元数据放在内存中。集群中至少需要一个磁盘结点来持久化元数据,默认情况下结点类型为磁盘结点。集群通过25672端口进行通信。
7.1、普通集群
这种模式下,不同节点之间只会相互同步元数据。由于消息是存储在队列中的,因此不能保证队列的高可用,如果节点失效将导致相关队列不可用。
7.2、镜像集群
镜像队列模式下,消息的内容也会在镜像节点间同步,可用性提高,但是会降低系统的性能。
这里简单总结一下学习RabbitMQ的知识点,demo演示后面在补充上。