hadoop学习笔记之完全分布模式安装
一、Hadoop是什么
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,它是一个开发和运行处理大规模数据的软件平台,是Appach的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop框架中最核心设计就是:HDFS和MapReduce.
- HDFS提供了海量数据的存储
- HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集(large data set)的应用程序。
- MapReduce提供了对数据的计算
- 通俗说MapReduce是一套从海量·源数据提取分析元素最后返回结果集的编程模型,将文件分布式存储到硬盘是第一步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。
总的来说Hadoop适合应用于大数据存储和大数据分析的应用,适合于服务器几千台到几万台的集群运行,支持PB级的存储容量。
Hadoop典型应用有:搜索、日志处理、推荐系统、数据分析、视频图像分析、数据保存等。
二、Hadoop模式介绍
单机模式:安装简单,几乎不用作任何配置,但仅限于调试用途
伪分布模式:在单节点上同时启动namenode、datanode、jobtracker、tasktracker、secondary namenode等5个进程,模拟分布式运行的各个节点
完全分布式模式:正常的Hadoop集群,由多个各司其职的节点构成
三、实验环境
系统:redhat6.5
软件版本:
- hadoop-2.7.3
- jdk-7u79-linux-x64
| IP | 主机名 | 角色 |
|---|---|---|
| 172.25.27.6 | server6 | NameNode DFSZKFailoverController ResourceManager |
| 172.25.27.7 | server7 | NameNode DFSZKFailoverController ResourceManager |
| 172.25.27.8 | server8 | JournalNode QuorumPeerMain DataNode NodeManager |
| 172.25.27.9 | server9 | JournalNode QuorumPeerMain DataNode NodeManager |
| 172.25.27.10 | server10 | JournalNode QuorumPeerMain DataNode NodeManager |
四、安装步骤
1.下载Hadoop和jdk
hadoop 官网: http://hadoop.apache.org/
下载地址: http://mirror.bit.edu.cn/apache/hadoop/common/
2.hadoop 单节点 伪分布搭建
1.hadoop 安装与测试
[root@server6 ~]# useradd -u 1000 hadoop ##id随意,需要注意的是所有节点id必须一致,所以需要合理选择避免冲突
[root@server6 ~]# id hadoop
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)
[root@server6 ~]# su - hadoop
##注意,下载后的包最好放在hadoop家目录,并且后续操作一定要切换成hadoop用户的身份进行相应操作
[hadoop@server6 ~]$ ls
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[hadoop@server6 ~]$ tar -zxf hadoop-2.7.3.tar.gz
[hadoop@server6 ~]$ tar -zxf jdk-7u79-linux-x64.tar.gz
[hadoop@server6 ~]$ ln -s hadoop-2.7.3 hadoop
[hadoop@server6 ~]$ ln -s jdk1.7.0_79/ jdk
[hadoop@server6 ~]$ vim ~/.bash_profile
PATH=$PATH:$HOME/bin:/home/hadoop/jdk/bin
export PATH
export JAVA_HOME=/home/hadoop/jdk
[hadoop@server6 ~]$ source ~/.bash_profile
[hadoop@server6 ~]$ echo $JAVA_HOME
/home/hadoop/jdk
[hadoop@server6 ~]$ cd hadoop
[hadoop@server6 hadoop]$ mkdir input
[hadoop@server6 hadoop]$ cp etc/hadoop/*.xml input/
[hadoop@server6 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+'
[hadoop@server6 hadoop]$ ls output/
part-r-00000 _SUCCESS
[hadoop@server6 hadoop]$ cat output/*
1 dfsadmin

[hadoop@server6 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount input output
[hadoop@server6 hadoop]$ ls output/
part-r-00000 _SUCCESS
[hadoop@server6 hadoop]$ cat output/* ##这个就能明显看出效果了
"*" 18
"AS 8
"License"); 8
"alice,bob 18
...2.伪分布式操作(需要ssh免密)
[hadoop@server6 hadoop]$ vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://172.25.27.6:9000value>
property>
configuration>
[hadoop@server6 hadoop]$ vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
configuration>
[hadoop@server6 hadoop]$ sed -i.bak 's/localhost/172.25.27.6/g' etc/hadoop/slaves
[hadoop@server6 hadoop]$ cat etc/hadoop/slaves172.25.27.6
- ssh 免密
[hadoop@server6 hadoop]$ exit
logout
[root@server6 ~]# passwd hadoop
Changing password for user hadoop.
New password:
BAD PASSWORD: it is based on a dictionary word
BAD PASSWORD: is too simple
Retype new password:
passwd: all authentication tokens updated successfully.
[root@server6 ~]# su - hadoop
[hadoop@server6 ~]$ ssh-keygen
[hadoop@server6 ~]$ ssh-copy-id 172.25.27.6
[hadoop@server6 ~]$ ssh 172.25.27.6 ##测试登陆,不需要输密码就ok
[hadoop@server6 hadoop]$ bin/hdfs namenode -format ##进行格式化
[hadoop@server6 hadoop]$ sbin/start-dfs.sh ##启动hadoop
[hadoop@server6 hadoop]$ jps ##用jps检验各后台进程是否成功启动,看到以下四个进程,就成功了
2391 Jps
2117 DataNode
1994 NameNode
2276 SecondaryNameNode浏览器输入: http://172.25.27.6:50070
浏览网站界面;默认情况下它是可用的
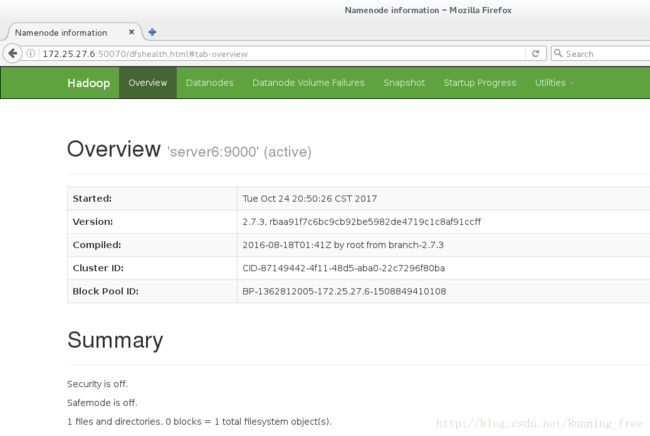
3.伪分布的操作
Utilities –> Browse the file system
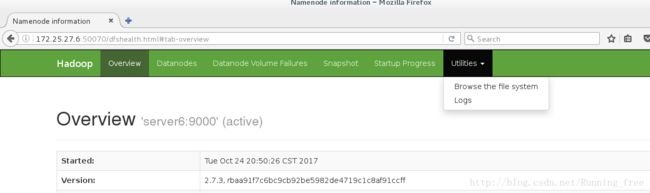
默认是空的,什么都没有

我们来创建一个文件夹
[hadoop@server6 hadoop]$ bin/hdfs dfs -mkdir /user
[hadoop@server6 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@server6 hadoop]$ bin/hdfs dfs -put input test ##上传本地的 input 并改名为 test
刷新看看

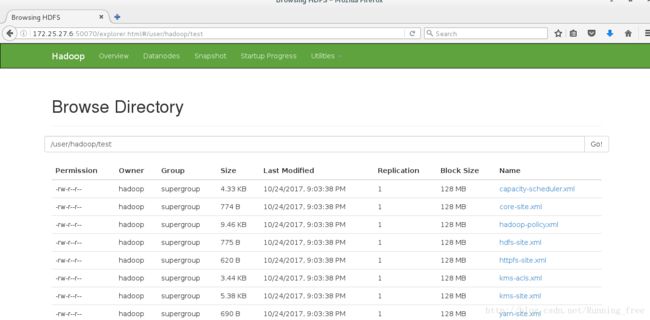
[hadoop@server6 hadoop]$ rm -rf input/ output/
[hadoop@server6 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount test output
[hadoop@server6 hadoop]$ ls ##output不在本地
bin include libexec logs README.txt share
etc lib LICENSE.txt NOTICE.txt sbin
刷新看看
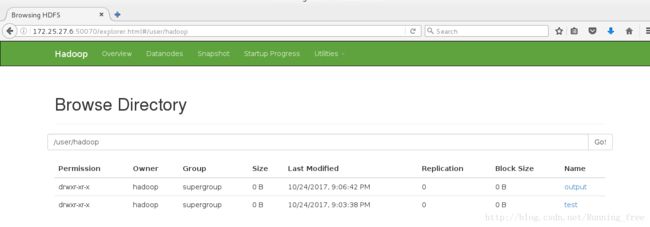
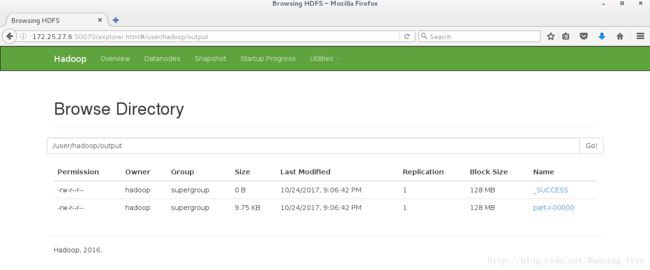
那怎么查看呢?用下面的命令
[hadoop@server6 hadoop]$ bin/hdfs dfs -cat output/*
...
within 1
without 1
work 1
writing, 8
you 9
[hadoop@server6 hadoop]$ bin/hdfs dfs -get output . ##将output下载到本地
[hadoop@server6 hadoop]$ ls
bin include libexec logs output sbin
etc lib LICENSE.txt NOTICE.txt README.txt share
[hadoop@server6 hadoop]$ bin/hdfs dfs -rm -r output ##删除
17/10/24 21:11:24 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted output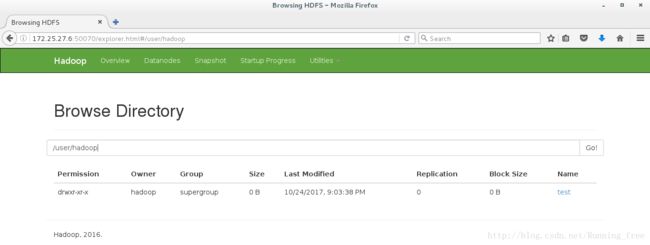
3.hadoop 完全分布模式搭建
1.准备工作
用nfs网络文件系统,就不用每个节点安装一遍了,需要rpcbind和nfs开启
[hadoop@server6 hadoop]$ sbin/stop-dfs.sh
[hadoop@server6 hadoop]$ logout
[root@server6 ~]# yum install -y rpcbind
[root@server6 ~]# /etc/init.d/rpcbind status
rpcbind is stopped
[root@server6 ~]# /etc/init.d/rpcbind start
Starting rpcbind: [ OK ]
[root@server6 ~]# /etc/init.d/rpcbind status
rpcbind (pid 2874) is running...
[root@server6 ~]# yum install -y nfs-utils
[root@server6 ~]# vim /etc/exports
/home/hadoop * (rw,anonuid=1000,anongid=1000)
[root@server6 ~]# /etc/init.d/nfs status
rpc.svcgssd is stopped
rpc.mountd is stopped
nfsd is stopped
[root@server6 ~]# /etc/init.d/nfs start
Starting NFS services: [ OK ]
Starting NFS mountd: [ OK ]
Starting NFS daemon: [ OK ]
Starting RPC idmapd: [ OK ]
[root@server6 ~]# showmount -e
Export list for server6:
/home/hadoop *
[root@server6 ~]# exportfs -v
/home/hadoop (rw,wdelay,root_squash,no_subtree_check,anonuid=1000,anongid=1000) 2.Hadoop 配置
[hadoop@server6 hadoop]$ vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://mastersvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>172.25.27.8:2181,172.25.27.9:2181,172.25.27.10:2181value>
property>
configuration>
[hadoop@server6 hadoop]$ vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.nameservicesname>
<value>mastersvalue>
property>
<property>
<name>dfs.ha.namenodes.mastersname>
<value>h1,h2value>
property>
<property>
<name>dfs.namenode.rpc-address.masters.h1name>
<value>172.25.27.6:9000value>
property>
<property>
<name>dfs.namenode.http-address.masters.h1name>
<value>172.25.27.6:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.masters.h2name>
<value>172.25.27.7:9000value>
property>
<property>
<name>dfs.namenode.http-address.masters.h2name>
<value>172.25.27.7:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://172.25.27.8:8485;172.25.27.9:8485;172.25.27.10:8485/mastersvalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/tmp/journaldatavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.mastersname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/hadoop/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
configuration>
[hadoop@server6 hadoop]$ vim etc/hadoop/slaves
172.25.27.8
172.25.27.9
172.25.27.10
[root@server6 ~]# mv zookeeper-3.4.9.tar.gz /home/hadoop/
[root@server6 ~]# su - hadoop
[hadoop@server6 ~]$ tar -zxf zookeeper-3.4.9.tar.gz
[hadoop@server6 ~]$ cp zookeeper-3.4.9/conf/zoo_sample.cfg zookeeper-3.4.9/conf/zoo.cfg
[hadoop@server6 ~]$ vim zookeeper-3.4.9/conf/zoo.cfg
server.1=172.25.27.8:2888:3888
server.2=172.25.27.9:2888:3888
server.3=172.25.27.10:2888:38883.server7\8\9\10
[root@server7 ~]# useradd -u 1000 hadoop
[root@server7 ~]# id hadoop
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)
[root@server7 ~]# yum install -y nfs-utils rpcbind
[root@server7 ~]# /etc/init.d/rpcbind start
Starting rpcbind: [ OK ]
[root@server7 ~]# mount 172.25.27.6:/home/hadoop/ /home/hadoop/
[root@server8 ~]# vim hadoop.sh
#!/bin/bash
useradd -u 1000 hadoop
yum install -y nfs-utils rpcbind
/etc/init.d/rpcbind start
mount 172.25.27.6:/home/hadoop/ /home/hadoop/
[root@server8 ~]# chmod +x hadoop.sh
[root@server8 ~]# ./hadoop.sh
[root@server8 ~]# scp hadoop.sh server9:
[root@server8 ~]# scp hadoop.sh server10:
[root@server9 ~]# ./hadoop.sh
[root@server10 ~]# ./hadoop.sh
[root@server8 ~]# su - hadoop
[hadoop@server8 ~]$ mkdir /tmp/zookeeper
[hadoop@server8 ~]$ echo 1 > /tmp/zookeeper/myid
[hadoop@server8 ~]$ cat /tmp/zookeeper/myid
1
[root@server9 ~]# su - hadoop
[hadoop@server9 ~]$ mkdir /tmp/zookeeper
[hadoop@server9 ~]$ echo 2 > /tmp/zookeeper/myid
[hadoop@server9 ~]$ cat /tmp/zookeeper/myid
2
[root@server10 ~]# su - hadoop
[hadoop@server10 ~]$ mkdir /tmp/zookeeper
[hadoop@server10 ~]$ echo 3 > /tmp/zookeeper/myid
[hadoop@server10 ~]$ cat /tmp/zookeeper/myid
34.在各节点启动服务
[hadoop@server8 ~]$ cd zookeeper-3.4.9
[hadoop@server8 zookeeper-3.4.9]$ bin/zkServer.sh start
[hadoop@server9 ~]$ cd zookeeper-3.4.9
[hadoop@server9 zookeeper-3.4.9]$ bin/zkServer.sh start
[hadoop@server10 ~]$ cd zookeeper-3.4.9
[hadoop@server10 zookeeper-3.4.9]$ bin/zkServer.sh start
[hadoop@server8 zookeeper-3.4.9]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower
[hadoop@server9 zookeeper-3.4.9]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: leader
[hadoop@server10 zookeeper-3.4.9]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower
5.启动 hdfs 集群(按顺序启动)
在三个 DN 上依次启动 zookeeper 集群(刚才已经启动过了,这里查看下状态,如为启动需要启动)
[hadoop@server8 zookeeper-3.4.9]$ jps
2012 QuorumPeerMain
2736 Jps在三个 DN 上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
[hadoop@server8 hadoop]$ sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-server8.out
[hadoop@server8 hadoop]$ jps
2818 Jps
2769 JournalNode
2012 QuorumPeerMain
[hadoop@server9 hadoop]$ sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-server9.out
[hadoop@server9 hadoop]$ jps
2991 Jps
2205 QuorumPeerMain
2942 JournalNode
[hadoop@server10 hadoop]$ sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-server10.out
[hadoop@server10 hadoop]$ jps
2328 JournalNode
1621 QuorumPeerMain
2377 Jps
格式化 HDFS 集群
Namenode 数据默认存放在/tmp,需要把数据拷贝到 h2
[hadoop@server6 hadoop]$ bin/hdfs namenode -format
[hadoop@server6 hadoop]$ scp -r /tmp/hadoop-hadoop 172.25.27.7:/tmp
格式化 zookeeper (只需在 h1 上执行即可)
[hadoop@server6 hadoop]$ bin/hdfs zkfc -formatZK启动 hdfs 集群(只需在 h1 上执行即可)
[hadoop@server6 hadoop]$ sbin/stop-all.sh
[hadoop@server6 hadoop]$ sbin/start-dfs.sh
Starting namenodes on [server6 server7]
server6: starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-server6.out
server7: starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-server7.out
172.25.27.9: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-server9.out
172.25.27.10: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-server10.out
172.25.27.8: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-server8.out
Starting journal nodes [172.25.27.8 172.25.27.9 172.25.27.10]
172.25.27.10: starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-server10.out
172.25.27.8: starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-server8.out
172.25.27.9: starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-server9.out
Starting ZK Failover Controllers on NN hosts [server6 server7]
server6: starting zkfc, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-zkfc-server6.out
server7: starting zkfc, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-zkfc-server7.out
查看各节点状态
[hadoop@server6 hadoop]$ jps
3783 NameNode
4162 Jps
4092 DFSZKFailoverController
[hadoop@server7 hadoop]$ jps
2970 Jps
2817 NameNode
2921 DFSZKFailoverController
[hadoop@server8 tmp]$ jps
2269 DataNode
1161 QuorumPeerMain
2366 JournalNode
2426 Jps
[hadoop@server9 hadoop]$ jps
1565 QuorumPeerMain
2625 DataNode
2723 JournalNode
2788 Jps
[hadoop@server10 hadoop]$ jps
2133 DataNode
1175 QuorumPeerMain
2294 Jps
2231 JournalNode
注意:如果发现某个节点的DataNode 没有启动,清尝试先停掉hdfs 集群,然后再删除该节点的 /tmp/hadoop-hadoop 文件夹,再重新启动hdfs 集群就没问题了
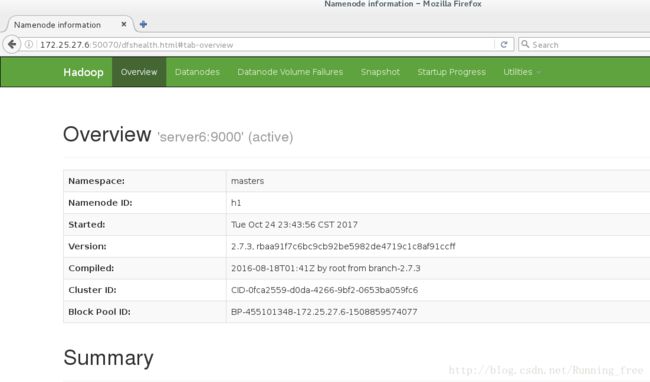

测试故障自动切换
[hadoop@server6 hadoop]$ jps
3783 NameNode
4162 Jps
4092 DFSZKFailoverController
[hadoop@server6 hadoop]$ kill -9 3783
[hadoop@server6 hadoop]$ jps
4092 DFSZKFailoverController
4200 Jps
[hadoop@server7 hadoop]$ jps
2817 NameNode
2921 DFSZKFailoverController
3030 Jps
杀掉 h1 主机的 namenode 进程后依然可以访问,此时 h2 转为 active 状态接管 namenode

[hadoop@server6 hadoop]$ sbin/hadoop-daemon.sh start namenode启动 h1 上的 namenode,此时 h1 为 standby 状态。
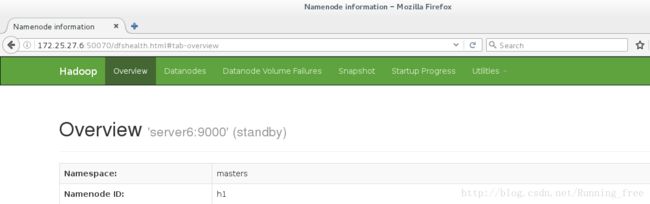
到此 hdfs 的高可用完成