用XGBoost进行二分类
数据:dataset_001.csv
问题介绍:
目的是判断病人是否会在 5 年内患糖尿病,给出的数据为csv文件,一共9列数据,这个数据前 8 列是变量,最后一列是预测值为 0 或 1。
代码:
## Indians_xgboost.py
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
加载数据,分出变量X和标签Y
dataset = loadtxt('dataset_001.csv', delimiter=",")
X = dataset[:,0:8]
Y = dataset[:,8]
将数据集分为训练集和测试集,训练集来训练模型,测试集来测试模型准确度
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
直接使用xgboost封装好的分类器和回归器,可以直接使用XGBClassifier建立模型
# 不可视化数据集loss
#model = XGBClassifier()
#model.fit(X_train, y_train)
##可视化测试集的loss
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=False)
# 改为True就能可视化loss
xgboost的结果是每一个样本属于第一类的概率,要使用round将其转换为0 1值
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
##Accuracy: 77.56%
THE END
当然上面是直接使用默认的参数,下面对参数进行探索,修改。
- 1、可视化每一维度变量的重要性
from xgboost import plot_importance
from matplotlib import pyplot
model.fit(X, Y)
plot_importance(model)
pyplot.show()
图如下所示
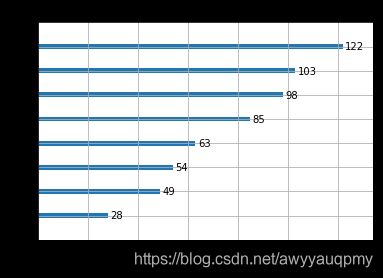
- 2、调参
下面是三个超参数的一般实践最佳值,可以先将它们设定为这个范围,然后画出 learning curves,再调解参数找到最佳模型:
learning_rate = 0.1 或更小,越小就需要多加入弱学习器; tree_depth = 2~8; subsample = 训练集的 30%~80%;
接下来我们用 GridSearchCV 来进行调参会更方便一些: 可以调的超参数组合有:
树的个数和大小 (n_estimators and max_depth).
学习率和树的个数 (learning_rate and n_estimators).
行列的 subsampling rates (subsample, colsample_bytree and colsample_bylevel).
下面以学习率为例
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
#设定要调节的 learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
# 和原代码相比就是在 model 后面加上 grid search 这几行:
model = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
param_grid = dict(learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(X, Y)
# 输出最佳学习率和其对应的分数
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
#Best: -0.483013 using {'learning_rate': 0.1}
# 打印出每一个学习率对应的分数
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
`
-0.689650 (0.000242) with: {‘learning_rate’: 0.0001}
-0.661274 (0.001954) with: {‘learning_rate’: 0.001}
-0.530747 (0.022961) with: {‘learning_rate’: 0.01}
-0.483013 (0.060755) with: {‘learning_rate’: 0.1}
-0.515440 (0.068974) with: {‘learning_rate’: 0.2}
-0.557315 (0.081738) with: {‘learning_rate’: 0.3}
``
参考:
001:参考API
002:参考博客
003:开发者讲义
004:github项目
附代码:
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
dataset = loadtxt('dataset_001.csv', delimiter=",")
X = dataset[:,0:8]
Y = dataset[:,8]
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# 不可视化数据集
#model = XGBClassifier()
#model.fit(X_train, y_train)
##可视化测试集的loss
model = XGBClassifier()
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="logloss", eval_set=eval_set, verbose=True)
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))