C++定义指针数组,数组指针,指针数据
https://www.cnblogs.com/warmfrog/p/3695173.html
C语言或C++中,数组元素全为指针的数组称为指针数组
一维指针数组的定义为:类型名*数组标识符[数组长度]
eg: int*ptr_array[10];
以下内容来自百度百科
链接
http://baike.baidu.com/link?url=r6JRJbaleIw_69o-t8uO2vTF0r4oukf1bMMpp0sp9caXDbprF9LNZXwfsf4QovUKWloO2r6CJiNFNPNvP5aRS_
与数组指针关系
数组指针是指向数组首元素的地址的指针,其本质为指针(这个指针存放的是数组首地址的地址,相当于2级指针,这个指针不可移动); 指针数组是数组元素为指针的数组,其本质为数组。
例如:*p[2]是指针数组,实质是一个数组,里面的两个元素都是指针 []的优先级比*的优先级高,p先与[]结合,形成数组p[2],有两个元素的数组,再与*结合,表示此数组是指针类型的,每个数组元素相当于一个指针变量
与二维数组对比
二维数组:如char string_1[10][10]只要定义了一个二维数组,无论赋不赋值,系统都会给他分配相应空间,而且该空间一定是连续的。其每个元素表示一个字符。我们可以通过制定下标对其元素进行修改。
指针数组:如char *str_B[5] 系统至少会分配5个连续的空间用来存储5个元素,表示str_B是一个5个元素的数组,每个元素是一个指向字符型数据的一个指针。
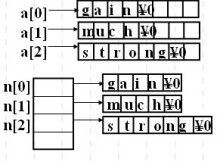
如果我做这样的定义:
char a[3][8]={"gain","much","strong"};
char *n[3]={"gain","much","strong"};
他们在内存的存储方式分别如右图所示,可见,系统给数组a分配了
3×8的空间,而给n分配的空间则取决于具体字符串的长度。
此外,系统分配给a的空间是连续的,而给n分配的空间则不一定连续。
由此可见,相比于比二维字符数组,指针数组有明显的优点:一是指针数组中每个元素所指的字符串不必限制在相同的字符长度;二是访问指针数组中的一个元素是用指针间接进行的,效率比下标方式要高。 但是二维字符数组却可以通过下标很方便的修改某一元素的值,而指针数组却无法这么做。
http://c.biancheng.net/view/2022.html
二维数组在概念上是二维的,有行和列,但在内存中所有的数组元素都是连续排列的,它们之间没有“缝隙”。以下面的二维数组 a 为例:
int a[3][4] = { {0, 1, 2, 3}, {4, 5, 6, 7}, {8, 9, 10, 11} };
从概念上理解,a 的分布像一个矩阵:
0 1 2 3
4 5 6 7
8 9 10 11但在内存中,a 的分布是一维线性的,整个数组占用一块连续的内存:![]()
C语言中的二维数组是按行排列的,也就是先存放 a[0] 行,再存放 a[1] 行,最后存放 a[2] 行;每行中的 4 个元素也是依次存放。数组 a 为 int 类型,每个元素占用 4 个字节,整个数组共占用 4×(3×4) = 48 个字节。
C语言允许把一个二维数组分解成多个一维数组来处理。对于数组 a,它可以分解成三个一维数组,即 a[0]、a[1]、a[2]。每一个一维数组又包含了 4 个元素,例如 a[0] 包含 a[0][0]、a[0][1]、a[0][2]、a[0][3]。
假设数组 a 中第 0 个元素的地址为 1000,那么每个一维数组的首地址如下图所示: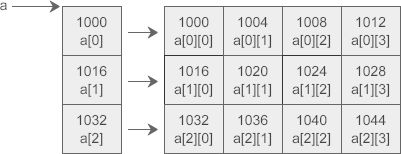
为了更好的理解指针和二维数组的关系,我们先来定义一个指向 a 的指针变量 p:
int (*p)[4] = a;
括号中的*表明 p 是一个指针,它指向一个数组,数组的类型为int [4],这正是 a 所包含的每个一维数组的类型。[ ]的优先级高于*,( )是必须要加的,如果赤裸裸地写作int *p[4],那么应该理解为int *(p[4]),p 就成了一个指针数组,而不是二维数组指针,这在《C语言指针数组》中已经讲到。
对指针进行加法(减法)运算时,它前进(后退)的步长与它指向的数据类型有关,p 指向的数据类型是int [4],那么p+1就前进 4×4 = 16 个字节,p-1就后退 16 个字节,这正好是数组 a 所包含的每个一维数组的长度。也就是说,p+1会使得指针指向二维数组的下一行,p-1会使得指针指向数组的上一行。
数组名 a 在表达式中也会被转换为和 p 等价的指针!
下面我们就来探索一下如何使用指针 p 来访问二维数组中的每个元素。按照上面的定义:
1) p指向数组 a 的开头,也即第 0 行;p+1前进一行,指向第 1 行。
2) *(p+1)表示取地址上的数据,也就是整个第 1 行数据。注意是一行数据,是多个数据,不是第 1 行中的第 0 个元素,下面的运行结果有力地证明了这一点:
- #include
- int main(){
- int a[3][4] = { {0, 1, 2, 3}, {4, 5, 6, 7}, {8, 9, 10, 11} };
- int (*p)[4] = a;
- printf("%d\n", sizeof(*(p+1)));
- return 0;
- }
运行结果:
16
3) *(p+1)+1表示第 1 行第 1 个元素的地址。如何理解呢?*(p+1)单独使用时表示的是第 1 行数据,放在表达式中会被转换为第 1 行数据的首地址,也就是第 1 行第 0 个元素的地址,因为使用整行数据没有实际的含义,编译器遇到这种情况都会转换为指向该行第 0 个元素的指针;就像一维数组的名字,在定义时或者和 sizeof、& 一起使用时才表示整个数组,出现在表达式中就会被转换为指向数组第 0 个元素的指针。
4) *(*(p+1)+1)表示第 1 行第 1 个元素的值。很明显,增加一个 * 表示取地址上的数据。
根据上面的结论,可以很容易推出以下的等价关系:
a+i == p+i
a[i] == p[i] == *(a+i) == *(p+i)
a[i][j] == p[i][j] == *(a[i]+j) == *(p[i]+j) == *(*(a+i)+j) == *(*(p+i)+j)
【实例】使用指针遍历二维数组。
- #include
- int main(){
- int a[3][4]={0,1,2,3,4,5,6,7,8,9,10,11};
- int(*p)[4];
- int i,j;
- p=a;
- for(i=0; i<3; i++){
- for(j=0; j<4; j++) printf("%2d ",*(*(p+i)+j));
- printf("\n");
- }
- return 0;
- }
运行结果:
0 1 2 3
4 5 6 7
8 9 10 11指针数组和二维数组指针的区别
指针数组和二维数组指针在定义时非常相似,只是括号的位置不同:
- int *(p1[5]); //指针数组,可以去掉括号直接写作 int *p1[5];
- int (*p2)[5]; //二维数组指针,不能去掉括号
指针数组和二维数组指针有着本质上的区别:指针数组是一个数组,只是每个元素保存的都是指针,以上面的 p1 为例,在32位环境下它占用 4×5 = 20 个字节的内存。二维数组指针是一个指针,它指向一个二维数组,以上面的 p2 为例,它占用 4 个字节的内存。