【RPC-Python】Redis 协议的缺陷
连接重连
RPC 是建立在 TCP 协议基础上进行消息传递,而 TCP 连接并不总是稳定的,它会受到网络波动的影响而导致连接断开。同时大部分服务器也会限制空闲连接的生存期,如果一个 TCP 连接闲置过久,也会被服务器主动关闭。如果这个 RPC 是以手机作为客户端发起的请求,那么这种连接断开的情况就更为频繁,用户的网络切换行为随时都会引发连接断开。
当 RPC 连接断开时,客户端一般都需要实现连接重连,否则客户端将无法继续进行 RPC 交互。
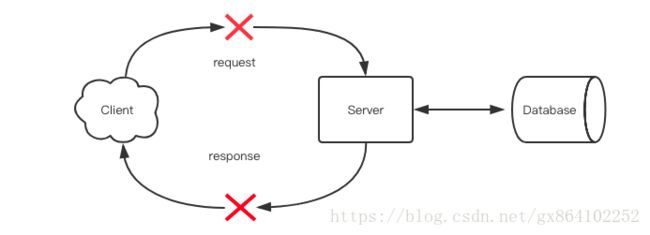
请求重试
当 RPC 客户端向服务器发送请求之后,连接突然断开,这个断开可能发生在请求阶段,这时服务器没有收到消息。也可能发生在响应阶段,这时服务器已经处理了消息,只是客户端没有收到回复就断开了。客户端并不总是可以轻易判断出服务器是否已经处理了消息还是根本就没收到。
然后客户端会尝试重连,连接成功后,需要重试之前的请求。这时问题就来了,如果连接的断开是在响应阶段,那么请求有可能会被重复执行。但是不重试的话,连接的断开如果发生在请求阶段,那就又会导致请求丢失。
所以客户端这时很矛盾,到底是重试呢还是丢弃呢?
请求唯一ID
为了解决上面的问题,客户端在构造请求时要为每个请求赋予一个唯一 ID。
UUID id; // 每个请求都有一个唯一 ID服务器收到请求后会记录这个唯一 ID,当请求处理完成后,会将响应也记录下来和请求 ID 关联上。如果请求重复发送了,就可以立即识别出来。服务器遇到重复请求时,不应该直接拒绝,而是将前面记录下来的响应直接进行回复。
考虑到服务器的内存也是有限的,不可能记录下所有的请求 ID 和响应,所以一般只保留近一段时间的请求 ID 和响应。
class Server {
set cachedResponses; // 已经处理完毕的请求
} Redis客户端的缺陷
如果仔细阅读 Redis 的客户端源码,你会发现 Redis 并没有给每个请求赋予唯一 ID,它只是简单地在遇到异常时重试一下。
def execute_command(self, *args, **options):
"Execute a command and return a parsed response"
pool = self.connection_pool
command_name = args[0]
connection = pool.get_connection(command_name, **options) # 从连接池中获取连接
try:
connection.send_command(*args) # 发送请求
return self.parse_response(connection, command_name, **options) # 接收并解析请求
except (ConnectionError, TimeoutError) as e:
connection.disconnect() # 关闭异常连接
if not connection.retry_on_timeout and isinstance(e, TimeoutError):
raise
connection.send_command(*args) # 重试
return self.parse_response(connection, command_name, **options)
finally:
pool.release(connection) # 被连接池回收那 Redis 究竟是如何解决重复的问题?亦或它根本就没解决?
接下来我们根据返回的错误类型逐个分析:
- ConnectionError
ConnectionError是指在建立连接时就出了错,或者是从连接池里获取连接因为系统过于繁忙,总是拿不到。这种情况毫无疑问是需要重试的,因为客户端根本还没有尝试去发送消息。 - TimeoutError
TimeoutError要分两种情况对待,一种是在写消息时遇到了超时,另一种是在读消息时遇到了超时。
写超时是指内核为当前套接字开辟的写缓存空间已经满了,有三种原因会导致写缓冲满。
- 写方的消息因为网络原因迟迟达到不了读方;
- 读方老是不读消息,所以没有给写方即时 ack;
- 写方因为网络原因收不到对方的 ack;
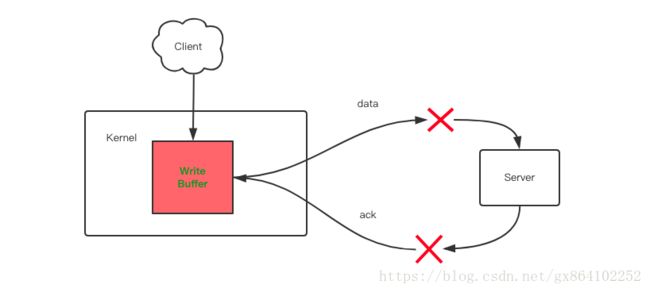
TCP 的超时重传策略要求必须收到读方的 ack 之后才可以将数据从写缓存中移除,否则会继续留在写缓冲区以便后续可能的 TCP 重传。
对于写方的消息达到不了读方这种情况,我们无法预料读方在未来的某个时间点是否又可以收到消息,所以此时不可以随意重试。
对于读方老是不读消息这种情况 (accept 了连接但是没有调用 read 方法),我们无法预料读方在未来的某个时间是否会继续恢复读消息,也就是无法预知服务器 (读方) 是否会处理当前的消息。这个时候选择重试只能是瞎子摸象无从得知是否会导致消息重复。
如果是因为写方临时的网络原因收不到读方的 ack 才导致的写缓冲区满,这时服务器方是已经读取了消息的并进行处理了。这样的超时理论上是不应该重试的,重试必然导致消息重复。

再看读超时,读超时是指消息已经写进 (send) 本地写缓冲区了,然后调用 recv 方法等待对方响应时很久没有收到一个完整的响应消息,可能是一个字节都没收到,也可能只是收到了半包消息。
消息写进写了缓冲区并不意味着读方一定可以收到,recv 方法一个字节都没收到也不能确定是服务器方没有处理还是已经处理了但是响应消息因为网络原因到达不了写方。也只有在收取到半包消息的情况下才可以确认消息确实已经被服务器处理过了。不过就 redis 客户端的实现来说,代码里并没有明确区分是一个字节都没收到还是半包消息。所以在读超时的情况下选择重试也是一样的瞎子摸象。
class StrictRedis(object):
def __init__(self, host='localhost', port=6379,
db=0, password=None, socket_timeout=None,
socket_connect_timeout=None,
socket_keepalive=None, socket_keepalive_options=None,
connection_pool=None, unix_socket_path=None,
encoding='utf-8', encoding_errors='strict',
charset=None, errors=None,
decode_responses=False, retry_on_timeout=False, # 注意这个参数
ssl=False, ssl_keyfile=None, ssl_certfile=None,
ssl_cert_reqs=None, ssl_ca_certs=None):也正是因为这个原因,Redis 的 Client 对象构造器提供了一个retry_on_timeout选项来让用户自己决定要不要在TimeoutError时进行重试,让用户自己来选择在超时出现时要丢失还是重复,客户端代码本身是无法确保消息是否会重复的。
Python 的 Redis 客户端有缺陷,那么 Java 的 Redis 客户端有没有缺陷呢?答案是「有」。因为问题的本质不在于编写客户端的程序员的代码能力问题,而是 Redis 服务器从消息协议的设计上就没有支持消息去重,无论是什么语言编写的客户端都无法解决这个问题。