Spark的Standalone和On Yarn的环境搭建
Standalone(独立模式)
注意:伪分布式集群环境搭建
准备工作
-
准备物理虚拟机一台
版本:CentOS7
-
配置网络
# 如果需要配置双网卡,需要添加网卡硬件支持 vi /etc/sysconfig/network-scripts/ifcfg-ens33 1. 将ip的分配方式改为static 2. 添加 IPADDR=静态IP地址 3. 添加 NETMASK=255.255.255.0 4. 网卡开机自启动 ONBOOT=yes -
关闭防火墙
[root@bogon ~]# systemctl stop firewalld [root@bogon ~]# systemctl disable firewalld Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. -
修改主机名
[root@bogon ~]# vi /etc/hostname Spark -
配置hosts映射
[root@Spark ~]# vi /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.11.100 Spark [root@Spark ~]# ping Spark -
安装vim编辑器
[root@Spark ~]# yum install -y vim
安装Hadoop
-
配置SSH免密登陆
[root@Spark ~]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Created directory '/root/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:KSQFcIduz5Fp5gS+C8FGJMq6v6GS+3ouvjcu4yT0qM4 root@Spark The key's randomart image is: +---[RSA 2048]----+ |..o.ooo | |o...oo | |.+ o...o | |. + +oB . | |.o o O..S | |..+ . +. | |o+.o . | |O=.+. | |XE@o. | +----[SHA256]-----+ [root@Spark ~]# ssh-copy-id Spark /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" The authenticity of host 'spark (192.168.11.100)' can't be established. ECDSA key fingerprint is SHA256:nLUImdu8ZPpknaVGhMQLRROdZ8ZfJCRC+lhqCv6QuF0. ECDSA key fingerprint is MD5:7e:a3:1f:b0:e3:c7:51:7c:24:70:e3:24:b9:ac:45:27. Are you sure you want to continue connecting (yes/no)? yes /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@spark's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'Spark'" and check to make sure that only the key(s) you wanted were added. [root@Spark ~]# ssh Spark Last login: Tue Oct 29 11:32:59 2019 from 192.168.11.1 [root@Spark ~]# exit 登出 Connection to spark closed. -
安装JDK
[root@Spark ~]# rpm -ivh jdk-8u171-linux-x64.rpm 准备中... ################################# [100%] 正在升级/安装... 1:jdk1.8-2000:1.8.0_171-fcs ################################# [100%] Unpacking JAR files... tools.jar... plugin.jar... javaws.jar... deploy.jar... rt.jar... jsse.jar... charsets.jar... localedata.jar... -
安装Hadoop
[root@Spark ~]# tar -zxf hadoop-2.9.2.tar.gz -C /usr [root@Spark ~]# cd /usr/hadoop-2.9.2/ [root@Spark hadoop-2.9.2]# ll 总用量 128 drwxr-xr-x. 2 501 dialout 194 11月 13 2018 bin drwxr-xr-x. 3 501 dialout 20 11月 13 2018 etc drwxr-xr-x. 2 501 dialout 106 11月 13 2018 include drwxr-xr-x. 3 501 dialout 20 11月 13 2018 lib drwxr-xr-x. 2 501 dialout 239 11月 13 2018 libexec -rw-r--r--. 1 501 dialout 106210 11月 13 2018 LICENSE.txt -rw-r--r--. 1 501 dialout 15917 11月 13 2018 NOTICE.txt -rw-r--r--. 1 501 dialout 1366 11月 13 2018 README.txt drwxr-xr-x. 3 501 dialout 4096 11月 13 2018 sbin drwxr-xr-x. 4 501 dialout 31 11月 13 2018 share -
修改HDFS的配置文件
[root@Spark hadoop-2.9.2]# vim /usr/hadoop-2.9.2/etc/hadoop/core-site.xml <property> <name>fs.defaultFSname> <value>hdfs://Spark:9000value> property> <property> <name>hadoop.tmp.dirname> <value>/usr/hadoop-2.9.2/hadoop-${user.name}value> property> [root@Spark hadoop-2.9.2]# vim /usr/hadoop-2.9.2/etc/hadoop/hdfs-site.xml <property> <name>dfs.replicationname> <value>1value> property> <property> <name>dfs.namenode.secondary.http-addressname> <value>Spark:50090value> property> <property> <name>dfs.datanode.max.xcieversname> <value>4096value> property> <property> <name>dfs.datanode.handler.countname> <value>6value> property> [root@Spark hadoop-2.9.2]# vim /usr/hadoop-2.9.2/etc/hadoop/slaves Spark -
配置JDK和Hadoop的环境变量
[root@Spark hadoop-2.9.2]# vim /root/.bashrc JAVA_HOME=/usr/java/latest PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin CLASSPATH=. export HADOOP_HOME export JAVA_HOME export PATH export CLASSPATH [root@Spark hadoop-2.9.2]# source /root/.bashrc -
启动HDFS分布式文件系统,Yarn暂时不用配置
[root@Spark hadoop-2.9.2]# hdfs namenode -format [root@Spark hadoop-2.9.2]# start-dfs.sh Starting namenodes on [Spark] Spark: starting namenode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-namenode-Spark.out Spark: starting datanode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-datanode-Spark.out Starting secondary namenodes [Spark] Spark: starting secondarynamenode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-secondarynamenode-Spark.out [root@Spark hadoop-2.9.2]# jps 10400 Jps 9874 NameNode 10197 SecondaryNameNode 10029 DataNode -
访问HDFS WebUI:http://192.168.11.100:50070
安装Spark
-
安装
[root@Spark ~]# tar -zxf spark-2.4.4-bin-without-hadoop.tgz -C /usr [root@Spark ~]# mv /usr/spark-2.4.4-bin-without-hadoop/ /usr/spark-2.4.4 [root@Spark ~]# cd /usr/spark-2.4.4/ [root@Spark spark-2.4.4]# ll 总用量 100 drwxr-xr-x. 2 1000 1000 4096 8月 28 05:52 bin # spark操作指令目录 drwxr-xr-x. 2 1000 1000 230 8月 28 05:52 conf # 配置文件 drwxr-xr-x. 5 1000 1000 50 8月 28 05:52 data # 测试样例数据 drwxr-xr-x. 4 1000 1000 29 8月 28 05:52 examples # 示例Demo drwxr-xr-x. 2 1000 1000 8192 8月 28 05:52 jars # 运行依赖类库 drwxr-xr-x. 4 1000 1000 38 8月 28 05:52 kubernetes # spark 容器支持 -rw-r--r--. 1 1000 1000 21316 8月 28 05:52 LICENSE drwxr-xr-x. 2 1000 1000 4096 8月 28 05:52 licenses -rw-r--r--. 1 1000 1000 42919 8月 28 05:52 NOTICE drwxr-xr-x. 7 1000 1000 275 8月 28 05:52 python drwxr-xr-x. 3 1000 1000 17 8月 28 05:52 R -rw-r--r--. 1 1000 1000 3952 8月 28 05:52 README.md -rw-r--r--. 1 1000 1000 142 8月 28 05:52 RELEASE drwxr-xr-x. 2 1000 1000 4096 8月 28 05:52 sbin # spark系统服务相关指令 drwxr-xr-x. 2 1000 1000 42 8月 28 05:52 yarn # spark yarn集群支持 -
Spark简单配置
[root@Spark spark-2.4.4]# cp conf/spark-env.sh.template conf/spark-env.sh [root@Spark spark-2.4.4]# cp conf/slaves.template conf/slaves [root@Spark spark-2.4.4]# vim conf/spark-env.sh SPARK_WORKER_INSTANCES=2 SPARK_MASTER_HOST=Spark SPARK_MASTER_PORT=7077 SPARK_WORKER_CORES=4 SPARK_WORKER_MEMORY=2g LD_LIBRARY_PATH=/usr/hadoop-2.9.2/lib/native SPARK_DIST_CLASSPATH=$(hadoop classpath) export SPARK_MASTER_HOST export SPARK_MASTER_PORT export SPARK_WORKER_CORES export SPARK_WORKER_MEMORY export LD_LIBRARY_PATH export SPARK_DIST_CLASSPATH export SPARK_WORKER_INSTANCES [root@Spark spark-2.4.4]# vim conf/slaves Spark -
启动Spark Standalone集群
[root@Spark spark-2.4.4]# sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /usr/spark-2.4.4/logs/spark-root-org.apache.spark.deploy.master.Master-1-Spark.out Spark: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark-2.4.4/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-Spark.out Spark: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark-2.4.4/logs/spark-root-org.apache.spark.deploy.worker.Worker-2-Spark.out [root@Spark spark-2.4.4]# [root@Spark spark-2.4.4]# [root@Spark spark-2.4.4]# jps 16433 Jps 9874 NameNode 16258 Worker 10197 SecondaryNameNode 16136 Master 16328 Worker 10029 DataNode -
访问Spark WebUI:http://192.168.11.100:8080/
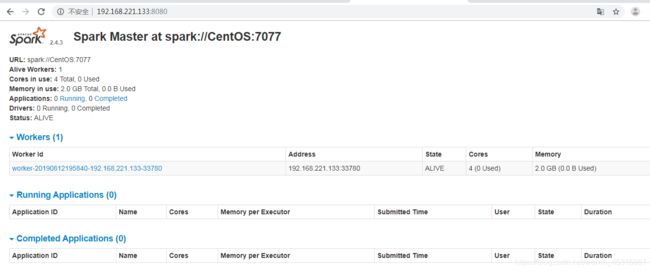
-
Spark shell 命令窗口
–master 远程连接的spark应用的运行环境 spark://host:port, mesos://host:port, yarn, k8s://https://host:port, or local (Default: local[*]).
–total-executor-cores NUM Executor 计算JVM进程 cores: 线程
[root@Spark spark-2.4.4]# bin/spark-shell --master spark://Spark:7077 --total-executor-cores 2 Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://Spark:4040 Spark context available as 'sc' (master = spark://Spark:7077, app id = app-20191029144958-0000). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.4 /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171) Type in expressions to have them evaluated. Type :help for more information. -
Spark 版的WordCount
# 1. 准备测试数据 并上传到HDFS中 root@Spark ~]# vim test.txt [root@Spark ~]# hdfs dfs -put test.txt / # 2. 开发Spark 批处理应用 scala> sc.textFile("hdfs://Spark:9000/test.txt").flatMap(_.split(" ")).map((_,1)).groupBy(_._1).map(t=>(t._1,t._2.size)).saveAsTextFile("hdfs://Spark:9000/result") # 3. 计算的结果需要保存到HDFS [root@Spark ~]# more test.txt Hello World Hello Spark Hello Scala Hello Kafka Kafka Good [root@Spark ~]# hdfs dfs -cat /result/* (Kafka,2) (Hello,4) (World,1) (Scala,1) (Spark,1) (Good,1)
Spark On Yarn
将spark应用发布运行在Hadoop Yarn集群中
YARN:分布式资源管理和调度系统
准备工作
-
克隆机
-
修改ens33网卡的ip地址: 192.168.11.101
-
修改hostname: SparkOnYarn
-
修改hosts文件: 192.168.11.101 SparkOnYarn
-
配置SSH免密登陆
[root@SparkOnYarn ~]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Created directory '/root/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:YfN4vpOtE5dk3+cGQ1LsnnmfPH8zRb7HXnFt+xcruKE root@SparkOnYarn The key's randomart image is: +---[RSA 2048]----+ | . | | o | | + o | | . = + o o| | S oo * B+| | o. o BoX| | .*. .BX| | =oo. O@| | Eo=. .o%| +----[SHA256]-----+ [root@SparkOnYarn ~]# ssh-copy-id SparkOnYarn /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@sparkonyarn's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'SparkOnYarn'" and check to make sure that only the key(s) you wanted were added. -
安装JDK
[root@SparkOnYarn ~]# rpm -ivh jdk-8u171-linux-x64.rpm 准备中... ################################# [100%] 正在升级/安装... 1:jdk1.8-2000:1.8.0_171-fcs ################################# [100%] Unpacking JAR files... tools.jar... plugin.jar... javaws.jar... deploy.jar... rt.jar... jsse.jar... charsets.jar... localedata.jar... -
安装Hadoop(HDFS&YARN)
[root@SparkOnYarn ~]# tar -zxf hadoop-2.9.2.tar.gz -C /usr [root@SparkOnYarn ~]# cd /usr/hadoop-2.9.2/ -
修改HDFS配置文件
[root@SparkOnYarn ~]# vi /usr/hadoop-2.9.2/etc/hadoop/core-site.xml <!--nn访问入口--> <property> <name>fs.defaultFS</name> <value>hdfs://SparkOnYarn:9000</value> </property> <!--hdfs工作基础目录--> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop-2.9.2/hadoop-${user.name}</value> </property> [root@SparkOnYarn ~]# vi /usr/hadoop-2.9.2/etc/hadoop/hdfs-site.xml <!--block副本因子--> <property> <name>dfs.replication</name> <value>1</value> </property> <!--配置Sencondary namenode所在物理主机--> <property> <name>dfs.namenode.secondary.http-address</name> <value>SparkOnYarn:50090</value> </property> <!--设置datanode最大文件操作数--> <property> <name>dfs.datanode.max.xcievers</name> <value>4096</value> </property> <!--设置datanode并行处理能力--> <property> <name>dfs.datanode.handler.count</name> <value>6</value> </property> [root@SparkOnYarn ~]# vi /usr/hadoop-2.9.2/etc/hadoop/slaves SparkOnYarn #----------------------------------------------------------------------- [root@SparkOnYarn ~]# vi /usr/hadoop-2.9.2/etc/hadoop/yarn-site.xml <!-- Site specific YARN configuration properties --> <!--配置MapReduce计算框架的核心实现Shuffle-洗牌--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--配置资源管理器所在的目标主机--> <property> <name>yarn.resourcemanager.hostname</name> <value>SparkOnYarn</value> </property> <!--关闭物理内存检查--> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!--关闭虚拟内存检查--> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> [root@SparkOnYarn ~]# cp /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml.template /usr/hadoop-2.9.2/etc/hadoop/mapred-site.xml <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> [root@SparkOnYarn ~]# vim .bashrc HADOOP_HOME=/usr/hadoop-2.9.2 JAVA_HOME=/usr/java/latest CLASSPATH=. PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export JAVA_HOME export CLASSPATH export PATH export HADOOP_HOME [root@SparkOnYarn ~]# source .bashrc -
启动Hadoop相关服务
[root@SparkOnYarn ~]# hdfs namenode -format [root@SparkOnYarn ~]# start-dfs.sh Starting namenodes on [SparkOnYarn] SparkOnYarn: starting namenode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-namenode-SparkOnYarn.out SparkOnYarn: starting datanode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-datanode-SparkOnYarn.out Starting secondary namenodes [SparkOnYarn] SparkOnYarn: starting secondarynamenode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-secondarynamenode-SparkOnYarn.out [root@SparkOnYarn ~]# jps 9634 Jps 9270 DataNode 9115 NameNode 9469 SecondaryNameNode [root@SparkOnYarn ~]# [root@SparkOnYarn ~]# start-yarn.sh starting yarn daemons starting resourcemanager, logging to /usr/hadoop-2.9.2/logs/yarn-root-resourcemanager-SparkOnYarn.out SparkOnYarn: starting nodemanager, logging to /usr/hadoop-2.9.2/logs/yarn-root-nodemanager-SparkOnYarn.out [root@SparkOnYarn ~]# jps 9844 NodeManager 9270 DataNode 9115 NameNode 9723 ResourceManager 10156 Jps 9469 SecondaryNameNode -
配置安装Spark
[root@SparkOnYarn ~]# tar -zxf spark-2.4.4-bin-without-hadoop.tgz -C /usr [root@SparkOnYarn ~]# mv /usr/spark-2.4.4-bin-without-hadoop/ /usr/spark-2.4.4 [root@SparkOnYarn ~]# cd /usr/spark-2.4.4/ [root@SparkOnYarn spark-2.4.4]# cp conf/spark-env.sh.template conf/spark-env.sh [root@SparkOnYarn spark-2.4.4]# cp conf/slaves.template conf/slaves [root@SparkOnYarn spark-2.4.4]# vim conf/spark-env.sh HADOOP_CONF_DIR=/usr/hadoop-2.9.2/etc/hadoop YARN_CONF_DIR=/usr/hadoop-2.9.2/etc/hadoop SPARK_EXECUTOR_CORES=4 SPARK_EXECUTOR_MEMORY=1g SPARK_DRIVER_MEMORY=1g LD_LIBRARY_PATH=/usr/hadoop-2.9.2/lib/native SPARK_DIST_CLASSPATH=$(hadoop classpath) SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs:///spark-logs" export HADOOP_CONF_DIR export YARN_CONF_DIR export SPARK_EXECUTOR_CORES export SPARK_DRIVER_MEMORY export SPARK_EXECUTOR_MEMORY export LD_LIBRARY_PATH export SPARK_DIST_CLASSPATH # 开启historyserver optional export SPARK_HISTORY_OPTS [root@SparkOnYarn spark-2.4.4]# vim conf/spark-defaults.conf # 开启spark history server日志记录功能 spark.eventLog.enabled=true spark.eventLog.dir=hdfs:///spark-logs [root@SparkOnYarn spark-2.4.4]# hdfs dfs -mkdir /spark-logs [root@SparkOnYarn spark-2.4.4]# sbin/start-history-server.sh starting org.apache.spark.deploy.history.HistoryServer, logging to /usr/spark-2.4.4/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-SparkOnYarn.out [root@SparkOnYarn spark-2.4.4]# jps 13968 Jps 9844 NodeManager 9270 DataNode 13880 HistoryServer 9115 NameNode 9723 ResourceManager 9469 SecondaryNameNode -
测试SparkOnYarn
Spark Shell
–executor-cores 每一个Executors JVM进程中的核心(线程)数量
–num-executors 总共 有多少个Executors JVM,进程
– master yarn
[root@SparkOnYarn spark-2.4.4]# bin/spark-shell --master yarn --executor-cores 2 --num-executors 2 Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 19/10/29 16:41:31 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME. Spark context Web UI available at http://SparkOnYarn:4040 Spark context available as 'sc' (master = yarn, app id = application_1572337552150_0001). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.4 /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_171) Type in expressions to have them evaluated. Type :help for more information. scala> sc.textFile("hdfs://SparkOnYarn:9000/test.txt").flatMap(_.split(" ")).map((_,1)).groupBy(_._1).map(t=>(t._1,t._2.size)).saveAsTextFile("hdfs://SparkOnYarn:9000/result")Spark Submit
[root@SparkOnYarn spark-2.4.4]# bin/spark-submit --master yarn --class com.baizhi.WordCountApplication3 --executor-cores 2 --num-executors 1 /root/spark-day1-1.0-SNAPSHOT.jar [root@SparkOnYarn hadoop-2.9.2]# hdfs dfs -cat /result2/* (are,4) (you,4) (how,2) (bj,1) (welcome,1) (from,1) (ok,1) (old,1) (to,1) (where,1)