爬虫学习记录(四)————利用pyquery,re爬取静态网站信息存储到mongodb中
爬虫学习记录(四)————利用pyquery,re爬取静态网站信息存储到mongodb中
-
- 静态页面爬取
-
- 引入需要的包
- 定义获取html文件的基本函数
- 定义获取所有详情页的url函数
- 定义解析详细信息的函数
- 将函数链接起来
- 存储到mongodb中
-
- 链接mongodb的基本参数
- 定义存储函数
- 重新编写主函数
- 学习感悟
静态页面爬取
GitHub地址:https://github.com/yunlong-G/learn/blob/master/spider_learn/static_spider_douban.ipynb
以豆瓣电影网站为例,使用request,pyquery,re进行爬取解析页面信息,将电影的基本信息存储到mongodb中。
引入需要的包
import requests
import logging
import re
import pymongo
from pyquery import PyQuery as pq
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
url = 'https://movie.douban.com'
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 OPR/66.0.3515.115'}
定义获取html文件的基本函数
豆瓣网站首页信息的爬取,如果不适用头文件的话,会被拦截,无法获得信息。头文件的内容如下图所示,改成字典形式就好。

在爬取url时进行异常检测,根据状态码来判断是否爬取成功。
def get_html(url, headers):
logging.info('scraping %s...', url)
try:
response = requests.get(url, headers = headers)
if response.status_code == 200:
return response.text
logging.error('get invalid status code %s while scraping %s', response.status_code, url)
except requests.RequestException:
logging.error('error occurred while scraping %s', url, exc_info=True)
定义获取所有详情页的url函数
通过电影首页的信息筛选每一个电影详情页的url,将其存到列表并返回。这里采用的是re库进行筛选,但此后会发现有很多多余的url要判断是否可用,并去重。
def get_all_urls():
doc = pq(url,headers=headers)
detail = doc('.ui-slide-item')
# print(detail)
details = re.findall('href="(.*?)"',str(detail), re.S)
detail = []
for d in details:
if 'gallery' not in d and 'from=showing' in d and d not in detail:
detail.append(d)
return detail
定义解析详细信息的函数
对每一个电影详情页的解析方法都是一样的,通过pyquery可以直接获得电影封面,之后我根据re的search合sub筛选了好多信息,方法我个人感觉比较麻烦,如何使用pyquery更快的查询我还不是特别熟练,也希望看到这篇博客的大神可以帮助解答。
def parse_info(html):
doc = pq(html)
cover = doc('#mainpic').children('a').children().attr('src')
title = doc('h1')
name = re.search('(.*?)', str(title), re.S)
name = re.sub('|','',str(name.group()))
links = doc('#info')
leader = re.search('rel="v:directedBy">(.*?)',str(links),re.S)
leader = re.sub('rel="v:directedBy">|','',str(leader.group()))
time = re.search('',str(links),re.S)
time = re.sub('', '',str(time.group()))
publish = re.search('上映日期: ',str(links),re.S)
publish = re.sub('上映日期: ','',str(publish.group()))
categories = re.findall('(.*?)',str(links),re.S)
score = pq(doc.find('#interest_sectl'))
score = re.findall(' (.*?)<', str(score), re.S)
return {
'cover': cover,
'name': name,
'categories': categories,
'published_at': publish,
'director': leader,
'score': score
}
将函数链接起来
def main():
detail = get_all_urls()
for d in detail:
html =get_html(d, headers)
data = parse_info(html)
logging.info('get detail data %s', data)
if __name__ == '__main__':
main()
存储到mongodb中
链接mongodb的基本参数
MONGO_CONNECTION_STRING = 'mongodb://localhost:27017'
MONGO_DB_NAME = 'movies'
MONGO_COLLECTION_NAME = 'movies'
client = pymongo.MongoClient(MONGO_CONNECTION_STRING)
db = client['movies']
collection = db['movies']
在这里我们声明了几个变量,介绍如下:
- MONGO_CONNECTION_STRING:MongoDB 的连接字符串,里面定义了 MongoDB 的基本连接信息,如 host、port,还可以定义用户名密码等内容。
- MONGO_DB_NAME:MongoDB 数据库的名称。
- MONGO_COLLECTION_NAME:MongoDB 的集合名称。
这里我们用 MongoClient 声明了一个连接对象,然后依次声明了存储的数据库和集合。
接下来,我们再实现一个将数据保存到 MongoDB 的方法,实现如下:
定义存储函数
def save_data(data):
collection.update_one({
'name': data.get('name')
}, {
'$set': data
}, upsert=True)
重新编写主函数
def main():
detail = get_all_urls()
for d in detail:
html =get_html(d, headers)
data = parse_info(html)
logging.info('get detail data %s', data)
logging.info('saving data to mongodb')
save_data(data)
logging.info('data saved successfully')
if __name__ == '__main__':
main()
最后数据库中会有这14个正在热映的电影信息。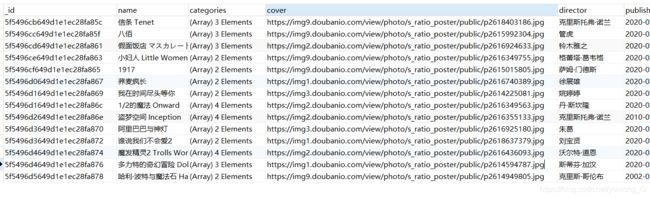
学习感悟
对静态网站的爬取html文件没有太多需要注意的部分,但是豆瓣网站的html文件个人觉得很繁杂,很难快速使用pyquery进行查找节点,也可能是我第一次主动爬取一个网站的原因。总的说来应用前几次的学习内容进行了自主的一次简单爬虫,感觉里爬虫又近了一步,希望读者可以更快的熟悉爬虫过程,有什么好的改良也希望可以相互交流。