mysql:名次排名 (并列与不并列)
说明
- 做后台的难免与sql接触,到目前为止搞过的sql大致都是一些简单的sql语句构造,在这里准备把自己在写sql时遇到的一些比较少见的用法记录一下。
- 又学习了一些之前一直没搞清的:
- DDL—数据定义语言(CREATE,ALTER,DROP,DECLARE)
- DML—数据操纵语言(SELECT,DELETE,UPDATE,INSERT)
- DCL—数据控制语言(GRANT,REVOKE,COMMIT,ROLLBACK)
正文
mysql用户
- 最近自己安装了一个mysql,需要配置上和测试环境一样的用户和密码,免得反复修改工程中的数据源配置。记录一下跟用户相关的mysql语法。万一以后当上了DBA呢?
- 直接创建用户:
CREATE USER 'username'@'host' IDENTIFIED BY 'password';- username:用户名
- host:该用户可以登录的ip
- password:密码
- 删除用户:
DROP USER 'username'@'host'; - 授权:
GRANT privileges ON databasename.tablename TO 'username'@'host';- privileges:权限[SELECT,INSERT,UPDATE,ALL]
- databasename:目标数据库[可以用*表示所有]
- tablename:目标表[可以用*表示所有]
- 创建同时授权:
GRANT all privileges on databasename.tablename to 'username'@'host' identified by 'password'
[没试验成功];
- 直接创建用户:
mysql排行查询
- 如何计算id=1的user的排名?
- 利用子查询,统计其”值”比该id的”值”大的记录总数:
-
COUNT(1) + 1 -
FROM -
`user` -
WHERE -
score > (SELECT score FROM `user` WHERE id = 1);
-
- 利用子查询,统计其”值”比该id的”值”大的记录总数:
- 如何实现一个排行榜查询?
- 这个地方其实就是要学习一下sql中的@, :=, CASE WHEN 这些用法
- 1.利用列序号:
-
SELECT -
id, `name`, score, -
@rownum:=@rownum +1 as rownum -
FROM -
(SELECT @rownum:=0) r , -
`user` -
ORDER BY score DESC;
-
- 2.更真实的排序:
-
SELECT id, `name`, score, -
@rownum := @rownum + 1 AS tmp, -
@incrnum := CASE -
WHEN @rowtotal = score THEN @incrnum -
WHEN @rowtotal := score THEN @rownum -
END AS rownum -
FROM -
(SELECT id, `name`, score FROM `user` ORDER BY score DESC) AS a, -
(SELECT @rownum := 0, @rowtotal := NULL, @incrnum := 0) b
-
- 擅自解释一下,有待考证:
- 思路:利用两个序号,第一个自然排序,第二个当分数和上一个相同时,使用上一个的排序,否则使用第一个的当前顺序。
- 注意点:
- 自定义变量【@】rownum初始值为0,并每次+1后赋值给自己;
- 自定义变量【@】rowtotal初始值为NULL,每次score不等于它时,将score赋值给它;
- 自定义变量【@】incrnum,初始值为0,并每次(如果score等于上次的score,则赋值为上次的incrnum;否则,rowtotal重新赋值为当前score,incrnum赋值为自然排序)
http://www.cnblogs.com/zengguowang/p/5541431.html
sql语句查询排名
思路:有点类似循环里面的自增一样,设置一个变量并赋予初始值,循环一次自增加1,从而实现排序;
mysql里则是需要先将数据查询出来并先行按照需要排序的字段做好降序desc,或则升序asc,设置好排序的变量(初始值为0):
a>.将已经排序好的数据从第一条依次取出来,取一条就自增加一,实现从1到最后的一个排名
b>.当出现相同的数据时,排名保持不变,此时则需要再设置一个变量,用来记录上一条数据的值,跟当前数据的值进行对比,如果相同,则排名不变,不相同则排名自增加1
c.当出现相同的数据时,排名保持不变,但是保持不变的排名依旧会占用一个位置,也就是类似于(1,2,2,2,5)这种排名就是属于中间的三个排名是一样的,但是第五个排名按照上面一种情况是(1,2,2,2,3),现在则是排名相同也会占据排名的位置
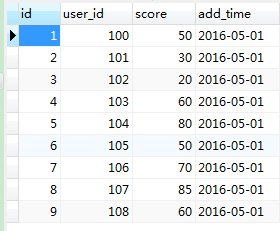
准备数据(用户id,分数):
CREATE TABLE `sql_rank` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(11) unsigned NOT NULL,
`score` tinyint(3) unsigned NOT NULL,
`add_time` date NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
插入数据:
INSERT INTO sql_rank (user_id, score, add_time)
VALUES
(100, 50, '2016-05-01'),
(101, 30, '2016-05-01'),
(102, 20, '2016-05-01'),
(103, 60, '2016-05-01'),
(104, 80, '2016-05-01'),
(105, 50, '2016-05-01'),
(106, 70, '2016-05-01'),
(107, 85, '2016-05-01'),
(108, 60, '2016-05-01')
当前数据库数据:
一、sql1{不管数据相同与否,排名依次排序(1,2,3,4,5,6,7.....)}
![]()
SELECT
obj.user_id,obj.score,@rownum := @rownum + 1 AS rownum
FROM
(
SELECT
user_id,
score
FROM
`sql_rank`
ORDER BY
score DESC
) AS obj,
(SELECT @rownum := 0) r
![]()
执行的结果如下图:
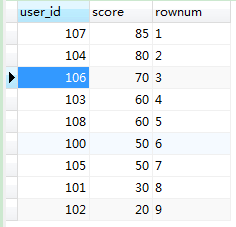
可以看到,现在按照分数从1到9都排好序了,但是有些分数相同的用户排名却不一样,这就是接下来要说的第二种sql
二、sql2{只要数据有相同的排名就一样,排名依次排序(1,2,2,3,3,4,5.....)}
![]()
SELECT
obj.user_id,
obj.score,
CASE
WHEN @rowtotal = obj.score THEN
@rownum
WHEN @rowtotal := obj.score THEN
@rownum :=@rownum + 1
WHEN @rowtotal = 0 THEN
@rownum :=@rownum + 1
END AS rownum
FROM
(
SELECT
user_id,
score
FROM
`sql_rank`
ORDER BY
score DESC
) AS obj,
(SELECT @rownum := 0 ,@rowtotal := NULL) r
![]()
这时候就新增加了一个变量,用于记录上一条数据的分数了,只要当前数据分数跟上一条数据的分数比较,相同分数的排名就不变,不相同分数的排名就加一,并且更新变量的分数值为该条数据的分数,依次比较
如下图结果:
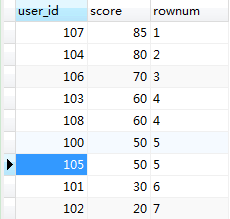
跟第一条sql的结果相对比你会发现,分数相同的排名也相同,并且最后一名的名次由第9名变成了第7名;
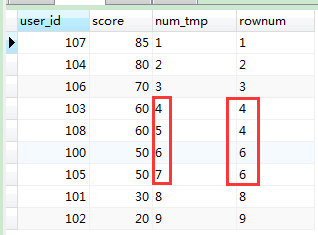
如果你需要分数相同的排名也相同,但是后面的排名不能受到分数相同排名相同而不占位的影响,也就是哪怕你排名相同,你也占了这个位置(比如:1,2,2,4,5,5,7....这种形式的,虽然排名有相同,但是你占位了,后续的排名根据占位来排)
三、sql2{只要数据有相同的排名就一样,但是相同排名也占位,排名依次排序(1,2,2,4,5,5,7.....)}
此时需呀再增加一个变量,来记录排序的号码(自增)
![]()
SELECT
obj_new.user_id,
obj_new.score,
obj_new.rownum
FROM
(
SELECT
obj.user_id,
obj.score,
@rownum := @rownum + 1 AS num_tmp,
@incrnum := CASE
WHEN @rowtotal = obj.score THEN
@incrnum
WHEN @rowtotal := obj.score THEN
@rownum
END AS rownum
FROM
(
SELECT
user_id,
score
FROM
`sql_rank`
ORDER BY
score DESC
) AS obj,
(
SELECT
@rownum := 0 ,@rowtotal := NULL ,@incrnum := 0
) r
) AS obj_new
![]()
上面sql执行的结果如下:
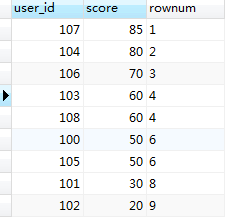
结果集中分数相同的,排名相同,同时它也占据了那个位置,中间的一个数据过程本人截图了,请往下看(跟上图做对比你就明白了):