简单的文本挖掘-用于QQ聊天记录(R)
平时的交流很多都在QQ上,QQ交流已经离不开日常的生活,这里我用R来分析QQ聊天记录,看看平时都聊了什么。
首先介绍下用的文本挖掘的包:Rwordseg 一个 R 环境下的中文分词工具,使用 rJava 调用 Java 分词工具 Ansj。
该包需配合rJava包一起使用。详见李舰老师博客:http://jianl.org/
Rwordseg包不能直接install.packages("Rwordseg"),需使用下列代码
install.packages("Rwordseg", repos="http://R-Forge.R-project.org")如果安装不成功,可以直接下载压缩包,然后安装:
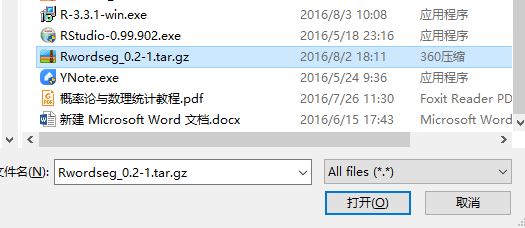
必备包安装好,下面该导出QQ聊天记录了:

这里保存为txt格式

导出的txt,导入R的时候可能会时间很长或者出错,这里用notepad++打开txt,然后转为ANSI编码格式即可。
准备工作做好了,下面开始文本
library(rJava)
library(Rwordseg)
library(RColorBrewer)
library(wordcloud)
myfile<-read.csv(file="D:\\message.txt",header=FALSE) #载入文本数据myfile[1:15,][1] 消息记录(此消息记录为文本格式,不支持重新导入)
[2] ================================================================
[3] 消息分组:高中
[4] ================================================================
[5] 消息对象:梦康
[6] ================================================================
[7] 2016-06-24 15:56:11 梦康
[8] 生日快乐 永远十八岁!
[9] ================================================================
[10] 消息分组:高中
[11] ================================================================
[12] 消息对象:李晨宇
[13] ================================================================
[14] 2016-07-04 20:24:35 李晨宇
[15] [收到好友的PK挑战,请在最新QQ手机版中查看详情]
14116 Levels: - 富有激情和强烈的创新优化意识,责任心抗压力强,能在快节奏环境中工作,能和项目成员进行快速有效的沟通 ...
myfile.res <- myfile[myfile!=" "] #去除 ""
myfile.words <- unlist(lapply(X = myfile.res,FUN = segmentCN)) #分词处理
myfile.words <- gsub(pattern="[a-zA-Z\\/\\.0-9]","",myfile.words)#正则表达式,用于替换
myfile.words <- gsub("\n","",myfile.words)
myfile.words <- gsub(" ","",myfile.words)#空格替换为空
myfile.words <- gsub("\\d","",myfile.words)#去除所有数字
myfile.words<-subset(myfile.words,nchar(as.character(myfile.words))>1) #选取字符大于1的数据集
myfile.freq <- table(unlist(myfile.words))
myfile.freq <- rev(sort(myfile.freq)) #排序从大到小
myfile.freq <- data.frame(myfile.freq)
names(myfile.freq) <- c("words","freq")
myfile.freq[1:15,] #词频统计数据:
words freq
1 图片 1664
2 表情 1102
3 夏天 763
4 消息 744
5 com 647
6 数据 572
7 系统 556
8 可以 497
9 三千 465
10 佳丽 464
11 后宫 464
12 绣花针 463
13 铁杵 463
14 加入 396
15 qq 379
wordcloud(myfile.freq$words,myfile.freq$freq,random.order=FALSE,random.color=FALSE,colors=c(1:20))

换个炫酷的色彩
mycolors <- brewer.pal(8,"Dark2")
windowsFonts(myFont=windowsFont("华文彩云"))
wordcloud(myfile.freq$words,myfile.freq$freq,random.order=FALSE,
random.color=FALSE,colors=mycolors,family="myFont")

从词云从明显的可以看到,
1.我的聊天记录出现的图片和表情最多,而且比“消息”这词还多,说明现在聊天“图片”和“表情”很疯狂啊!PS想和我斗图,来试试~
2.怎么会有“qq”和“com”呢,我来查了下聊天记录
1. 这是群里面的一段聊天记录。。。原来会自动加上qq.com,所以“qq”和“com”这两词词频特别高.
2. 这段聊天记录还有“夏天”,
(1)这位童靴...果然很活跃。
(2)另一种可能就是别人的名字都被分词给分了,“夏天”很巧就是个词
3. 从这一段聊天记录就可以明显的发现:群成员都喜欢发图片和表情....PS说出来你可能不信,我的图片、表情都是群里面的。
大家看到这个词云有几个词特别的显眼:“佳丽”、“后宫”、“三千”、“绣花针”
这里!!我要特别说明一下,大家不要误会!

就是这货,认识他感觉好丢人(表情脸)
说明词云来是有些不准的,有些词需要去除,“人名”需要去除,接下来继续做词云。

最终词云,今天娱乐结束。。。