Machine Learning Yearning - note
Andrew Ng的机器学习新书 Machine Learning Yearning的简单记录。
1.Why Machine Learning Strategy
为了提高算法性能,尝试各种办法:
Get more data,Collect a more diverse training set,Train the algorithm longer,Try a bigger neural network,Try a smaller neural network,Try adding regularization ,Change the neural network architecture
…
怎么选呢? choose well 还好, choose poorly就糟糕了。
Most machine learning problems leave clues that tell you what is useful to try, and what is not useful to try. Learning to read those clues will save you months or years of development time.
2.How to use this book to help your team
A few changes in prioritization can have a huge effect on your team’s productivity.
学习完本书:
you will have a deep understanding of how to set technical direction for a machine learning project.
4.Scale drives machine learning progress
关于deep learning的兴起:
- Data availability
- Computational scale
the older algorithms didn’t know what to do with all the data we now have.引出传统算法与NN的性能对比图。page9 注释1
5.Setting up development and test sets
由检测cat的例子引出。
你从网络中获得大量的cats 和 non-cats图像,按70%/30%分为training set/test set。有了这些样本,可以建立一个在training set/test set都work well的detector。但是在移动端性能太差。
your algorithm did not generalize well to the actual distribution you care about of smartphone pictures.[移动端用户上传的图像–分辨率低、模糊、光照不理想,这与从网络中下载的样本分布不同]
按70%/30% 划分样本构成 training and test sets在practice中是可以work的,but is a bad idea in more and more applications where the training distribution is different from the distribution you ultimately care about.
- Training set
run your learning algorithm on - Dev (development) set
tune parameters, select features, and make other decisions regarding the learning algorithm - Test set
evaluate the performance of the algorithm
The purpose of the dev and test sets are to direct your team toward the most important changes to make to the machine learning system.
Choose dev and test sets to reflect data you expect to get in the future and want to do well on.
6.Your dev and test sets should come from the same distribution
由例子引出。假设手里有了移动端的cats样本,用作dev and test sets,它们是US, China, India, and Other相当于四个分布了。分配的时候不能简单地把其中两个国家的cats样本放一个sets,另两个作为一个sets。这会导致和chapter5一样的问题:数据集的分布不同。所以dev set 和 test set中都要包含这四类cats。 举例:假设系统work well on dev but not on test。此时, 如果保证了dev 和 test 的数据分布相同,那么很清楚知道哪里出问题了。( overfit dev set) 如果dev和test数据分布不同,就不太清楚问题出在哪里了。(overfit dev set; test set is harder than dev set; test not harder,but just different from the dev set )7.How large do the dev/test sets need to be?
The dev set should be large enough to detect differences between algorithms that you are trying out. 例子:classifier A accuracy 90%, classifier B accuracy 90.1%, dev set的样本数量太少(100)不足以detect这二者0.1%的difference。
8.Establish a single-number evaluation metric for your team to optimize
single-number evaluation metric的优点:
- 快速从众多分类器中做选择(根据evaluation metric的得分排序,指向明确,single-number,谁高用谁,就一个也不用和其他的比来比去。)
√ classification accuracy : a single number for assessing classifier
× precision and recall : two numbers for assessing classifier [看precision,classifierA比B好;看recall,classifierB比A好]
Having multiple-number evaluation metrics makes it
harder to compare algorithms.
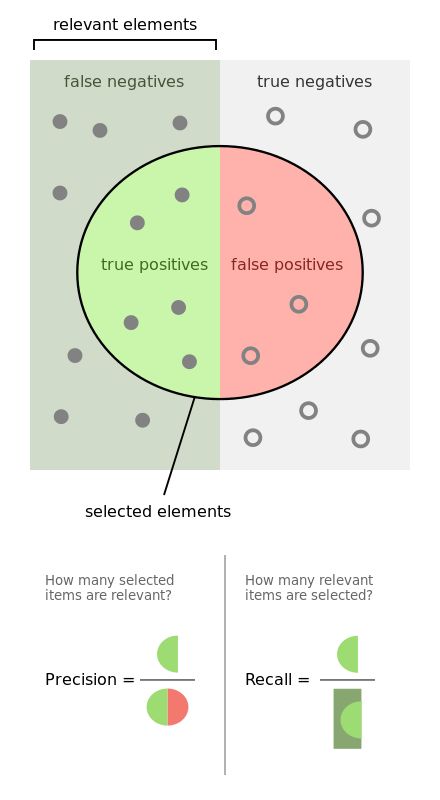
如果想用多个numbers的evaluation metric。一种方式是combine them into a single number。
F1 score https://en.wikipedia.org/wiki/F1_score

9.Optimizing and satisficing metrics
another way to combine multiple evaluation metrics
假设有N个不同的指标,考虑设置 N-1个“satisficing”指标(binary file size of model, running time, …),1个“optimizing”指标(accuracy)。控制变量,在给定N-1个条件后(通过阈值等),控制了N-1个satisficing指标,优化accuracy。
例子:
假设建硬件设备,麦克风监听到用户说唤醒词“wakeword”,则系统被唤醒。(Apple的‘Hey Siri’, Android的‘Okay Google’, Amazon Echo的‘Alexa’)。
两种指标出现了:
- false positive rate: 用户没喊唤醒词,系统被唤醒了的比例
- false negative rate:用户喊了唤醒词,系统没有被唤醒的比例
考虑一下实际情况,应该尽量避免false negative的情况,江湖救急,我要唤醒你,结果你还在睡觉,太尴尬。所以相比较,optimizing metirc应该是false negative rate。另一个false positive rate作为satisficing metric。具体一下评价性能的目标可以是:
在保证每24小时的唤醒过程中至多发生一次false positive前提下,最小化false negative rate。
明确要优化的评价指标
10.Having a dev set and metric speeds up iterations
针对一个新问题,构建机器学习系统:
如图,循环往复。The faster you can go round this loop, the faster you will make progress.
解释了dev/test sets和metric的重要性:
- Each time you try an idea, measuring your idea is performance on the dev set lets you quickly decide if you are heading in the right direction.[quickly发现idea导致的性能提升程度,quickly决定放弃或继续调整idea]
以检测cats为例,分类准确率从95.0%到95.1%,这1%的提升可能放在app中没有明显的变化,但是多个1%的积累效果是可观的。
11.When to change dev/test sets and metrics
开始一个新项目,尽快选择dev/test sets。(明确的追求目标)
Having an initial dev/test set and metric helps you iterate quickly. If you ever find that the dev/test sets or metric are no longer pointing your team in the right direction, it is not a big deal! Just change them and make sure your team knows about the new direction.
12.Takeaways: Setting up development and test sets
- dev and test sets 最好相同分布,可以与train set不同分布。
- 选择single-number evaluation metric来优化,如果有多个关心目标,(1)考虑组合到单一的形式(averaging multiple error metrics); (2)考虑定义satisficing和optimizing metrics。
- 机器学习是高度迭代过程,需要尝试很多想法。
- dev/test sets 和 single-number evaluation metric帮助快速评价算法,加快迭代(idea->code->experiment)进程。
- 开始新项目,尽快建立dev/test sets。
- 旧的启发式的train/test比例70%/30%不再适用于大规模数据,dev + test远小于数据集的30%。
- dev set should be large enough to detect meaningful changes in the accuracy. test set should be big enough to give you a confident estimate of the final performance.
- 当dev set和metric偏离正确方向的时候,及时更改:
- overfit dev set -> more dev set data
- 实际关心的数据分布于dev/test set不同 -> 换新的dev/test set数据
- metric不再衡量对你看重的因素的话 -> 换metirc