深入学习java各种容器--面试使用
转载地址
对着原文走了一遍流程,分析地址是androd sdk中的29中的源代码分析,和原文地址jdk源码分析有点区别,大体一致
前言
相信大家在工作中使用容器的场景是具有多变性的,那么在性能方面你知道怎么去选择一种当前最优的数据结构吗? 或许对于工作多年有经验的开发者来说,是没有问题的。但是对于刚入门 1 ~ 2 年或者只知道怎么使用而不知道对当前最适用的,那么这一篇文章将全面为你解惑。
该篇还是延续上一篇 面试官: 说一下你做过哪些性能优化? 的风格,以问答的模式来进行解答,相信对你是有帮助的。
如果你正在找工作, 那么你需要一份 Android 高级开发面试宝典
List
1、有使用过 ArrayList 吗 ?说一下它的底层实现 ?
程序员:
有使用,它的底层是基于数组的数据结构, 默认第一次初始化长度为 10 ,由于 add ,put , size 没有处理线程安全,所以它是非线程安全的。
要不我手动画一下它的整体结构吧。如下图所示。
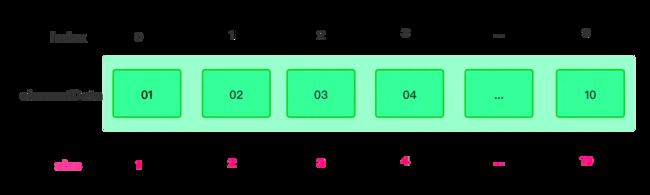
图解:
- Index: ArrayList 的索引下标
- elementData: ArrayList 的索引下标对应的数据
- size: ArrayList 的大小
面试官:
嗯,那你详细说下它的 add 过程,以及自动扩容机制。
程序员:
好的,那我先说 add 过程,在说自动扩容机制。
- add过程
public boolean add(E e) {
//确保数组大小足够,不需要扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
//直接复制,线程安全
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
//如果是空数组,就从最小容量和默认容量10之间取最大值
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//确保容积足够
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
//记录数组被修改
modCount++;
//如果我们希望的最小容量大于目前数组的长度,那么就扩容
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
//扩容机制是 增加原来数组的 1/2 -> (oldCapacity + (oldCapacity >> 1))
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//oldCapacity >> 1 是把oldCapacity / 2的意思
int newCapacity = oldCapacity + (oldCapacity >> 1);
//如果扩容后的值 < 我们的期望值,扩容后的值就等于我们的期望值
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//如果扩容后的值 > jvm所能分配的数组的最大值,那么就取Integer的最大值
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
//通过复制进行扩容
elementData = Arrays.copyOf(elementData, newCapacity);
}
1、当我们实例化 ArrayList 的时候可以指定它的大小,也可以直接空参实例化或者直接传入一个已有的数组,如下代码所示。
//1.指定底层初始化的数组大小
public ArrayList(int initialCapacity) {
this.elementData = new Object[initialCapacity];
...//省略代码
}
//2.无参数构造器,默认是空数组
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//3.指定初始已有数据
public ArrayList(Collection<? extends E> c) {
...//省略代码
elementData = Arrays.copyOf(elementData, size, Object[].class);
}
先介绍有几种初始化的方式,然后在说 add 操作。
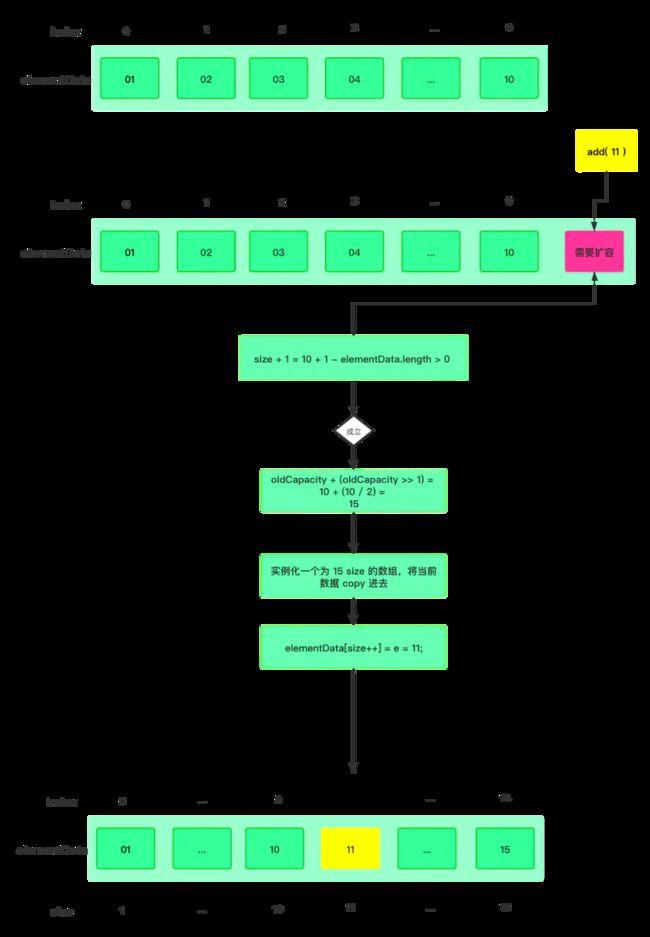
2、当第一次调用 add(E) 函数存入数据,先取得最小可以扩容的大小 minCapacity = 10
3、如果我们希望的最小容量大于目前数组的长度(默认是空数组),那么就扩容
4、第一次扩容由于 elementData 其实是一个空数组,也就是 size 为 0 的数组,所以直接将默认 DEFAULT_CAPACITY=10 赋值给当前 newCapacity 新的扩容大小。
5、最后通过 Arrays.copyOf函数,进行实例化一个默认大小为 10 的空数组。
6、如果当我们在 size = 10 的情况下,add[11],那么就会基于该公式检查 (size + 1)- size > 0 ,如果成立就会进行第二次扩容。
7、第二次扩容机制,是有一个计算公式,其实第一次也有只是可以忽略不计,因为算出来是 0 。大白话的计算公式为 当前数组大小 + (当前数组大小 / 2) = 10 + 5 也就是第二次扩容大小为 15 。
8、最后直接将需要添加的数据以 elementData[size++] = e 形式添加。
这就是一个详细的添加和扩容过程。这里也可以用一张图来进行说明(详细代码我就不贴了,主要讲解以什么思路来回答面试官),如下所示:
面试官:
嗯,添加和扩容机制了解挺细致的。
下面在说一下,ArrayList 的删除吧。
- 删除机制
删除的话,ArrayList 给我们提供了 remove(index) 和 remove(obj) 等方式,平时我在项目中用的最多的就是这 2 个 API , 下面我分别来说下它们底层实现方式吧:
remove(index):
//根据数组下标去删除
public E remove(int index) {
//比如 index = 5,size = 10
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
modCount++;
E oldValue = (E) elementData[index]; //[1,2,3,4,5,6,7,8,9,10] //删除 6
int numMoved = size - index - 1;//4
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);//直接从 [7,8,9,10] 往前移动一位
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
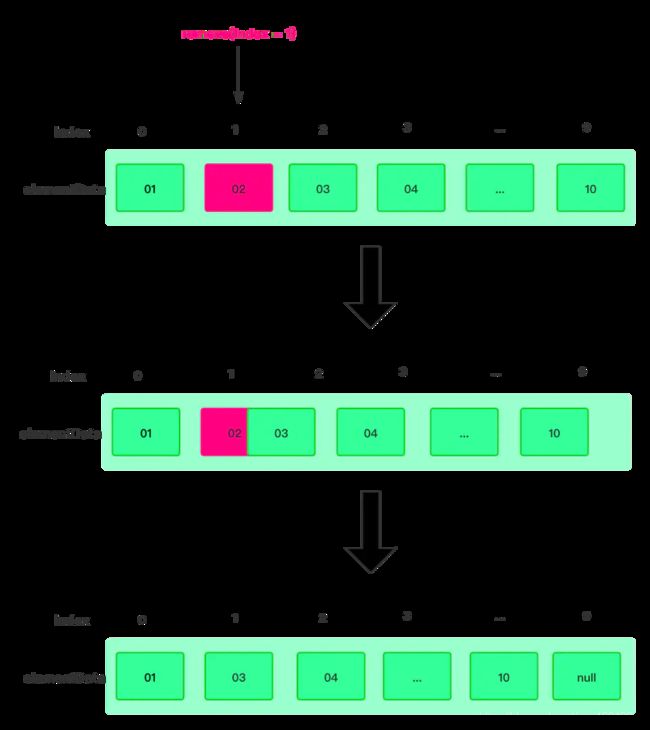
这个 API 它的意思就是根据索引来删除
1、检查索引是否越界
2、根据索引拿到删除的数据
3、将 index + 1 作为移动的起点, size - index -1 作为需要移动数组的长度
4、利用 System.arraycopy 数组,将后面的数据向前移动一位,并将最后一位置空。
5、最后返回删除的节点数据
remove(obj):
// 根据值去删除
public boolean remove(Object o) {
// 如果值是空的,找到第一个值是空的删除
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
// 值不为空,找到第一个和入参相等的删除
for (int index = 0; index < size; index++)
// 这里是根据 equals 来判断值相等的
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
这个 API 是删除 ArrayList 里面匹配到的对象
1、如果需要删除的 obj = null 那么就遍历集合将 elementData[index] == null 的节点全部删除,删除原理同 remove(index) 一样。
2、如果条件 1 不成立,那么遍历,判断 2 个对象的地址值是否指向同一块内存,如果成立,那么就删除,删除原理同 remove(index) 一样。
这里询问一下面试官,我描述的是否清晰? 面试官如果没有懂,那么我们就可以现场画一个图,如下所示:
面试官:
嗯,是的, 删除原理是这样的!
程序员:
但是在开发中,使用 ArrayList 还是有几点注意事项,比如:
1、不能使用 for 来进行删除,因为每删除一个对象 ,底层的索引对应关系就会发生改变, 导致会删除异常。解决的办法应该使用迭代器。
2、多线程并发也不能使用 ArrayList ,应该使用 CopyOnWriteArrayList 或者 Collections.synchronizedList(list) 来解决线程安全问题。
3、还有性能问题,添加多,查找少,应该选择 LinkedList 数据结构。避免频繁对数组的 copy
其实到这里,ArrayList 基本原理就介绍的差不多了,面试官也不可能每个 API 都问,一般都是问常用的。
2、有使用过 LinkedList 吗?说一下它的底层实现 ?
程序员:
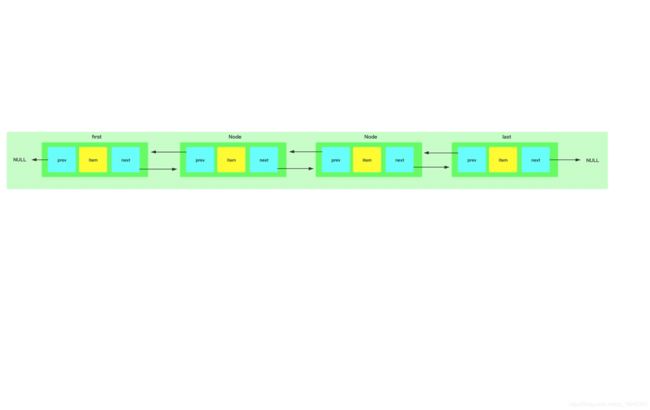
有用过,它的底层数据结构是双向链表组成, 我还是画一下它的结构图吧。如下所示:

图解:
-
链表每个节点我们叫做 Node,Node 有 prev 属性,代表前一个节点的位置,next 属性,代表后一个节点的位置;
-
first 是双向链表的头节点,它的前一个节点是 null。
-
last 是双向链表的尾节点,它的后一个节点是 null;
-
当链表中没有数据时,first 和 last 是同一个节点,前后指向都是 null;
面试官:
嗯,基本架构差不多是这样,那你说说底层的 add , get ,remove 原理吧。
程序员:
好的,那我就依次来说一下它们各自实现机制。
add:
//添加数据
public boolean add(E e) {
linkLast(e);
return true;
}
// 从尾部开始追加节点
void linkLast(E e) {
// 把尾节点数据暂存
final Node<E> l = last;
//新建新的节点,l 是前一个节点,e 是当前节点的值,后一个节点是 null
final Node<E> newNode = new Node<>(l, e, null);
//新建的节点放在尾部
last = newNode;
//如果链表为空,头部和尾部是同一个节点,都是新建的节点
if (l == null)
first = newNode;
//否则把前尾节点的下一个节点,指向当前尾节点。
else
l.next = newNode;
//大小和版本更改
size++;
modCount++;
}
添加数据我常用的是 add(E) API ,我就基于它来说吧,它是基于尾结点来添加数据的, 总得来说有如下几个步骤:
1、拿到 Last 尾结点,赋值给一个临时变量 l 。
2、生成一个新的 newNode= Node[l,item,null] 的数据类型,l 代表的就是连接上一个尾结点,item 就是存入的数据,null 代表的是 item 的尾结点指向。
3、将生成的 newNode 赋值给 last 尾结点,这一步相当于更新 last 数据。
4、最后是判断临时变量的 l 是否为空,如果为空说明链表中还没有数据,然后将 newNode 赋值给 first 头节点。反之将 newNode 赋值给 l.last 节点。
5、最后更新链表 size ,还有修改的版本 modCount
可以由一个动图来说明以上步骤的操作, 如下所示:
添加的增加过程就是这样,还是比较简单,都是操作移动节点数据。
get:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
// 根据索引查询节点
Node<E> node(int index) {
// assert isElementIndex(index);
// index 处于队列的前半部分,从头开始找
if (index < (size >> 1)) {
Node<E> x = first;
// 直到 for 循环到 index 的前一个 node
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// index 处于队列的后半部分,从尾开始找
Node<E> x = last;
// 直到 for 循环到 index 的后一个 node
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
获取数据我比较常用的是 get(index) API,我也基于它来说吧,总体来说它是分为两部分来查找数据,步骤有如下几步:
1、检查 index 是否越界。
2、根据 index > 或 < (size >> 1) 来判断在链表的上半部分还是下半部分。
3、如果是上半部分直接从 first 头节点开始遍历 index 次,然后拿到节点 item 数据。反之从下半部份 last 尾部开始向前遍历 index 次,然后拿到节点 item 数据。
总得来说获取数据的步骤就这 3 大步,因为它是链表结构没有索引对应关系,取数据只能挨个遍历。所以,如果对取数据操作频繁也可以使用 ArrayList 来弥补不足的性能。
remove:
删除数据,我常用的是 remove() 或者 remove(index) 它们的区别就是一个从头删除节点,一个是指定 index 来删除节点,我就直接说一下根据索引删除的原理吧。
1、还是检查索引是否越界。
2、搜索节点上的数据原理同 get 的第二小点一样,都是分段搜索。
3、拿到当前需要删除的 node , 然后处理当前节点上的 prev,item , next 节点指向位置,还有将当前 item 的指针全部置空,避免内存泄漏。
删除也是 3 大步骤,相较于 ArrayList 删除 API 来说,LinkedList 删除的性能是比 ArrayList 要高的。
所以,如果有 增加和删除操作比较频繁的可以选择 LinkedList 数据结构。
3、你在工作中对 ArrayList 和 LinkedList 是怎么选型的?
程序员:
如果项目中有需要快速的查找匹配,但是新增删除不频繁我一般使用的是 ArrayList 数组结构,但是如果查询比较少,新增和删除比较多我一般用的是 LinkedList 链表结构。(ps:结合它们的原理回答为什么)
4、 ArrayList 在多线程使用应该注意什么?
程序员:
在多线程使用 List 要注意线程安全问题,解决的办法通常有两种来解决。第一种也是最简单的一种直接使用 Collections.synchronizedList(list) ,但是其性能不好,因为它的实现原理相当于委托模式,交于另一个类来处理,而且内部将每个函数都加了 synchronized , 另一种实现是 java.util.concurrent##CopyOnWriteArrayList 。
面试官:
那你用过 CopyOnWriteArrayList 吗?它是怎么实现线程安全的 ?
程序员:
有用过,它的基本原理和 ArrayList 是一致的,底层也是基于数组实现。它的基本特性总结有以下几点:
1、线程安全的,多线程环境下可以直接使用,无需加锁;
2、通过锁 + 数组拷贝 + volatile 关键字保证了线程安全;
3、每次数组操作,都会把数组拷贝一份出来,在新数组上进行操作,操作成功之后再赋值回去。
线程安全我从源码的 add 、remove 的实现来说一下它们各自怎么保证线程安全的吧?
这里一定要思路清晰,最好主动找常用的 API 来说明一下内部怎么实现线程安全,不要直接给答案,一定要先分析源码,最后给出总结。
面试官:
可以,那你分别说一下吧。
程序员:
1、底层数组是如何保证数据安全的?
在分析底层数组是如何保证其安全性之前,我先简单说一下 Java 内存模型,因为数组的线程安全会涉及到 volatile 关键字。
volatile 的意思是可见的,常用来修饰某个共享变量,意思是当共享变量的值被修改后,会及时通知到其它线程上,其它线程就能知道当前共享变量的值已经被修改了。
在多核 CPU 下,为了提高效率,线程在拿值时,是直接和 CPU 缓存打交道的,而不是内存。主要是因为 CPU 缓存执行速度更快,比如线程要拿值 C,会直接从 CPU 缓存中拿, CPU 缓存中没有,就会从内存中拿,所以线程读的操作永远都是拿 CPU 缓存的值。
这时候会产生一个问题,CPU 缓存中的值和内存中的值可能并不是时刻都同步,导致线程计算的值可能不是最新的,共享变量的值有可能已经被其它线程所修改了,但此时修改是机器内存的值,CPU 缓存的值还是老的,导致计算会出现问题。
这时候有个机制,就是内存会主动通知 CPU 缓存。当前共享变量的值已经失效了,你需要重新来拉取一份,CPU 缓存就会重新从内存中拿取一份最新的值。
volatile 关键字就会触发这种机制,加了 volatile 关键字的变量,就会被识别成共享变量,内存中值被修改后,会通知到各个 CPU 缓存,使 CPU 缓存中的值也对应被修改,从而保证线程从 CPU 缓存中拿取出来的值是最新的。
还是画一个图来说明一下:
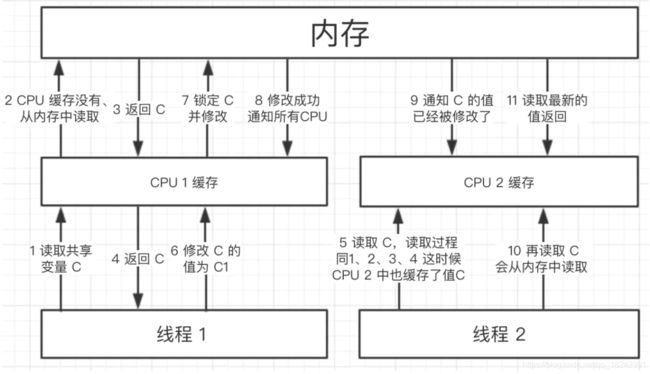
从图中我们可以看到,线程 1 和线程 2 一开始都读取了 C 值,CPU 1 和 CPU 2 缓存中也都有了 C 值,然后线程 1 把 C 值修改了,这时候内存的值和 CPU 2 缓存中的 C 值就不等了,内存这时发现 C 值被 volatile 关键字修饰,发现其是共享变量,就会使 CPU 2 缓存中的 C 值状态置为无效,CPU 2 会从内存中重新拉取最新的值,这时候线程 2 再来读取 C 值时,读取的已经是内存中最新的值了。
volatile 原理知道了,那么通过源码我们知道 object[] 就是通过 volatile 关键字来修饰的,那么也就保证了它在内存中是可见的,具有安全的。
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private static final long serialVersionUID = 8673264195747942595L;
/**
* The lock protecting all mutators. (We have a mild preference
* for builtin monitors over ReentrantLock when either will do.)
*/
final transient Object lock = new Object();
/** The array, accessed only via getArray/setArray. */
// volatile 关键字修饰,可见的
// array 只开放出 get set
private transient volatile Object[] array;
/**
* Gets the array. Non-private so as to also be accessible
* from CopyOnWriteArraySet class.
*/
final Object[] getArray() {
return array;
}
/**
* Sets the array.
*/
final void setArray(Object[] a) {
array = a;
}
/**
* Creates an empty list.
*/
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
2、操作 add(E) API 是怎么保证数据安全的?
根据之前看源码,它是有如下几个步骤保证了操作 add(E) 的安全性。
public boolean add(E e) {
//对象锁
synchronized (lock) {
// 得到所有的原数组
Object[] elements = getArray();
int len = elements.length;
//拷贝到新数组里面,新数组的长度是 + 1 的
Object[] newElements = Arrays.copyOf(elements, len + 1);
//在新数组中进行赋值,新元素直接放在数组的尾部
newElements[len] = e;
//替换原来的数组
setArray(newElements);
return true;
}
}
1、通过Synchronized对 add(E) 加锁
2、通过 getArray() 方法得到已经存在的数组
3、实例化一个长度为当前 size + 1 的数组,然后将 getArray 的数组放入新数组中
4、最后将添加的数据存入新数组的最后索引中
5、基于当前类中的 setArray(newElements); 来替换缓存中的数组数据,因为它在类中中被 volatile 修饰了,所以只要内存地址一变,那么就会立马通知,其它 CPU 的缓存让它得到更新。
所以 add(E) 方法是根据 synchronized + 数组copy + update Object[] 内存地址 + volatile 来保证其数据安全性的。
面试官:
你刚刚说 add(E) 函数中是通过 synchronized + 数组copy 等其它手段来实现的线程安全,那既然有了互斥锁保证了线程安全,为什么还要 copy 数组呢 ?
程序员:
的确,对 add(E) 进行加锁后,能够保证同一时刻,只有一个线程能对数组进行 add(E),在同单核 CPU 下的多线程环境下肯定没有问题,但我们现在的机器都是多核 CPU,如果我们不通过复制拷贝新建数组,修改原数组容器的内存地址的话,是无法触发 volatile 可见性效果的,那么其他 CPU 下的线程就无法感知数组原来已经被修改了,就会引发多核 CPU 下的线程安全问题。
假设我们不复制拷贝,而是在原来数组上直接修改值,数组的内存地址就不会变,而数组被 volatile 修饰时,必须当数组的内存地址变更时,才能及时的通知到其他线程,内存地址不变,仅仅是数组元素值发生变化时,是无法把数组元素值发生变动的事实,通知到其它线程的。
面试官:
嗯,看来你对这些机制都了解的挺清楚的,那你在说说 remove 是怎么保证的线程安全吧?
2、remove 是怎么保证线程安全的?
其实 remove 保证线程安全机制跟 add 思路都差不多,都是先加锁 +不同策略的数组拷贝最后是释放锁。
面试官:
add , remove 方法内部都实现了 copy ,在性能上你有什么优化建议吗?
程序员:
尽量使用 addAll、removeAll 方法,而不要在循环里面使用 add、remove 方法,主要是因为 for 循环里面使用 add 、remove 的方式,在每次操作时,都会进行一次数组的拷贝(甚至多次),非常耗性能,而 addAll、removeAll 方法底层做了优化,整个操作只会进行一次数组拷贝,由此可见,当批量操作的数据越多时,批量方法的高性能体现的越明显。
Map
1、说一下你对 HashMap 的了解
程序员:
HashMap 底层是数组 + 单链表 + 红黑树 组成的存储数据结构,简单来说当链表长度大于等于 8 并且数组长度大于 64 那么就会由链表转为红黑树,当红黑树的大小容量 <= 6 时又转换为 链表的一个底层结构。非线程安全的。
可以用一张图来解释 HashMap 底层结构,如下所示:
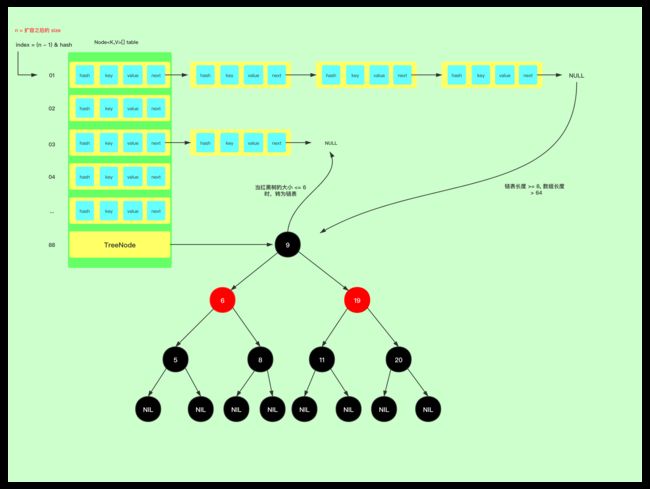
图解:
1、最左边 table 是 HashMap 的数组结构,允许 Node 的 value 值为 NULL
2、数组的扩容机制第一次默认扩容大小为 16 size, 扩容阀值为 threshold = size * loadFactor -> 12 = 16 * 0.75 ,只要 ++size > threshold 就按照 newCap = oldCap << 1 机制来扩容。
3、数组的下标有可能是一个链表、红黑树,也有可能只是一个 Node,只有当数组长度 > 64,链表长度 >= 8 才会将数组中的 Node 节点转为 TreeNode 节点。也只有当红黑树的大小 <= 6 时,才转为单链表结构。
程序员:
HashMap 底层的基本实现实现基本就是这样。
面试官:
嗯,那你描述一下 put(K key, V value) 这个 API 的存储过程 。
程序员:
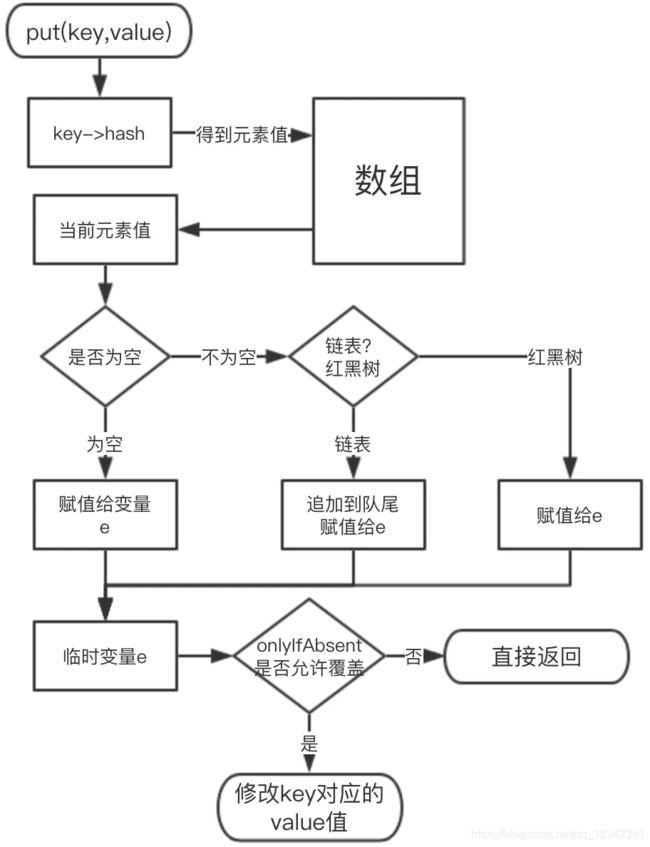
好的,我先描述一下基本流程,最后我画一张流程图来总结一下
1、根据 key 通过该公式 (h = key.hashCode()) ^ (h >>> 16) 计算 hash 值
2、判断 HashMap table 数组是否已经初始化,如果没有初始化,那么就按照默认 16 的大小进行初始化,扩容阀值也将按照 size * 0.75 来定义
3、通过该公式 (n - 1) & hash 拿到存入 table 的 index 索引,判断当前索引下是否有值,如果没有值就进行直接赋值 tab[index] , 如果有值,那么就会发生 hash 碰撞 ,也就是俗称 hash冲突 , 在 JDK中的解决是的办法有 2 个,其一是链表,其二是 红黑树。
4、当发送 hash 冲突 首先判断数组中已存入的 key 是否与当前存入的 key 相同,并且内存地址也一样,那么就直接默认直接覆盖 values
5、如果 key 不相等,那么先拿到 tab[index] 中的 Node是否是红黑树,如果是红黑树,那么就加入红黑树的节点;如果 Node 节点不是红黑树,那么就直接放入 node 的 next 下,形成单链表结构。
6、如果链表结构的长度 >= 8 就转为红黑树的结构。
7、最后检查扩容机制。
整个 put 流程就是这样,可以用一个流程图来进行总结,如下所示:
面试官:
嗯,理解的很透彻,刚刚你说解决 hash 冲突有 2 种办法,那你描述一下红黑树是怎么实现新增的?
程序员:
好的,基本流程有如下几步:
1、首先判断新增的节点在红黑树上是不是已经存在,判断手段有如下两种:
1.1、如果节点没有实现 Comparable 接口,使用 equals 进行判断;
1.2、如果节点自己实现了 Comparable 接口,使用 compareTo 进行判断。
2、新增的节点如果已经在红黑树上,直接返回;不在的话,判断新增节点是在当前节点的左边还是右边,左边值小,右边值大;
3、自旋递归 1 和 2 步,直到当前节点的左边或者右边的节点为空时,停止自旋,当前节点即为我们新增节点的父节点;
4、把新增节点放到当前节点的左边或右边为空的地方,并于当前节点建立父子节点关系;
5、进行着色和旋转,结束。
面试官:
你知道链表转红黑树定义的长度为什么是 8 吗?
程序员:
这个答案,我通过 HashMap 类中的注释有留意过,它大概描述的意思是链表查询的时间复杂度是 O (n),红黑树的查询复杂度是 O (log (n))。在链表数据不多的时候,使用链表进行遍历也比较快,只有当链表数据比较多的时候,才会转化成红黑树,但红黑树需要的占用空间是链表的 2 倍,考虑到转化时间和空间损耗,所以我们需要定义出转化的边界值。
在考虑设计 8 这个值的时候,我们参考了泊松分布概率函数,由泊松分布中得出结论,链表各个长度的命中概率为:
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
意思是,当链表的长度是 8 的时候,出现的概率是 0.00000006,不到千万分之一,所以说正常情况下,链表的长度不可能到达 8 ,而一旦到达 8 时,肯定是 hash 算法出了问题,所以在这种情况下,为了让 HashMap 仍然有较高的查询性能,所以让链表转化成红黑树,我们正常写代码,使用 HashMap 时,几乎不会碰到链表转化成红黑树的情况,毕竟概念只有千万分之一。
面试官:
嗯,还挺细心的。留意到了源码中的注释。
这里可能会让面试官感觉是非常注重源码中的细节问题,会去思考,为什么?
开始你介绍到 HashMap 在多线程操作下是不安全了,那么你在工作中是怎么解决的?
程序员:
可以自己在外部加锁,或者通过 Collections#synchronizedMap 来实现线程安全,Collections#synchronizedMap 的实现是在每个方法上加上了 synchronized 锁;也可以使用 concurrent 包下的 ConcurrentHashMap 类。它的原理我们将在 ConcurrentHashMap 说明
面试官:
嗯,那你在说说数组为什么每次都是以 2的幂次方扩容?
程序员:
好的。如下是我的理解。
HashMap 为了存取高效,要尽量减少碰撞,就是要尽量把数据分配均匀。
比如:
2 的 n 次方实际就是 1 后面 n 个 0,2 的 n 次方 -1,实际就是 n 个 1。
那么长度为 8 时候,3 & (8-1) = 3 ,2 & (8-1) = 2 ,不同位置上,不碰撞。
而长度为 5 的时候,3 & (5-1)= 0 , 2 & (5-1) = 0,都在 0 上,出现碰撞了。
//3 & 4
011
100
000
//2 & 4
010
100
000
所以,保证容积是 2 的 n 次方,是为了保证在做 (size-1) 的时候,每一位都能 & 1 ,也就是和 1111……1111111进行与运算。
面试官:
在考你一道扩容机制的题目,现在后台的图片数据有 1000 条, 当我请求下来也处理完了,现在我想要缓存到 Map 中,如果我直接调用 new HashMap(1000) 构造方法,内部还会扩容吗?
程序员:
你可以这样回答,其实如果直接给定 1000 的初始化容量,那么我们需要根据源码中的计算来分析,有如下几个步骤:
1、首先会在构造函数中调用 1024 = tableSizeFor(1000); 该 API 来计算扩容阀值。
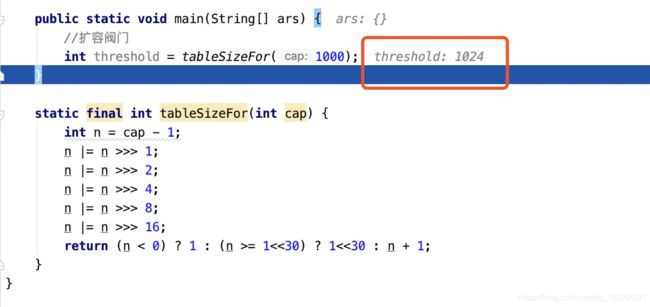
你可不要认为,这里就是真正的扩容大小,它在扩容的时候还会有一个计算公式。
2、计算真正的扩容阀值。
那么根据第一次 put 数据的时候,判断 table 是否为空,如果为空那么就需要扩容。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; //第一次进来为 null 那么就是 0 长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold; //这里其实就是 1024
int newCap, newThr = 0;
if (oldCap > 0) {
...
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr; // newCap = 1024
else {
// zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;//1024 * 0.75 = 768.0
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//更新扩容的阀值
threshold = newThr;
//实例化一个数组
@SuppressWarnings({
"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//正在扩容 newTab 的大小
table = newTab;
...
return newTab;
}
可以看到其实真正的扩容阀门是 768。
3、判断扩容机制
if (++size > threshold)//769 > 768 需要扩容
resize();
所以当我们给定 1000 为初始化扩容容量的时候,是需要扩容的。因为底层并不会真正以 1024 来进行设置阀门,它还要乘以一个加载因子。这个时候其实我们可以有办法不让它扩容,那就是调用 new HashMap(1000,1f) 那么就不会扩容了。
这里你不仅给出了实际答案,还提供了解决办法。
面试官对你的回答肯定是满意的。
2、说一下你对 ArrayMap 的了解
程序员:
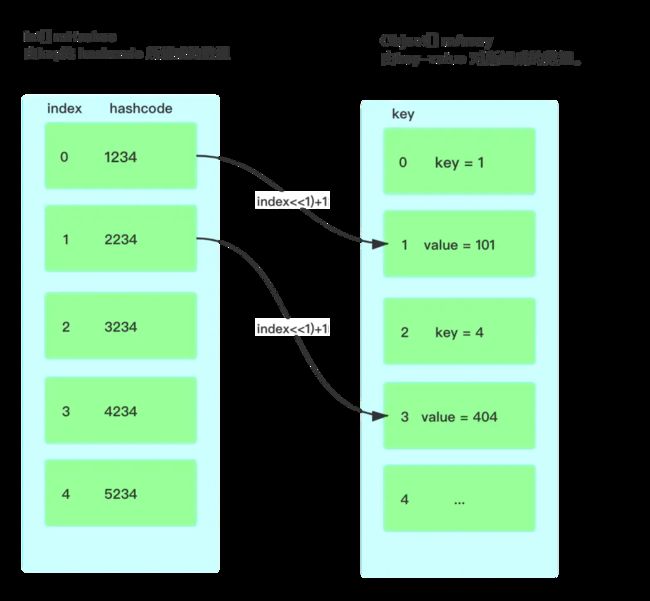
ArrayMap 底层通过两个数组来建立映射关系,其中 int[] mHashes 按大小顺序保存 Key 对象 hashCode 值,Object[] mArray 按 mHashes 的顺序用相邻位置保存 Key 对象和 Value 对象。mArray 长度 是 mHashes 长度的 2 倍。
存储数据是根据 key 的 hashcode() 方法得到 hash 值,计算出在 mArrays 的 index 值,然后利用二分查找找到对应的位置进行插入,当出现哈希冲突时,会在 index 的相邻位置插入。
取数据是根据 key 的 hashcode() 方法得到 hash 值,然后通过 hash 值根据二分查找拿到 mHashes 的 index 索引,最后在根据 index + 1 索引拿到 mArrays 对应的 values 值。
3、你在工作中对 HashMap 和 ArrayMap 还有 SparseArray 是怎么选型的 ?
程序员:
好的,我总结了一套性能对比,每次需求我都是参考如下的总结。
| 序号 | 需求 | 性能选择 |
|---|---|---|
| 01 | 有 1K 数据需要装入容器 | key 是 int 选择 SparseArray 节省 30% 内存,反之选择 ArrayMap 节省 10% |
| 02 | 有 1W 数据需要装入容器 | HashMap |
4、有用过 LinkedHashMap 吗 ?底层怎么维护插入顺序的,又是怎么维护删除最少访问元素的 ?
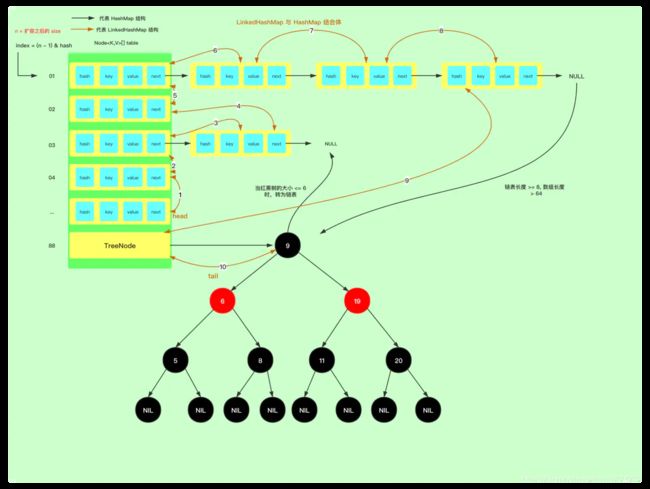
ps: 由于内部存储机制都是散开的,如果按照散开的来连接,那图上连接线估计很乱,所以为了上图能够稍微好点一点,我就按照我自己的思路来绘制的,当然,内部结构还是不会变的。
程序员:
有用过,之前看 LruCache 底层也是基于 LinkedHashMap 实现的。那我还是按照我的思路来回答吧。
通过翻阅源码得知它是继承于 HashMap ,那么间接的它也拥有了 HashMap 的所有特性,而且在此基础上,还提供了两大特性,一个是增加了插入顺序和实现了最近最少访问的删除策略。
先来看下是怎么实现顺序插入:
LinkedHashMap 外部结构是一个双向链表结构,内部是一个 HashMap 结构,它就是相当于 HashMap + LinkedHashMap 的结合体。
其实 LinkedHashMap 的源码实现很简单,它就是重写了 HashMap##put 方法执行中调用的 newNode/newTreeNode 方法。然后在该函数内部中实现了链表的双向连接。如下所示:
//新增节点到链表的尾部
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMapEntry<K,V> p =
new LinkedHashMapEntry<K,V>(hash, key, value, e);
//节点追加到链表的尾部
linkNodeLast(p);
return p;
}
//重写新增红黑树节点
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p);
return p;
}
//链接到当前链表中
private void linkNodeLast(LinkedHashMapEntry<K,V> p) {
LinkedHashMapEntry<K,V> last = tail;
tail = p;
//last为空,说明链表位空,首尾节点相等
if (last == null)
head = p;
//链表有数据,直接建立本节点和上个尾节点之间的前后关系即可
else {
p.before = last; //将上一个尾节点赋值给当前尾节点的前节点
last.after = p; //将上一个尾节点的后节点指向当前尾节点
}
}
总结来说,LinkedHashMap 把新增的节点都使用双向链表连接起来,从而实现了插入顺序。然后核心的数据结构还是交于 HashMap 来处理维护的。
在来看下是怎么实现的访问最少删除功能:
其实访问最少删除功能的这种策略也叫做 LRU 算法,底层原理就是把经常使用的元素会被追加到当前链表的尾结点,而不经常使用的就自然都靠在链表的头节点,然后我们就可以设置删除策略,比如给当前 Map 设置一个策略大小,那么当存入的数据大于设置的大小时,就会从头节点开始删除。
在源码当中,将经常使用的 节点数据追加到链表的操作是在 get API 中,如下所示:
public V get(Object key) {
Node<K,V> e;
// 调用 HashMap getNode 方法
if ((e = getNode(hash(key), key)) == null)
return null;
// 如果设置了 LRU 策略
if (accessOrder)
// 这个方式把当前 key 移动到尾节点
afterNodeAccess(e);
return e.value;
}
当存入数据的时候 LinkedHashMap 重写的 HashMap#putVal 方法中的 afterNodeInsertion API 。
//HashMap
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
....//删除其余代码
// 删除不经常使用的元素
afterNodeInsertion(evict);
}
//LinkedHashMap
// 删除不经常使用的元素
void afterNodeInsertion(boolean evict) {
// possibly remove eldest
// 得到元素头节点
LinkedHashMapEntry<K,V> first;
// removeEldestEntry 来控制删除策略,removeEldestEntry 外部控制是否删除
if (evict && (first = head) != null && removeEldestEntry(first)) {
//拿到头节点的 key,删除头,因为最近使用的在 get 的时候都会移动到尾结点
K key = first.key;
// removeNode 删除节点
removeNode(hash(key), key, null, false, true);
}
}
总结来说,LinkedHashMap 的操作都是基于 HashMap 暴露的 API , 实现了顺序存储和最近最少删除策略。
说了这些原理之后,一般来说面试官不会再问其它的。因为核心功能我们都已经回答完了。
5、你知道 TreeMap 的内部是怎么排序的吗 ?
程序员:
嗯,知道。这个 API 我使用的比较少,之前只是看过它的源码,知道它的底层还是红黑树结构,跟 HashMap 的红黑树是一样的。然后 TreeMap 是利用了红黑树左大右小的性质,根据 key 来进行排序的。
面试官:
嗯,那你具体来说一下底层是怎么根据 key 排序的?
程序员:
在程序中,如果我们想给一个 List 排序的话,其一是实现 Comparable##compareTo 接口抽象方法,其二是利用外部排序器 Comparator 进行排序, 而 TreeMap 利用的也是此原理,从而实现了对 key 的排序。
我就直接说一下 put(K key, V value) API 怎么实现的排序吧。
1、判断红黑树的节点是否为空,为空的话,新增的节点直接作为根节点,代码如下:
Entry<K,V> t = root;
//红黑树根节点为空,直接新建
if (t == null) {
// compare 方法限制了 key 不能为 null
compare(key, key); // type (and possibly null) check
// 成为根节点
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
2、根据红黑树左小右大的特性,进行判断,找到应该新增节点的父节点,代码如下:
Comparator<? super K> cpr = comparator;
if (cpr != null) {
//自旋找到 key 应该新增的位置,就是应该挂载那个节点的头上
do {
//一次循环结束时,parent 就是上次比过的对象
parent = t;
// 通过 compare 来比较 key 的大小
cmp = cpr.compare(key, t.key);
//key 小于 t,把 t 左边的值赋予 t,因为红黑树左边的值比较小,循环再比
if (cmp < 0)
t = t.left;
//key 大于 t,把 t 右边的值赋予 t,因为红黑树右边的值比较大,循环再比
else if (cmp > 0)
t = t.right;
//如果相等的话,直接覆盖原值
else
return t.setValue(value);
// t 为空,说明已经到叶子节点了
} while (t != null);
}
3、在父节点的左边或右边插入新增节点,代码如下:
//cmp 代表最后一次对比的大小,小于 0 ,代表 e 在上一节点的左边
if (cmp < 0)
parent.left = e;
//cmp 代表最后一次对比的大小,大于 0 ,代表 e 在上一节点的右边,相等的情况第二步已经处理了。
else
parent.right = e;
4、着色旋转,达到平衡,结束。
可以看到 TreeMap 排序是根据如果外部有传进来 Comparator 比较器,那么就用 Comparator 来进行对 key 比较,如果外部没有就用 Key 自己实现 Comparable 的 compareTo 方法。
6、ConcurrentHashMap 通过哪些手段保证了线程安全?
程序员:
它的主要结构跟 HashMap 一样底层都是基于数组 + 单链表 + 红黑树构成。
保证线程安全主要有一下几点:
1、储存 Map 数据的数组被 volatile 关键字修饰,一旦被修改,立马就能通知其他线程,因为是数组,所以需要改变其内存值,才能真正的发挥出 volatile 的可见特性;
//第一次插入时才会初始化,java7是在构造器时就初始化了
//容量大小都是2的幂次方,通过iterators进行迭代
transient volatile Node<K,V>[] table;
//扩容后的数组
private transient volatile Node<K,V>[] nextTable;
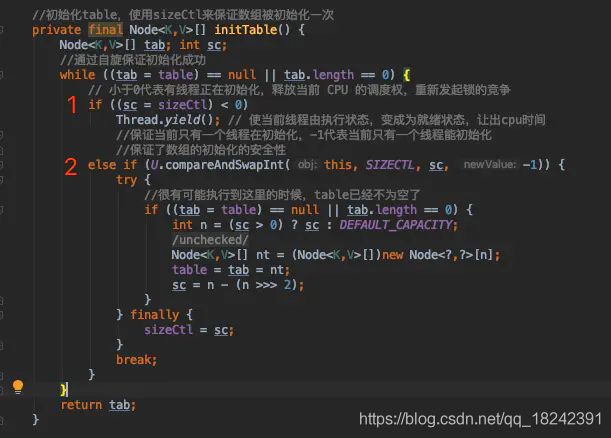
2、put 时,如果数组还未初始化,那么使用 Thread##yield 和 sun.misc.Unsafe##compareAndSwapInt 保证了只有一个线程初始化数组。
3、put 时,如果计算出来的数组下标索引没有值的话,采用无限 for 循环 + CAS 算法,来保证一定可以新增成功,又不会覆盖其他线程 put 进去的值;
//如果当前索引位置没有值,直接创建
if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//cas 在 i 位置创建新的元素,当i位置是空时,创建成功结束for自循,否则继续自旋
if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break;
}
/** * CAS
* @param tab 要修改的对象
* * @param i 对象中的偏移量
* * @param c 期望值
* * @param v 更新值
* * @return true | false
*/
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
4、如果 put 的节点正好在扩容,会等待扩容完成之后,再进行 put ,保证了在扩容时,老数组的值不会发生变化;
//如果当前的hash是转发节点的hash,表示该槽点正在扩容,就会一直等待扩容完成
if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
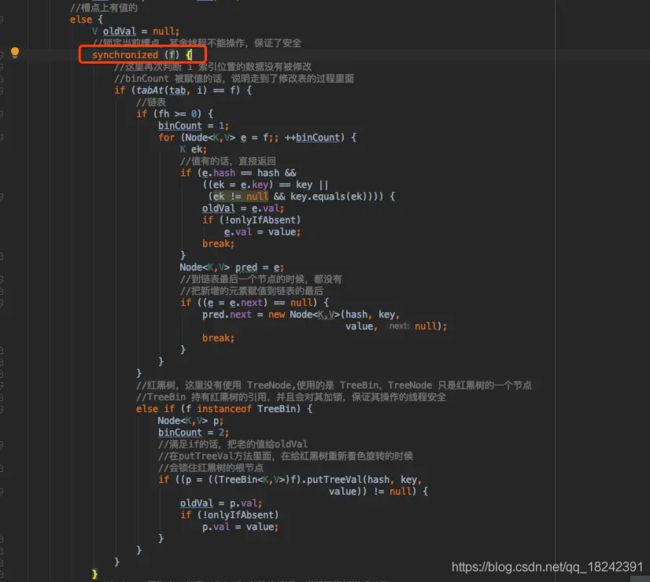
5、对数组的槽点进行操作时,会先锁住槽点,保证只有当前线程才能对槽点上的链表或红黑树进行操作;
6、红黑树旋转时,会锁住根节点,保证旋转时的线程安全。
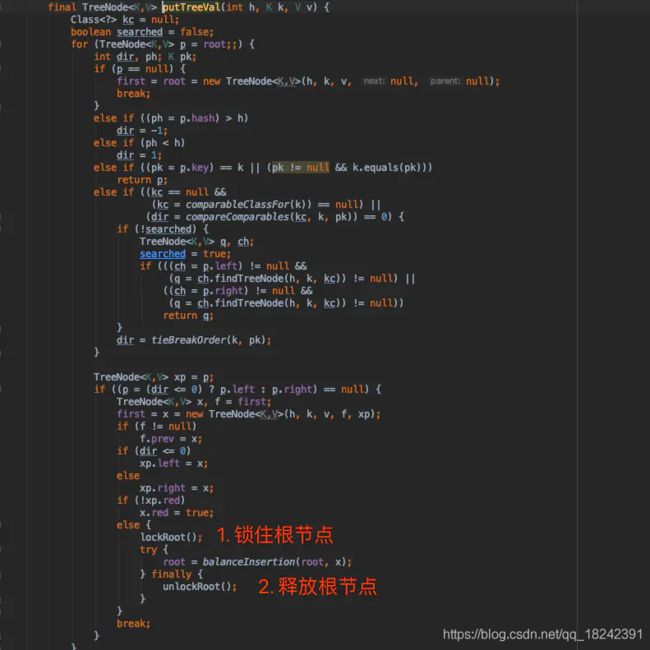
面试官:
刚刚看你说了到了 CAS 算法,那你描述一下 CAS 算法在 ConcurrentHashMap 中的应用?
程序员:
CAS 其实是一种乐观锁,一般有三个值,分别为:赋值对象,原值,新值,在执行的时候,会先判断内存中的值是否和原值相等,相等的话把新值赋值给对象,否则赋值失败,整个过程都是原子性操作,没有线程安全问题。
ConcurrentHashMap 的 put 方法中,有使用到 CAS ,是结合无限 for 循环一起使用的,步骤如下:
1.计算出数组索引下标,拿出下标对应的原值;
2.CAS 覆盖当前下标的值,赋值时,如果发现内存值和 1 拿出来的原值相等,执行赋值,退出循环,否则不赋值,转到 3;
3. 进行下一次 for 循环,重复执行 1,2,直到成功为止。
4.
可以看到这样做的好处,第一是不会盲目的覆盖原值,第二是一定可以赋值成功。
面试官:
嗯,还不错,那你再说下与 HashMap 的相同点和不同点
程序员:
相同点:
1、都实现了 Map 接口,继承了 AbstractMap 抽象类,所以两者的方法大多都是相似的,可以互相切换。
2、底层都是基于 数组 + 单链表 + 红黑树实现。
不同点:
1、ConcurrentHashMap 是线程安全的,在多线程环境下,无需加锁,可直接使用;
2、数据结构上,ConcurrentHashMap 多了转移节点,主要用于保证扩容时的线程安全。
Queue
1、说一说你对队列的理解,队列和集合的区别 ?
程序员:
好的,那我先说一下对队列的理解,然后在说下区别;
对队列的理解:
1、首先队列本身也是个容器,底层也会有不同的数据结构,比如 LinkedBlockingQueue 是底层是链表结构,所以可以维持先入先出的顺序,比如 DelayQueue 底层可以是队列或堆栈,所以可以保证先入先出,或者先入后出的顺序等等,底层的数据结构不同,也造成了操作实现不同;
2、部分队列(比如 LinkedBlockingQueue )提供了暂时存储的功能,我们可以往队列里面放数据,同时也可以从队列里面拿数据,两者可以同时进行;
3、队列把生产数据的一方和消费数据的一方进行解耦,生产者只管生产,消费者只管消费,两者之间没有必然联系,队列就像生产者和消费者之间的数据通道一样,如 LinkedBlockingQueue;
4、队列还可以对消费者和生产者进行管理,比如队列满了,有生产者还在不停投递数据时,队列可以使生产者阻塞住,让其不再能投递,比如队列空时,有消费者过来拿数据时,队列可以让消费者 hodler 住,等有数据时,唤醒消费者,让消费者拿数据返回,如 ArrayBlockingQueue;
5、队列还提供阻塞的功能,比如我们从队列拿数据,但队列中没有数据时,线程会一直阻塞到队列有数据可拿时才返回。
区别:
1、和集合的相同点,队列(部分例外)和集合都提供了数据存储的功能,底层的储存数据结构是有些相似的,比如说 LinkedBlockingQueue 和 LinkedHashMap 底层都使用的是链表,ArrayBlockingQueue 和 ArrayList 底层使用的都是数组。
2、和集合的区别:
1.部分队列和部分集合底层的存储结构很相似的,但两者为了完成不同的事情,提供的 API 和其底层的操作实现是不同的。
2.队列提供了阻塞的功能,能对消费者和生产者进行简单的管理,队列空时,会阻塞消费者,有其他线程进行 put 操作后,会唤醒阻塞的消费者,让消费者拿数据进行消费,队列满时亦然。
3.解耦了生产者和消费者,队列就像是生产者和消费者之间的管道一样,生产者只管往里面丢,消费者只管不断消费,两者之间互不关心。
2、有用过 LinkedBlockingQueue 队列吗? 说一下 LinkedBlockingQueue 底层怎么实现数据存取。
程序员:
有用过。LinkedBlockingQueue 整体是一个具有阻塞的链表结构,具有生产者和消费者的作用。阻塞底层的实现是基于 AQS 实现的。
阻塞存数据:
队列存数据有多种函数实现,比如 add , put , offer,这些函数的功能都是存数据,但是内部实现确都不一样。这里我就介绍 put 吧,因为它是我比较常用的。
大概意思就是当存入的数据已经达到内部最大容量,那么就会陷入线程阻塞,只有等 take 函数唤醒的时机才会执行后面的代码。如果队列未满,就直接入队列,把当前新增的元素放入尾端。最后在通知消费者也就是 take 函数可以取数据了。
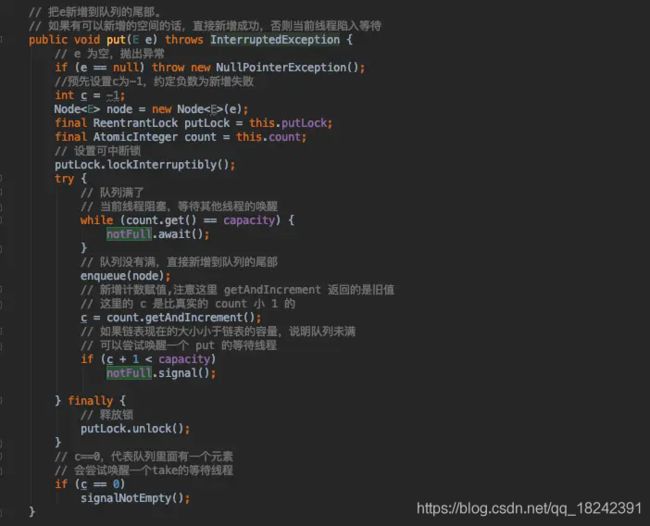
阻塞取数据:
阻塞取数据其实同阻塞存数据同理。取数据的原理是先判断当前队列大小是否为空,如果为空就陷入无限等待,唤醒的时机是存完数据会通知。如果队列中有数据那么从队列的头部获取(遵循先入先出)。
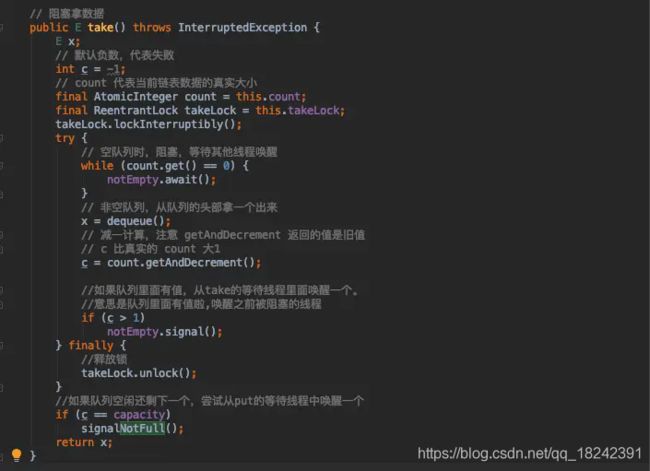
内部实现还是比较简单,难点在于存取 API 的娴熟使用。应用场景也比较多,比如线程池就是基于阻塞队列的原理。
3、有用过 ArrayBlockingQueue 队列吗? 说一下 ArrayBlockingQueue 底层怎么实现数据存取? 支持自动扩容吗 ?
程序员:
有用过,底层是基于数组实现的存储结构。实例化 ArrayBlockingQueue 必须设置一个固定的队列大小,内部不支持扩容。
面试官:
嗯,那你说说底层实现新增数据的原理吧?
程序员:
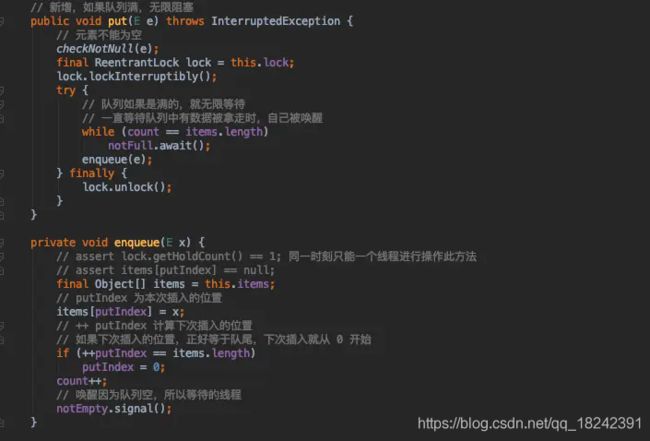
存入数据的时候先利用 ReentrantLock 给该函数上锁,然后判断当前队列的容量是否满了,如果满了就无限等待,直到有数据在唤醒;如果还未满,那么就入队列。入队列这里有如下几步我就直接画一个流程图吧,这样好说明一些:
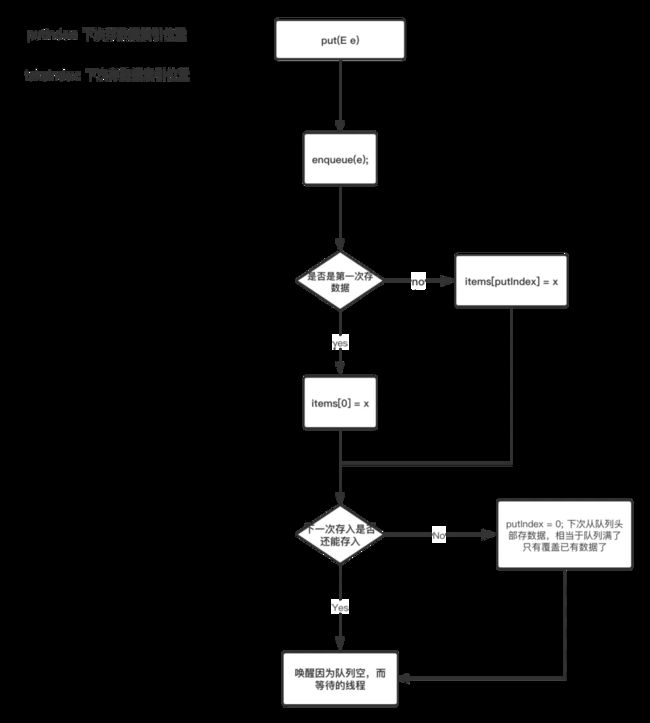
根据流程图,我们知道,先根据 putIndex 来存入数据,然后计算下一次 putIndex 的值跟队列大小比较,如果相等说明下一次就只能从队列头部存入了。
面试官:
那你在说在如何从队列中获取数据吧?
程序员:
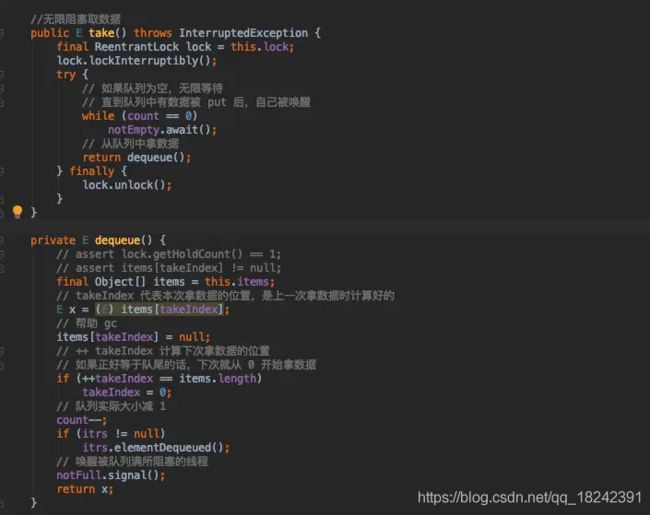
其实 take 跟 put 是有相关联的,内部机制也都差不多。基本上都是先上锁,然后判断队列中是否有数据,如果没有就无限等待;如果有数据就存入队列,存入队列我这里还是画一个流程图吧。
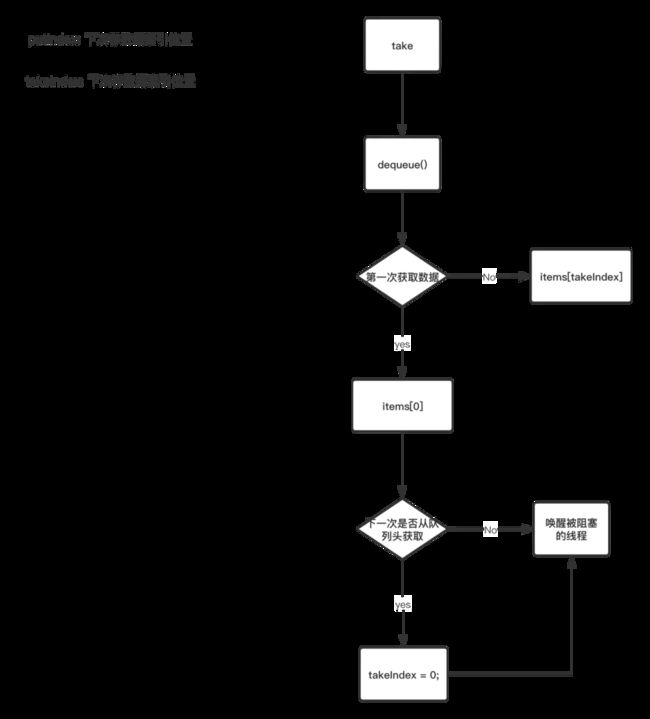
根据流程图,我们知道,先根据 takeIndex 来拿到数据,然后计算下一次 takeIndex 的值跟队列大小比较,如果相等说明下一次就只能从队列头部拿数据了。
4、说一下有哪些队列具有阻塞功能? 大概是如何阻塞的 ?
程序员:
1、LinkedBlockingQueue 链表阻塞队列和 ArrayBlockingQueue 数组阻塞队列是一类,前者容量是 Integer 的最大值,后者数组大小固定,两个阻塞队列都可以指定容量大小,当队列满时,如果有线程 put 数据,线程会阻塞住,直到有其他线程进行消费数据后,才会唤醒阻塞线程继续 put,当队列空时,如果有线程 take 数据,线程会阻塞到队列不空时,继续 take。
2、SynchronousQueue 同步队列,当线程 put 时,必须有对应线程把数据消费掉,put 线程才能返回,当线程 take 时,需要有对应线程进行 put 数据时,take 才能返回,反之则阻塞,举个例子,线程 A put 数据 A1 到队列中了,此时并没有任何的消费者,线程 A 就无法返回,会阻塞住,直到有线程消费掉数据 A1 时,线程 A 才能返回。
面试官:
具体说一下底层阻塞原理?
程序员:
其实这些具有阻塞的功能,最终都会在 Java 层调用 LockSupport##park/unpark 函数,这里我就以我常用的 LinkedBlockingQueue 队列来说下具体实现阻塞原理:
最后实现是 native 函数,如下所示:
public native void unpark(Object var1);
public native void park(boolean var1, long var2);
接着我们直接看 c++ 实现:
C++ 源码实现比较多,感兴趣的可以看这篇文章 LockSupport原理分析
5、说一下 LinkedBlockingQueue 和 ArrayBlockingQueue 有什么区别?
程序员:
相同点:
1、两者的阻塞机制大体相同,比如在队列满、空时,线程都会阻塞住。
不同点:
1、LinkedBlockingQueue 底层是链表结构,容量默认是 Interge 的最大值,ArrayBlockingQueue 底层是数组,容量必须在初始化时指定。
2、两者的底层结构不同,所以 take、put、remove 的底层实现也就不同。
6、队列的存取 API 都有什么区别?比如 put take 和 offer poll
程序员:
这里我就用一个下面的表格来总结一下:
| 功能 | 无限阻塞 | 抛异常 | 有时间限制阻塞 | 特殊值 |
|---|---|---|---|---|
| 新增 - 队列满 | put | add | offer 过超时时间 return false | offer return false |
| 查看并删除 - 队列空 | take | remove | offer 过超时时间 return false | offer return null |
| 只查看不删除 - 队列空 | 无 | element | 无 | Peek return null |

参考
1.HashMap面试必问的6个点,你知道几个?
2.面试官系统精讲Java源码及大厂真题
3.深度解读ArrayMap优势与缺陷
4.Java中的队列都有哪些,有什么区别?