2019独角兽企业重金招聘Python工程师标准>>> 
opencsv
java读取csv的类库主要有两种,opencsv和javacsv,研究发现,javacsv最后一次更新是2014-12-10,很久不维护了。opencsv是apache的项目,并且至今仍在维护,所以决定使用opencsv。
csv
csv文件,全名 comma separated values,默认以逗号分隔,是纯文本文件。虽然用excel打开后格式排版了,但是那是excel对他进行了处理。用notepad或者sublime text打开能看到最原始的文本。
为了后续举例,这里编辑了一个test.csv
header1,header2,header3
1,a,10
2,b,20
3,c,30
4,d,40
5,e,50
6,f,60读取方式
- 最原始的方式,逐行读取,然后操作
CSVReader reader = new CSVReader(new InputStreamReader(new FileInputStream("test.csv"),"gbk"));
/*
* 逐行读取
*/
String[] strArr = null;
while((strArr = reader.readNext())!=null){
System.out.println(strArr[0]+"---"+strArr[1]+"----"+strArr[2]);
}
reader.close();绑定csv文件转换成bean
逐行读取操作是最原始的操作方式,opencsv提供了基于“策略”的映射,将csv绑定到bean。
策略简介
观察一下策略的继承层次 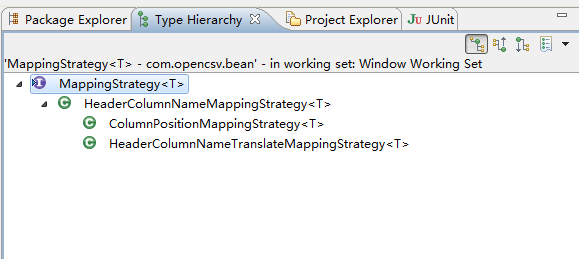
接口
- MappingStrategy
- 映射的顶层接口
- HeaderColumnNameMappingStrategy
- 列名映射策略,读取csv文件第一行作为header,比如header1,header2,header3,然后调用bean的setHeader1方法,setHeader2方法,setHeader3方法分别设置值,所以这种策略要求,列名与bean中的属性名完全一致,如果不一致,则值为空,不会出错。使用注解时,注解名字必须与csv中列名一致。
- ColumnPositionMappingStrategy
- 列位置映射策略,他没有header的概念,所以会输出取所有行。在columnMapping数组中指定bean的属性,第一个值对应csv的第一列,第二个值对应csv的第二类……
- HeaderColumnNameTranslateMappingStrategy
- 列头名字翻译映射策略,与HeaderColumnNameMappintStrategy相比,bean的属性名可以与csv列头不一样。通过指定map来映射。
具体映射用法
Java POJO类
public class SimpleBeanInfo {
private String header1;
private String header2;
private String header3;
public String getHeader1() {
return header1;
}
@Override
public String toString() {
return "SimpleBeanInfo [header1=" + header1 + ", header2=" + header2
+ ", header3=" + header3 + "]";
}
public void setHeader1(String header1) {
this.header1 = header1;
}
public String getHeader2() {
return header2;
}
public void setHeader2(String header2) {
this.header2 = header2;
}
public String getHeader3() {
return header3;
}
public void setHeader3(String header3) {
this.header3 = header3;
}
基于列索引的映射
-
通俗点来说就是列位置映射,csv文件中的列位置对应到bean中的列
-
非注解方式
CSVReader reader = new CSVReader(new InputStreamReader(new FileInputStream("test.csv"),"gbk"));
/*
*基于列位置,映射成类
*/
//csv文件中的第一列对应类的header,第二列对应类的header2,第三列对应类的header3
String[] columnMapping={"header1","header2","header3"};
ColumnPositionMappingStrategy mapper = new ColumnPositionMappingStrategy();
mapper.setColumnMapping(columnMapping);
mapper.setType(SimpleBeanInfo.class);
/* */
CsvToBean csvToBean = new CsvToBean();
List list = csvToBean.parse(mapper, reader);
for(SimpleBeanInfo e : list){
System.out.println(e);
}
} - 注解方式
public class SimpleBeanInfo {
@CsvBindByPosition(position=0)
private String header1;
@CsvBindByPosition(position=1)
private String header2;
@CsvBindByPosition(position=2)
private String header3;
}CSVReader reader = new CSVReader(new InputStreamReader(new FileInputStream("test.csv"),"gbk"));
ColumnPositionMappingStrategy mapper = new ColumnPositionMappingStrategy();
mapper.setType(SimpleBeanInfo.class);
CsvToBean csvToBean = new CsvToBean();
List list = csvToBean.parse(mapper, reader);
for(SimpleBeanInfo e : list){
System.out.println(e);
} 基于列名的映射
- 非注解方式
CSVReader reader = new CSVReader(new InputStreamReader(new FileInputStream("test.csv"),"gbk"));
/* */
HeaderColumnNameMappingStrategy mapper = new
HeaderColumnNameMappingStrategy();
mapper.setType(SimpleBeanInfo.class);
CsvToBean csvToBean = new CsvToBean();
List list = csvToBean.parse(mapper, reader);
for(SimpleBeanInfo e : list){
System.out.println(e);
} - 注解方式
public class SimpleBeanInfo {
@CsvBindByName(column="header1")
private String header1;
@CsvBindByName(column="header2")
private String header2;
@CsvBindByName(column="header3")
private String header3;
}CSVReader reader = new CSVReader(new InputStreamReader(new FileInputStream("test.csv"),"gbk"));
HeaderColumnNameMappingStrategy mapper = new
HeaderColumnNameMappingStrategy();
mapper.setType(SimpleBeanInfo.class);
CsvToBean csvToBean = new CsvToBean();
List list = csvToBean.parse(mapper, reader);
for(SimpleBeanInfo e : list){
System.out.println(e);
} 基于列名转换映射
CSVReader reader = new CSVReader(new InputStreamReader(new FileInputStream("test.csv"),"gbk"));
/*
* 基于列名转换,映射成类
*/
HeaderColumnNameTranslateMappingStrategy mapper =
new HeaderColumnNameTranslateMappingStrategy();
mapper.setType(SimpleBeanInfo.class);
Map columnMapping = new HashMap();
columnMapping.put("header1", "header1");//csv中的header1对应bean的header1
columnMapping.put("header2", "header2");
columnMapping.put("header3", "header3");
mapper.setColumnMapping(columnMapping);
CsvToBean csvToBean = new CsvToBean();
List list = csvToBean.parse(mapper, reader);
for(SimpleBeanInfo e : list){
System.out.println(e);
} 过滤器
opencsv提供了过滤器,可以过滤某些行,比如page header、page footer等
- 所有的过滤器必须实现CsvToBeanFilter 接口
public class MyCsvToBeanFilter implements CsvToBeanFilter {
public boolean allowLine(String[] line) {
//过滤第一列值等于1的行
if("1".equals(line[0])){
return false;
}
return true;
}
} MyCsvToBeanFilter filter = new MyCsvToBeanFilter();
List list = csvToBean.parse(mapper, reader,filter); 转化器
类中的属性不一定都是字符串,比如数字、日期等,但是我们从csv中获取到的都是字符串,这种情况就应该使用转化器。
这里定义一个SimpleBeanConverter,继承AbstractBeanField
public class SimpleBeanFieldConverter extends AbstractBeanField {
@Override
protected Object convert(String value) throws CsvDataTypeMismatchException,
CsvRequiredFieldEmptyException, CsvConstraintViolationException {
Field f = getField();
if("date".equals(f.getName())){
try {
return new SimpleDateFormat("yyyy-MM-dd").parse(value);
} catch (ParseException e) {
e.printStackTrace();
}
}
return null;
}
} test.csv添加一列header4
header1,header2,header3,header4
1,a,10,2016-05-01
2,b,20,2016-05-02
3,c,30,2016-05-03
4,d,40,2016-05-04
5,e,50,2016-05-05
6,f,60,2016-05-06SimpleBeanInfo添加属性
@CsvCustomBindByPosition(position=3,converter=SimpleBeanFieldConverter.class)
private Date date;输出结果
由于ColumnPositionMappingStrategy会连header行也解析,所以第一行会打印异常信息。我们看到header4列已经转换为日期。如果不只一个列需要转换怎么办?在相应的属性上添加注解(@CsvCustomBindByPosition或@CsvCustomBindByName),然后在convert(Object value)中扩展即可
java.text.ParseException: Unparseable date: "header4"
at java.text.DateFormat.parse(DateFormat.java:357)
at test_maven.SimpleBeanFieldConverter.convert(SimpleBeanFieldConverter.java:24)
at com.opencsv.bean.AbstractBeanField.setFieldValue(AbstractBeanField.java:70)
at com.opencsv.bean.CsvToBean.processField(CsvToBean.java:245)
at com.opencsv.bean.CsvToBean.processLine(CsvToBean.java:220)
at com.opencsv.bean.CsvToBean.processLine(CsvToBean.java:189)
at com.opencsv.bean.CsvToBean.parse(CsvToBean.java:166)
at com.opencsv.bean.CsvToBean.parse(CsvToBean.java:133)
at test_maven.TestCSV.main(TestCSV.java:46)
SimpleBeanInfo [header1=header1, header2=header2, header3=header3, date=null]
SimpleBeanInfo [header1=2, header2=b, header3=20, date=Mon May 02 00:00:00 CST 2016]
SimpleBeanInfo [header1=3, header2=c, header3=30, date=Tue May 03 00:00:00 CST 2016]
SimpleBeanInfo [header1=4, header2=d, header3=40, date=Wed May 04 00:00:00 CST 2016]
SimpleBeanInfo [header1=5, header2=e, header3=50, date=Thu May 05 00:00:00 CST 2016]
SimpleBeanInfo [header1=6, header2=f, header3=60, date=Fri May 06 00:00:00 CST 2016]