DataCamp课程:Intermediate Python
1. Matplotlib
Line plot
print() the last item from both the year and the pop list to see what the predicted population for the year 2100 is. Use two print() functions.
print(year[-1])
print(pop[-1])
2100
10.85
Before you can start, you should import matplotlib.pyplot as plt. pyplot is a sub-package of matplotlib, hence the dot.
Use plt.plot() to build a line plot. year should be mapped on the horizontal axis, pop on the vertical axis. Don’t forget to finish off with the show() function to actually display the plot.
from matplotlib import pyplot as plt
plt.plot(year, pop)
plt.show()
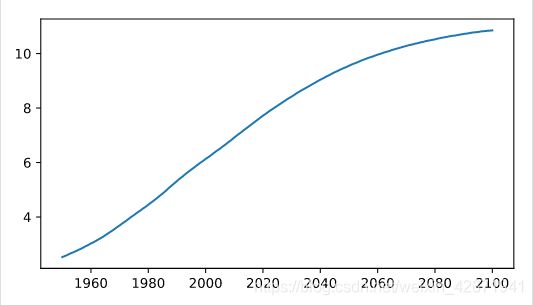
Have another look at the plot you created in the previous exercise; it’s shown on the right. Based on the plot, in approximately what year will there be more than ten billion human beings on this planet?
- 2040
- 2060
- 2085
- 2095
Print the last item from both the list gdp_cap, and the list life_exp; it is information about Zimbabwe.
print(gdp_cap[-1])
print(life_exp[-1])
469.70929810000007
43.487
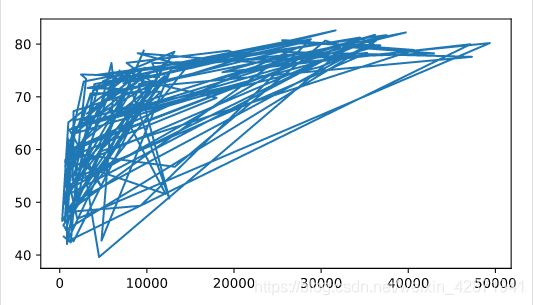
Build a line chart, with gdp_cap on the x-axis, and life_exp on the y-axis. Does it make sense to plot this data on a line plot?
Don’t forget to finish off with a plt.show() command, to actually display the plot.
plt.plot(gdp_cap, life_exp)
plt.show()
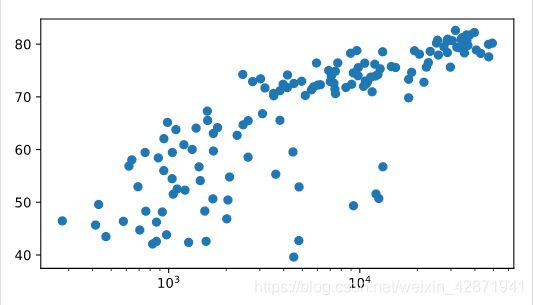
Scatter Plot
Change the line plot that’s coded in the script to a scatter plot.
A correlation will become clear when you display the GDP per capita on a logarithmic scale. Add the line plt.xscale(‘log’).
Finish off your script with plt.show() to display the plot.
plt.scatter(gdp_cap, life_exp)
plt.xscale('log')
plt.show()
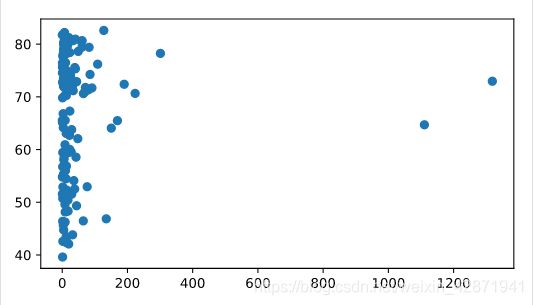
Start from scratch: import matplotlib.pyplot as plt.
Build a scatter plot, where pop is mapped on the horizontal axis, and life_exp is mapped on the vertical axis.
Finish the script with plt.show() to actually display the plot. Do you see a correlation?
import matplotlib.pyplot as plt
plt.scatter(pop, life_exp)
plt.show()
Build a histogram
Use plt.hist() to create a histogram of the values in life_exp. Do not specify the number of bins; Python will set the number of bins to 10 by default for you.
Add plt.show() to actually display the histogram. Can you tell which bin contains the most observations?
plt.hist(life_exp)
plt.show()
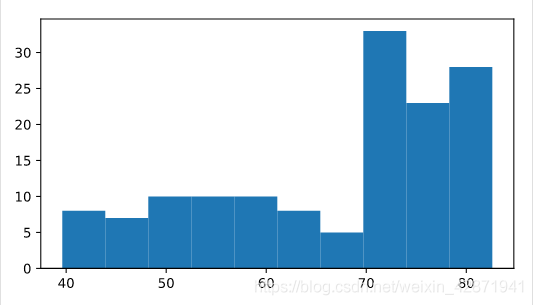
Build a histogram of life_exp, with 5 bins. Can you tell which bin contains the most observations?
Build another histogram of life_exp, this time with 20 bins. Is this better?
plt.hist(life_exp, 5)
plt.show()
plt.clf()
# Build histogram with 20 bins
plt.hist(life_exp, 20)
plt.show()
plt.clf()
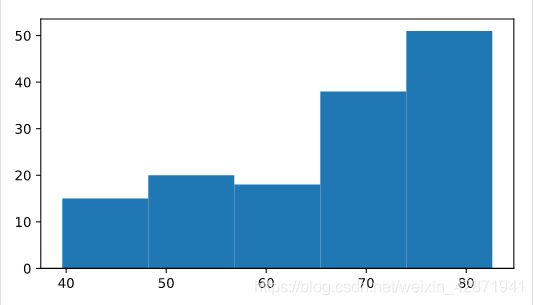
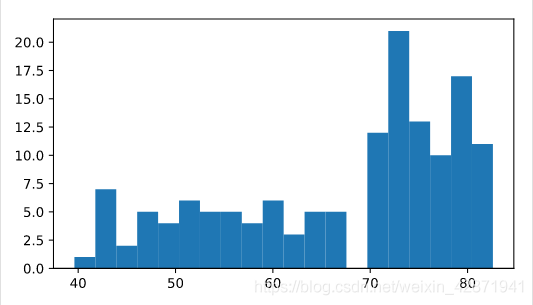
Build a histogram of life_exp with 15 bins.
Build a histogram of life_exp1950, also with 15 bins. Is there a big difference with the histogram for the 2007 data?
plt.hist(life_exp, 15)
plt.show()
plt.clf()
# Histogram of life_exp1950, 15 bins
plt.hist(life_exp1950, 15)
plt.show()
plt.clf()
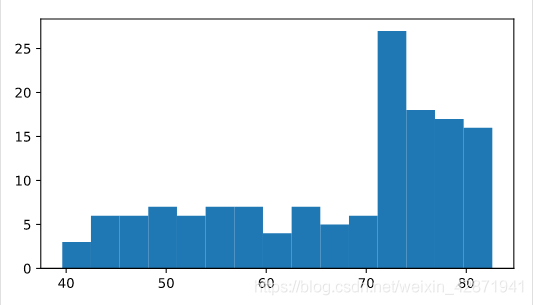

Choose the right plot
You’re a professor teaching Data Science with Python, and you want to visually assess if the grades on your exam follow a particular distribution. Which plot do you use?
- Line plot
- Scatter plot
- Histogram
You’re a professor in Data Analytics with Python, and you want to visually assess if longer answers on exam questions lead to higher grades. Which plot do you use?
- Line plot
- Scatter plot
- Histogram
Labels
The strings xlab and ylab are already set for you. Use these variables to set the label of the x- and y-axis.
The string title is also coded for you. Use it to add a title to the plot.
After these customizations, finish the script with plt.show() to actually display the plot.
plt.scatter(gdp_cap, life_exp)
plt.xscale('log')
xlab = 'GDP per Capita [in USD]'
ylab = 'Life Expectancy [in years]'
title = 'World Development in 2007'
plt.xlabel(xlab)
plt.ylabel(ylab)
plt.title(title)
plt.show()
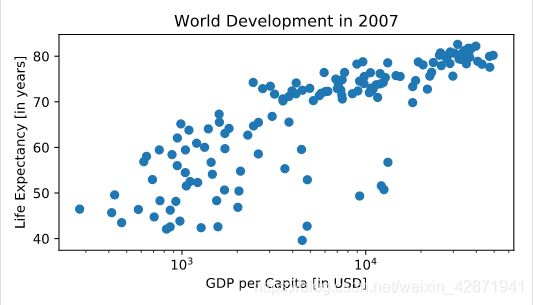
Ticks
Use tick_val and tick_lab as inputs to the xticks() function to make the the plot more readable.
As usual, display the plot with plt.show() after you’ve added the customizations.
plt.scatter(gdp_cap, life_exp)
plt.xscale('log')
plt.xlabel('GDP per Capita [in USD]')
plt.ylabel('Life Expectancy [in years]')
plt.title('World Development in 2007')
tick_val = [1000, 10000, 100000]
tick_lab = ['1k', '10k', '100k']
plt.xticks(tick_val, tick_lab)
plt.show()
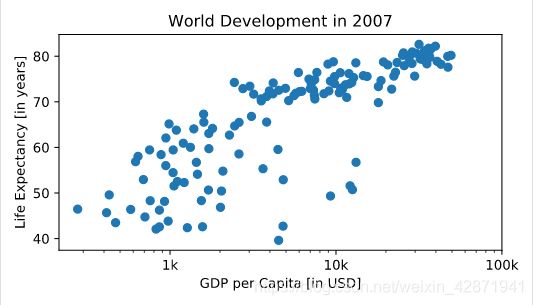
Sizes
Run the script to see how the plot changes.
plt.scatter(gdp_cap, life_exp, s = pop)
plt.xscale('log')
plt.xlabel('GDP per Capita [in USD]')
plt.ylabel('Life Expectancy [in years]')
plt.title('World Development in 2007')
plt.xticks([1000, 10000, 100000],['1k', '10k', '100k'])
plt.show()
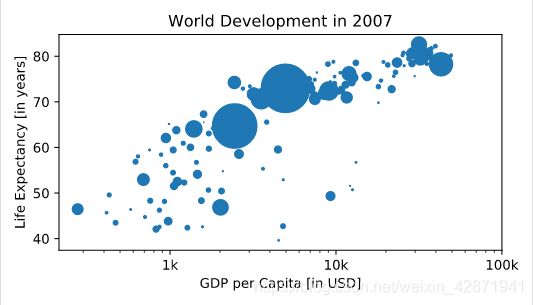
Looks good, but increasing the size of the bubbles will make things stand out more.
- Import the numpy package as np.
- Use np.array() to create a numpy array from the list pop. Call this Numpy array np_pop.
- Double the values in np_pop setting the value of np_pop equal to np_pop * 2. Because np_pop is a Numpy array, each array element will be doubled.
- Change the s argument inside plt.scatter() to be np_pop instead of pop.
import numpy as np
# Store pop as a numpy array: np_pop
np_pop = np.array(pop)
# Double np_pop
np_pop = np_pop * 2
plt.scatter(gdp_cap, life_exp, s = np_pop)
plt.xscale('log')
plt.xlabel('GDP per Capita [in USD]')
plt.ylabel('Life Expectancy [in years]')
plt.title('World Development in 2007')
plt.xticks([1000, 10000, 100000],['1k', '10k', '100k'])
plt.show()
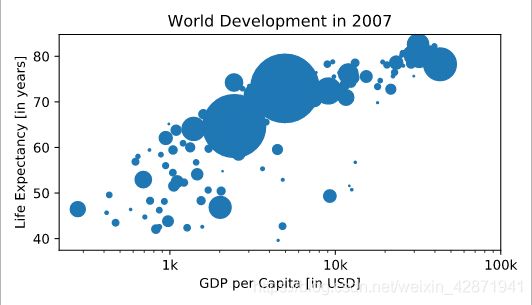
Colors
Add c = col to the arguments of the plt.scatter() function.
Change the opacity of the bubbles by setting the alpha argument to 0.8 inside plt.scatter(). Alpha can be set from zero to one, where zero is totally transparent, and one is not at all transparent.
plt.scatter(x = gdp_cap, y = life_exp, s = np.array(pop) * 2, c = col, alpha = 0.8)
plt.xscale('log')
plt.xlabel('GDP per Capita [in USD]')
plt.ylabel('Life Expectancy [in years]')
plt.title('World Development in 2007')
plt.xticks([1000,10000,100000], ['1k','10k','100k'])
plt.show()
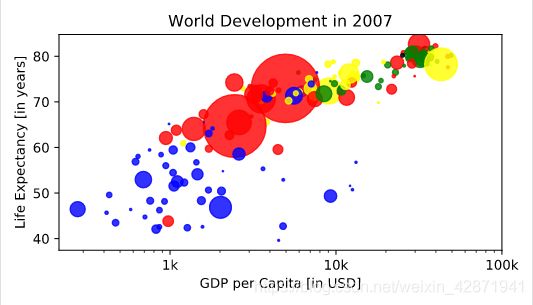
Additional Customizations
Add plt.grid(True) after the plt.text() calls so that gridlines are drawn on the plot.
plt.scatter(x = gdp_cap, y = life_exp, s = np.array(pop) * 2, c = col, alpha = 0.8)
plt.xscale('log')
plt.xlabel('GDP per Capita [in USD]')
plt.ylabel('Life Expectancy [in years]')
plt.title('World Development in 2007')
plt.xticks([1000,10000,100000], ['1k','10k','100k'])
plt.text(1550, 71, 'India')
plt.text(5700, 80, 'China')
plt.grid(True)
plt.show()
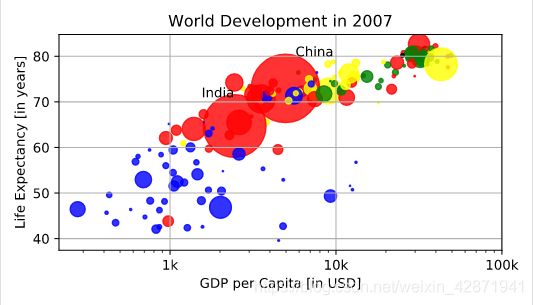
What can you say about the plot?
- The countries in blue, corresponding to Africa, have both low life expectancy and a low GDP per capita.
- There is a negative correlation between GDP per capita and life expectancy.
- China has both a lower GDP per capita and lower life expectancy compared to India.
2. Dictionaries & Pandas
Motivation for dictionaries
Use the index() method on countries to find the index of ‘germany’. Store this index as ind_ger.
Use ind_ger to access the capital of Germany from the capitals list. Print it out.
countries = ['spain', 'france', 'germany', 'norway']
capitals = ['madrid', 'paris', 'berlin', 'oslo']
ind_ger = countries.index('germany')
print(capitals[ind_ger])
<script.py> output:
berlin
Create dictionary
With the strings in countries and capitals, create a dictionary called europe with 4 key:value pairs. Beware of capitalization! Make sure you use lowercase characters everywhere.
Print out europe to see if the result is what you expected.
countries = ['spain', 'france', 'germany', 'norway']
capitals = ['madrid', 'paris', 'berlin', 'oslo']
europe = {
'spain':'madrid', 'france':'paris', 'germany':'berlin', 'norway':'oslo' }
print(europe)
<script.py> output:
{
'spain': 'madrid', 'norway': 'oslo', 'france': 'paris', 'germany': 'berlin'}
Access dictionary
Check out which keys are in europe by calling the keys() method on europe. Print out the result.
Print out the value that belongs to the key ‘norway’.
europe = {
'spain':'madrid', 'france':'paris', 'germany':'berlin', 'norway':'oslo' }
print(europe.keys())
print(europe['norway'])
<script.py> output:
dict_keys(['spain', 'norway', 'france', 'germany'])
oslo
Dictionary Manipulation
Add the key ‘italy’ with the value ‘rome’ to europe.
To assert that ‘italy’ is now a key in europe, print out ‘italy’ in europe.
Add another key:value pair to europe: ‘poland’ is the key, ‘warsaw’ is the corresponding value.
Print out europe.
europe = {
'spain':'madrid', 'france':'paris', 'germany':'berlin', 'norway':'oslo' }
europe['italy'] = 'rome'
print('italy' in europe)
europe['poland'] = 'warsaw'
print(europe)
<script.py> output:
True
{
'spain': 'madrid', 'norway': 'oslo', 'poland': 'warsaw', 'italy': 'rome', 'france': 'paris', 'germany': 'berlin'}
The capital of Germany is not ‘bonn’; it’s ‘berlin’. Update its value.
Australia is not in Europe, Austria is! Remove the key ‘australia’ from europe.
Print out europe to see if your cleaning work paid off.
europe = {
'spain':'madrid', 'france':'paris', 'germany':'bonn',
'norway':'oslo', 'italy':'rome', 'poland':'warsaw',
'australia':'vienna' }
europe['germany'] = 'berlin'
del europe['australia']
print(europe)
<script.py> output:
{
'poland': 'warsaw', 'italy': 'rome', 'germany': 'berlin', 'france': 'paris', 'norway': 'oslo', 'spain': 'madrid'}
Dictionariception
Use chained square brackets to select and print out the capital of France.
Create a dictionary, named data, with the keys ‘capital’ and ‘population’. Set them to ‘rome’ and 59.83, respectively.
Add a new key-value pair to europe; the key is ‘italy’ and the value is data, the dictionary you just built.
europe = {
'spain': {
'capital':'madrid', 'population':46.77 },
'france': {
'capital':'paris', 'population':66.03 },
'germany': {
'capital':'berlin', 'population':80.62 },
'norway': {
'capital':'oslo', 'population':5.084 } }
print(europe['france'])
# Create sub-dictionary data
data = {
'capital':'rome', 'population':59.83}
europe['italy'] = data
print(europe)
<script.py> output:
{
'population': 66.03, 'capital': 'paris'}
{
'france': {
'population': 66.03, 'capital': 'paris'}, 'norway': {
'population': 5.084, 'capital': 'oslo'}, 'italy': {
'population': 59.83, 'capital': 'rome'}, 'germany': {
'population': 80.62, 'capital': 'berlin'}, 'spain': {
'population': 46.77, 'capital': 'madrid'}}
Dictionary to DataFrame
Import pandas as pd.
Use the pre-defined lists to create a dictionary called my_dict. There should be three key value pairs:
- key ‘country’ and value names.
- key ‘drives_right’ and value dr.
- key ‘cars_per_cap’ and value cpc.
Use pd.DataFrame() to turn your dict into a DataFrame called cars.
Print out cars and see how beautiful it is.
names = ['United States', 'Australia', 'Japan', 'India', 'Russia', 'Morocco', 'Egypt']
dr = [True, False, False, False, True, True, True]
cpc = [809, 731, 588, 18, 200, 70, 45]
import pandas as pd
my_dict = {
'country':names, 'drives_right':dr, 'cars_per_cap':cpc}
cars = pd.DataFrame(my_dict)
print(cars)
<script.py> output:
cars_per_cap country drives_right
0 809 United States True
1 731 Australia False
2 588 Japan False
3 18 India False
4 200 Russia True
5 70 Morocco True
6 45 Egypt True
Hit Run Code to see that, indeed, the row labels are not correctly set.
Specify the row labels by setting cars.index equal to row_labels.
Print out cars again and check if the row labels are correct this time.
import pandas as pd
names = ['United States', 'Australia', 'Japan', 'India', 'Russia', 'Morocco', 'Egypt']
dr = [True, False, False, False, True, True, True]
cpc = [809, 731, 588, 18, 200, 70, 45]
cars_dict = {
'country':names, 'drives_right':dr, 'cars_per_cap':cpc }
cars = pd.DataFrame(cars_dict)
print(cars)
row_labels = ['US', 'AUS', 'JPN', 'IN', 'RU', 'MOR', 'EG']
# Specify row labels of cars
cars.index = row_labels
print(cars)
<script.py> output:
cars_per_cap country drives_right
0 809 United States True
1 731 Australia False
2 588 Japan False
3 18 India False
4 200 Russia True
5 70 Morocco True
6 45 Egypt True
cars_per_cap country drives_right
US 809 United States True
AUS 731 Australia False
JPN 588 Japan False
IN 18 India False
RU 200 Russia True
MOR 70 Morocco True
EG 45 Egypt True
CSV to DataFrame
To import CSV files you still need the pandas package: import it as pd.
Use pd.read_csv() to import cars.csv data as a DataFrame. Store this dataframe as cars.
Print out cars. Does everything look OK?
import pandas as pd
cars = pd.read_csv('cars.csv')
print(cars)
<script.py> output:
Unnamed: 0 cars_per_cap country drives_right
0 US 809 United States True
1 AUS 731 Australia False
2 JPN 588 Japan False
3 IN 18 India False
4 RU 200 Russia True
5 MOR 70 Morocco True
6 EG 45 Egypt True
Run the code with Submit Answer and assert that the first column should actually be used as row labels.
Specify the index_col argument inside pd.read_csv(): set it to 0, so that the first column is used as row labels.
Has the printout of cars improved now?
import pandas as pd
# Fix import by including index_col
cars = pd.read_csv('cars.csv', index_col=0)
print(cars)
<script.py> output:
cars_per_cap country drives_right
US 809 United States True
AUS 731 Australia False
JPN 588 Japan False
IN 18 India False
RU 200 Russia True
MOR 70 Morocco True
EG 45 Egypt True
Square Brackets
Use single square brackets to print out the country column of cars as a Pandas Series.
Use double square brackets to print out the country column of cars as a Pandas DataFrame.
Use double square brackets to print out a DataFrame with both the country and drives_right columns of cars, in this order.
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
# Print out country column as Pandas Series
print(cars['country'])
# Print out country column as Pandas DataFrame
print(cars[['country']])
# Print out DataFrame with country and drives_right columns
print(cars[['country', 'drives_right']])
<script.py> output:
US United States
AUS Australia
JPN Japan
IN India
RU Russia
MOR Morocco
EG Egypt
Name: country, dtype: object
country
US United States
AUS Australia
JPN Japan
IN India
RU Russia
MOR Morocco
EG Egypt
country drives_right
US United States True
AUS Australia False
JPN Japan False
IN India False
RU Russia True
MOR Morocco True
EG Egypt True
Select the first 3 observations from cars and print them out.
Select the fourth, fifth and sixth observation, corresponding to row indexes 3, 4 and 5, and print them out.
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
print(cars[0:3])
print(cars[3:6])
<script.py> output:
cars_per_cap country drives_right
US 809 United States True
AUS 731 Australia False
JPN 588 Japan False
cars_per_cap country drives_right
IN 18 India False
RU 200 Russia True
MOR 70 Morocco True
loc and iloc
Use loc or iloc to select the observation corresponding to Japan as a Series. The label of this row is JPN, the index is 2. Make sure to print the resulting Series.
Use loc or iloc to select the observations for Australia and Egypt as a DataFrame. You can find out about the labels/indexes of these rows by inspecting cars in the IPython Shell. Make sure to print the resulting DataFrame.
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
# Print out observation for Japan
print(cars.loc[['JPN']])
print(cars.iloc[2])
# Print out observations for Australia and Egypt
print(cars.loc[['AUS', 'EG']])
<script.py> output:
cars_per_cap country drives_right
JPN 588 Japan False
cars_per_cap 588
country Japan
drives_right False
Name: JPN, dtype: object
cars_per_cap country drives_right
AUS 731 Australia False
EG 45 Egypt True
Print out the drives_right value of the row corresponding to Morocco (its row label is MOR)
Print out a sub-DataFrame, containing the observations for Russia and Morocco and the columns country and drives_right.
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
# Print out drives_right value of Morocco
print(cars.loc['MOR', 'drives_right'])
# Print sub-DataFrame
print(cars.loc[['RU', 'MOR'], ['country', 'drives_right']])
<script.py> output:
True
country drives_right
RU Russia True
MOR Morocco True
Print out the drives_right column as a Series using loc or iloc.
Print out the drives_right column as a DataFrame using loc or iloc.
Print out both the cars_per_cap and drives_right column as a DataFrame using loc or iloc.
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
# Print out drives_right column as Series
print(cars.loc[:, 'drives_right'])
# Print out drives_right column as DataFrame
print(cars.loc[:, ['drives_right']])
# Print out cars_per_cap and drives_right as DataFrame
print(cars.loc[:, ['cars_per_cap', 'drives_right']])
<script.py> output:
US True
AUS False
JPN False
IN False
RU True
MOR True
EG True
Name: drives_right, dtype: bool
drives_right
US True
AUS False
JPN False
IN False
RU True
MOR True
EG True
cars_per_cap drives_right
US 809 True
AUS 731 False
JPN 588 False
IN 18 False
RU 200 True
MOR 70 True
EG 45 True
3. Logic, Control Flow and Filtering
Equality
In the editor on the right, write code to see if True equals False.
print(True == False)
<script.py> output:
False
Write Python code to check if -5 * 15 is not equal to 75.
print(-5 * 15 != 75)
<script.py> output:
True
Ask Python whether the strings “pyscript” and “PyScript” are equal.
print("pyscript" == "PyScript")
<script.py> output:
False
What happens if you compare booleans and integers? Write code to see if True and 1 are equal.
print(True == 1)
<script.py> output:
True
Greater and less than
Write Python expressions, wrapped in a print() function, to check whether:
- x is greater than or equal to -10. x has already been defined for you.
x = -3 * 6
print(x >= -10)
<script.py> output:
False
- “test” is less than or equal to y. y has already been defined for you.
y = "test"
print("test" <= y)
<script.py> output:
True
- True is greater than False.
print(True > False)
<script.py> output:
True
Compare arrays
Using comparison operators, generate boolean arrays that answer the following questions:
- Which areas in my_house are greater than or equal to 18?
- You can also compare two Numpy arrays element-wise. Which areas in my_house are smaller than the ones in your_house?
- Make sure to wrap both commands in a print() statement so that you can inspect the output!
import numpy as np
my_house = np.array([18.0, 20.0, 10.75, 9.50])
your_house = np.array([14.0, 24.0, 14.25, 9.0])
print(my_house >= 18)
print(my_house < your_house)
<script.py> output:
[ True True False False]
[False True True False]
and, or, not
Write Python expressions, wrapped in a print() function, to check whether:
- my_kitchen is bigger than 10 and smaller than 18.
- my_kitchen is smaller than 14 or bigger than 17.
- double the area of my_kitchen is smaller than triple the area of your_kitchen.
my_kitchen = 18.0
your_kitchen = 14.0
print(my_kitchen > 10 and my_kitchen < 18)
print(my_kitchen < 14 or my_kitchen > 17)
print(my_kitchen * 2 < your_kitchen * 3)
<script.py> output:
False
True
True
x = 8
y = 9
not(not(x < 3) and not(y > 14 or y > 10))
What will the result be if you execute these three commands in the IPython Shell?
- True
- False
- Running these commands will result in an error.
Boolean operators with Numpy
Generate boolean arrays that answer the following questions:
Which areas in my_house are greater than 18.5 or smaller than 10?
Which areas are smaller than 11 in both my_house and your_house? Make sure to wrap both commands in print() statement, so that you can inspect the output.
import numpy as np
my_house = np.array([18.0, 20.0, 10.75, 9.50])
your_house = np.array([14.0, 24.0, 14.25, 9.0])
print(np.logical_or(my_house > 18.5, my_house < 10))
print(np.logical_and(my_house < 11, your_house < 11))
<script.py> output:
[False True False True]
[False False False True]
Warmup
To experiment with if and else a bit, have a look at this code sample:
area = 10.0
if(area < 9) :
print("small")
elif(area < 12) :
print("medium")
else :
print("large")
What will the output be if you run this piece of code in the IPython Shell?
- small
- medium
- large
- The syntax is incorrect; this code will produce an error.
if
Examine the if statement that prints out “Looking around in the kitchen.” if room equals “kit”.
Write another if statement that prints out “big place!” if area is greater than 15.
room = "kit"
area = 14.0
if room == "kit" :
print("looking around in the kitchen.")
if area > 15:
print("big place!")
<script.py> output:
looking around in the kitchen.
Add else
Add an else statement to the second control structure so that “pretty small.” is printed out if area > 15 evaluates to False.
room = "kit"
area = 14.0
if room == "kit" :
print("looking around in the kitchen.")
else :
print("looking around elsewhere.")
if area > 15 :
print("big place!")
else:
print("pretty small.")
<script.py> output:
looking around in the kitchen.
pretty small.
Customize further: elif
Add an elif to the second control structure such that “medium size, nice!” is printed out if area is greater than 10.
room = "bed"
area = 14.0
# if-elif-else construct for room
if room == "kit" :
print("looking around in the kitchen.")
elif room == "bed":
print("looking around in the bedroom.")
else :
print("looking around elsewhere.")
# if-elif-else construct for area
if area > 15 :
print("big place!")
elif area > 10:
print("medium size, nice!")
else :
print("pretty small.")
<script.py> output:
looking around in the bedroom.
medium size, nice!
Driving right
Extract the drives_right column as a Pandas Series and store it as dr.
Use dr, a boolean Series, to subset the cars DataFrame. Store the resulting selection in sel.
Print sel, and assert that drives_right is True for all observations.
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
dr = cars['drives_right']
sel = cars.loc[dr]
print(sel)
<script.py> output:
cars_per_cap country drives_right
US 809 United States True
RU 200 Russia True
MOR 70 Morocco True
EG 45 Egypt True
Convert the code on the right to a one-liner that calculates the variable sel as before.
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
sel = cars[cars['drives_right']]
print(sel)
<script.py> output:
cars_per_cap country drives_right
US 809 United States True
RU 200 Russia True
MOR 70 Morocco True
EG 45 Egypt True
Cars per capita
Select the cars_per_cap column from cars as a Pandas Series and store it as cpc.
Use cpc in combination with a comparison operator and 500. You want to end up with a boolean Series that’s True if the corresponding country has a cars_per_cap of more than 500 and False otherwise. Store this boolean Series as many_cars.
Use many_cars to subset cars, similar to what you did before. Store the result as car_maniac.
Print out car_maniac to see if you got it right.
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
cpc = cars['cars_per_cap']
many_cars = cpc > 500
car_maniac = cars[many_cars]
print(car_maniac)
<script.py> output:
cars_per_cap country drives_right
US 809 United States True
AUS 731 Australia False
JPN 588 Japan False
Use the code sample above to create a DataFrame medium, that includes all the observations of cars that have a cars_per_cap between 100 and 500.
Print out medium.
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
import numpy as np
cpc = cars['cars_per_cap']
between = np.logical_and(cpc > 100, cpc < 500)
medium = cars[between]
print(medium)
<script.py> output:
cars_per_cap country drives_right
RU 200 Russia True
4. Loops
while: warming up
Can you tell how many printouts the following while loop will do?
x = 1
while x < 4 :
print(x)
x = x + 1
- 0
- 1
- 2
- 3
- 4
Basic while loop
Create the variable offset with an initial value of 8.
Code a while loop that keeps running as long as offset is not equal to 0. Inside the while loop:
- Print out the sentence “correcting…”.
- Next, decrease the value of offset by 1. You can do this with offset = offset - 1.
- Finally, still within your loop, print out offset so you can see how it changes.
offset = 8
while offset != 0:
print("correcting...")
offset = offset - 1
print(offset)
<script.py> output:
correcting...
7
correcting...
6
correcting...
5
correcting...
4
correcting...
3
correcting...
2
correcting...
1
correcting...
0
Add conditionals
Inside the while loop, complete the if-else statement:
- If offset is greater than zero, you should decrease offset by 1.
- Else, you should increase offset by 1.
If you’ve coded things correctly, hitting Submit Answer should work this time.
offset = -6
while offset != 0 :
print("correcting...")
if offset > 0 :
offset = offset - 1
else :
offset = offset + 1
print(offset)
<script.py> output:
correcting...
-5
correcting...
-4
correcting...
-3
correcting...
-2
correcting...
-1
correcting...
0
Loop over a list
Write a for loop that iterates over all elements of the areas list and prints out every element separately.
areas = [11.25, 18.0, 20.0, 10.75, 9.50]
for element in areas:
print(element)
<script.py> output:
11.25
18.0
20.0
10.75
9.5
Indexes and values
Adapt the for loop in the sample code to use enumerate() and use two iterator variables.
Update the print() statement so that on each run, a line of the form “room x: y” should be printed, where x is the index of the list element and y is the actual list element, i.e. the area. Make sure to print out this exact string, with the correct spacing.
areas = [11.25, 18.0, 20.0, 10.75, 9.50]
# Change for loop to use enumerate() and update print()
for index, a in enumerate(areas) :
print("room " + str(index) + ": " + str(a))
<script.py> output:
room 0: 11.25
room 1: 18.0
room 2: 20.0
room 3: 10.75
room 4: 9.5
Adapt the print() function in the for loop on the right so that the first printout becomes “room 1: 11.25”, the second one “room 2: 18.0” and so on.
areas = [11.25, 18.0, 20.0, 10.75, 9.50]
for index, area in enumerate(areas) :
print("room " + str(index+1) + ": " + str(area))
<script.py> output:
room 1: 11.25
room 2: 18.0
room 3: 20.0
room 4: 10.75
room 5: 9.5
Loop over list of lists
Write a for loop that goes through each sublist of house and prints out the x is y sqm, where x is the name of the room and y is the area of the room.
house = [["hallway", 11.25],
["kitchen", 18.0],
["living room", 20.0],
["bedroom", 10.75],
["bathroom", 9.50]]
# Build a for loop from scratch
for x, y in house:
print("the " + str(x) + " is " + str(y) + " sqm")
<script.py> output:
the hallway is 11.25 sqm
the kitchen is 18.0 sqm
the living room is 20.0 sqm
the bedroom is 10.75 sqm
the bathroom is 9.5 sqm
Loop over dictionary
Write a for loop that goes through each key:value pair of europe. On each iteration, “the capital of x is y” should be printed out, where x is the key and y is the value of the pair.
europe = {
'spain':'madrid', 'france':'paris', 'germany':'berlin',
'norway':'oslo', 'italy':'rome', 'poland':'warsaw', 'austria':'vienna' }
# Iterate over europe
for key, value in europe.items():
print("the capital of " + key + " is " + str(value))
<script.py> output:
the capital of france is paris
the capital of germany is berlin
the capital of poland is warsaw
the capital of norway is oslo
the capital of italy is rome
the capital of austria is vienna
the capital of spain is madrid
Loop over Numpy array
Import the numpy package under the local alias np.
Write a for loop that iterates over all elements in np_height and prints out “x inches” for each element, where x is the value in the array.
Write a for loop that visits every element of the np_baseball array and prints it out.
import numpy as np
# For loop over np_height (一维数组)
for x in np_height:
print(str(x) + " inches")
# For loop over np_baseball (二维数组)
for x in np.nditer(np_baseball):
print(x)
Loop over DataFrame
Write a for loop that iterates over the rows of cars and on each iteration perform two print() calls: one to print out the row label and one to print out all of the rows contents.
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
# Iterate over rows of cars
for lab, row in cars.iterrows():
print(lab)
print(row)
<script.py> output:
US
cars_per_cap 809
country United States
drives_right True
Name: US, dtype: object
AUS
cars_per_cap 731
country Australia
drives_right False
Name: AUS, dtype: object
.....(省略)
Using the iterators lab and row, adapt the code in the for loop such that the first iteration prints out “US: 809”, the second iteration “AUS: 731”, and so on.
The output should be in the form “country: cars_per_cap”. Make sure to print out this exact string (with the correct spacing).
- You can use str() to convert your integer data to a string so that you can print it in conjunction with the country label.
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
# Adapt for loop
for lab, row in cars.iterrows() :
print(lab + ": " + str(row['cars_per_cap']))
<script.py> output:
US: 809
AUS: 731
JPN: 588
IN: 18
RU: 200
MOR: 70
EG: 45
Add column
Use a for loop to add a new column, named COUNTRY, that contains a uppercase version of the country names in the “country” column. You can use the string method upper() for this.
To see if your code worked, print out cars. Don’t indent this code, so that it’s not part of the for loop.
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
# Code for loop that adds COUNTRY column
for lab, row in cars.iterrows():
cars.loc[lab, "COUNTRY"] = row['country'].upper()
print(cars)
<script.py> output:
cars_per_cap country drives_right COUNTRY
US 809 United States True UNITED STATES
AUS 731 Australia False AUSTRALIA
JPN 588 Japan False JAPAN
IN 18 India False INDIA
RU 200 Russia True RUSSIA
MOR 70 Morocco True MOROCCO
EG 45 Egypt True EGYPT
Replace the for loop with a one-liner that uses .apply(str.upper). The call should give the same result: a column COUNTRY should be added to cars, containing an uppercase version of the country names.
As usual, print out cars to see the fruits of your hard labor
import pandas as pd
cars = pd.read_csv('cars.csv', index_col = 0)
# Use .apply(str.upper)
for lab, row in cars.iterrows() :
cars["COUNTRY"] = cars["country"].apply(str.upper)
print(cars)
<script.py> output:
cars_per_cap country drives_right COUNTRY
US 809 United States True UNITED STATES
AUS 731 Australia False AUSTRALIA
JPN 588 Japan False JAPAN
IN 18 India False INDIA
RU 200 Russia True RUSSIA
MOR 70 Morocco True MOROCCO
EG 45 Egypt True EGYPT
5. Case Study: Hacker Statistics
Random float
Import numpy as np.
Use seed() to set the seed; as an argument, pass 123.
Generate your first random float with rand() and print it out.
import numpy as np
np.random.seed(123)
print(np.random.rand())
<script.py> output:
0.6964691855978616
Roll the dice
Use randint() with the appropriate arguments to randomly generate the integer 1, 2, 3, 4, 5 or 6. This simulates a dice. Print it out.
Repeat the outcome to see if the second throw is different. Again, print out the result.
import numpy as np
np.random.seed(123)
print(np.random.randint(1, 7))
print(np.random.randint(1, 7))
<script.py> output:
6
3
Determine your next move
Roll the dice. Use randint() to create the variable dice.
Finish the if-elif-else construct by replacing ___:
- If dice is 1 or 2, you go one step down.
- if dice is 3, 4 or 5, you go one step up.
- Else, you throw the dice again. The number of eyes is the number of steps you go up.
Print out dice and step. Given the value of dice, was step updated correctly?
# Numpy is imported, seed is set
step = 50
dice = np.random.randint(1, 7)
if dice <= 2 :
step = step - 1
elif dice <= 5 :
step = step + 1
else :
step = step + np.random.randint(1,7)
print(dice)
print(step)
<script.py> output:
6
53
The next step
Make a list random_walk that contains the first step, which is the integer 0.
Finish the for loop:
- The loop should run 100 times.
- On each iteration, set step equal to the last element in the random_walk list. You can use the index -1 for this.
- Next, let the if-elif-else construct update step for you.
- The code that appends step to random_walk is already coded.
Print out random_walk.
# Numpy is imported, seed is set
random_walk = [0]
for x in range(100) :
step = random_walk[-1]
dice = np.random.randint(1,7)
if dice <= 2:
step = step - 1
elif dice <= 5:
step = step + 1
else:
step = step + np.random.randint(1,7)
random_walk.append(step)
print(random_walk)
<script.py> output:
[0, 3, 4, 5, 4, 5, 6, 7, 6, 5, 4, 3, 2, 1, 0, -1, 0, 5, 4, 3, 4, 3, 4, 5, 6, 7, 8, 7, 8, 7, 8, 9, 10, 11, 10, 14, 15, 14, 15, 14, 15, 16, 17, 18, 19, 20, 21, 24, 25, 26, 27, 32, 33, 37, 38, 37, 38, 39, 38, 39, 40, 42, 43, 44, 43, 42, 43, 44, 43, 42, 43, 44, 46, 45, 44, 45, 44, 45, 46, 47, 49, 48, 49, 50, 51, 52, 53, 52, 51, 52, 51, 52, 53, 52, 55, 56, 57, 58, 57, 58, 59]
How low can you go?
Use max() in a similar way to make sure that step doesn’t go below zero if dice <= 2.
Hit Submit Answer and check the contents of random_walk.
# Numpy is imported, seed is set
random_walk = [0]
for x in range(100) :
step = random_walk[-1]
dice = np.random.randint(1,7)
if dice <= 2:
step = max(0, step - 1)
elif dice <= 5:
step = step + 1
else:
step = step + np.random.randint(1,7)
random_walk.append(step)
print(random_walk)
<script.py> output:
[0, 3, 4, 5, 4, 5, 6, 7, 6, 5, 4, 3, 2, 1, 0, 0, 1, 6, 5, 4, 5, 4, 5, 6, 7, 8, 9, 8, 9, 8, 9, 10, 11, 12, 11, 15, 16, 15, 16, 15, 16, 17, 18, 19, 20, 21, 22, 25, 26, 27, 28, 33, 34, 38, 39, 38, 39, 40, 39, 40, 41, 43, 44, 45, 44, 43, 44, 45, 44, 43, 44, 45, 47, 46, 45, 46, 45, 46, 47, 48, 50, 49, 50, 51, 52, 53, 54, 53, 52, 53, 52, 53, 54, 53, 56, 57, 58, 59, 58, 59, 60]
Visualize the walk
Add some lines of code after the for loop:
- Import matplotlib.pyplot as plt.
- Use plt.plot() to plot random_walk.
- Finish off with plt.show() to actually display the plot.
# Numpy is imported, seed is set
random_walk = [0]
for x in range(100) :
step = random_walk[-1]
dice = np.random.randint(1,7)
if dice <= 2:
step = max(0, step - 1)
elif dice <= 5:
step = step + 1
else:
step = step + np.random.randint(1,7)
random_walk.append(step)
import matplotlib.pyplot as plt
plt.plot(random_walk)
plt.show()

Simulate multiple walks
Fill in the specification of the for loop so that the random walk is simulated 10 times.
After the random_walk array is entirely populated, append the array to the all_walks list.
Finally, after the top-level for loop, print out all_walks.
# Numpy is imported; seed is set
all_walks = []
for i in range(10) :
random_walk = [0]
for x in range(100) :
step = random_walk[-1]
dice = np.random.randint(1,7)
if dice <= 2:
step = max(0, step - 1)
elif dice <= 5:
step = step + 1
else:
step = step + np.random.randint(1,7)
random_walk.append(step)
all_walks.append(random_walk)
print(all_walks)
<script.py> output:
[[0, 3, 4, 5, 4, 5, 6, 7, 6, 5, 4, 3, 2, 1, 0, 0, 1, 6, 5, 4, 5, 4, 5, 6, 7, 8, 9, 8, 9, 8, 9, 10, 11, 12, 11, 15, 16, 15, 16, 15, 16, 17, 18, 19, 20, 21, 22, 25, 26, 27, 28, 33, 34, 38, 39, 38, 39, 40, 39, 40, 41, 43, 44, 45, 44, 43, 44, 45, 44, 43, 44, 45, 47, 46, 45, 46, 45, 46, 47, 48, 50, 49, 50, 51, 52, 53, 54, 53, 52, 53, 52, 53, 54, 53, 56, 57, 58, 59, 58, 59, 60], [0, 4, 3, 2, 4, 3, 4, 6, 7, 8, 13, 12, 13, 14, 15, 16, 17, 16, 21, 22, 23, 24, 23, 22, 21, 20, 19, 20, 21, 22, 28, 27, 26, 25, 26, 27, 28, 27, 28, 29, 28, 33, 34, 33, 32, 31, 30, 31, 30, 29, 31, 32, 35, 36, 38, 39, 40, 41, 40, 39, 40, 41, 42, 43, 42, 43, 44, 45, 48, 49, 50, 49, 50, 49, 50, 51, 52, 56, 55, 54, 55, 56, 57, 56, 57, 56, 57, 59, 64, 63, 64, 65, 66, 67, 68, 69, 68, 69, 70, 71, 73], [0, 2, 1, 2, 3, 6, 5, 6, 5, 6, 7, 8, 7, 8, 7, 8, 9, 11, 10, 9, 10, 11, 10, 12, 13, 14, 15, 16, 17, 18, 17, 18, 19, 24, 25, 24, 23, 22, 21, 22, 23, 24, 29, 30, 29, 30, 31, 32, 33, 34, 35, 34, 33, 34, 33, 39, 38, 39, 38, 39, 38, 39, 43, 47, 49, 51, 50, 51, 53, 52, 58, 59, 61, 62, 61, 62, 63, 64, 63, 64, 65, 66, 68, 67, 66, 67, 73, 78, 77, 76, 80, 81, 82, 83, 85, 84, 85, 84, 85, 84, 83], [0, 6, 5, 6, 7, 8, 9, 10, 11, 12, 13, 12, 13, 12, 11, 12, 11, 12, 11, 12, 13, 17, 18, 17, 23, 22, 21, 22, 21, 20, 21, 20, 24, 23, 24, 23, 24, 23, 24, 26, 25, 24, 23, 24, 23, 28, 29, 30, 29, 28, 29, 28, 29, 28, 33, 34, 33, 32, 31, 30, 31, 32, 36, 42, 43, 44, 45, 46, 45, 46, 48, 49, 50, 51, 50, 49, 50, 49, 50, 51, 52, 51, 52, 53, 54, 53, 52, 53, 54, 59, 60, 61, 66, 65, 66, 65, 66, 67, 68, 69, 68], [0, 6, 5, 6, 5, 4, 5, 9, 10, 11, 12, 13, 12, 11, 10, 9, 8, 9, 10, 11, 12, 13, 14, 13, 14, 15, 14, 15, 16, 19, 18, 19, 18, 19, 22, 23, 24, 25, 24, 23, 26, 27, 28, 29, 28, 27, 28, 31, 32, 37, 38, 37, 38, 37, 38, 37, 43, 42, 41, 42, 44, 43, 42, 41, 42, 43, 44, 45, 49, 54, 55, 56, 57, 60, 61, 62, 63, 64, 65, 66, 65, 64, 65, 66, 65, 71, 70, 71, 72, 71, 70, 71, 70, 69, 75, 74, 73, 74, 75, 74, 73], [0, 0, 0, 1, 7, 8, 11, 12, 18, 19, 20, 26, 25, 31, 30, 31, 32, 33, 32, 38, 39, 38, 39, 38, 39, 38, 39, 38, 39, 43, 44, 46, 45, 46, 45, 44, 45, 44, 45, 44, 48, 52, 51, 50, 49, 50, 51, 55, 56, 57, 61, 60, 59, 58, 59, 60, 62, 61, 60, 61, 62, 64, 67, 72, 73, 72, 73, 74, 75, 76, 77, 76, 77, 78, 84, 83, 88, 87, 91, 90, 94, 93, 96, 97, 96, 97, 103, 102, 101, 100, 104, 103, 102, 103, 104, 103, 104, 105, 106, 107, 106], [0, 0, 0, 1, 0, 0, 4, 5, 7, 11, 17, 16, 15, 16, 17, 18, 17, 18, 17, 18, 19, 18, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 33, 32, 35, 36, 35, 34, 35, 36, 37, 36, 35, 34, 33, 34, 35, 36, 37, 38, 39, 40, 39, 40, 41, 43, 42, 43, 44, 47, 49, 50, 49, 48, 47, 46, 45, 46, 45, 46, 48, 49, 50, 49, 50, 49, 48, 49, 48, 47, 46, 47, 46, 45, 46, 47, 48, 50, 51, 52, 51, 50, 51, 57, 56, 57, 58, 63, 62, 63], [0, 0, 1, 2, 1, 2, 3, 9, 10, 11, 12, 11, 13, 14, 15, 16, 15, 16, 17, 18, 19, 18, 19, 18, 19, 20, 19, 20, 24, 25, 28, 29, 33, 34, 33, 34, 35, 34, 33, 38, 39, 40, 39, 38, 39, 40, 41, 40, 44, 43, 44, 45, 46, 47, 48, 49, 50, 49, 48, 47, 48, 49, 53, 54, 53, 54, 55, 54, 60, 61, 62, 63, 62, 63, 64, 67, 66, 67, 66, 65, 64, 65, 66, 68, 69, 70, 74, 75, 74, 73, 74, 75, 74, 73, 74, 75, 76, 75, 74, 75, 76], [0, 1, 0, 1, 2, 1, 0, 0, 1, 2, 3, 4, 5, 10, 14, 13, 14, 13, 12, 11, 12, 11, 12, 13, 12, 16, 17, 16, 17, 16, 15, 16, 15, 19, 20, 21, 22, 23, 24, 23, 24, 25, 26, 27, 28, 27, 32, 33, 34, 33, 34, 33, 34, 35, 34, 35, 40, 41, 42, 41, 42, 43, 44, 43, 44, 43, 44, 45, 44, 43, 42, 43, 44, 43, 42, 41, 42, 46, 47, 48, 49, 50, 51, 50, 51, 52, 51, 52, 57, 58, 57, 56, 57, 56, 55, 54, 58, 59, 60, 61, 60], [0, 1, 2, 3, 4, 5, 4, 3, 6, 5, 4, 3, 2, 3, 9, 10, 9, 10, 11, 10, 9, 10, 11, 12, 11, 15, 16, 15, 17, 18, 17, 18, 19, 20, 21, 22, 23, 22, 21, 22, 23, 22, 23, 24, 23, 22, 21, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 33, 34, 35, 36, 37, 38, 37, 36, 42, 43, 44, 43, 42, 41, 45, 46, 50, 49, 55, 56, 57, 61, 62, 61, 60, 61, 62, 63, 64, 63, 69, 70, 69, 73, 74, 73, 74, 73, 79, 85, 86, 85, 86, 87]]
Visualize all walks
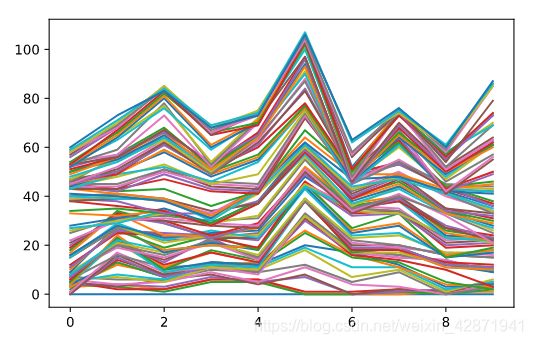
Use np.array() to convert all_walks to a Numpy array, np_aw.
Try to use plt.plot() on np_aw. Also include plt.show(). Does it work out of the box?
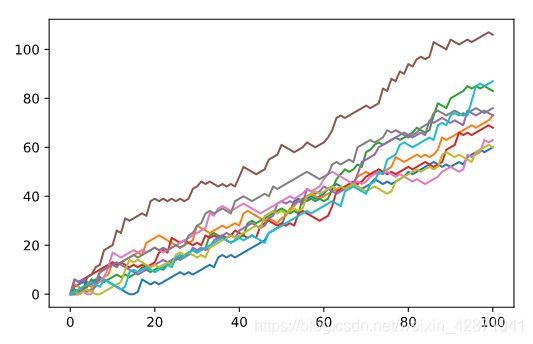
Transpose np_aw by calling np.transpose() on np_aw. Call the result np_aw_t. Now every row in np_all_walks represents the position after 1 throw for the 10 random walks.
Use plt.plot() to plot np_aw_t; also include a plt.show(). Does it look better this time?
# numpy and matplotlib imported, seed set.
all_walks = []
for i in range(10) :
random_walk = [0]
for x in range(100) :
step = random_walk[-1]
dice = np.random.randint(1,7)
if dice <= 2:
step = max(0, step - 1)
elif dice <= 5:
step = step + 1
else:
step = step + np.random.randint(1,7)
random_walk.append(step)
all_walks.append(random_walk)
np_aw = np.array(all_walks)
plt.plot(np_aw)
plt.show()
plt.clf()
np_aw_t = np.transpose(np_aw) #转置
plt.plot(np_aw_t)
plt.show()
Implement clumsiness
Change the range() function so that the simulation is performed 250 times.
Finish the if condition so that step is set to 0 if a random float is less or equal to 0.001. Use np.random.rand().
# numpy and matplotlib imported, seed set
all_walks = []
for i in range(250) :
random_walk = [0]
for x in range(100) :
step = random_walk[-1]
dice = np.random.randint(1,7)
if dice <= 2:
step = max(0, step - 1)
elif dice <= 5:
step = step + 1
else:
step = step + np.random.randint(1,7)
# Implement clumsiness
if np.random.rand() <= 0.001 :
step = 0
random_walk.append(step)
all_walks.append(random_walk)
np_aw_t = np.transpose(np.array(all_walks))
plt.plot(np_aw_t)
plt.show()

Plot the distribution
To make sure we’ve got enough simulations, go crazy. Simulate the random walk 500 times.
From np_aw_t, select the last row. This contains the endpoint of all 500 random walks you’ve simulated. Store this Numpy array as ends.
Use plt.hist() to build a histogram of ends. Don’t forget plt.show() to display the plot.
# numpy and matplotlib imported, seed set
all_walks = []
for i in range(500) :
random_walk = [0]
for x in range(100) :
step = random_walk[-1]
dice = np.random.randint(1,7)
if dice <= 2:
step = max(0, step - 1)
elif dice <= 5:
step = step + 1
else:
step = step + np.random.randint(1,7)
if np.random.rand() <= 0.001 :
step = 0
random_walk.append(step)
all_walks.append(random_walk)
np_aw_t = np.transpose(np.array(all_walks))
ends = np_aw_t[-1,:]
plt.hist(ends)
plt.show()

Calculate the odds
What’s the estimated chance that you’ll reach 60 steps high if you play this Empire State Building game?
- 48.8%
- 73.9%
- 78.4%
- 95.9%
np.mean(ends >= 60)
<script.py> output:
0.784