C++ STL 常用容器
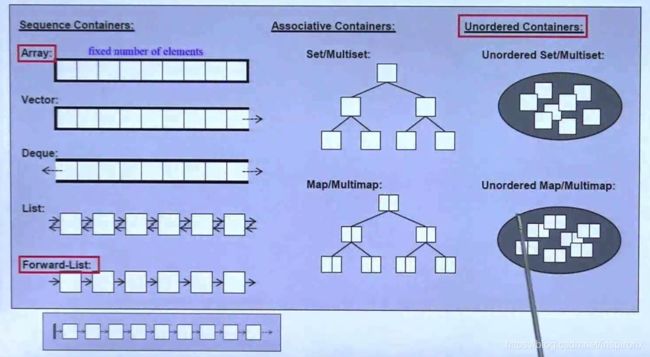
STL容器
STL的常用容器,分别是:
#1 vector list deque multiset unordered_multiset
#2 array hashtable tuple
vector
定义:template < class T, class Alloc = allocator > class vector;
基本概念
vector(向量)是一个封装了大小和类型的动态容器,其本质和数组差不多;
vector的数据存储是一维的,默认每次扩容一倍;
正常使用情况,尽量指定容器的大小,对内存和速度有优化

常用API
// --------ctor---------
vector<int> v1 = {
3, 4, 5, 7, 9 }; // 使用initializer_list来构造一个vector
vector<int> v2 (); // 空构造函数
vector<int> v3 (v1); // 复制构造函数
vector<int> v4 (3); // 指定容器的数量
vector<int> v5 (3, 0); // 指定容器的数量并且全部初始化一个默认值
vector<int> v6 (v1.begin(), v1.end());//使用另外一个容器的fist和last迭代器指针来构造
// ---------add----------
v1.push_back(11); // 往容器的最后添加一个数据
v1.insert(v1.begin(), 1);// 在容器的指定位置添加一个数据
// ---------remove----------
v1.erase(v1.begin()); // 在容器的指定位置删除一个数据
v1.pop_back(); // 取出容器的最后一个数据,容器数据会删除
v1.clear(); // 清除容器的全部数据
// ---------capacity---------
v1.size(); // 容器当前的数据数量
v1.capacity(); // 容器当前开辟的内存空间数量
v1.max_size(); // 容器最大可以存储的数据量
v1.empty(); // 判断容器里面是否有数据
// ---------update----------
v1.swap(v6); // 交换同类型2个容器的数据
v1[0] = -3; // 更新指定位置数据的值
list
定义:template < class T, class Alloc = allocator > class list;
基本概念
list是环状双向链表,可以在数据的两端对数据进行操作;
list无法通过下标定位数据,每次都要从0个元素开遍历数据;
正常使用情况,尽量指定容器的大小,对内存和速度有优化

常用API
list<int> link1 = {
3, 4, 5, 6, 7, 8 };
list<int> link2 ();
list<int> link3(link1);
list<int> link4(3);
list<int> link5(3, 4);
list<int> link6(link1.begin(), link1.end());
// ---------add---------
link1.push_back(9);
link1.push_front(2);
link1.insert(link1.begin(), 1);
// ---------remove---------
link1.pop_front();
link1.pop_back();
// link1.clear();
link1.erase(link1.begin());
// ---------update----------
link1.emplace_front(2);
link1.emplace_back(9);
link1.assign({
1, 2, 3});
link1.swap(link6);
// ---------query-----------
link1.begin();
link1.end();

deque
deque是不规则的顺序队列,可以从数据两边分别展开,拥有一段数据的约束范围

常用API
deque<int> queue1 = {
3, 4, 5, 6, 7 };
deque<int> queue2 ();
deque<int> queue3(queue1);
deque<int> queue4(3);
deque<int> queue5(3, 4);
deque<int> queue6(queue1.begin(), queue1.end());
// --------add--------
queue1.push_back(8);
queue1.insert(queue1.begin(), 2);
// --------remove--------
queue1.pop_back();
queue1.pop_front();
queue1.erase(queue1.begin());
// queue1.clear();
// --------update--------
queue1.assign({
1, 2, 3 });
queue1.swap(queue6);
queue1.emplace_back(8);
queue1.emplace_front(2);
// --------query--------
queue1.at(0);
queue1[0];
queue1.front();
queue1.back();

multiset
树状结构数据,和二叉树的数据结构差不多,可以允许元素重复;

常用API
multiset<int> tree1 = {
3, 4, 5, 6, 7 };
multiset<int> tree2 ();
multiset<int> tree3 (tree1);
multiset<int> tree4 (tree1.begin(), tree1.end());
// --------add--------
tree1.insert(tree1.begin(), 2);
tree1.emplace(8);
// --------remove--------
tree1.erase(tree1.begin());
// tree1.clear()
// --------update--------
tree1.swap(tree4);
// --------query--------
tree1.find(4);

unordered_multiset
无序多集数据链表,效率比multiset高

常用API

array
array是固定数量大小的顺序数组,是基于原始数据的第一层封装
int main(int argc, char* argv[])
{
// 固定数量大小,不足位补零
array<int, 6> arr1 = {
3,4, 5, 6, 7};
// 将数据全部定义成8
arr1.assign(8);
arr1.front();
arr1.back();
arr1.at(0);
arr1[0];
}

hashtable
hash表,也是散列表,对于数据拥有不确定性,写入慢,读取快
工作原理:先开辟一个数量的内存空间,如果数据的占据空间大于开辟的内存空间,
则进行rehashing来扩容。
C++2.0无序容器
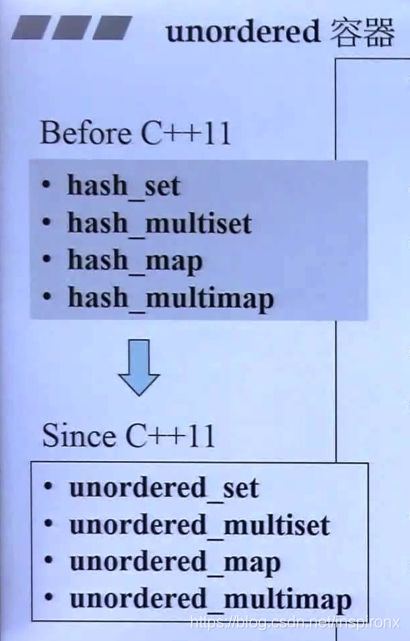
unordered_set<int> us1 = {
3, 4, 5, 6, 7 };
unordered_multiset<int> um1 = {
3, 4, 5, 6, 7 };
unordered_map<int, string> um2 = {
{
1, "one" }, {
2, "two" }, {
3, "three"} };
unordered_multimap<int, string> um3 = {
{
1, "one" }, {
2, "two" }, {
3, "thred" } };
cout << um2[1] << endl;
cout << um3.begin()->first << um3.begin()->second << endl;
tuple
tuple元组可以最多指定数量为15个元素
常用API
tuple<int, string, float> t1(1, "one", 3.14 );
auto t2 = make_tuple(2, "two", 3.14);
string t1t = get<1>(t1);
string t2t = get<1>(t2);
cout << t1t << " " << t2t << endl;
// 将tuple对应类型的数据赋值到声明的变量上
int ai;
const char* ac;
double ad;
tie(ai, ac, ad) = t2;
cout << ac << endl;