CUDA10.0 官方手册 阅读笔记 章三 CUDA编程接口
(因为这章内容比较碎,不好提炼,大部分为原文翻译,人工翻译,不是机器翻译。抵制不负责任的机翻从你我做起!翻译不易,转载贴上出处。——[email protected])
目录
3.1 用NVCC编译
3.1.1 编译工作流
3.1.2 二进制兼容性
3.1.3 PTX(线程并行执行能力)兼容性
3.1.4 程序兼容性
3.1.5 C/C++兼容性
3.1.6 64位兼容性
3.2 CUDA C 运行时
3.2.1 初始化
3.2.2 设备内存
3.2.3 共享内存
3.2.4 页锁定的主机内存
3.2.4.1 轻便内存
3.2.4.2 写混合式内存
3.2.4.3 映射内存
3.2.5 异步的同时执行
3.2.5.6 图
3.2.6 多设备系统
3.2.7 统一虚拟内存
3.2.8 IPC(进程内通信)
3.2.9 纠错
3.2.10 调用栈
3.2.11 纹理和表层(surface)内存
3.2.12 图形(库)互用性
3.3 版本和计算能力
3.4 计算模型
3.5 (显示)模型切换
3.6 windows中Tesla计算集簇(cluster)模型
正文开始:
由于CUDA对C的拓展,所有包含CUDA代码的源文件都必须由NVCC编译一遍。
当提到 编译工作流 时runtime提供了主机和设备机之间的交互。
Runtime必须建立在低层次的API函数、CUDA 驱动函数之上。驱动函数通过包含底层函数、主机对设备机的类函数、CUDA模型、设备机动态库 提供了对控制的拓展。
大多数程序并不需要使用驱动函数,
3.1 用NVCC编译
CUDA内核函数可由CUDA推荐的固定结构书写——PTX(并行线程执行结构),也可由更高效(指编写高效)的高层次API如C编写。但都需要用NVCC编译成 能在设备上运行的二进制代码。
NVCC是一个编译器,它简化了C或PTX代码编写。
3.1.1 编译工作流
3.1.1.1 离线编译
NVCC主要编译流程如下
- 将设备代码编译成汇编或二进制形式
- 通过查询runtime加载函数和kernel调用函数修改主机代码,将<<<…>>>语法写入内核中
修改过的代码被输出成C的形式,可以用别的工具编译成目标代码。
此时程序可以
- 链接成编译过的主机代码
- 或 忽略修改过的主机代码并且使用CUDA驱动函数来 加载和执行PTX代码或CUBIN项目
3.1.1.2 运行时编译
任何PTX代码在程序执行时被调用,然后才由设备驱动(解释器)编译的这种编译叫做“运行时编译”。运行时编译增加了程序加载时间,但使PTX代码获得了因设备驱动器(解释器)优化而带来的性能优化。并且这也是运行一个未编译的PTX代码的唯一的方法。
当设备驱动为程序运行时编译了一些PTX代码时,它自动缓存了一份所编译的代码,防止接下来再编译,但当驱动升级时这些缓存将自动失效。
3.1.2 二进制兼容性
二进制代码与架构一一对应。一个CUDA可执行程序使用编译器选择-code编译成对应特异性架构的代码。举个栗子,使用选择-code=sm_35编译出的二进制代码能在计算能力为3.5的设备上运行。这种编译有向下兼容性,但不向上兼容(旧设备跑不了新代码)。
值得注意的是,二进制兼容性只支持pc端,不支持嵌入式的Tegra芯片。并且,这两者编译出的代码不能共用。
3.1.3 PTX(线程并行执行能力)兼容性
一些PTX特性只支持高等级的设备。例如,Warp Shuffle(瓦片乱序执行)只能在计算能力在3.0以上的设备上运行。编译设置”-arch”指明了目标设备的计算能力,如Warp Shuffle需要设置“-arch=compute_30”(或更高)
含有计算性能要求的PTX代码 编译成的目标代码总要求不小于这个计算性能要求。需要注意的是,从早期代码编译来的程序可能并没有完全利用硬件性能。如,编译为Pascal架构写的PTX代码,当它的目标设备是Volta架构时,可能没有用到Tensor加速核,而导致性能浪费。因此,旧代码编译到新设备上,可能表现会变糟。
3.1.4 程序兼容性
想要在特定设备上运行,程序必须加载二进制代码或与设备性能相符的PTX代码。
编译参数举例:
nvcc x.cu
-gencode arch=compute_35,code=sm_35
-gencode arch=compute_60,code=sm_35
译者注:![]() 我的设备是6.1能力的,经实践得出,这样编译超过计算能力的代码,将导致程序运行不成功,即使没有使用高等级设备的特性。
我的设备是6.1能力的,经实践得出,这样编译超过计算能力的代码,将导致程序运行不成功,即使没有使用高等级设备的特性。
宏__CUDA_ARCH__标注了设备等级。如编译选择arch=compute_35,__CUDA_ARCH__就等于350
使用驱动API的程序,必须编译成分立文件,并且在执行时要详尽地加载和执行对应的文件。(这在说个啥,还没碰到过,先略过)
特别需要注意,Volta架构引入了独立线程调度,这会使得以前依赖于SIMT调度机制的代码运行混乱,得到错误的结果。所以,编译那些程序时,要特定-arch=compute_60 -code=sm_60而不能用默认的70
可以使用-arch=sm_35 来简化-arch=compute_35 -code=sm_35
3.1.5 C/C++兼容性
主机端支持全部C/C++,设备端只支持一部分,需要查表“C/C++ Language Support”
3.1.6 64位兼容性
64位的NVCC使用64位模式编译。设备机只在主机端代码以64位模式编译时编译成64位。32位的于此相同。
32位的NVCC也可以用-m64来编译64位设备代码
64位的NVCC也可以用-m32来编译32位设备代码。
3.2 CUDA C 运行时
运行时是调用cudart库,它与程序链接,通过cudart.lib or libcudaer.a静态链接,或通过cudart.dll or libcudart.so动态调用。动态调用需要调用库作为程序安装的一个部分被安装。这些链接的入口指针都被CUDA预先固定了。
设备内存:总览运行时使用设备内存情况。
共享内存:说明共享内存的使用,可以作为性能最大化评估点。
页锁定内存:使内核执行时,主机和设备之间内存映射重叠。
异步并行执行:说明异步并行执行在不同等级系统内的需求的概念和API。
多设备系统:说明如何将编程模型拓展到一个由单主机多设备的系统中去。
错误校对:描述如何正确地检测错误和在运行时生成错误提示。
调用栈:提到用于管理CUDA C调用的运行时函数。
纹理和表面内存:展示了纹理和表面内存这种使用内存的另一种方式。这也展示了GPU纹理化的内在操作。
图形(函数库)协同性:介绍了不同 运行时 可协同工作的函数,主要有图形api,OpenGL,Direct3D
3.2.1 初始化
第一步:创建CUDA上下文。这个上下文是设备的第一个上下文,它在主机程序中所有线程中共享。创建的同时,那些“运行时编译的设备代码”编译并且装入设备内存中。这些操作都是在底层,并且首要上下文对程序是透明的。
当主机调用cudaDeviceRestart()时,销毁当前主机线程创建的首要上下文。当其他线程新的运行时函数调用时,将创建新的首要上下文。
3.2.2 设备内存
设备内存可以像 访问“线性存储”或“CUDA数组”一样访问。
当使用纹理内存时,CUDA数组是不透明的内存结构(意思是要懂CUDA数组)
线性内存在设备的40位地址空间中,所以可以通过指针来访问那些分开存储的空间,就像二叉树那样。
线性内存的申请使用cudaMalloc(),用cudaFree()释放,主机和设备间搬运内存用cudaMemcpy();
线性内存也可以通过cudaMallocPitch()和cudaMalloc3D()来申请。这要求数据符合2D、3D结构要求。对应的内存拷贝是cudaMemcpy2D()、cudaMemcpy3D();
下面的代码说明了一个width*height 2D数组,并且如何在设备中循环
__global__ void My2DArraySampleKernel(float *devPtr, size_t pitch, int width, int height) {
for (int r = 0; r < height; r++) {
float *row = (float*)((char*)devPtr + r * pitch);
for (int c = 0; c < width; c++) {
float element = row[c];
}
}
}
void host2DArraySample() {
int width = 64, height = 64;
float *devPtr;//设备存储空间的指针
size_t pitch;
cudaMallocPitch(&devPtr, &pitch, width * sizeof(float), height);
My2DArraySampleKernel<<<100, 512 >>> (devPtr, pitch, width, height);
}
译者注:
pitch的意思是

下面代码说明了使用width*height*depth的3D数组
__global__ void My3DArraySampleKernel(cudaPitchedPtr devPitchedPtr, int width, int height, int depth) {
char * devPtr = (char*)devPitchedPtr.ptr;
size_t pitch = devPitchedPtr.pitch;
size_t slicePitch = pitch * height;
for (int z = 0; z < depth; z++) {
char *slice = devPtr + z * slicePitch;
for (int y = 0; y < height; y++) {
float * row = (float*)(slice + y * pitch);
for (int x = 0; x < width; x++) {
float element = row[x];
}
}
}
}
void host3DArraySample() {
int width = 64, height = 64, depth = 64;
cudaExtent extent = make_cudaExtent(width * sizeof(float), height, depth);
cudaPitchedPtr devPitchedPtr;
cudaMalloc3D(&devPitchedPtr, extent);
My3DArraySampleKernel<<<100,512>>>(devPitchedPtr, width, height, depth);
}
下面说明了所有用来复制 由cudaMalloc()、cudaMallocPtich、cudaMalloc3D、CUDA数组,和全局与常量数组 申请的线性内存的函数
void cudaMemoryAccessSample() {
//常量与主机内存直接
__constant__ float constData[256];
float data[256];
cudaMemcpyToSymbol(constData, data, sizeof(data));//主机→设备
cudaMemcpyFromSymbol(data, constData, sizeof(data));//设备→主机
//设备内存与主存
__device__ float *devData;
float value = 3.14f;
cudaMemcpyToSymbol(devData, &value, sizeof(float));
//设备内存指针与设备内存
__device__ float *devPointer;
float *ptr;
cudaMalloc(&ptr, 256 * sizeof(float));
cudaMemcpyToSymbol(devPointer, &ptr, sizeof(ptr));
}
cudaGetSymbolAddress()用于取回定义在全局内存空间中的变量指针。同时也可以用cudaGetSymbolSize()来获取那个变量的大小。
3.2.3 共享内存
共享内存使用“__shared__”作为内存定义分类符。
共享内存的访问速度快于全局内存。任何能被局部内存化的全局内存访问都应当局部内存化。
下面这个例子说明了如何局部内存化。它(指这个例子)之直接使用了矩阵乘法,而没有局部内存化。每个线程读取A的一行 和 B的一列,并且计算后放到C的正确位置。因此,计算A时要从全局内存中读取B B.width次,计算B时要从全局内存中读取A A.width次。
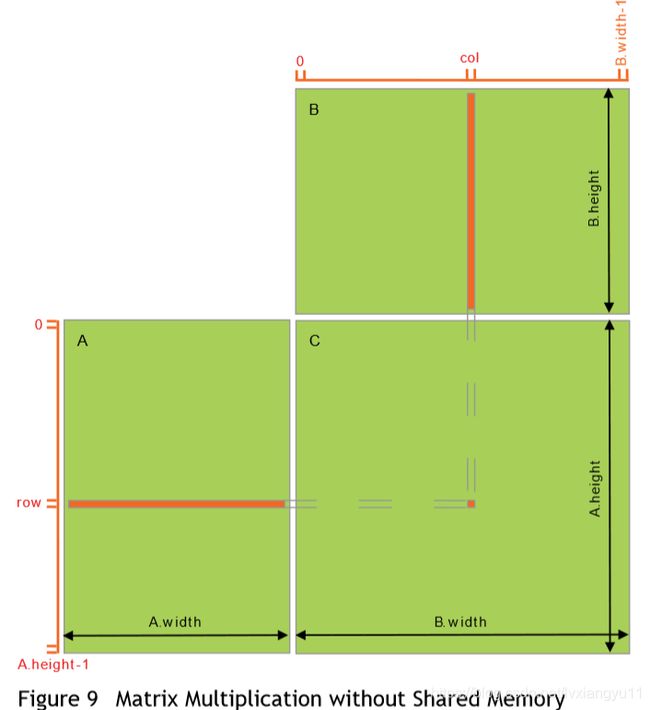
//CUDA矩阵乘法(未局部内存优化)版本
//矩阵以行号为主索引号
//M(row, col) = *(M.elemets + row * M.width + col);
struct Matrix {
int width;
int height;
float *elements;
};
//定义线程块大小
#define BLOCK_SIZE 16
//先定义众核矩阵乘函数
__global__ void MatMulKernelWithNoSharedMemorlized(const Matrix, const Matrix, Matrix);
//矩阵乘主机端代码
//矩阵维度被设为BLOCK_SIZE的线程数
void MatMulWithNoSharedMemorized(const Matrix A, const Matrix B, Matrix C) {
//将A,B矩阵从主机内存中搬到设备端中去
Matrix d_A;
d_A.width = A.width; d_A.height = A.height;
size_t size = A.width * A.height * sizeof(float);
cudaMalloc(&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size, cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = B.width; d_B.height = B.height;
size = B.width * B.height * sizeof(float);
cudaMalloc(&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size, cudaMemcpyHostToDevice);
//在设备中分配C的内存空间
Matrix d_C;
d_C.width = C.width; d_C.height = C.height;
size = C.width * C.height * sizeof(float);
cudaMalloc(&d_C.elements, size);
//申请CUDA内核
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);//定义二维线程块,大小是BLOCK_SIZE*BLOCK_SIZE*1
dim3 dimGrid(B.width / BLOCK_SIZE, A.height / dimBlock.y);//定义线程网格大小
MatMulKernelWithNoSharedMemorlized <<
cudaError_t cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "乘法计算失败");
}
//将C的结果从设备端搬回主机端
cudaMemcpy(C.elements, d_C.elements, size, cudaMemcpyDeviceToHost);
//释放CUDA内存
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
//众核矩阵乘函数
__global__ void MatMulKernelWithNoSharedMemorlized(Matrix A, Matrix B, Matrix C) {
//每一个线程计算一个C
//通过放到C列中的计算结果(这说的是个“人话”?)
float Cvalue = 0;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
for (int ele = 0; ele < A.width; ele++) {
Cvalue += A.elements[row*A.width + ele] * B.elements[ele*B.width + col];
}
C.elements[row*C.width + col] = Cvalue;
}
下面这个例子使用了局部内存优化。每一个线程块都负责计算C的一个子矩阵Csub ,这个线程块中的所有线程都负责计算这个子矩阵中的一个元素。Csub的大小是BLOCK_SIZE*BLOCK_SIZE,C的大小是A.height*B.weight。同时,A、B矩阵也被分成BLOCK_SIZE大小。这将计算一个线程块的Csub变成计算多个AblockBblock相乘后的结果相加。每次(线程块的)计算先将AB矩阵的那个分块从 全局变量区 搬到 共享内存区,然后每个线程计算对应的内容,将结果保存在寄存器中,计算玩所有AB对应分块矩阵后,再将多次结果得到的合保存到全局内存中去。
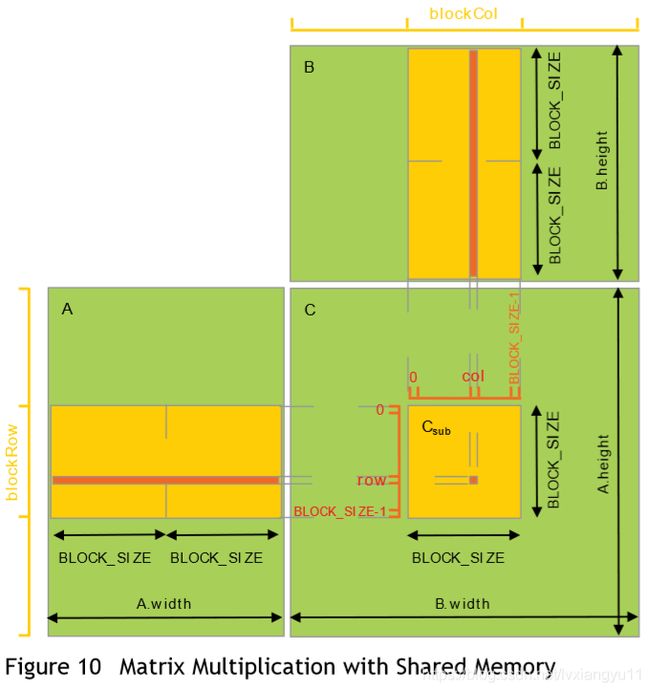
通过将计算内容分块,我们利用了共享内存访问快的这一特点。并且节约了很多全局内存的访问带宽。A读取了B.width/BLOCK_SIZE次,B读取了A.width/BLOCK_SIZE次。
由于有了步幅这种增强,子矩阵可以用同种方式有效的访问。__device__函数用来获取和设置参数并且建立矩阵的子矩阵。
代码如下
//设置线程块大小
#define BLOCK_SIZE 32
//CUDA矩阵乘法(未局部内存优化)版本
//矩阵以行号为主索引号
//M(row, col) = *(M.elemets + row * M.stride + col);
struct Matrix {
int width;
int height;
int stride;
float *elements;
};
//获取矩阵元素
__device__ float GetElement(const Matrix A, int row, int col) {
return A.elements[row*A.stride + col];
}
//设置矩阵内容
__device__ void SetElement(Matrix A, int row, int col, float value) {
A.elements[row*A.stride + col] = value;
}
//获取BLOCK_SIZE*BLOCK_SIZE的子矩阵,
__device__ Matrix GetSubMatrix(Matrix A, int row, int col) {
Matrix Asub;
Asub.width = BLOCK_SIZE;
Asub.height = BLOCK_SIZE;
Asub.stride = A.stride;
Asub.elements = &A.elements[A.stride * BLOCK_SIZE * row + BLOCK_SIZE * col];//获得第一个位置即可,机智啊!
return Asub;
}
//先定义下内核函数
__global__ void MatMulKernelWithSharedMemorlized(const Matrix, const Matrix, Matrix);
//矩阵乘 主机到设备机的代码 矩阵维度要求是BLOCK_SIZE的倍数
void MatMulWithSharedMemorlized(const Matrix A, const Matrix B, Matrix C) {
//将A,B矩阵从主机内存中搬到设备端中去
Matrix d_A;
d_A.width = d_A.stride = A.width; d_A.height = A.height;
size_t size = A.width * A.height * sizeof(float);
cudaMalloc(&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size, cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = d_B.stride = B.width; d_B.height = B.height;
size = B.width * B.height * sizeof(float);
cudaMalloc(&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size, cudaMemcpyHostToDevice);
//在设备中分配C的内存空间
Matrix d_C;
d_C.width = d_C.stride = C.width; d_C.height = C.height;
size = C.width * C.height * sizeof(float);
cudaMalloc(&d_C.elements, size);
//申请CUDA内核
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);//定义二维线程块,大小是BLOCK_SIZE*BLOCK_SIZE*1
dim3 dimGrid(B.width / BLOCK_SIZE, A.height / dimBlock.y);//定义线程网格大小
MatMulKernelWithSharedMemorlized <<
//将C的结果从设备端搬回主机端
cudaMemcpy(C.elements, d_C.elements, size, cudaMemcpyDeviceToHost);
//释放CUDA内存
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
//局部内存化的矩阵乘代码
__global__ void MatMulKernelWithSharedMemorlized(const Matrix A, const Matrix B, Matrix C) {
//线程块的行和列索引号
int blockRow = blockIdx.y;
int blockCol = blockIdx.x;
//每一个线程块计算一个C的子矩阵
Matrix Csub = GetSubMatrix(C, blockRow, blockCol);
//每一个线程计算子矩阵的一个单元,并放在Cvalue中
float Cvalue = 0;//这将被放在CUDA寄存器中,因为CUDA的寄存器很多(4096个/CUDA嘛?)
//线程行和列索引号
int row = threadIdx.y;
int col = threadIdx.x;
//循环A,B中需要计算的那些子矩阵,同时计算每一个子成分并且求和
int LoopAim = A.width / BLOCK_SIZE;
for (int m = 0; m < LoopAim; m++) {
//得到A的子矩阵
Matrix Asub = GetSubMatrix(A, blockRow, m);
//得到B的子矩阵
Matrix Bsub = GetSubMatrix(B, m, blockCol);
//直接用来存放那些AB的子矩阵的局部内存
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
//从设备内存中将AB子矩阵搬运到局部内存中去,每一个线程搬运各自的子矩阵的一个元素
As[row][col] = GetElement(Asub, row, col);
Bs[row][col] = GetElement(Bsub, row, col);
//同步,确保子矩阵在计算前加载进来了
__syncthreads();
//将AB的子矩阵同时计算
for (int ele = 0; ele < BLOCK_SIZE; ele++) {
Cvalue += As[row][ele] * Bs[ele][col];
}
//同步,确保在加载AB新的子矩阵前,全部线程都计算完了
__syncthreads();
}
//将每一个线程中的内容写回全局内存
SetElement(Csub, row, col, Cvalue);
}
3.2.4 页锁定的主机内存
运行时提供了使用页锁定(固定内存地址)的主机内存申请方式,他有别于普通的malloc()申请到的内存。
- cudaHostAlloc()、cudaFreeHost():用来分配和释放页锁定内存。
- cudaHostRegister():将一段malloc()申请到的普通内存注册成页锁定内存。
使用页锁定内存有以下几点好处
- 前文提到的异步同步执行中的内核函数,使他们能在主机端与设备之间及时交互内存。
- 在一些设备中,页锁定的主机内存 可以被映射到设备端内存中,消除一些不必要的内存搬运。
- 在一些要用到北桥的系统上,这种页锁定方式会使得带宽变高,特别是在 写混合 式的内存上更高。
页锁定内存是一个匮乏的资源,并且使用过多的页锁定内存会使系统的性能下降。
相应的例子请看 页锁定APIs系列
手册注:页锁定内存没有在不具备IO连续的Tegra设备中缓存。并且没有连续IO的Tegra设备不支持cudaHostRegister();
我注:内存锁定,让分配的主机端内存锁定在一个固定的位置,不再受系统的分页分段机制与虚拟内存的换入换出机制影响。在设备端向内存交互内存时,可以直接将自己和主机的地址交给DMA,这样很快。如果不适用内存锁定,首先分配的页可能被系统交换到外存上去,其次设备在交互时,要先将内存搬运到一个隐式的临时内存锁定中去,然后再将锁定内存区内的东西搬到对应地方去,无形之中增加了内存交互的时间。但,这也不能全部都用内存锁定方式,这会带来主机端内存在运行中多次强制锁定内存而内存碎片化,或主存消耗殆尽。所以,这需要一个折衷。
3.2.4.1 轻便内存
一块内存锁定区可以在所有系统中混合使用,但是,使用页锁定的好处只在 这块被分配在混合式设备中之后才有效。(我是没看懂在说个啥)为了在所有设备中使用这种好处,需要分配的内存块需要向cudaHostAlloc()注册cudaHostAllocPortable,或者通过向cudaHostRegister()注册cudaHostRegisterPortable
3.2.4.2 写混合式内存
默认的是,页锁定内存被分配为可缓存的。可以通过向cudaHostAlloc()置cudaHostAllocWriteCombined来分配写混合内存。写混合内存释放了主机的一级二级缓存资源。此外,写混合内存在通过PCIe总线交互内存时不可见,这可以改善传输40%的性能。
主机端访问混合式内存是很慢的,所以写混合内存通常只在“只有设备写”时使用。
3.2.4.3 映射内存
一块的页锁定内存也可以通过向cudaHostAlloc()设置cudaHostAllocMapped标志(或向cudaHostRegister设置cudaHostRegisterMapped标志)来映射到设备内存。这些内存块通常都因此会有两个地址:一个是malloc()得到的,和用cudaHostGetDevicePointer()得到的设备内存。
在内核函数中直接获取主机内存有几种好处(通过内存映射方式):
- 不需要一次性的内存搬运,不需要在设备中定义那个内存块。当内核需要内存时自动搬运。
- 不需要使用流来重叠内核转变数据,内核会自动地将内核起源的数据转换。
但,这需要用流或事件来内存同步,并且避免可能的读后存、存后读或写写乱序。
cudaHostGetDevicePointer()将会得到错误,如果不将映射内存的设备调用标有cudaDeviceMapHost的cudaSetDeviceFlags()(手册上这话说的不像人话)
并且设备不支持映射页锁定内存也将会出错。设备要先确定支持canHapHostMemory。
注意,在别的设备或主机看来,当前设备的对 映射内存锁定内存的原子操作 (这修饰语好长) 并不是原子的。
注意PCIe总线对齐对 设备和主机内存对齐的影响。如CUDA运行时不支持通过8B对齐到的PCIe总线写2个4B。
3.2.5 异步的同时执行
一下操作是可以与其他命令同时进行的
- 在主机端计算
- 在设备端计算
- 主机向设备复制内存
- 设备向主机复制内存
- 给定设备的内存复制
- 所有设备中的内存复制
这些操作的同时执行性取决于下面描述的 设备特征集和设备计算能力
3.2.5.1 主机和设备之间的同时执行
在使用异步调用的情况下,线程可以排队等待CUDA驱动器的数据到达。
下面几个是关于系统异步执行的:
- 内核函数发送
- 从单一设备拷贝内存
- 从内存向设备考本不大于64KB的存储块
- 以Async结尾的内存操作函数
- 内存集合调用
可以通过定义CUDA_LAUNCH_BLOCKING来禁止异步执行,但这应当只限于调试,而不是用它来保证线程的执行顺序。
动态调试时异步执行无效。
3.2.5.2 同时执行内核
不同上下文的CUDA内核不能同时执行。大量使用纹理内存常量内存的内核低几率与其他内核同时执行。
3.2.5.3-3.2.5.4
说的废话,意思是自己去查设备版本对内存同时访问的可行性
3.2.5.5 流
流描述了程序管理执行的方法,是一系列顺序执行的命令。
3.2.5.5.1 创建和销毁流
下面用例子说明创建两个流并且分配一个在内存页锁定的float的hostPtr数组
cudaStream_t stream[2];
for (int i = 0; i < 2; i++) {
cudaStreamCreate(&stream[i]);
}
float* hostPtr;
cudaMallocHost(&hostPtr, 2 * sizeof(float));
每一个流都被下面的函数定义,从主机向设备拷贝内存。一个内核启动,一个内核从设备向主机拷贝。
float *inputDevPtr;
cudaMalloc(&inputDevPtr,sizeof(float)*2);
float *outputDevPtr;
cudaMallocHost(&outputDevPtr, 2 * sizeof(float));
size_t size = sizeof(float) * 2;
for(int i = 0; i < 2; i++){
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size, size, cudaMemcpyHostToDevice, stream[i]);
_32551MyKernel <<<100, 512, 0, stream[i] >>> (outputDevPtr + i * size, inputDevPtr + i * size, size);
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
注意hostPtr必须是页锁定的主存
流通过调用cudaStreamDestroy()销毁
完整的例子:
void _32551CreateSample() {
cudaStream_t stream[2];
for (int i = 0; i < 2; i++) {
cudaStreamCreate(&stream[i]);
}
float* hostPtr;
cudaMallocHost(&hostPtr, 2 * sizeof(float));
for (int i = 0; i < 2; i++)
hostPtr[i] = i;
float *inputDevPtr;
cudaMalloc(&inputDevPtr,sizeof(float)*2);
float *outputDevPtr;
cudaMallocHost(&outputDevPtr, 2 * sizeof(float));
size_t size = sizeof(float) * 2;
for(int i = 0; i < 2; i++){
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size, size, cudaMemcpyHostToDevice, stream[i]);
hostPtr[i] = i;
//_32551MyKernel <<<100, 512, 0, stream[i] >>> (outputDevPtr + i * size, inputDevPtr + i * size, size);
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
}
for (int i = 0; i < 2; i++)
std::cout<<hostPtr[i];
for (int i = 0; i < 2; i++) {
cudaStreamDestroy(stream[i]);
}
}
但stream还在工作时销毁,函数会立即返回,但流中所有工作都完成后 流占用的资源会自动释放。
3.2.5.5.2 默认流
用含有--default-stream per-thread命定的NVCC编译或在引用cuda头文件前定义CUDA_API_PER_THREAD_DEFAULT_STREAM就可以为每一个内核创建一个默认的流。
3.2.5.5.3 显式同步
cudaDeviceSynchronize() 等到设备内所有流都完成了。
cudaStreamSynchronize() 以一个线程为参考,等待在给定流中的所有线程完成。
cudaStreamWaitEvent() 以一个流或事件作为参考,并且使所有指令都加载到给定流中,将会等待到流总所有内容完成。
cudaSreamQuery() 查询流中的指令是否完成了。
为防止降低性能,同步最好只在内存搬运时使用。
3.2.5.5.4 隐式同步
下列主机线程情况会导致不同流的任务不能同时执行:
- 申请一个页锁定内存
- 申请设备内存
- 设置设备内存
- 对同一个设备同时拷贝两个不同位置的内存
- 空的流
- 一级缓存和共享内存之间的转换
- 所有支持同时执行的低于3.0计算能力的设备,每一个操作都要求检测流内核是否发送完毕。
在不大于3.0计算能力的设备上运行同时执行内核,所有操作都要求检测流内核是否发送完毕:
- 只能在 比他高优先级的已经执行流 中所有线程执行完毕后,这个流才能开始执行。
- 在确认了内核已发送前,所有后发送的内核都被挂起。
当向同一个已被检测的内核发送新的指令后,也需要检测是否传送完毕,这可通过cudaStreamQuery()来完成对这个流发送情况的检测(这句话原文连个标点都没有!定语状语堆一起,令人发指!) 因此,所有CUDA应用需要如下改进潜在的同时内核执行。
- 所有“独立的操作”应当在“不独立的操作”之前流出。
- 各种同步应当尽可能的往后放。
(原文是delay一词,同步delay。。。不妥)
5.2.5.5.5 重叠操作
两个流的执行重叠度却决于以下两点:每个流 的流出顺序;和设备是否支持数据传输与内核执行 同时执行、同时内核执行、和同时数据传输。
举个栗(例)子。在不支持同时数据传输的设备上,两个“创建与销毁”的样例代码 并不会重叠,这由于从stream[0]要先于stream[1]执行“主机向设备拷贝内存”这一操作。如果假设在支持同时数据传输,数据回传stream[1]可以和stream[0]重叠执行。
for (int i = 0; i < 2; i++)
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size, size, cudaMemcpyHostToDevice, stream[i]);
for (int i = 0; i < 2; i++)
MyKernel << <100, 512, 0, stream[i] >> > (ouputDevPtr + i * size, inputDevPtr + i * size, size);
for (int i = 0; i < 2; i++)
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
3.0及以下的设备同时执行“主机向设备”和“设备向主机”的内存拷贝 不能同时执行。可以参考上面那个例子进行优化。
3.2.5.5.6 流回调函数
执行时可以在执行流的任意一点,通过cudaStreamAddCallBack()插入一个回调。回调函数执行在主机端,当他被放入到流中,只有在其他所有流的任务都完成了,他才会被执行。
下面的例子展示了向两个MyCallBack中,在执行内存拷贝后加入回调函数。主机端的回调函数在设备向主机内存拷贝完成后才执行。
void CUDART_CB MyCallbacl(cudaStream_t stream, cudaError_t status, void *data) {
printf("加入回调函数%d\n", (size_t)data);
}
for (size_t i = 0; i < 2; i++) {
cudaMemcpyAsync(devPtrIn[i], hostPtr[i], size, cudaMemcpyHostToDevice, stream[i]);
MyKernel << <100, 512, 0, stream[i] >> > (devPtrOut[i], devPtrIn[i], size);
cudaMemcpyAsync(hostPtr[i], devPtrIn[i], size, cudaMemcpyDeviceToHost, stream[i]);
cudaStreamAddCallback(stream[i], MyCallback, (void*)i, 0);//第四个参数是用来以后用的
}
任何回调函数不能以任何方式使用CUDA API,否则会出现自己等自己的死锁情况。
3.2.5.5.7 流优先级
可以通过cudaStreamCreateWithPriority()创建有优先级的流。可以通过cudaDeviceGetStreamRange()获得可选择的流优先级范[higest priority, lowest priority]。在运行时。在低优先级流中的线程块执行完后,在高优先级流中的线程块才被调度进来计算。
下面的例子展示了,获取当前设备可取的优先级范围,并且创建最高最低优先级流
//获取设备支持的优先级范围
int priority_high, priority_low;
cudaDeviceGetStreamPriorityRange(&priority_low, &priority_high);
//创建最低最高优先级流
cudaStream_t st_h, st_l;
cudaStreamCreateWithPriority(&st_h, cudaStreamNonBlocking, priority_high);
cudaStreamCreateWithPriority(&st_l, cudaStreamNonBlocking, priority_low);
3.2.5.6 图
图是CUDA递交任务的一种新方法。一个图是一系列的操作,如内核发送,与依赖项连接,这些都从执行分开。这允许一个图定义一次然后运行多次(流要求发送几次才能执行几次)。将图和执行分开使以下行为成为可能:与流发送相比减少CPU发送内核的消耗;相比分段提交的流,它能提供整个工作流。
- 使用图提交任务可以分为以下三部分,定义,安装,执行。
- 定义阶段,程序创建它们操作的描述,并且创建所需要的依赖项。
- 安装阶段对图的模板做一个快照,证实他们,并且初始化最小需求的目标任务。
一个可执行的图可以像其他CUDA工作一样放入流中执行。他可以不需要多次的初始化。
3.2.5.6.1 图的结构
一个操作在图中生成一个节点。各操作之间的依赖度是边,这种依赖性就限制了操作的顺序。
一个操作在他依赖项完成时可被任意调度。调度任务交由CUDA系统。
3.2.5.6.1.1 图的节点类型
一个节点可以是下列中的某一种:
- 内核
- CPU函数调用
- 内存复制
- 设置内存
- 空点
- 子图:执行一个分割嵌套的图。
3.2.5.6.2 使用图API创建图
每个图都可以通过,设置API设流计算。下面是一个图计算的例子

//创建一个空的图
cudaGraphCreate(&graph, 0);
//处于实验目的,我们将独立于依赖项创建节点,这样来证明它可以用两种方式运行。注意,依赖项也可以在创建时指定
cudaGrapheAddKernelNode(&a, graph, NULL, 0, &nodeParams);
cudaGrapheAddKernelNode(&b, graph, NULL, 0, &nodeParams);
cudaGrapheAddKernelNode(&c, graph, NULL, 0, &nodeParams);
cudaGrapheAddKernelNode(&d, graph, NULL, 0, &nodeParams);
//现在为每个节点设置依赖项
cudaGraphAddDependencies(graph, &a, &b, 1);//A->B
cudaGraphAddDependencies(graph, &a, &c, 1);//A->C
cudaGraphAddDependencies(graph, &b, &d, 1);//B->D
cudaGraphAddDependencies(graph, &c, &d, 1);//C->D
3.2.5.6.3 用流捕获创建图
可以调用API来用已存在的流来创建图。例子如下:
cudaGraph_t graph;
cudaStreamBeginCapture(stream);//创建一个处在捕获态的流。处在此状态的流,但有新的任务进入其中时,并没有直接进入流中,而是附在正在构建的图的尾部。
kernel_A <<<..., stream >>> (...);
kernel_B <<<..., stream >>> (...);
libraryCall(stream);
kernel_C <<<..., stream >>> (...);
cudaStreamEndCapture(stream, &graphe);//流捕获终止于此。
流捕获不能在空流中使用、cudaStreamLegacy。但可以在cudaStreamPerThread中使用。如果程序使用了默认流,这可能每个线程重定义了一个默认流。
一个流可以调用cudaStreamIsCapturing()来确认流请求是否正在被捕获。
3.2.5.6.3.1 交叉流的依赖项和事件
流捕获可以用cudaEventRecord()和cudaStreamWaitEvent()来处理贯穿全流的依赖项,提供这种事件用来等待,直到记录到在同一个捕获流。
如下所示,同一个流捕获中的所有流直到cudaStreamEndCapture()才停止。不能接在源流(第一个流)将会导致流捕获这个操作的全面错误。
void SampleCudaStreamCaptureFailure() {
cudaGraph_t graphe;
cudaStream_t stream1, stream2, stream3;
cudaEvent_t event1, event2;
//源流
cudaStreamBeginCapture(stream1);
kenerl_A<<<..., stream1 >>> (...);
//stream2分叉
cudaEventRecord(event1, stream1);
cudaStreamWaitEvent(stream2, event1,0);
kenerl_B <<<..., stream1 >>> (...);
kenerl_C <<<..., stream1 >>> (...);
//将stream加载到源流的后面
cudaEventRecord(event2,stream2);
cudaStreamWaitEvent(stream1,event2,0);
kenerl_D <<<..., stream1 >>> (...);
//停止捕获
cudaStreamEndCapture(stream1, &graphe);
}
上面这例子,将会生成上面图12的样子。
流中有一部分被捕获走了,但并不影响本身流的其他操作和捕获走的操作之间的依赖性。
3.2.5.6.3.2 禁止和未处理的操作
不允许在“捕获流和捕获事件时”要求“同步或执行”,因为这无法调度。
3.2.5.6.3.3 无效性
只要出现无效操作,再往图里捕获流都会出错,并且返回空。
3.2.5.6.4 使用图API
cudaGraphe_t是线程不安全的,需要要求多线程不会同时执行它。
cudaGrapheExec_t自身不能同时执行。
3.2.5.7 事件
使用event可以对CUDA程序进行精准计时。
//创建cuda事件
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
//下面通过事件进行计时
cudaEventRecord(start, 0);
//
//CUDA操作
//
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
//销毁cuda事件
cudaEventDestroy(start);
cudaEventDestroy(stop);
3.2.6 多设备系统
3.2.6.1 设备计数
void getDeviceInfo() {
int deviceCount;
cudaGetDeviceCount(&deviceCount);
for (int device = 0; device < deviceCount; device++) {
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, device);
std::cout << "设备" << device<<"名称:"<<deviceProp.name << " 计算能力是" << deviceProp.major << "." << deviceProp.minor << "\n";
}
}
3.2.6.2 选择设备
void setDeviceSample() {
size_t size = 1024 * sizeof(float);
cudaSetDevice(0);//设置0为当前计算设备
float *p0;
cudaMalloc(&p0, size);
//MyKernel<<...,....>(p0);
int deviceCount;
cudaGetDeviceCount(&deviceCount);
if (deviceCount > 0){
cudaSetDevice(1);//设置1为计算设备
float *p1;
cudaMalloc(&p1, size);
//kernel
cudaFree(p1);
}
cudaFree(p0);
}
3.2.6.3 流和事件的行为
如果内核还有下面这个例子的问题,将会启动失败。
void StreamAndEventBehavior() {
cudaSetDevice(0); // 设置0为当前计算设备
cudaStream_t s0;
cudaStreamCreate(&s0); // 在设备0上创建流s0
MyKernel <<<100, 64, 0, s0 >>> (); // 在设备0向s0上发送内核
cudaSetDevice(1); // 设置1为当前计算设备
cudaStream_t s1;
cudaStreamCreate(&s1); // 在设备1上创建流s1
MyKernel << <100, 64, 0, s1 >> > (); // 在设备1向s1上发送内核
//下面这个内核函数调用将会出错
MyKernel << <100, 64, 0, s0 >> > (); // 在设备1向s0上发送内核
}
从非当前设备的流上复制内存也能成功。
cudaEventRecord()不能使用在不同设备的流和事件
cudaEventElapsedTime()两个输入事件关联于不同设备将会失败
cudaEventSynchronize()、cudaEventQuery()输入事件及时不同设备也能用。
cudaStreamWaitEvent()不同设备可用,所以可用于多设备的同步。
3.2.6.4 对等内存访问
运行在64位状态 且 计算能力大于2.0的Tesla系列 可在不同设备中访问互相的内存(即在A设备中的内存地址,可在B设备中用一个指向那个内存地址的指针访问到A中对的内存)。
可以通过cudaDeviceCanAccessPeer()的返回值判断两个设备是否支持这种特性。
下面的例子说明了内存的设置
cudaSetDevice(0); //设置0为当前计算设备
float* p0;
size_t size = 1024 * sizeof(float);
cudaMalloc(&p0, size); // 向设备0分配内存
MyKernel <<<1000, 128 >>> (p0); // 在设备0上执行
cudaSetDevice(1); // 设置1为当前计算设备
cudaDeviceEnablePeerAccess(0, 0); //通过设备0设置p0为对等内存
MyKernel <<<1000, 128 >>> (p0);//设备1上内核可通过指针访问设备0的p0内存
3.2.6.5 对等内存的内存拷贝
第一种方法是,在复制内存的两个设备上都定义一个统一的内存,然后用正常的cudaMemcpy()进行拷贝。
另一种方法如下所示
cudaSetDevice(0); //设置0为当前计算设备
float* p0;
size_t size = 1024 * sizeof(float);
cudaMalloc(&p0, size); //在设备0上分配内存
cudaSetDevice(1); //设置1为当前计算设备
float* p1;
cudaMalloc(&p1, size); //在设备1上分配内存
cudaSetDevice(0);
MyKernel <<<1000, 128 >>> (p0); //在设备0上执行内核函数
cudaSetDevice(1);
cudaMemcpyPeer(p1, 1, p0, 0, size); // 从设备0上将p0复制到设备1上去
MyKernel <<<1000, 128 >>> (p1);
两个设备之间复制内存需要两个设备没有内核在执行。
3.2.7 统一虚拟内存
当运行在64位模式中,为主机和不低于2.0计算能力设备申请的内存。所有通过CUDA API申请的主机内存、设备支持的存储方式 都处在虚拟内存范围内。
所以:
- 用CUDA定义的主机内存 和 统一的设备内存 都可以使用cudaPointerGetAttributes()来。可以使用cudaPointerGetAttributes()来,从指针的值来决定(虚拟内存?啥?)
- 当从或向 使用了统一内存 的设备,cudaMemcpy()的cudaMemcpyKind参数可以设置成cudaMemcpyDefault来确定来自指针的位置。
- 使用cudaHostAlloc()申请的内存 自轻便化,对于使用统一内存的设备中。没有必要使用cudaHostGetDeivepointer()来获取设备指针。
3.2.8 IPC(进程内通信)
同处理器内创建的线程可直接查询其他线程的 内存指针 事件句柄。不同处理器之间的线程不能直接访问。需要使用IPC APIs来完成这种通信。注意只在64位、计算能力不低于2.0 的Linux系统上能用。Tegra设备不支持IPC调用。
使用cudaIpcGetMemHandle()来从给定内存指针中获取IPC句柄,使用标准IPC机制来传送给别的处理器(如共享内存或文件)。cudaIpcOpenMemHandle()从IPC句柄中获取其他处理器有的设备指针。
3.2.9 纠错
运行时函数能直接返回错误代码。同时执行的函数不能直接返回错误代码,
同步执行函数的错误只能通过调用cudaDeviceSynchronize()来获得。
运行时位每一个主机线程保留一个“错误变量“,并在出现错误时被改写。cudaPeekAtLastError()返回这个值,然后重置为cudaSuccess;
内核发送不会返回任何错误代码,所以发送后需要检测是否发送成功,获取发送前错误代码(使用cudaPeekAtLastError())。
cudaStreamQuery()和cudaEventQuery()产生的cudaErrorNotReady并不是一个错误,因此不会被cudaPeekAtLastError()或cudaGetLastError()获取到错误。
3.2.10 调用栈
在不低于2.0计算能力的设备上,可以使用cudaDeviceGetLimit()获取调用栈大小,用cudaDeviceSetLimit()设置调用栈大小。
当调用爆栈时,可以通过CUDA Debugher(cuda-gdb,Nsight)来查看爆栈错误,或者返回一个不明确的错误。
3.2.11 纹理和表层(surface)内存
可以以下两种方式使用纹理内存, texture reference API(限制多)和texture object API(计算能力要≥3.0).
3.2.11.1 纹理内存
- 纹理对象是在运行时创建的;纹理参考在编译时创建,并在运行时进行内存绑定。
- 纹理可是1D、2D、3D的。纹理的维度参数见设备参数表。纹理数组中的单个元素叫纹素(texels)。纹素可以是“基本整数”、“单精度浮点数”、“1个或2个或4个组成一组的char,short,int,long,longlong,float,double”
- cudaReadModeElementType()中的cudaReadModeNormalizeFloat说明处在read mode。如果处在cudaReadModeNormalizedFloat的标准单精浮点数时,并且纹理是16位或8位整数形式时,纹理获取通常的返回值是“指向单精浮点数的指针”。而且所有unsigned int将映射到[0.0,1.0]之间,int映射到[-1.0,0.0]之间。举例来说,0xff的8位纹理将读成1.,并且不执行任何的类型转换操作!
- 对于一些将“纹理地址独立于纹理数组大小”作为优化的程序来说。纹理坐标默认的是从0到最长-1,但可以将每个维度的坐标都归一化到[0,1-1/N](N是对应纹理的对应维度的最大值)如64*32的纹理数组,默认坐标是x:[0,63],y:[0,31],归一化后是x:[0,1-1/64},y:[0,1-1/32]。
- 寻址模式中,正常地址处在[0,N)的范围,归一化得到[0.0,1.0)的范围。在准确定义了纹理范围的纹理中访问越界将返回0。(wrap模式和mirror模式没看懂,后面用到是再补,反正就是一堆稀奇古怪的寻址方式)
- 过滤模式具体化“根据输入纹理坐标获得的纹理”的返回值。线性纹理过滤可以只通过返回的单精浮点数指针数据完成。这在相邻纹素点之间有低精度的插值。(后面巴拉巴拉讲了一堆纹理过滤的东西,没图形学基础。。。。暂时看不懂)
3.2.11.1.1 纹理对象API
纹理定义参数如下

描述纹素(Texel)的结构cudaChannelFormatDesc的定义是

其中,x,y,z,w 是每一个返回值的位数,f为channel的类型,有三种
cudaChannelFormatKindSigned:组成全是有符号整数[吕1]
cudaChannelFormatKindUnsigned:组成全是无符号整数
cudaChannelFormatKindFloat:组成全是float
下面是一个纹理对象的实验,因为牵涉较多图形学,且篇幅较大,已独立发布。请参考
https://blog.csdn.net/lvxiangyu11/article/details/88078796
3.2.11.1.2 纹理引用函数
有一些“纹理引用函数的参数“是不可改变的,并且必须在编译时知道这种限定,它们在声明纹理引用函数时被设定。纹理引用如下定义
Texture
具体参数意义自己查手册,太多了!
纹理引用函数只能定义成static global变量,不能作为实参传递给函数。
其他的纹理引用参数是可以在运行时,由主机设定。由高级C接口和低级C接口。纹理结构定义在高级API中,作为一个公开的结构体,来自于低级API。
在内核可以使用纹理引用访问纹理内存之间,纹理引用必须使用cudaBindTexture()或cudaBindTexture2D()绑定到纹理上。一旦纹理引用没有被绑定,它可以被安全地重新绑定到别的纹理上,即使前面内核的纹理绑定没有完成。建议在线性内存中,使用2维的cudaMallocPicth()并且使用这个“对齐内存访问”来作为cudaBindTexture2D()的输入参数。
下面的例子说明了,使用devPtr将2D纹理绑定线性内存。
使用低级API
texture<float, cudaTextureType2D, cudaReadModeElementType> texRef;
textureReference *texRefPtr;
cudaGetTextureReference(&texRefPtr, &texRef);
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
size_t offset;
cudaBindTexture2D(&offset, texRefPtr, devPtr, &channelDesc, width, height, pitch);
使用高级API
texture<float, cudaTextureType2D, cudaReadModeElementType> texRef;
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
size_t offset;
cudaBindTexture2D(&offset, texRef, devPtr, &channelDesc, width, height, pitch);
下面的例子说明了,使用devPtr将2D纹理绑定CUDA数组cuArray。
使用低级API
texture<float, cudaTextureType2D, cudaReadModeElementType> texRef;
textureReference *texRefPtr;
cudaGetTextureReference(&texRefPtr, &texRef);
cudaChannelFormatDesc channelDesc;
cudaGetChannelDesc(&channelDesc, cuArray);
cudaBindTextureToArray(texRef, cuArray, &channelDesc);
使用高级API
texture<float, cudaTextureType2D, cudaReadModeElementType> texRef;
cudaBindTextureToArray(texRef, cuArray);//VS2017报参数过少
将纹理绑定到纹理引用时说明的格式,一定要与声明纹理引用时设置的格式相同。否则获取到的纹理为undefined。
可以绑定到内核的纹理数可以查设备支持表。Table14
下面的例子说明了使用一些简单的“内核对纹理的转变”
https://blog.csdn.net/lvxiangyu11/article/details/88081100
3.2.11.1.3 16位单精浮点指针的指针
16位单精浮点指针 或 half,CUDA数组均支持且与IEEE 754-2008 Binary2 相同。
CUDA C不支持一个matching data(与上述相符的?) 类型。但是提供了一个从32位单精浮点指针格式来的转换,这是通过unsigned short类型:__float2half_rn(float)和__half2float(unsigned short)。这只在设备端可用。主机端相同的操作可在OpenEXR库中找到。E.g.
纹理获取时,在纹理过滤之前,16位单精浮点指针升级到32位单精浮点。
一个关于16位单精浮点格式的channel描述,可用通过调用cudaCreateChannelDescHalf*()函数。
3.2.11.1.4 层次化的纹理
Texture Array in Direct3D & Array Texture in OpenGL
一维层次纹理用“一个int索引”和”一个float坐标”,二维层次纹理用“一个int索引”和“两个float坐标”。
层次纹理可以使用tex1DLayered(),tex2DLayered()来获取。纹理过滤只在层次里操作,而不在层次间操作。
层次纹理要求计算设备能力≥2.0
3.2.11.1.5 立方图纹理
Cubamap是2维层次纹理的特殊类型,像有6个面一样,它有6个层次。
层次的宽等于高。
使用xyz三维纹理位置定位。以立方体体心为原点,层次中的点与面相应。面是通过含有最大size的坐标m,与 相对应的层次选中的。这个地址使用坐标(s/m+1)/2和(t/m+1)/2,s,t如下所示。
索引如图所示
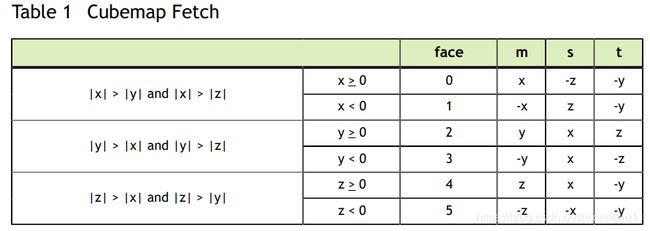 数学表示的比较恶心,画个图就简单了,我图画的不好,大家自己画哈。
数学表示的比较恶心,画个图就简单了,我图画的不好,大家自己画哈。
立方图纹理的层次化内存只能是用了cudaArrayCubemap的cudaMalloc3DArray()创建的CUDA数组。
立方图纹理使用设备端的texCubemap()和texCubemap()来获取。
要求计算设备能力≥2.0
3.2.11.1.6 立方图层次化的纹理
一个立方图层次化的纹理是一个层次纹理,他的层次的与立方图维度(dimension)相同。
使用一个int的index和三个float的纹理坐标进行索引。
只能是设置了cudaArrayLayered和cudaArrayCubemap的cudaMalloc3DArray()的CUDA数组。
设备端中,可以使用texCubemapLayered()和texCubemapLayered()获取立方图层次化的纹理。(立方图的)纹理过滤只能在层次中进行,不能超出层次。
要求计算设备能力≥2.0
3.2.11.1.7 纹理积聚(texture gather)
纹理聚集是一种只能用在二位纹理中的纹理获取。通过tex2Dgather()调用,这与tex2D()相同,plus an additional comp parameter equal to 0,1,2 or 3(see tex2Dgather() and tex2Dgather)(没看懂。)。它可以返回4个32位数,这4个数与comp的4纹素组成的值相同,而这个值是在正常纹理获取中 作为双线性过滤的(原文这里对texel的修饰定语极长,真恶心)。这里举个栗(例)子,如果这些纹素是
(253,20,31,255),
(250,25,29,254),
(249,16,37,253),
(251,22,30,250)
并且comp是2,
则tex2Dgather()返回(31,29,37,30);//他就返回了每一组的第2位(从0开始数)
注:这里比较难懂,牵涉图形学,我也稀里糊涂的,后面我会再写这些关于图形学的疑问的,参考下OpenGL的纹理积聚操作也许有些收获,https://www.khronos.org/registry/OpenGL-Refpages/gl4/html/textureGather.xhtml;
需要注意的是,(纹理积聚的)纹理坐标只使用8位精度小数。因此,在tex2D()可能使用1.0作为它weights(α或β)值时,tex2Dgather()可能会返回不可预期的结果。
举个例子,使用坐标为2.49805的纹理x:xB=x-0.5=1.99805,然而xB的小数精度短于固定的8位。由于0.99805相比于255.f/256.f更接近于256.f/256.f,因此,xB被设定为2。所以,这个例子中,tex2Dgather()会因此返回x中的2和3值,而不是1和2的值。
纹理积聚只在“使用了cudaArrayTextureGather参数创建的CUDA数组”中有效,并且(CUDA数组)宽高要小于Table14中所示的最大限度,这小于正常纹理获取。
要求计算设备能力≥2.0
3.2.11.2 表层(surface)内存
要求计算设备能力≥2.0,一个用cudaArraySurfaceLoadStore标志创建的CUDA数组,可以通过表层对象(Surface Object)和表层引用(Surface Reference)来访问和读写。
3.2.11.2.1 表层对象API
表层对象从“资源struct cudaResourceDesc”使用cudaCreateSurfaceObject()。
下面用例子说明使用表层对象进行纹理转换。
移步:https://blog.csdn.net/lvxiangyu11/article/details/88096587
3.2.11.2.2 表层引用API
表层引用作为一个“表层类型”的变量,申明在文件域中。
Surface
Type的是表层引用的参数,并且可选值有:cudaSurfaceType1D, cudaSurfaceType2D, cudaSurfaceType3D, cudaSurfaceTypeCubemap, cudaSurfaceType1DLayered, cudaSurfaceType2DLayered, cudaSurfaceCubemapLayered。Type默认值是cudaSurfaceType1D。表层引用只能定义成一个static global变量,并且不能作为一个可传实参。
在内核函数前,可以使用表层引用来获取CUDA数组,表层引用必须使用cudaBindSurfaceToArray()绑定至CUDA数组上。
下面的例子展示了如何将表层引用绑定到CUDA数组cuArray上
低级API
surface<void, cudaSurfaceType2D> surfRef;
surfaceReference *surfRefPtr;
cudaGetSurfaceReference(&surfRefPtr, "surfRef");
cudaChannelFormatDesc channelDesc;
cudaChannelFormatDesc(&channelDesc, cuArray);
cudaBindSurfaceToArray(surfRef, cuArray, &channelDesc);
注:cuda sdk手册中,对cudaGetSurfaceReference有一个注释,第二条”Use of string naming a variable as the symbol(即第二个参数) parameter was removed in CUDA 5.0”需要注意。
高级API
surface<void, cudaSurfaceType2D> surfRef;
cudaBindSurfaceToArray(surfRef, cuArray);
此时,对CUDA数组的读写,必须使用“对应维度和类型的表层函数”与“与数组对应维度的表层引用”(原文两个and连用,难以分析,恶心)。否则,读写出的CUDA数组均为undefined。
于纹理内存不同,表层纹理使用字节(Byte)寻址。这意味着以前通过纹理函数访问纹理元素的x坐标,但它以表层引用的方式访问相同纹理元素时,需要翻倍成Byte大小。
举个例子加以说明:一个在纹理坐标为X,且它所在的CUDA数组是一维的float型数组,同时,他所在的CUDA数组被纹理引用texRef绑定,同时也被表层引用surfRef绑定。但纹理引用通过纹理引用texRef使用tex1d(texRef, x)访问这个数组时,纹理引用访问却需要使用surf1Dread(surfRef,4*x)。
同样,二维时同样的元素,纹理引用访问使用tex2D(texRef, x, y),表层引用使用surf2Dread(surfRef, 4*x, y)(y坐标的字节偏移,自动内在地从潜在的CUDA数组行对其访问(line pitch of CUDA array)计算出来)。
下面的例子说明了,简单的纹理变换内核。
【补地址】
3.2.11.2.3 立方图表层
使用surfCubemapread()和surfCubemapwite()来对立方图纹理读写,如二维层次纹理那样,即使用用一个int定位到一个面,然后用两个float定位对应于那个面的纹理坐标。面顺序见上面Tabel1
3.2.11.2.4 立方图层次表层
使用surfCubemapLayeredread()和surfCubemapLayeredwrite()对立方图层次表层读写,如二位层次表层一样,举个例子,使用一个int定位立方图的面,使用两个float定位面上的纹理坐标。面顺序见Tabel1。例如,index((2*6+3)是获取第三个立方图的第四个面。
3.2.11.3 CUDA数组
当使用纹理获取(Texture fetching)时,CUDA数组是不透明的存储层次。它有1至3维层次,元素的组成可以是1,2,4个参数一组,参数的类型可以是8,16,32位的int。CUDA数组只能由内核函数,调用纹理获取(texture fetching)或表层读写(surface reading and writing)。
3.2.11.4 读写一致性
纹理和表层内存都被缓存了(cached),并且在一个相同的内核调用中,缓存并不与全局内存写和表层内存写保持一致。所以,在同一个内核调用中,如果进行向全局内存写或表层写(surface write)操作的地址,进行纹理获取或表层读,读到的都是undefined。换句话说,任何一个线程只能在“内存地址已经被前面别的内核调用更新,或内存复制了”时读取纹理内核和表层内存才是安全的,而不是来自同一个线程的内核调用修改。因为,surface write不与cache同步,同一个线程写,并没有放入到cache中。
3.2.12 图形(库)互用性
一些来自OpenGL和Direct3D的资源可以映射到CUDA的地址空间,或者可以用CUDA来访问那些用OpenGL或Direct3D写的资源,或写一些可作为OpenGL或Direct3D可使用的数据。
在使用之前资源必须注册到CUDA上。这些(图形库)注册函数返回一个指向CUDA图像资源的指针,资源的结构是struct cudaGraphicsResource。注册一个资源是潜在地十分高总开销的(high-overhead),因此常常一个资源只注册一次。CUDA图像资源使用cudaGraphicsUnregisterResource()来解注册。每一个使用这种资源的CUDA上下文需要独自地注册一次。
一旦资源注册到CUDA上了,可以根据需要多次进行映射或解映射,相应函数是cudaGraphicMapResources()和cudaGraphicesUnmapResources()。cudaGraphicResourceSetMapFlags()可以用来设置CUDA驱动函数的读写设置(write-only,read-only)。
一个映射了的资源可以使用设备内存指针来读写,指针有cudaGraphicResourceGetMappedPointer()返回的buffer指针 和 cudaGraphicSubResourceGetMappedArray()返回的CUDA数组指针。
不同内核映射的资源,通过OpenGL和Direct3D访问的到的是undefined结果,后面有例子说明特殊情况。
3.2.12.1 OpenGL互用性
可以映射到CUDA的OpenGL资源有:buffer,texture,renderBuffer(渲染缓冲区) objects。
使用cudaGraphicsGLRegisterBuffer()来注册缓冲区,得到的值如连续内存。可以通过cudaMemcpy()来读写。
使用cudaGraphicsGLRegisterImage()来注册纹理和渲染缓冲区。得到的值像CDUA数组。可以通过纹理texture或表层surface 的引用reference来访问。也可以在注册时使用cudaGraphicsRegisterFlagsSurfaceLoadStore值来通过表层(surface)写。也可以用cudaMemcpy2D()来进行读写。cudaGraphicsGLRegisterImage()支持所有1,2,4参数的纹理格式,也支持内构的float类型(如GL_RGBA_FLOAT32),也支持内构的整数(如GL_RGBA8,GL_INTENSITY16),和unnormalized int(如GL_RGBA8UI)。(please note that since unnormalized integerformats require OpenGL 3.0, they can only be written by shaders, not the fixed functionpipeline)
后面对OpenGL上下文有限制。没学过OpenGL没看懂,原文如下:
The OpenGL context whose resources are being shared has to be current to the hostthread making any OpenGL interoperability API calls.
Please note: When an OpenGL texture is made bindless (say for example by requestingan image or texture handle using the glGetTextureHandle*/glGetImageHandle* APIs)it cannot be registered with CUDA. The application needs to register the texture forinterop before requesting an image or texture handle.
下面的代码例子使用了一个内核,这个内核动态地调整了一个存在矩阵缓冲对象的2D width*height点(vertices)的网格。
(后面的代码自己看CUDA[吕2] 手册吧,我没学过OpenGL、Direct3D,感兴趣这部分的自己看手册。)
3.2.12.2 Direct3D 共享性
3.2.12.3 SLI共享性
SLI多卡交火。现在用不着,略。
3.3 版本和计算能力
驱动API版本定义在头文件里CUDA_VERSION。驱动API向后兼容,不向前兼容。
系统中只能安装一个驱动API,版本必须比所有程序最低限度要高。
Plg-ins和库动态链接时可以版本不同。
3.4 计算模型
三种计算模型:
默认模型:主机的多线程可以使用设备
排他计算(Exclusive-process)计算模型:系统中所有处理器只能创建一个CUDA上下文。
禁止计算模式:不能在设备端创建上下文。
这就意味着,可能使用runtime API时在一个不能创建上下文的设备上要求运行。可以通过cudaSetValideDevices()来设备禁止列表。
Pascal开始,有了任务抢占(preemption)方式,它支持在“指令层次”这一粒度的任务调度,而不是低于它的(如Maxwell,Kepler)的以线程块为粒度的调度方式。这带来了一定的好处,防止任务独占和计算超时。
3.5 (显示)模型切换
GPU有一种显示输出,这种输出有叫做主表层(primary surface)的DRAM存储器。这是用来刷新那些给用户看的显示设备。扩大显示分辨率会增大这个区域,初始化显示模式转换也会改变这个区域(如启动一个全屏的DirectX程序、alt+tab显示任务选择框,alt+tabl+del)
如果显示模式转换时要创建过多的这种内存区域,系统可能会拆了已经分配给CUDA程序的内存,转而分配给显示区域。因此这种显示切换会导致CUDA程序运行出错,或返回出错。
3.6 windows中Tesla计算集簇(cluster)模型
使用NVIDAIA的系统管理接口(nvidia-smi),Windows设备驱动可以放在TCC(Tesla Computer Cluster)模型中,在计算能力≥2.0的Tesla和Quadro系列中可用。
有如下好处:
可以在没有NVIDIA集成显卡的集簇节点中使用GPUs。
可以远程使用GPUs,并且可以直接使用远程主机的集簇管理系统。
使GPUs的程序可以在windows服务器上运行。
但TCC模型删去了所有图形(显示)功能。
By-吕翔宇
2019年3月6日 21:48 止