PyTorch(CNN+MNIST测试)
说明
- 数据集采用的是MNIST数据集(训练集60000个, 测试集10000个,单通道28*28的图片)
- 采用的网络模型结构
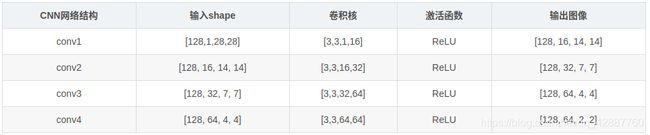
- 程序在GPU上跑的。运行时
watch -n 1 nvidia-smi实时查看电脑GPU的使用情况。 - 目录结构
测试集代码
# 需要导入的包
import torch
from torch.utils import data # 获取迭代数据
from torch.autograd import Variable # 获取变量
import torchvision
from torchvision.datasets import mnist # 获取数据集
import matplotlib.pyplot as plt
# 数据集的预处理
data_tf = torchvision.transforms.Compose(
[
torchvision.transforms.ToTensor(), # 对原有数据转成Tensor类型
torchvision.transforms.Normalize([0.5],[0.5]) # 用平均值和标准偏差归一化张量图像
]
)
# 获取数据集
data_path = r'./mnist_data' # 当前目录下的mnist_data文件夹下
train_data = mnist.MNIST(data_path,train=True,transform=data_tf,download=False)
test_data = mnist.MNIST(data_path,train=False,transform=data_tf,download=False)
# 获取迭代数据:
train_loader = data.DataLoader(train_data, batch_size=128, shuffle=True, num_workers=2) # 总共有60000/128 = 469个批次
test_loader = data.DataLoader(test_data, batch_size=128, shuffle=False, num_workers=2) # 总共有10000/128 = 79个批次, 测试集不需要打乱数据
# 定义网络结构
class CNNnet(torch.nn.Module):
def __init__(self):
super(CNNnet,self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=2, padding=1),
torch.nn.BatchNorm2d(16),
torch.nn.ReLU()
)
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(16,32,3,2,1),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU()
)
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(32,64,3,2,1),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
self.conv4 = torch.nn.Sequential(
torch.nn.Conv2d(64,64,2,2,0),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
self.mlp1 = torch.nn.Linear(2*2*64,100)
self.mlp2 = torch.nn.Linear(100,10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.mlp1(x.view(x.size(0),-1))
x = self.mlp2(x)
return x
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = CNNnet() # 实例化模型
model = model.to(device) # 把模型放到GPU上去
# print(model) # 输出模型信息
# 定义损失和优化器
loss_func = torch.nn.CrossEntropyLoss() # 使用交叉熵损失
optimizer = torch.optim.Adam(model.parameters(),lr=0.001) # 使用Adam优化器
# optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # SGD with moment
'''
训练网络:步骤
- 获取损失:loss = loss_func(out,batch_y)
- 清空上一步残余更新参数:opt.zero_grad()
- 误差反向传播:loss.backward()
- 将参数更新值施加到net的parmeters上:opt.step()
'''
loss_count = []
# 训练网络 , 迭代epoch
for epoch in range(10):
running_loss = 0.0
for step, (x,y) in enumerate(train_loader, 0): # 60000/128 = 469个batch(其中batch_size=128)
# get the input
inputs = Variable(x).to(device) # torch.Size([128, 1, 28, 28])
labels = Variable(y).to(device) # torch.Size([128])
# CNN output
outputs = model(inputs)
loss = loss_func(outputs, labels) # 计算loss
optimizer.zero_grad() # 清空上一步残余更新参数值
loss.backward() # loss 求导, 误差反向传播,计算参数更新值
optimizer.step() # 更新参数:将参数更新值施加到net的parmeters上
# print statistics
loss_count.append(loss) # 是一个Tensor对象列表
running_loss += loss.item() # tensor.item() 获取tensor的数值
# print("loss_count-->", loss_count)
# print("running_loss-->", running_loss)
if step % 100 == 99:
print('[%d, %5d] loss: %.3f' % (epoch + 1, step + 1, running_loss / 100)) # 每100个batch,输出loss的平均值
running_loss = 0.0
# --------保存模型-----------
# torch.save(model, './model/model_mnist.pkl') # 保存整个模型,体积比较大(*.pkl或*.pth都行)
torch.save(model.state_dict(), './model/model_mnist.pth') # 只保存模型的圈中参数(推荐采用下面这种)
# 损失函数图
plt.figure('PyTorch_CNN_Loss')
plt.plot(loss_count,label='Loss')
plt.legend()
plt.show()
print('Finished Training')
训练集代码
# 需要导入的包
import torch
from torch.utils import data # 获取迭代数据
from torch.autograd import Variable # 获取变量
import torchvision
from torchvision.datasets import mnist # 获取数据集
import matplotlib.pyplot as plt
# 设备判断
is_support = torch.cuda.is_available()
if is_support:
device = torch.device('cuda:0')
else:
device = torch.device('cpu')
# 数据集的预处理
data_tf = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(), # 对原有数据转成Tensor类型
torchvision.transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)) # 用平均值和标准偏差归一化张量图像
])
# 获取数据集
test_data = mnist.MNIST('mnist_data',train=False,transform=data_tf,download=False)
test_loader = data.DataLoader(test_data, batch_size=128, shuffle=False, num_workers=2) # 总共有10000/128 = 78.125 = 79个批次, 测试集不需要打乱数据
# 定义网络结构(无论是哪种方式加载模型,都要将模型定义一遍,否则报错)
class CNNnet(torch.nn.Module):
def __init__(self):
super(CNNnet,self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=2, padding=1),
torch.nn.BatchNorm2d(16),
torch.nn.ReLU()
)
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(16,32,3,2,1),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU()
)
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(32,64,3,2,1),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
self.conv4 = torch.nn.Sequential(
torch.nn.Conv2d(64,64,2,2,0),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
self.mlp1 = torch.nn.Linear(2*2*64,100)
self.mlp2 = torch.nn.Linear(100,10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.mlp1(x.view(x.size(0),-1))
x = self.mlp2(x)
return x
# 第一种加载模型的方式
# model = torch.load('./model/model_mnist.pkl')# 用这种方式加载的时候还是要定义模型类
# 第二种加载模型的方式
model = CNNnet()# 实例化模型
model.load_state_dict(torch.load('./model/model_mnist.pth'))# 加载权重参数
model.to(device) # GPU模式需要添加
# print(model) # 输出模型信息
# ------------在整个测试集上测试-------------------------------------------
correct = 0 # 测试机中测试正确的个数
total = 0 # 测试集总共的样本个数
count = 0 # 共进行了count个batch = total/batch_size
with torch.no_grad():
for images, labels in test_loader:
images = Variable(images).to(device)
labels = Variable(labels).to(device)
# forward
pre_labels = model(images) # 100*10
_, pred = torch.max(pre_labels, 1) # 100*1
correct += (pred == labels).sum().item() # 正确的个数
total += labels.size(0) # 计算测试集中总样本个数
count += 1 # 记录测试集共分成了多少个batch
print("在第{0}个batch中的Acc为:{1}" .format(count, correct/total))
# 总体平均 Acc
accuracy = float(correct) / total
print("====================== Result =============================")
print('测试集上平均Acc = {:.5f}'.format(accuracy))
print("测试集共样本{0}个,分为{1}个batch,预测正确{2}个".format(total, count, correct))
结果

参考:
- 使用PyTorch实现CNN
- pytorch学习(十)—训练并测试CNN网络